应用Markdown 在线阅读器
Posted zhangjk1993
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了应用Markdown 在线阅读器相关的知识,希望对你有一定的参考价值。
前言
一款在线的 Markdown 阅读器,主要用来展示 Markdown 内容。支持 html 导出,同时可以方便的添加扩展功能。在这个阅读器的基础又做了一款在线 Github Pages 页面生成器,可以方便的生成不同主题风格的 GitHub Page 页面。
功能
阅读器
- 支持文件拖拽
- 兼容移动端
Prism.js/Highlight.js代码高亮- 自动生成目录
- 本地图片显示
- 导出 Html (包含样式)
- 扩展功能
Github Page 生成器
在上面的基础上加上了下面的功能
地址
效果
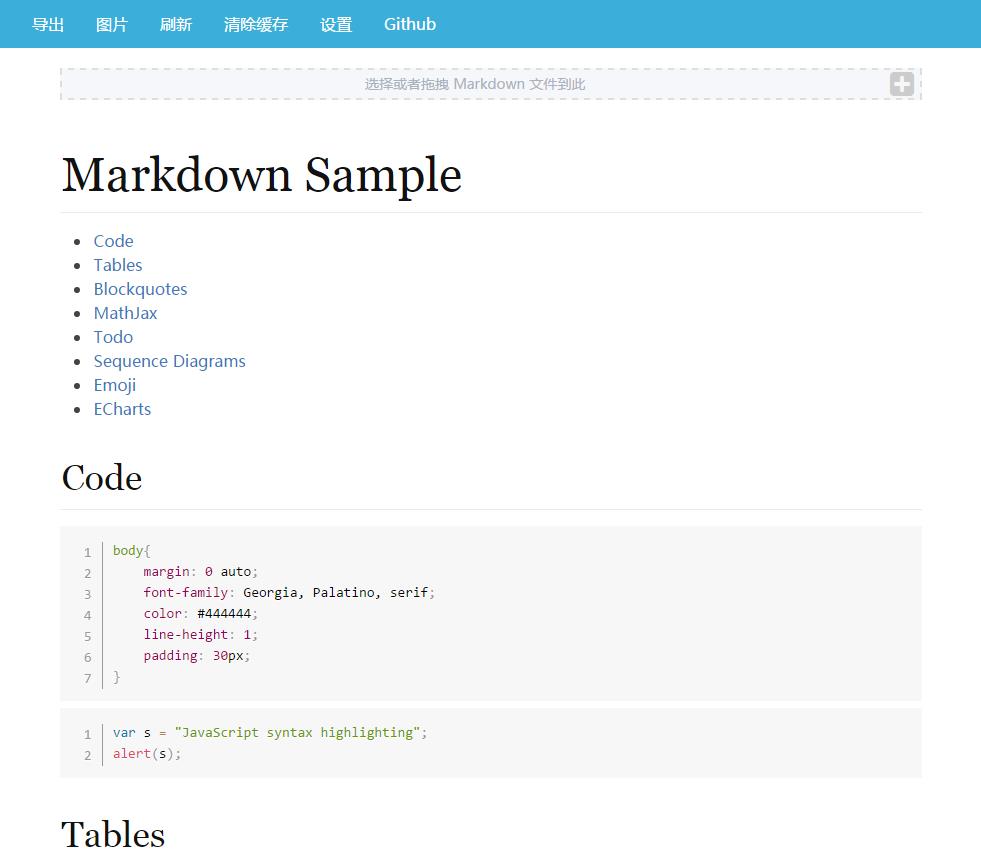
阅读器
生成器

实现
文件解析
程序使用 marked 将 markdown 格式转为 html 格式,这是一个 js 的库,可以直接在浏览器端使用。下面是一个基本的示例
var htmlContent = marked(mdContent);
$("#content").html(htmlContent);同时 marked 提供了一些接口,让我们可以方便的定制自己的功能。具体的可以参考它的 说明文件 。在下面我们会介绍我们是如何利用这些接口来实现扩展功能。
文件上传
自定义上传按钮样式
原始的上传按钮太丑了,所以我们需要自定义自己的样式。这里使用的方式是使用在 input 上面覆盖一个 button,用 button 来显示样式。同时我们将 button 的 pointer-events 设为 none,就可以阻止 button 的事件响应(具体可以参考这里)。下面是具体的实现代码:
html:
<div class="upload-area" id="upload-area">
<input type="file" id="select-file" class="select-file">
<button class="select-file-style" id="drop">选择或者拖拽 Markdown 文件到此</button>
</div>css
.upload-area
width: auto;
height: 200px;
margin: 0 2.6em 0 0.4em;
padding: 0;
position: relative;
cursor: pointer;
transition: height 0.5s;
.upload-area .select-file
border-width: 0px;
width: 100%;
height: 200px;
margin: 0;
cursor: pointer;
.upload-area .select-file-style
background: #F5F7FA;
position: absolute;
top: 0;
left: 0;
width: 100%;
height: 200px;
border: 0px;
pointer-events: none;
color: #AAB2BD;
font-size: 2em;
line-height: 2em;
font-family: "Microsoft YaHei", "Tahoma", arial;
下面是效果图

读取文件内容
因为程序完全是运行在浏览器端,所以我们使用 html5 的 FileReader 来读取本地文件。FileReader 提供 4 种读取文件的方式:
readAsBinaryString(Blob|File)readAsText(Blob|File, opt_encoding)readAsDataURL(Blob|File)readAsArrayBuffer(Blob|File)
其中 readAsText 用来读取文本文件,readAsDataUrl 可以用来读取图片。具体的介绍可以参考 这里 。FileReader 一般结合文件选择事件或者拖拽事件使用,因为通过这两个事件可以获得源文件。另外 FileReader 是异步读取的,通过 onload 事件可以监听文件是否读取完毕。下面是一个示例, 通过点击 <input type= "file"> 选择文件,然后读取文件内容。
document.getElementById("file-select").addEventListener("change", function(e)
e.stopPropagation();
e.preventDefault();
var reader = new FileReader();
reader.readAsText(this.files[0]);
reader.onload = function (e)
var content = e.target.result;
//......
;
, false);拖拽文件
为了方便用户操作,我们提供了点击和拖拽两种方式来上传文件。现在的主流浏览器都支持文件拖拽功能,下面是拖拽过程中触发的事件
| 事件 | 描述 |
|---|---|
| dragstart | 用户开始拖动对象时触发。 |
| dragenter | 鼠标初次移到目标元素并且正在进行拖动时触发。这个事件的监听器应该之指出这个位置是否允许放置元素。如果没有监听器或者监听器不执行任何操作,默认情况下不允许放置。 |
| dragover | 拖动时鼠标移到某个元素上的时候触发。 |
| dragleave | 拖动时鼠标离开某个元素的时候触发。 |
| drag | 对象被拖拽时每次鼠标移动都会触发。 |
| drop | 拖动操作结束,放置元素时触发。 |
| dragend | 拖动对象时用户释放鼠标按键的时候触发。 |
另外在拖拽过程中是不触发鼠标事件的。文件读取完后文件信息会保存在 DataTransfer 对象中。详细的介绍可以参考 这里 。下面是添加事件的示例
fileSelect.addEventListener("dragenter", dragMdEnter, false);
fileSelect.addEventListener("dragleave", dragMdLeave, false);
fileSelect.addEventListener('drop', dropMdFile, false);读取拖拽的文件
function dropMdFile(e)
// 取消浏览器默认行为
e.stopPropagation();
e.preventDefault();
var reader = new FileReader();
reader.readAsText(e.dataTransfer.files[0]);
reader.onload = function (e)
var content = e.target.result;
//......
;
本地图片显示
因为没有服务器,所以为了显示本地图片,使用了替换图片 src 的方式。首先读取本地文件,然后将 <img> 的 src 路径替换为图片内容 。如下所示:
<img src="path">
// 替换为
<img src="data:image/jpeg;base64,/9j/4AAQSkZJRgABAQAAAQABAAD/2wBDAAMCAgI...">下面是具体的代码实现:
// 读取选择或者拖拽的文件(多个文件)
function processImages(imgFiles)
var index = 0;
for (i = 0; i < imgFiles.length; i++)
var file = imgFiles[i];
var reader = new FileReader();
reader.readAsDataURL(file);
(function (reader, file)
reader.onload = function (e)
cacheImages[file.name] = e.target.result;
index++;
if (index == length)
replaceImage();
)(reader, file);
// 将路径替换为图片内容
function replaceImage()
var images = $("img");
var i;
for (i = 0; i < images.length; i++)
var imgSrc = images[i].src;
var imgName = getImgName(imgSrc);
if (cacheImages.hasOwnProperty(imgName))
images[i].src = cacheImages[imgName];
如果图片过大,我们可以将图片压缩一下,具体方法就是创建一个 canvas 元素,将图片绘制到 canvas 上,然后将 canvas 转为图片。这种方式对 jpg 文件压缩效果较好,对 png 文件压缩效果不太好。下面是代码实现:
function compressImage(img, format)
var max_width = 862;
var canvas = document.createElement('canvas');
var width = img.width;
var height = img.height;
if (format == null || format == "")
format = "image/png";
if (width > max_width)
height = Math.round(height *= max_width / width);
width = max_width;
// resize the canvas and draw the image data into it
canvas.width = width;
canvas.height = height;
var ctx = canvas.getContext("2d");
ctx.drawImage(img, 0, 0, width, height);
return canvas.toDataURL(format);
循环中使用异步回调函数
为了方便使用,我们可以同时上传多个图片,我们使用 for 循环来读取多个文件,但是有个问题是文件的读取是异步的,也就是说在 for 循环执行完之后,图片可能仍在读取中,当图片读取完后,再调用 onload 回调函数进行处理。简单一点就是说如何在 for 循环中正确使用延迟调用的回调函数。看下面的例子:
function print(value, callback)
console.log("value in print", value);
setTimeout(callback, 1000);
for(var i = 0; i < 4; i++)
var value = i;
print(value, function()
console.log("value in callback", value);
);
上面打的代码和我们读取图片文件的逻辑类似,callback 函数会在调用 print 函数1秒后执行,下面是输出结果
value in print 0
value in print 1
value in print 2
value in print 3
value in callback 3
value in callback 3
value in callback 3
value in callback 3最后在 callback 中 value 值都是3,这是因为在 js 中没有块级作用域,只有函数作用域,也就是说下面的两段代码是等同的:
for(var i = 0; i < 4; i++)
var value = i;
// do someting
// 等同于
var value;
for(var i = 0; i < 4; i++)
value = i;
// do someting
因此,为了解决这个问题,我们只需要为循环中的回调函数添加一个单独的作用域即可,我们使用闭包来实现:
for(var i = 0; i < 4; i++)
var value = i;
(function(value)
print(value, function()
console.log("value in callback", value);
);
(value));
代码高亮
我们使用两款代码高亮插件 – highlight.js 和 prism.js,根据喜好可以自由切换。这两款插件对代码块的 html 格式有不同的要求,我们重写了 marked 中解析代码块的方法,根据高亮方式来生成不同的 html 代码:
renderer.code = function (code, lang)
if (Setting.highlight == Constants.highlight)
return "<pre><code class='" + lang + "'>" + code + "</code></pre>";
return "<pre><code class='language-" + lang + "'>" + code + "</code></pre>";
;然后调用 highlight.js 和 prism.js 的代码高亮方法即可
if (Setting.highlight == Constants.highlight)
$('pre code').each(function (i, block)
hljs.highlightBlock(block);
);
else
// 添加行号支持
$("pre").addClass("line-numbers");
Prism.highlightAll();
目录
为了生成文件的目录,我们需要首先获得目录信息,因此我们重写 marked 的 heading 方法, 将目录信息保存起来,同时为每个标题添加链接图标(仿照 github),下面是代码:
renderer.heading = function (text, level)
var slug = text.toLowerCase().replace(/[\\s]+/g, '-');
if (tocStr.indexOf(slug) != -1)
slug += "-" + tocDumpIndex;
tocDumpIndex++;
tocStr += slug;
toc.push(
level: level,
slug: slug,
title: text
);
return "<h" + level + " id=\\"" + slug + "\\"><a href=\\"#" + slug + "\\" class=\\"anchor\\">" + '' +
'<svg aria-hidden="true" class="octicon octicon-link" height="16" version="1.1" viewBox="0 0 16 16" width="16"><path fill-rule="evenodd" d="M4 9h1v1H4c-1.5 0-3-1.69-3-3.5S2.55 3 4 3h4c1.45 0 3 1.69 3 3.5 0 1.41-.91 2.72-2 3.25V8.59c.58-.45 1-1.27 1-2.09C10 5.22 8.98 4 8 4H4c-.98 0-2 1.22-2 2.5S3 9 4 9zm9-3h-1v1h1c1 0 2 1.22 2 2.5S13.98 12 13 12H9c-.98 0-2-1.22-2-2.5 0-.83.42-1.64 1-2.09V6.25c-1.09.53-2 1.84-2 3.25C6 11.31 7.55 13 9 13h4c1.45 0 3-1.69 3-3.5S14.5 6 13 6z"></path></svg>' +
'' + "</a>" + text + "</h" + level + ">";
;同时需要加入下面的 css,以是标题的链接图片正常显示:
h1:hover .anchor, h2:hover .anchor, h3:hover .anchor, h4:hover .anchor, h5:hover .anchor, h6:hover .anchor
text-decoration: none
h1:hover .anchor .octicon-link, h2:hover .anchor .octicon-link, h3:hover .anchor .octicon-link, h4:hover .anchor .octicon-link, h5:hover .anchor .octicon-link, h6:hover .anchor .octicon-link
visibility: visible
.octicon
display: inline-block;
vertical-align: text-top;
fill: currentColor;
.anchor
float: left;
padding-right: 4px;
margin-left: -20px;
line-height: 1;
为了生成目录,我们只需按照保存的目录信息,生成 <ul> 和 <li> 标签即可,具体的可以参考源码中的实现。
配置页面锚链接
目录使用的是页内锚链接的方式进行跳转,如下面所示:
<a href="#h1">跳转到 H1</a>
...
<h1 id="h1">我是 H1</h1>
...默认情况下,页内锚链接跳转之后,目标标签(上面代码中的 <h1> )会移动到页面的最顶部,但是在我们的程序中有一个固定的 header,如果跳转到最顶部,目标标签会被 header 遮挡住,所以我们希望目标标签移动到距离页面顶部 header-height 的地方。为了实现我们的需要,只要加入下面的 css 代码即可。
:target:before
content:"";
display:block;
height:50px; /* fixed header height*/
margin:-50px 0 0; /* negative fixed header height */
Todo 列表
Todo 列表实际上就是 checkbox 的列表,完成的工作用选中的 checkbox 表示,未完成的工作用喂选中的列表表示,如下图所示:

一般来说,会将下面形式的 markdown 代码解析为 todo 列表
- [x] 完成
- [ ] 未完成
- [ ] 未完成为了实现这个功能,我们重写 marked 中解析列表的方法,加入对 todo 列表的支持。
renderer.listitem = function (text)
if (/^\\s*\\[[x ]\\]\\s*/.test(text))
text = text
.replace(/^\\s*\\[ \\]\\s*/, '<input type="checkbox" class="task-list-item-checkbox" disabled> ')
.replace(/^\\s*\\[x\\]\\s*/, '<input type="checkbox" class="task-list-item-checkbox" disabled checked> ');
return '<li style="list-style: none">' + text + '</li>';
else
return '<li>' + text + '</li>';
;同时加入下面的样式:
.task-list-item-checkbox
margin: 0 0.2em 0.25em -2.3em;
vertical-align: middle;
[type="checkbox"], [type="radio"]
box-sizing: border-box;
padding: 0;
缓存
现在的浏览器都已经支持 localStorage,可以方便的存储数据。localStorage 就是一个对象。我们存储数据就是直接给它添加一个属性,可以通过 localStoage["a"]=1 或者 localStorage.a = 1 的方式来存储数据,但是看起来总觉的不太优雅,因为一般使用下面的方式来操作 localStorage:
localStorage.setItem(key, vlaue);
localStorage.getItem(key);
localStorage.removeItem(key);另外 localStorage 也有一些局限,使用时需要注意:
- 存储空间有限制,一般是
5M左右,和浏览器有关 - 用户清除浏览器缓存之后有可能丢失本地缓存的数据
- 不能直接存对象,要先使用
JSON.stringfy方法将对象进行序列化处理之后再保存。使用时需要使用JSON.parse方法将字符串转为对象。
导出文件
通过使用 FileSaver.js,我们可以方便的在浏览器端生成文件,并提供给用户下载。使用方法也很简单:
var blob = new Blob([htmlContent], type: "text/html;charset=utf-8");
saveAs(blob, name);扩展
我们提供了一些扩展功能,用来更好的展示 markdown 内容。在现在的程序中我们可以很方便的添加扩展功能,下面会具体介绍。
自定义扩展
为了添加扩展,我们首先需要确定哪些内容需要作为扩展处理。因为在将 markdown 文件转为 html 的过程中,一般是不处理代码块中的内容的,所以我们使用代码块来存放扩展内容,通过代码块的语言来确定是哪种扩展。以添加序列图扩展为例:
确定时序图的代码标记

修改
marked中对于代码块的解析函数,添加对于时序图标记的支持
var renderer = new marked.Renderer();
var originalCodeFun = function (code, lang)
if (Setting.highlight == Constants.highlight)
return "<pre><code class='" + lang + "'>" + code + "</code></pre>";
return "<pre><code class='language-" + lang + "'>" + code + "</code></pre>";
;
renderer.code = function (code, language)
if (language == "seq")
return "<div class='diagram' id='diagram'>" + code + "</div>"
else
return originalCodeFun.call(this, code, language);
;
marked.setOptions(
renderer: renderer
);- 引入
js-sequence-diagrams相关文件
<link href=" bower directory /js-sequence-diagrams/dist/sequence-diagram-min.css" rel="stylesheet" />
<script src=" bower directory /bower-webfontloader/webfont.js" />
<script src=" bower directory /snap.svg/dist/snap.svg-min.js" />
<script src=" bower directory /underscore/underscore-min.js" />
<script src=" bower directory /js-sequence-diagrams/dist/sequence-diagram-min.js" />- 渲染 Markdown 文件时,调用相关函数
$(".diagram").sequenceDiagram(theme: 'simple');添加扩展会影响文件的渲染速度,如果不需要某个扩展可以手动关闭。
Mathjax
使用Mathjax 对数学公式进行支持。关于Mathjax 语法,请参考这里。下面是添加扩展的流程:
- 引入文件并配置
<script type="text/x-mathjax-config">
MathJax.Hub.Config(tex2jax: inlineMath: [['$','$'], ['\\\\(','\\\\)']],
TeX:
equationNumbers:
autoNumber: ["AMS"],
useLabelIds: true
,
"HTML-CSS":
linebreaks:
automatic: true
,
SVG:
linebreaks:
automatic: true
);
</script>
<script type="text/javascript" src="http://cdn.bootcss.com/mathjax/2.7.0/MathJax.js?config=TeX-AMS-MML_HTMLorMML"></script>- 将 markdown 文件转为 html 之后,调用 Mathjax 中的方法将对应标记转为数学公式。
// content 是需要处理的 html 标签的 id
MathJax.Hub.Queue(["Typeset", MathJax.Hub, "content"]);Emoji
使用 emojify.js 来提供对 Emoji 标签的支持。Emoji表情参见 EMOJI CHEAT SHEET。下面是添加扩展的流程
- 引用文件并配置
<script src="http://cdn.bootcss.com/emojify.js/1.1.0/js/emojify.min.js"></script>
<script type="text/javascript">
emojify.setConfig(
emojify_tag_type: 'div', // Only run emojify.js on this element
only_crawl_id: null, // Use to restrict where emojify.js applies
img_dir: 'http://cdn.bootcss.com/emojify.js/1.0/images/basic', // Directory for emoji images
ignored_tags: // Ignore the following tags
'SCRIPT': 1,
'TEXTAREA': 1,
'A': 1,
'PRE': 1,
'CODE': 1
);
</script>- 将 markdown 文件转为 html 之后,调用 emojify 中的方法将对应标记转换 emoji 表情。
emojify.run(document.getElementById('content'))图表 (ECharts)
使用 ECharts 来提供对图表的支持。ECharts 的语法可以参考 官网的示例。下面是使用方法:
确定 ECharts 在 markdown 中的语法标签

在 code 方法解析中添加对 echarts 的支持
renderer.code = function (code, language)
switch (language)
case "echarts":
if (Setting.echarts)
return loadEcharts(code);
return originalCodeFun.call(this, code, language);
;
function loadEcharts(text)
var width = "100%";
var height = "400px";
try
var options = eval("(" + text + ")");
if (options.hasOwnProperty("width"))
width = options["width"];
if (options.hasOwnProperty("height"))
height = options["height"];
echartIndex++;
echartData.push(
id: echartIndex,
option: options,
previousOption: text
);
return '<div id="echarts-' + echartIndex + '" style="width: ' + width + ';height:' + height + ';"></div>'
catch (e)
console.log(e);
return "";
- 将 markdown 文件转为 html 之后,调用 echarts 中的方法,将对应的 div 转为图表:
var chart;
echartData.forEach(function (data)
if (data.option.theme)
chart = echarts.init(document.getElementById('echarts-' + data.id), data.option.theme);
else
chart = echarts.init(document.getElementById('echarts-' + data.id));
chart.setOption(data.option);
);评论
在生成Github Page页面时,我们可以选择添加 多说 或者 Disqus 评论,其中多说就是在导出的页面中加入下面的代码
<div class="ds-thread" data-thread-key="" data-title="" data-url=""></div>
<script type="text/javascript">
var duoshuoQuery =
short_name: ""
;
(function()
var ds = document.createElement("script");
ds.type = "text/javascript";
ds.async = true;
ds.src = (document.location.protocol == "https:" ? "https:" : "http:") + "//static.duoshuo.com/embed.js";
ds.charset = "UTF-8";
(document.getElementsByTagName("head")[0] || document.getElementsByTagName("body")[0]).appendChild(ds);
)();
</script>其中 data-thread-key, data-title, data-url 和 short_name 是需要我们自定义的东西。而Disqus 需要在导出时插入下面的代码:
<div id="disqus_thread"></div>
<script type="text/javascript">
var disqus_shortname = '';
var prefix = document.location.protocol == "https:" ? "https:" : "http:"
var disqus_config = function()
this.page.url = "";
this.page.identifier = ""
;
(function()
var d = document,
s = d.createElement('script');
s.src = prefix + '//' + disqus_shortname + '.disqus.com/embed.js';
s.setAttribute('data-timestamp', +new Date());
(d.head || d.body).appendChild(s);
)();
</script>其中 disqus_shortname, page.url 和 page.indertifier 是需要我们自定义的东西。这里需要注意的是 page.url 要使用绝对路径。
具体的插入逻辑可参考源码的实现,这里不再赘述。
以上是关于应用Markdown 在线阅读器的主要内容,如果未能解决你的问题,请参考以下文章