线程池
Posted 我可能是个假开发
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了线程池相关的知识,希望对你有一定的参考价值。
Java 语言中创建线程看上去就像创建一个对象一样简单,只需要 new Thread() 就可以了,但实际上创建线程远不是创建一个对象那么简单。
创建对象,仅仅是在 JVM 的堆里分配一块内存而已;而创建一个线程,却需要调用操作系统内核的 API,然后操作系统要为线程分配一系列的资源,这个成本就很高了,所以线程是一个重量级的对象,应该避免频繁创建和销毁。
一、线程池是一种生产者 - 消费者模式
线程池的使用方是生产者,线程池本身是消费者。
//简化的线程池,仅用来说明工作原理
class MyThreadPool
//利用阻塞队列实现生产者-消费者模式
BlockingQueue<Runnable> workQueue;
//保存内部工作线程
List<WorkerThread> threads = new ArrayList<>();
// 构造方法
MyThreadPool(int poolSize, BlockingQueue<Runnable> workQueue)
this.workQueue = workQueue;
// 创建工作线程
for(int idx=0; idx<poolSize; idx++)
WorkerThread work = new WorkerThread();
work.start();
threads.add(work);
// 提交任务
void execute(Runnable command)
workQueue.put(command);
// 工作线程负责消费任务,并执行任务
class WorkerThread extends Thread
public void run()
//循环取任务并执行
while(true) ①
Runnable task = workQueue.take();
task.run();
/** 下面是使用示例 **/
// 创建有界阻塞队列
BlockingQueue<Runnable> workQueue = new LinkedBlockingQueue<>(2);
// 创建线程池
MyThreadPool pool = new MyThreadPool(10, workQueue);
// 提交任务
pool.execute(()->
System.out.println("hello");
);
在 MyThreadPool 的内部,我们维护了一个阻塞队列 workQueue 和一组工作线程,工作线程的个数由构造函数中的 poolSize 来指定。用户通过调用 execute() 方法来提交 Runnable 任务,execute() 方法的内部实现仅仅是将任务加入到 workQueue 中。MyThreadPool 内部维护的工作线程会消费 workQueue 中的任务并执行任务,相关的代码就是代码①处的 while 循环。
二、使用 Java 中的线程池
Java 提供的线程池相关的工具类中,最核心的是 ThreadPoolExecutor,通过名字你也能看出来,它强调的是 Executor,而不是一般意义上的池化资源。
ThreadPoolExecutor 的构造函数非常复杂,如下面代码所示,这个最完备的构造函数有 7 个参数。
ThreadPoolExecutor(
int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
- corePoolSize:线程池保有的最小线程数。有些项目很闲,但是也不能把所有线程都撤了,至少要留 corePoolSize 个线程坚守阵地。
- maximumPoolSize:线程池创建的最大线程数。当项目很忙时,就需要加线程,但是也不能无限制地加,最多就加到 maximumPoolSize 个线程。当项目闲下来时,就要回收线程了,最多能回收到剩下 corePoolSize 个线程为止。
- keepAliveTime & unit:最大空闲时间。一个线程如果在一段时间内,都没有执行任务,说明很闲,keepAliveTime 和 unit 就是用来定义这个“一段时间”的参数。也就是说,如果一个线程空闲了keepAliveTime & unit这么久,而且线程池的线程数大于 corePoolSize ,那么这个空闲的线程就要被回收了。
- workQueue:工作队列。
- threadFactory:通过这个参数可以自定义如何创建线程,例如可以给线程指定一个有意义的名字。
- handler:通过这个参数可以自定义任务的拒绝策略。如果线程池中所有的线程都在忙碌,并且工作队列也满了(前提是工作队列是有界队列),那么此时提交任务,线程池就会拒绝接收。拒绝的策略,可以通过 handler 这个参数来指定。
ThreadPoolExecutor 已经提供了以下 4 种拒绝策略:
- CallerRunsPolicy:提交任务的线程自己去执行该任务。
- AbortPolicy:默认的拒绝策略,会 throws RejectedExecutionException。
- DiscardPolicy:直接丢弃任务,没有任何异常抛出。
- DiscardOldestPolicy:丢弃最老的任务,把最早进入工作队列的任务丢弃,然后把新任务加入到工作队列。
Java 在 1.6 版本还增加了 allowCoreThreadTimeOut(boolean value) 方法,它可以让所有线程都支持超时,这意味着如果项目很闲,就会将项目组的成员都撤走。
三、使用线程池要注意的事项
考虑到 ThreadPoolExecutor 的构造函数实在是有些复杂,所以 Java 并发包里提供了一个线程池的静态工厂类 Executors,利用 Executors 你可以快速创建线程池。不过目前大厂的编码规范中基本上都不建议使用 Executors 了。
1.不建议使用Executors
不建议使用 Executors 的最重要的原因是:Executors 提供的很多方法默认使用的都是无界的 LinkedBlockingQueue,高负载情境下,无界队列很容易导致 OOM,而 OOM 会导致所有请求都无法处理,这是致命问题。所以强烈建议使用有界队列。
2.建议使用有界队列
使用有界队列,当任务过多时,线程池会触发执行拒绝策略,线程池默认的拒绝策略会 throw RejectedExecutionException 这是个运行时异常,对于运行时异常编译器并不强制 catch 它,所以开发人员很容易忽略。因此默认拒绝策略要慎重使用。如果线程池处理的任务非常重要,建议自定义自己的拒绝策略;并且在实际工作中,自定义的拒绝策略往往和降级策略配合使用。
3.合理的处理异常
使用线程池,还要注意异常处理的问题,例如通过 ThreadPoolExecutor 对象的 execute() 方法提交任务时,如果任务在执行的过程中出现运行时异常,会导致执行任务的线程终止;不过,最致命的是任务虽然异常了,但是你却获取不到任何通知,这会让你误以为任务都执行得很正常。虽然线程池提供了很多用于异常处理的方法,但是最稳妥和简单的方案还是捕获所有异常并按需处理。
try
//业务逻辑
catch (RuntimeException x)
//按需处理
catch (Throwable x)
//按需处理
四、设置合适的线程数
使用多线程,本质上就是提升程序性能。
1.度量性能
度量性能的指标有很多,但是有两个指标是最核心的:
- 延迟:发出请求到收到响应这个过程的时间,延迟越短,意味着程序执行得越快,性能也就越好
- 吞吐量:单位时间内能处理请求的数量;吞吐量越大,意味着程序能处理的请求越多,性能也就越好。
这两个指标内部有一定的联系(同等条件下,延迟越短,吞吐量越大),但是由于它们隶属不同的维度(一个是时间维度,一个是空间维度),并不能互相转换。
所谓提升性能,从度量的角度,主要是降低延迟,提高吞吐量。
2.提升性能
要想“降低延迟,提高吞吐量”,对应的方法:
- 优化算法:
- 将硬件的性能发挥到极致。
在并发编程领域,提升性能本质上就是提升硬件的利用率,再具体点来说,就是提升 I/O 的利用率和 CPU 的利用率。
3.CPU 和 I/O 设备综合利用率
操作系统已经解决了磁盘和网卡的利用率问题,利用中断机制还能避免 CPU 轮询 I/O 状态,也提升了 CPU 的利用率。但是操作系统解决硬件利用率问题的对象往往是单一的硬件设备,并发程序,往往需要 CPU 和 I/O 设备相互配合工作,也就是说,需要解决 CPU 和 I/O 设备综合利用率的问题。关于这个综合利用率的问题,操作系统虽然没有办法完美解决,但是却给我们提供了方案,那就是:多线程。
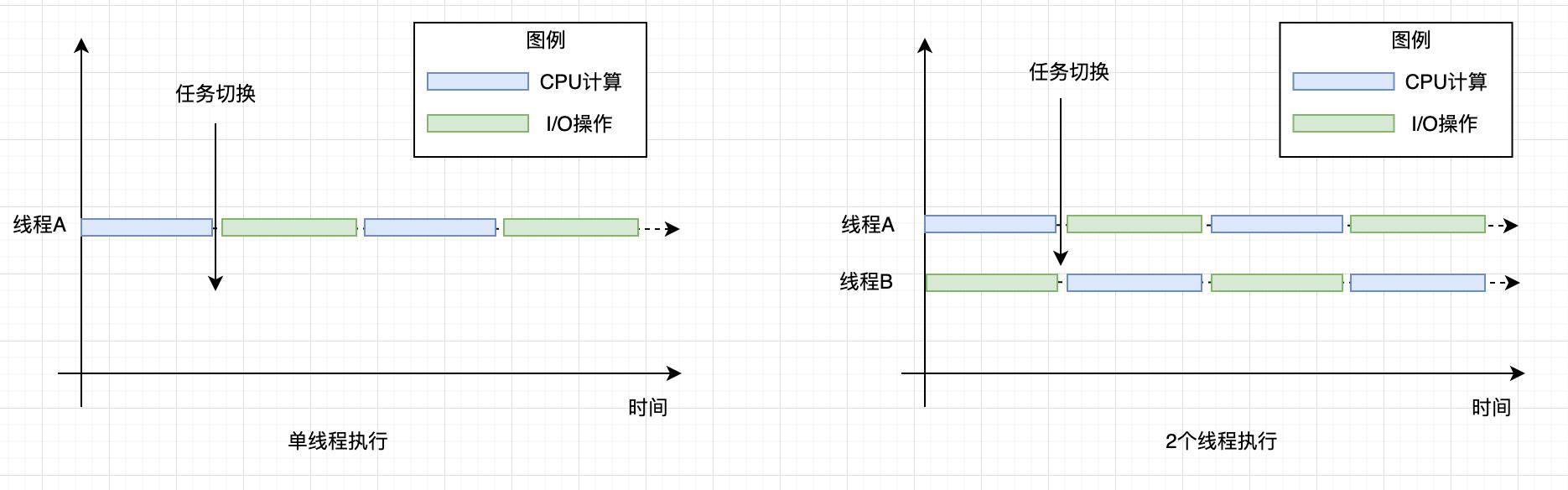
只有一个线程,执行 CPU 计算的时候,I/O 设备空闲;执行 I/O 操作的时候,CPU 空闲,所以 CPU 的利用率和 I/O 设备的利用率都是 50%。
两个线程,当线程 A 执行 CPU 计算的时候,线程 B 执行 I/O 操作;当线程 A 执行 I/O 操作的时候,线程 B 执行 CPU 计算,这样 CPU 的利用率和 I/O 设备的利用率就都达到了 100%。
在单核时代,多线程主要就是用来平衡 CPU 和 I/O 设备的。如果程序只有 CPU 计算,而没有 I/O 操作的话,多线程不但不会提升性能,还会使性能变得更差,原因是增加了线程切换的成本。但是在多核时代,这种纯计算型的程序也可以利用多线程来提升性能。因为利用多核可以降低响应时间。
计算 1+2+… … +100 亿的值:
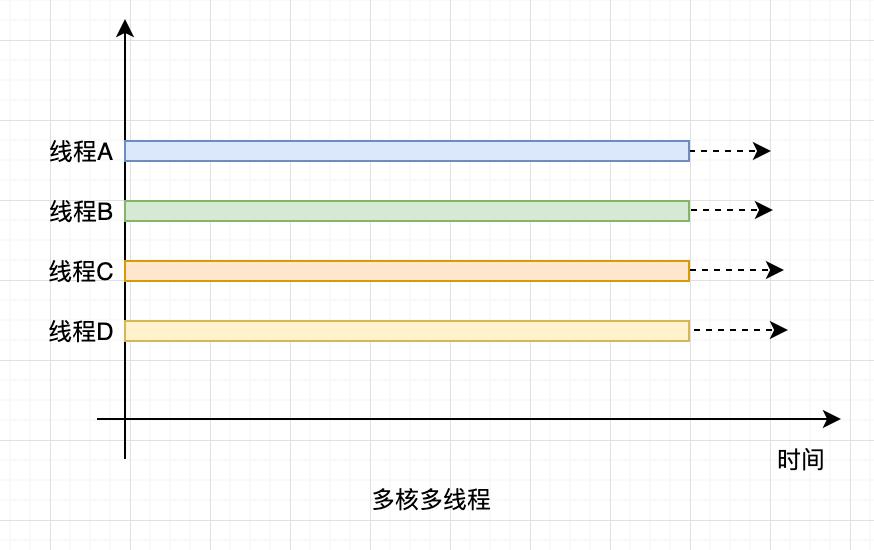
如果在 4 核的 CPU 上利用 4 个线程执行,线程 A 计算[1,25 亿),线程 B 计算[25 亿,50 亿),线程 C 计算[50,75 亿),线程 D 计算[75 亿,100 亿],之后汇总,那么理论上应该比一个线程计算[1,100 亿]快将近 4 倍,响应时间能够降到 25%。一个线程,对于 4 核的 CPU,CPU 的利用率只有 25%,而 4 个线程,则能够将 CPU 的利用率提高到 100%。
4.创建多少线程合适
I/O 密集型:I/O 操作执行的时间相对于 CPU 计算来说都非常长
CPU 密集型:纯 CPU 计算
对于 CPU 密集型计算,多线程本质上是提升多核 CPU 的利用率,所以对于一个 4 核的 CPU,每个核一个线程,理论上创建 4 个线程就可以了,再多创建线程也只是增加线程切换的成本。所以,对于 CPU 密集型的计算场景,理论上“线程的数量 =CPU 核数”就是最合适的。不过在工程上,线程的数量一般会设置为“CPU 核数 +1”,这样的话,当线程因为偶尔的内存页失效或其他原因导致阻塞时,这个额外的线程可以顶上,从而保证 CPU 的利用率。
对于 I/O 密集型的计算场景,如果 CPU 计算和 I/O 操作的耗时是 1:1,那么 2 个线程是最合适的。如果 CPU 计算和 I/O 操作的耗时是 1:2,那3个线程是最合适的。
如下图所示:CPU 在 A、B、C 三个线程之间切换,对于线程 A,当 CPU 从 B、C 切换回来时,线程 A 正好执行完 I/O 操作。这样 CPU 和 I/O 设备的利用率都达到了 100%。
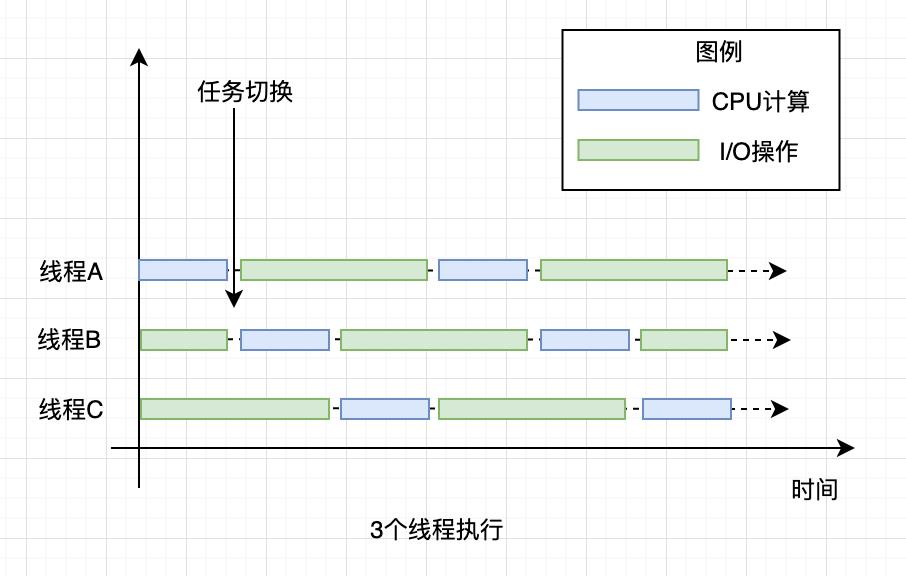
总结:
- 单核CPU:最佳线程数 =1 +(I/O 耗时 / CPU 耗时)
- 多核CPU:最佳线程数 =CPU 核数 * [ 1 +(I/O 耗时 / CPU 耗时)]
以上是关于线程池的主要内容,如果未能解决你的问题,请参考以下文章