python爬虫做好了怎么用pandas保存为excle文件?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫做好了怎么用pandas保存为excle文件?相关的知识,希望对你有一定的参考价值。
import requestsimport randomimport timedef updata_cookies(url,my_hearders): s = requests.Session() s.get(my_headers['Referer'], headers=my_headers) cookies = s.cookies return cookiesdef crawler(req_url,my_headers,cookies,qs_params,form_data): req_result=requests.post(req_url,headers=my_headers,cookies=cookies,params=qs_params,data=form_data) result=req_result.json() position_infos=result['content']['positionResult']['result'] pn=form_data['pn'] for i in range(len(position_infos)): print("-------------第%s页第%s个电子工程师相关的职位的信息--------------"%(pn,i+1)) print("职位名称是:".format(position_infos[i]['positionName'])) print('公司名称是:'.format(position_infos[i]['companyShortName'])) print("薪资是:".format(position_infos[i]['salary']))if __name__=="__main__": req_url='url信息' my_headers= 'User-agent':'user信息', 'Referer':'referer信息', qs_params = 'needAddtionalResult': 'false'for i in range(1,6): if i==1: form_data_1='first':True,'kd':'电子工程师','pn':1 number=random.randint(10,30) time.sleep(number) cookies=updata_cookies(my_headers['Referer'],my_headers) crawler(req_url,my_headers,cookies,qs_params,form_data_1) else: form_data_i='first':'false','kd':'电子工程师','pn':i number=random.randitn(10,30) cookies = updata_cookies(my_headers['Referer'], my_headers) crawler(req_url, my_headers, cookies, qs_params, form_data_i)
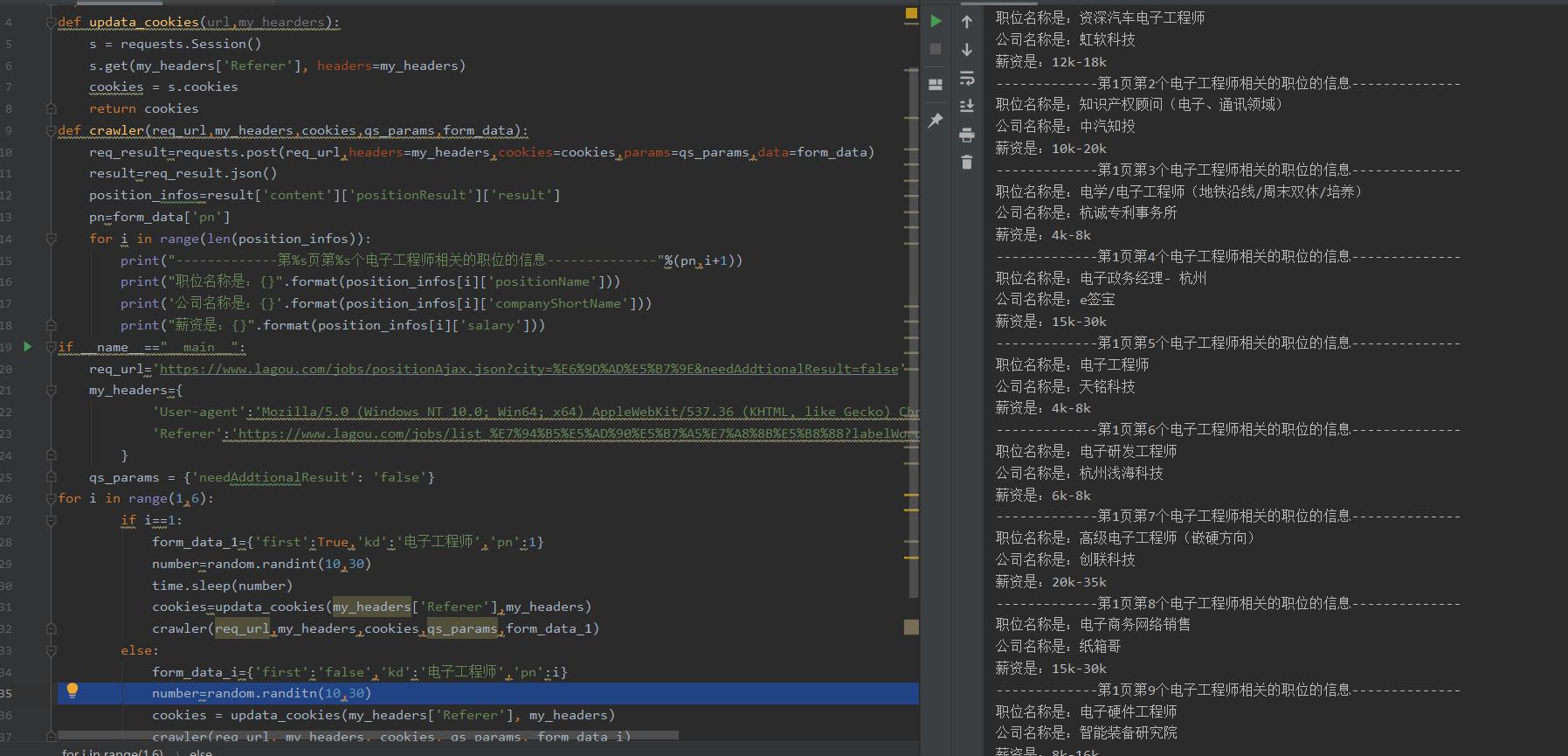
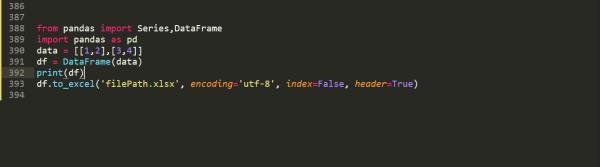
怎么把爬到的信息放到data?
本回答被提问者采纳以上是关于python爬虫做好了怎么用pandas保存为excle文件?的主要内容,如果未能解决你的问题,请参考以下文章