4.kafka消费者源码初探
Posted do__something
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了4.kafka消费者源码初探相关的知识,希望对你有一定的参考价值。
目录
4. kafka消费者源码初探
4.1 kafka消费者基本原理
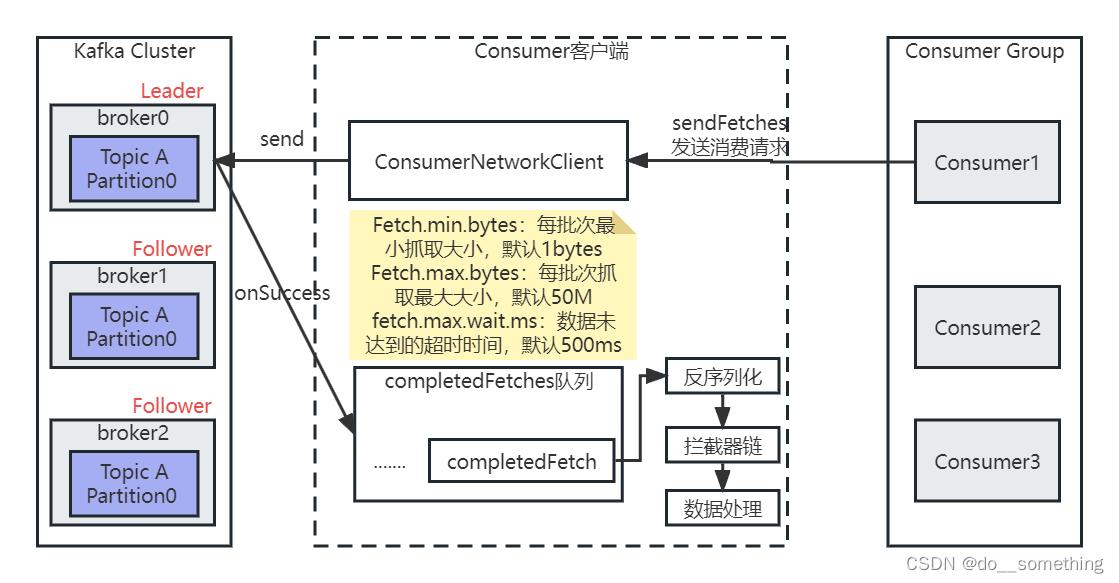
kafka是通过pull(拉)模式从服务端数据,其流程其实就是客户端不断循环向服务端发送网络请求,通过回调函数获取数据、处理数据的过程,大致流程如图:
4.2 消费者源码
4.2.1 示例代码
public class ConsumerFastAnalysis
public static final String brokerList = "hadoop101:9092";
public static final String topic = "topic-demo";
public static final String groupId = "group.demo";
public static void main(String[] args)
//配置消费者客户端参数
Properties properties = new Properties();
properties.put("key.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
properties.put("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
properties.put("bootstrap.servers", brokerList);
properties.put("group.id", groupId);
//kafka消费者
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
//订阅主题
consumer.subscribe(Collections.singletonList(topic));
while (true)
//拉取消息
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records)
System.out.println("消费到的消息:" + record.value());
由示例代码可以看出,消费者正常消费逻辑大体可以分为三步:
①配置消费者客户端参数及创建相应的消费者实例(KafkaConsumer初始化)
②订阅主题
③拉取消息并消费
4.2.2 KafkaConsumer初始化
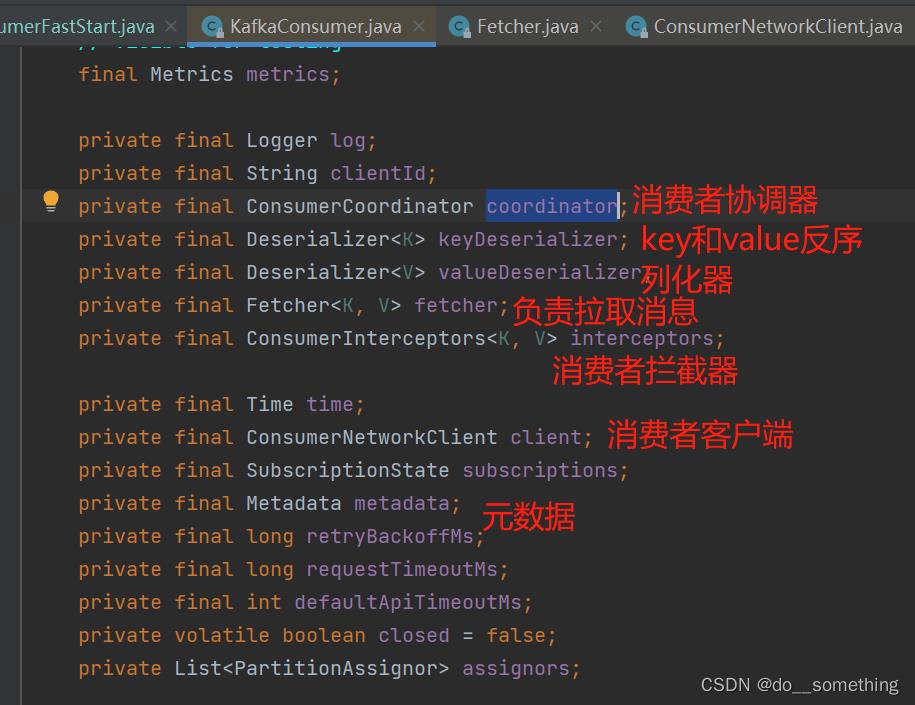
同KafkaProducer初始化原理相同,KafkaConsumer初始化也是读取用户自定义的配置,然后封装为具有不同功能的java对象,KafkaConsumer持有这些对象,完成消费者功能:
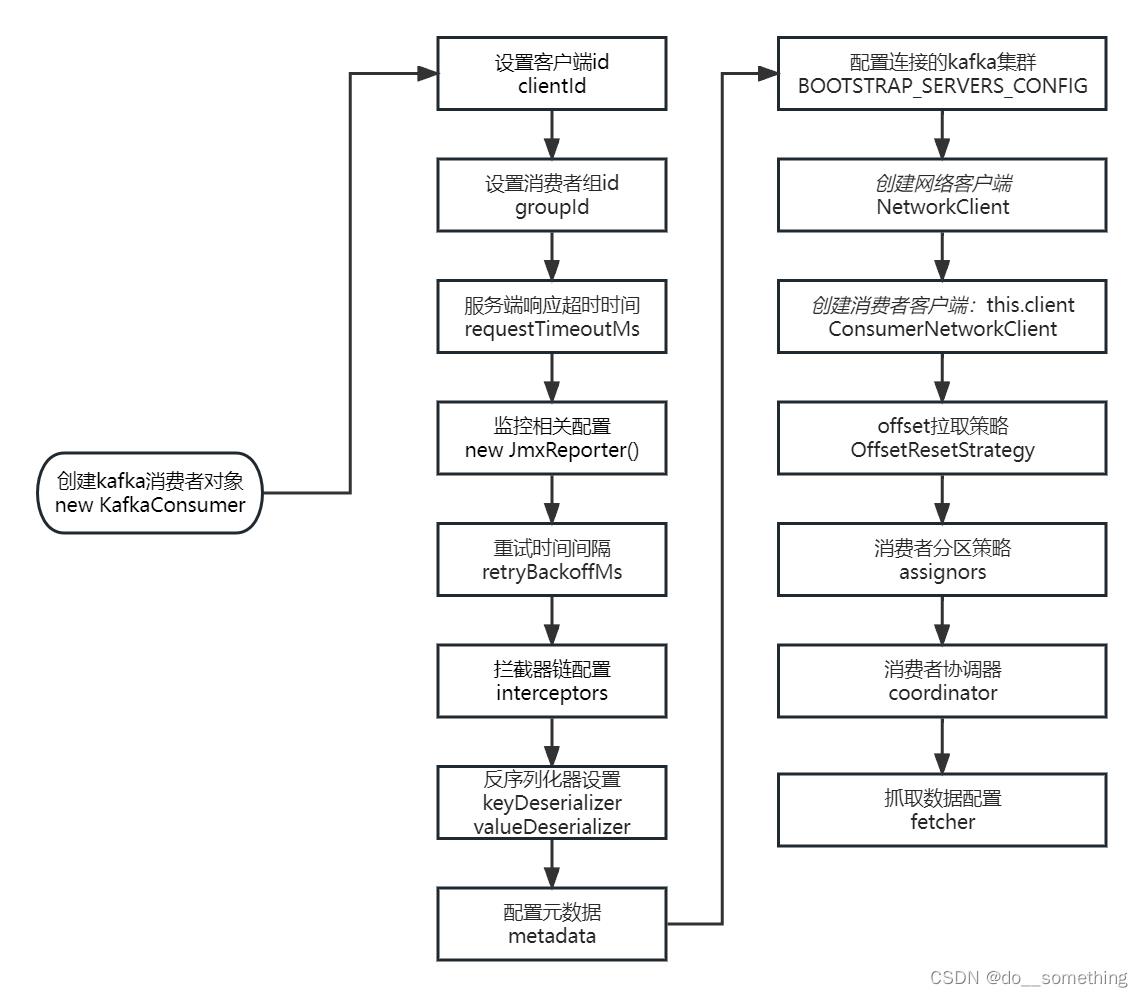
KafkaConsumer初始化大致流程如下:
源码解析:
private KafkaConsumer(ConsumerConfig config,
Deserializer<K> keyDeserializer,
Deserializer<V> valueDeserializer)
try
//设置客户端id
String clientId = config.getString(ConsumerConfig.CLIENT_ID_CONFIG);
if (clientId.isEmpty())
clientId = "consumer-" + CONSUMER_CLIENT_ID_SEQUENCE.getAndIncrement();
this.clientId = clientId;
//设置消费者组id
String groupId = config.getString(ConsumerConfig.GROUP_ID_CONFIG);
LogContext logContext = new LogContext("[Consumer clientId=" + clientId + ", groupId=" + groupId + "] ");
this.log = logContext.logger(getClass());
log.debug("Initializing the Kafka consumer");
//等待服务端响应的最大时间,默认30s
this.requestTimeoutMs = config.getInt(ConsumerConfig.REQUEST_TIMEOUT_MS_CONFIG);
this.defaultApiTimeoutMs = config.getInt(ConsumerConfig.DEFAULT_API_TIMEOUT_MS_CONFIG);
this.time = Time.SYSTEM;
Map<String, String> metricsTags = Collections.singletonMap("client-id", clientId);
MetricConfig metricConfig = new MetricConfig().samples(config.getInt(ConsumerConfig.METRICS_NUM_SAMPLES_CONFIG))
.timeWindow(config.getLong(ConsumerConfig.METRICS_SAMPLE_WINDOW_MS_CONFIG), TimeUnit.MILLISECONDS)
.recordLevel(Sensor.RecordingLevel.forName(config.getString(ConsumerConfig.METRICS_RECORDING_LEVEL_CONFIG)))
.tags(metricsTags);
List<MetricsReporter> reporters = config.getConfiguredInstances(ConsumerConfig.METRIC_REPORTER_CLASSES_CONFIG,
MetricsReporter.class);
reporters.add(new JmxReporter(JMX_PREFIX));
this.metrics = new Metrics(metricConfig, reporters, time);
//重试时间间隔,默认100ms
this.retryBackoffMs = config.getLong(ConsumerConfig.RETRY_BACKOFF_MS_CONFIG);
// load interceptors and make sure they get clientId
Map<String, Object> userProvidedConfigs = config.originals();
userProvidedConfigs.put(ConsumerConfig.CLIENT_ID_CONFIG, clientId);
//拦截器配置
List<ConsumerInterceptor<K, V>> interceptorList = (List) (new ConsumerConfig(userProvidedConfigs, false)).getConfiguredInstances(ConsumerConfig.INTERCEPTOR_CLASSES_CONFIG,
ConsumerInterceptor.class);
this.interceptors = new ConsumerInterceptors<>(interceptorList);
//key和value反序列化配置
if (keyDeserializer == null)
this.keyDeserializer = config.getConfiguredInstance(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
Deserializer.class);
this.keyDeserializer.configure(config.originals(), true);
else
config.ignore(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG);
this.keyDeserializer = keyDeserializer;
if (valueDeserializer == null)
this.valueDeserializer = config.getConfiguredInstance(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
Deserializer.class);
this.valueDeserializer.configure(config.originals(), false);
else
config.ignore(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG);
this.valueDeserializer = valueDeserializer;
ClusterResourceListeners clusterResourceListeners = configureClusterResourceListeners(keyDeserializer, valueDeserializer, reporters, interceptorList);
//配置元数据
this.metadata = new Metadata(retryBackoffMs, config.getLong(ConsumerConfig.METADATA_MAX_AGE_CONFIG),
true, false, clusterResourceListeners);
//配置连接的kafka集群
List<InetSocketAddress> addresses = ClientUtils.parseAndValidateAddresses(config.getList(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG));
this.metadata.update(Cluster.bootstrap(addresses), Collections.<String>emptySet(), 0);
String metricGrpPrefix = "consumer";
ConsumerMetrics metricsRegistry = new ConsumerMetrics(metricsTags.keySet(), "consumer");
ChannelBuilder channelBuilder = ClientUtils.createChannelBuilder(config);
IsolationLevel isolationLevel = IsolationLevel.valueOf(
config.getString(ConsumerConfig.ISOLATION_LEVEL_CONFIG).toUpperCase(Locale.ROOT));
Sensor throttleTimeSensor = Fetcher.throttleTimeSensor(metrics, metricsRegistry.fetcherMetrics);
//心跳时间,默认3s
int heartbeatIntervalMs = config.getInt(ConsumerConfig.HEARTBEAT_INTERVAL_MS_CONFIG);
//创建网络客户端
NetworkClient netClient = new NetworkClient(
new Selector(config.getLong(ConsumerConfig.CONNECTIONS_MAX_IDLE_MS_CONFIG), metrics, time, metricGrpPrefix, channelBuilder, logContext),
this.metadata,
clientId,
100, // a fixed large enough value will suffice for max in-flight requests
config.getLong(ConsumerConfig.RECONNECT_BACKOFF_MS_CONFIG),
config.getLong(ConsumerConfig.RECONNECT_BACKOFF_MAX_MS_CONFIG),
config.getInt(ConsumerConfig.SEND_BUFFER_CONFIG),
config.getInt(ConsumerConfig.RECEIVE_BUFFER_CONFIG),
config.getInt(ConsumerConfig.REQUEST_TIMEOUT_MS_CONFIG),
time,
true,
new ApiVersions(),
throttleTimeSensor,
logContext);
//创建消费者客户端
this.client = new ConsumerNetworkClient(
logContext,
netClient,
metadata,
time,
retryBackoffMs,
config.getInt(ConsumerConfig.REQUEST_TIMEOUT_MS_CONFIG),
heartbeatIntervalMs); //Will avoid blocking an extended period of time to prevent heartbeat thread starvation
//offset的拉取策略(offset从什么位置开始拉取,默认是latest)
OffsetResetStrategy offsetResetStrategy = OffsetResetStrategy.valueOf(config.getString(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG).toUpperCase(Locale.ROOT));
this.subscriptions = new SubscriptionState(offsetResetStrategy);
//消费者分区的分配策略(默认为RangeAssignor :范围分区分配策略)
//RangeAssignor:以单个Topic为维度来分配, 只负责将每一个Topic的分区尽可能均衡的分配给消费者
this.assignors = config.getConfiguredInstances(
ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,
PartitionAssignor.class);
int maxPollIntervalMs = config.getInt(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG);
int sessionTimeoutMs = config.getInt(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG);
//创建消费者协调器(自动提交offset的时间间隔,默认为5s)
this.coordinator = new ConsumerCoordinator(logContext,
this.client,
groupId,
maxPollIntervalMs,
sessionTimeoutMs,
new Heartbeat(sessionTimeoutMs, heartbeatIntervalMs, maxPollIntervalMs, retryBackoffMs),
assignors,
this.metadata,
this.subscriptions,
metrics,
metricGrpPrefix,
this.time,
retryBackoffMs,
config.getBoolean(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG),
config.getInt(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG),
this.interceptors,
config.getBoolean(ConsumerConfig.EXCLUDE_INTERNAL_TOPICS_CONFIG),
config.getBoolean(ConsumerConfig.LEAVE_GROUP_ON_CLOSE_CONFIG));
//抓取数据配置
//一次抓取最小值,默认1个字节
//一次抓取最大值,默认50m
//一次抓取最大等待时间,默认500ms
//每个分区抓取最大字节数,默认1m
//一次poll拉取数据返回消息最大条数,默认500条
//key和value的序列化
this.fetcher = new Fetcher<>(
logContext,
this.client,
config.getInt(ConsumerConfig.FETCH_MIN_BYTES_CONFIG),
config.getInt(ConsumerConfig.FETCH_MAX_BYTES_CONFIG),
config.getInt(ConsumerConfig.FETCH_MAX_WAIT_MS_CONFIG),
config.getInt(ConsumerConfig.MAX_PARTITION_FETCH_BYTES_CONFIG),
config.getInt(ConsumerConfig.MAX_POLL_RECORDS_CONFIG),
config.getBoolean(ConsumerConfig.CHECK_CRCS_CONFIG),
this.keyDeserializer,
this.valueDeserializer,
this.metadata,
this.subscriptions,
metrics,
metricsRegistry.fetcherMetrics,
this.time,
this.retryBackoffMs,
this.requestTimeoutMs,
isolationLevel);
config.logUnused();
AppInfoParser.registerAppInfo(JMX_PREFIX, clientId, metrics);
log.debug("Kafka consumer initialized");
catch (Throwable t)
// call close methods if internal objects are already constructed
// this is to prevent resource leak. see KAFKA-2121
close(0, true);
// now propagate the exception
throw new KafkaException("Failed to construct kafka consumer", t);
4.2.3 订阅主题
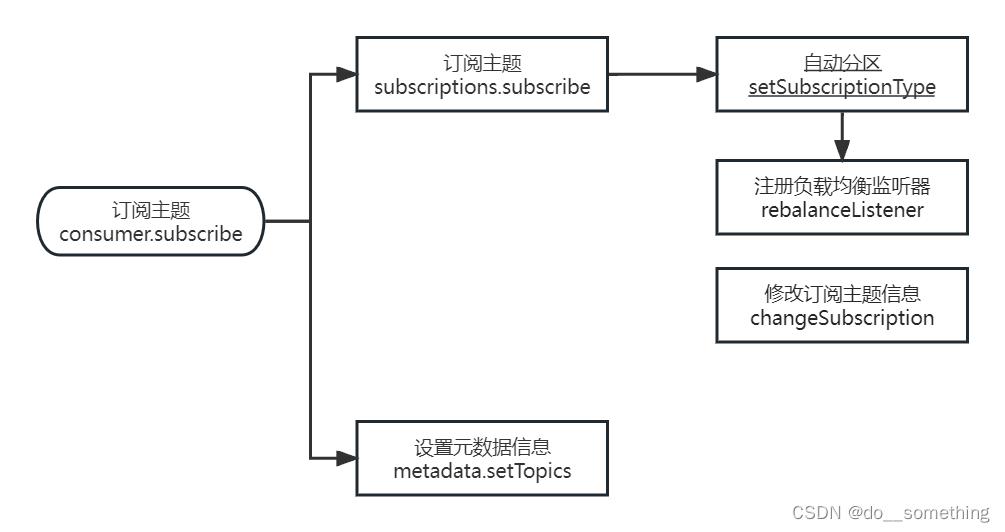
订阅主题主要逻辑就是将主题信息维护在元数据(metadata)中,并且注册一个负载均衡监听器(eg:消费者组中新增/减少消费者会触发该监听器),流程如图:
//之前的所有逻辑是对主题topics和消费者再均衡监听器ConsumerRebalanceListener的合法性检验
//订阅主题
this.subscriptions.subscribe(new HashSet<>(topics), listener);
//设置元数据信息
metadata.setTopics(subscriptions.groupSubscription());
订阅主题代码:
public void subscribe(Set<String> topics, ConsumerRebalanceListener listener)
if (listener == null)
throw new IllegalArgumentException("RebalanceListener cannot be null");
//按照设置的主题开始订阅,自动分配分区
setSubscriptionType(SubscriptionType.AUTO_TOPICS);
//注册负载均衡监听(例如在消费者组中,其他消费者退出触发再平衡)
this.rebalanceListener = listener;
//修改订阅主题信息
changeSubscription(topics);
4.2.4 拉取消息消费
consumer.poll()方法中,拉取消息消费的内部代码封装为了三个方法:
①updateAssignmentMetadataIfNeeded:主要目的是找到可用的消费者协调器(coordinator),更新fetcher拉取消息的位移
②pollForFetches:发送请求拉取数据
③this.interceptors.onConsume:调用拦截器链处理数据
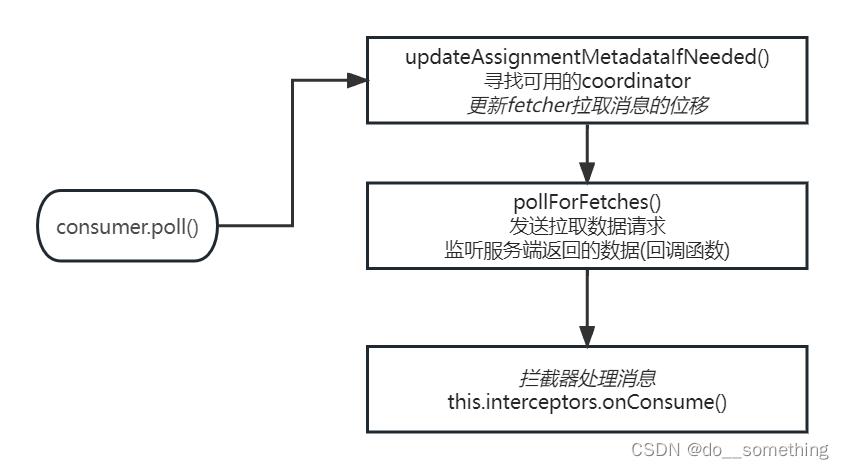
(1)先看updateAssignmentMetadataIfNeeded方法
boolean updateAssignmentMetadataIfNeeded(final long timeoutMs)
final long startMs = time.milliseconds();
//循环给服务端发请求,直到找到coordinator
if (!coordinator.poll(timeoutMs))
return false;
//更新fetcher拉取消息的位移
return updateFetchPositions(remainingTimeAtLeastZero(timeoutMs, time.milliseconds() - startMs));
public boolean poll(final long timeoutMs)
final long startTime = time.milliseconds();
long currentTime = startTime;
long elapsed = 0L;
if (subscriptions.partitionsAutoAssigned())
//发送一次心跳
pollHeartbeat(currentTime);
if (coordinatorUnknown())
//保证coordinator正常通信(寻找服务器端的coordinator)
if (!ensureCoordinatorReady(remainingTimeAtLeastZero(timeoutMs, elapsed)))
return false;
currentTime = time.milliseconds();
elapsed = currentTime - startTime;
以上是关于4.kafka消费者源码初探的主要内容,如果未能解决你的问题,请参考以下文章