美团2面:如何保障 MySQL 和 Redis 数据一致性?这样答,让面试官爱到 死去活来
Posted 40岁资深老架构师尼恩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了美团2面:如何保障 MySQL 和 Redis 数据一致性?这样答,让面试官爱到 死去活来相关的知识,希望对你有一定的参考价值。
美团2面:如何保障 mysql 和 Redis 的数据一致性?
说在前面
在尼恩的(50+)读者社群中,经常遇到一个 非常、非常高频的一个面试题,但是很不好回答,类似如下:
- 如何保障 MySQL 和 Redis 的数据一致性?
- 如何保障 MySQL 和 Cache 的数据一致性?
最近,有个小伙伴美团,2面又遇到了这个问题。
这里,尼恩基于自己的《Java高并发核心编程 卷3加强版》(注意是加强版),以及自己的 3高架构知识体系(3高架构宇宙),给大家梳理一个科书式的答案。
通过此答案,使得大家可以充分展示一下大家雄厚的 “技术肌肉”,让面试官爱到 “不能自已、口水直流”。也一并把题目以及参考答案,收入咱们的《尼恩Java面试宝典》 V55,供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。
注:本文以 PDF 持续更新,最新尼恩 架构笔记、面试题 的PDF文件,请从这里获取:码云
首先,什么是Cache-Aside Pattern(旁路缓存模式)?
Cache-Aside Pattern(旁路缓存)模式,又叫旁路路由策略,在这种模式中,读取缓存、读取数据库和更新缓存的操作都是在应用程序中完成。此模式是业务系统最常用的缓存策略。
旁路缓存又模式分为读缓存和写缓存。
旁路缓存模式在读的时候,先读缓存,缓存命中的话,直接返回数据;如果缓存没有命中的话,就去读数据库,从数据库取出数据,放入缓存后,同时返回响应。
Cache-Aside Pattern(旁路缓存)模式读操作流程,具体如下:
step 1:应用程序接收用户的数据查询的请求;
step 2:应用程序优先从缓存查找数据;
step 3:如果存在(cache hit),从缓存上查询出来,返回查询到数据;
Step 4:如果不存在(cache miss),从数据库中查询数据并存入缓存中,返回查询到数据。
Cache-Aside Pattern(旁路缓存)模式读操作流程,具体如下图所示:
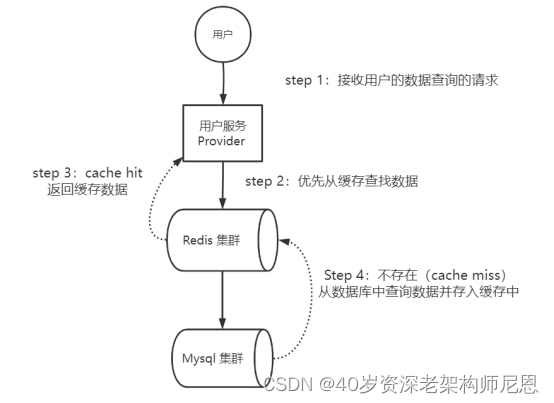
图:Cache-Aside Pattern(旁路缓存)模式读操作流程
Cache-Aside Pattern(旁路缓存)模式写操作流程,具体如下:
step 1:接收用户的数据写入的请求;
step 2:先写入数据库;
step 3:再写入缓存。
Cache-Aside Pattern(旁路缓存)模式写操作流程,具体如下图所示:
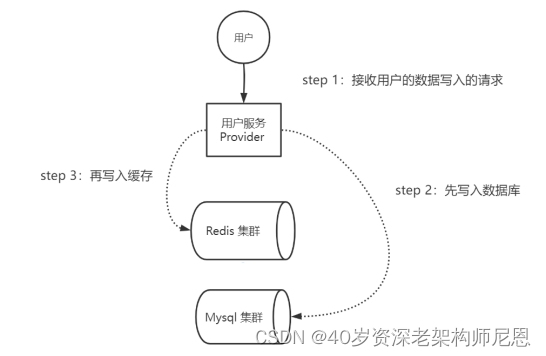
图:Cache-Aside Pattern(旁路缓存)模式写操作流程
数据什么时候从数据库(如Mysql集群)加载到缓存(如Redis集群)呢?有以下两种加载模式可被选择:懒汉模式、饿汉模式。懒汉模式、饿汉模式可以理解为及时加载模式、延迟加载模式。
所谓懒汉模式,就会在使用时临时加载缓存。具体来说,就是当需要使用数据时,就从数据库中把它查询出来,然后写入缓存。第一次查询之后,后续的请求都能从缓存中查询到数据。
所谓饿汉模式,就是提前预加载缓存。具体来说,在项目启动的时候,预加载数据到缓存。当需要使用数据时,能直接从缓存获取数据,而不需要从数据获取。
饿汉模式,提前预加载数据到缓存的时机,能极大地提升请求处理的性能力,极大地提升系统的吞吐量。此模式,适合于缓存那些不是经常变更的数据(例如商品类目数据),或者那些访问非常频繁的极热数据(例如秒杀商品数据)。
说 明
懒汉模式、饿汉模式这组名词来自于Java的单例模式,关于Java的单例模式的详细介绍,请参考《Java高并发核心编程 卷2加强版》 (注意,是加强版)。
Cache-Aside如何保证双写的数据一致性?
Cache-Aside是日常开发中使用最多的缓存层高并发访问模式。所以,面试官也喜欢围绕这种模式进行发问。一个非常高频的问题是:Cache-Aside在写入的时候,为什么是删除缓存而不是更新缓存呢。而且,很多大厂也喜欢问这个领域的问题,下面就是一道来自于社群的美团真题。
美团面试题
Cache-Aside如何保证DB和Cache双写的数据一致性?
要完美的回答这个问题,咱们把Cache-Aside模式(旁路缓存模式)下的DB和Cache双写的策略,做一个系统化的梳理,大概分为如下五大策略。
-
策略一:先更数据库,再更缓存
-
策略二:先删缓存,再更新数据库
-
策略三:先更数据库,再删缓存
-
策略四:延迟双删策略
-
策略五:逻辑删除策略
-
策略六:先更数据库,再基于队列删缓存
如果能在面试的时候,把其中每一种策略的角色功能、适用场景、执行流程、优势弱点、改进策略进行系统化、体系化的陈述,无论是那个厂,无论是什么顶级的大厂,一定会对候选人的能力有十分的认可。
这里的内容,来自于《Java高并发核心编程 卷3加强版》
有关6中策略的代码实操介绍,请参见 尼恩的 100Wqps三级缓存组件实操
策略一:先更数据库,再更缓存
在实际的业务场景中,一种常见的并发场景是:微服务Provider实例A、B同时进行同一个数据的更新操作。按照先更数据库,再更缓存的策略,则微服务Provider实例A、B可能会出现下面的执行次序:
l step 1:微服务A去执行update DB
l step 2:微服务B去执行update DB
l step 3:微服务B去执行update Cache
l step 4:微服务A去执行update Cache
上面的执行流程,具体如下图所示:
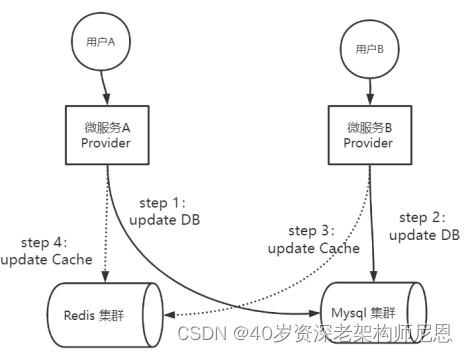
图:先更数据库,再更缓存的并发执行案例
上面的执行流程,是典型的并发写入场景。
在图中的并发写入的场景中,Provider A进行数据的写入,Provider B也进行数据的写入。
最终的结果是:DB中的数据是Provider B的数据,Cache中的数据是Provider A的数据,出现DB和Cache数据不一致问题。
具体的原因是:Provider B的更新在Cache中的数据,被Provider A的更新在Cache中的数据覆盖了。DB的更新次序先A后B,理论上Cache中的数据更新也应该是先A后B。理论上,最终Cache中的数据应该是Provider B的数据,而不是Provider A的数据。所以,在流程执行完毕后,缓存中的Provider A的数据为脏数据。
而之出现这个问题,是因为以上流程中step 3与step 4的执行均为操作缓存,都是高并发的操作,很难保证先后次序,所以缓存出现脏数据的概率很大。
为何不更新缓存而是删除缓存?
核心面试题
一个非常高频的问题是:Cache-Aside在写入的时候,为什么是删除缓存而不是更新缓存呢?
回到上一节的例子,在图中的并发写入的场景中,Provider A进行数据的写入,Provider B也进行数据的写入。
在这个例子中,写入DB的次序如下:
l Provider A先发起一个写操作,第一步先更新数据库
l Provider B再发起一个写操作,第二步更新了数据库
现在,由于分布式系统,无法保证并发操作的有序性,写入Cache的次序可能如下:
l Provider B先发起一个Cache写操作,第一步先更新Cache
l Provider A再发起一个Cache写操作,第二步更新了Cache
这时候,Cache保存的是Provider A的数据(老数据),DB保存的是B的数据(新数据),于是发生了DB和Cache数据不一致,Cache中出现脏数据。
如果使用删除操作取代更新操作,则Cache不会出现上面的脏数据问题。具体如下图所示:
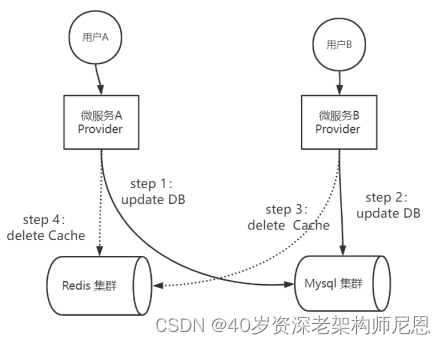
图:为何不更新缓存而是删除缓存
除了能够减少脏数据之外,更新缓存相对于删除缓存,还有两点劣势:
(1)如果写入Cache的值,是经过复杂计算才得到的话。更新缓存频率高的话,就会大大降低性能。
(2)及时更新缓存属于饿汉模式,适用于数据读取高频的场景。在写多读少的情况下,数据很多时候还没被读取到,又被更新了,这也浪费了Cache的空间,也降低了性能。
这里的内容,来自于《[Java高并发核心编程 卷3加强版]《Java高并发核心编程 卷3加强版》 (注意,是加强版)的 策略1
策略1的代码实操介绍,请参见 尼恩的 100Wqps三级缓存组件实操
策略二:先删缓存,再更新数据库
在实际的业务场景中,一种常见的并发场景是:微服务Provider实例A进行数据的写入,而服务Provider实例 B同时进行同一个数据的读取操作。按照先删缓存,再更新数据库的策略,则微服务Provider实例A、B可能会出现下面的执行次序:
l step 1:微服务A去执行delete Cache
l step 2:微服务B去执行load from DB
l step 3:微服务B去执行update Cache
l step 4:微服务A去执行update DB
上面的执行流程,具体如下图所示:

图:先删缓存,再更新数据库的并发执行案例
上面的执行流程,是典型的并发读写场景。
在图中的并发读写的场景中,Provider A进行数据的写入,Provider B进行数据的查询。
最终,DB中的数据是Provider A的更新数据,Cache中的数据是Provider B从DB加载的数据,而这个数据已经过时,出现DB和Cache数据不一致问题。
具体的原因是:Provider B查询Cache的时候,Cache中的数据被删除,Provider B只能去DB查找,然后将数据更新在Cache。而Provider A在Provider B查完之后,竟然更新了DB,导致了DB和Cache的不一致。
出现这个DB和Cache的不一致问题的根本原因,大致如下:
写操作是先删Cache(操作1)再写DB(操作2),如果在此期间发生并发读,读取的动作很容易发生操作1、操作2的中间,从而读取到过时的数据,最终导致Cache和DB不一致。更为严重的时候,读操作把过期数据刷入Cache后,会导致后面比较长时间的不一致。这个时间,一直持续到缓存过期,如说4个小时(以项目中的配置时间为准)。
上面的Cache和DB不一致,将导致一个严重的后面:后续的读取操作,都会使用Cache中的数据,所以,后面的读取操作都会使用过时数据。
这里的内容,来自于《[Java高并发核心编程 卷3加强版]《Java高并发核心编程 卷3加强版》 (注意,是加强版)的 策略2
策略2的代码实操介绍,请参见 尼恩的 100Wqps三级缓存组件实操
策略三:先更数据库,再删缓存
先更数据库,再删缓存,基本上可以解决并发读写场景中,Cache和DB数据不一致的问题。
但是,在一些特殊的场景中,还是会存在数据不一致的问题。
一种非常特殊的并发场景是:
微服务Provider实例A进行数据的写入操作,先写DB(操作1),再删Cache(操作2),如果由于某种原因出现了卡顿,没有及时把数据放入Cache,或者说放入Cache的操作,简单的说,操作2发生了滞后。
此时,服务Provider实例 B进行一个数据的读取操作,读取的次序仍然是先读Cache,再读DB,很容易发生DB和Cache的不一致性。
按照先更数据库,再删缓存的策略,则微服务Provider实例A、B可能会出现下面的执行次序:
l step 1:微服务A去执行update DB
l step 2:微服务B去执行load from Cache
l step 3:微服务A去执行delete Cache,但是发生了延迟
上面的执行流程,具体如下图所示:
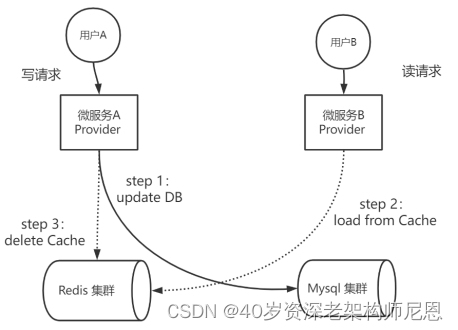
图:先更数据库,再删缓存的并发执行案例
在图中的并发读写的场景中,Provider A进行数据的写入,Provider B进行数据的查询。
微服务Provider实例A先写DB(操作1),再删Cache(操作2),如果Provider实例A发生卡顿、或者网络延迟等异常的问题,导致操作2严重滞后。在操作2执行完成之前,DB和Cache的数据是不一致的。
在此期间,其他的数据读取操作,都会读取Cache中的过期数据,出现DB和Cache数据不一致问题。
出现这个DB和Cache的不一致问题的根本原因,大致如下:
写操作是先写DB(操作1)再删Cache(操作2),如果在此期间发生并发读,读操作很容易发生操作1、操作2的中间,从而,并发读操作从Cache读取到过时的数据,最终导致Cache和DB不一致。
但是等到写操作删除Cache(操作2)的动作执行完成之后,Cache和DB的数据,会恢复一致性。
无论如何,策略三(先写DB再删Cache),比策略二(先删Cache再写DB)发生数据不一致的时间短。相比较而言,推荐大家使用策略三,而不是策略二。
那么,策略三的问题是啥呢?
(1)写DB(操作1)和删Cache(操作2)之间,存在短时间的数据不一致;
(2)如果删Cache失败,存在较长时间的数据不一致,这个时间会一直持续到Cache过期;
如何解决策略三中Cache删除失败所导致的DB和Cache较长时间的数据不一致呢?可以使用策略四:延迟双删。
这里的内容,来自于《[Java高并发核心编程 卷3加强版]《Java高并发核心编程 卷3加强版》 (注意,是加强版)的 策略3
策略3的代码实操介绍,请参见 尼恩的 100Wqps三级缓存组件实操
策略四:延迟双删策略
什么是延迟双删呢?延迟双删是基于策略二进行改进,就是先删Cache,后写DB,最后延迟一定时间,再次删Cache。
在实际的业务场景中,一种常见的并发场景是:微服务Provider实例A进行数据的写入,而服务Provider实例 B同时进行同一个数据的读取操作。按照先删Cache,后写DB,最后延迟一定时间,再次删Cache策略,则微服务Provider实例A、B可能会出现下面的执行次序:
l step 1:微服务A去执行delete Cache
l step 2:微服务B去执行load from DB
l step 3:微服务B去执行update Cache
l step 4:微服务A去执行update DB
l step 5:微服务A去执行 delay delete Cache
上面的执行流程,具体如下图所示:
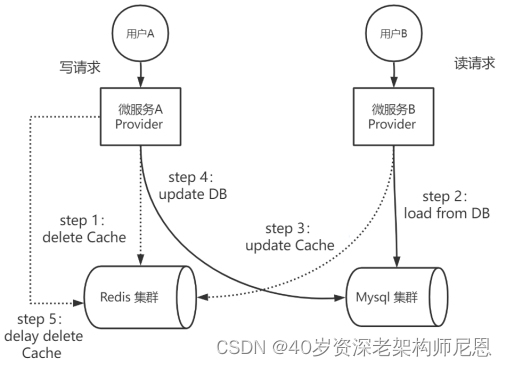
图:先删Cache,后写DB,再次延迟删Cache的并发执行案例
在图中的并发读写的场景中,Provider A进行数据的写入,Provider B进行数据的查询。
微服务Provider实例A先删Cache(操作1),再写DB(操作2),最后再二次延迟删除Cache(操作3)。在操作2之前,如果发生并发读,从DB读取到过时数据,可能出现DB和Cache数据不一致问题。
出现这个DB和Cache的不一致问题的根本原因,大致如下:
写操作是先删Cache(操作1)再写DB(操作2),如果在此期间发生并发读,读操作容易发生操作1、操作2的中间,从DB读到过时数据,最终导致Cache和DB不一致。但是,这一轮的数据不一致,持续时间不会太长。为啥呢?写操作还有一个兜底的动作:二次延迟删除Cache(操作3),从而保证数据一致。
所以,延迟双删也会存在数据不一致,不过是持续时间比较短而已。
那么,策略四的问题是啥呢?
(1)如果写操作比较频繁,可能会对Redis造成一定的压力;
(2)极端情况下,第二次延迟删Cache失败,操作的效果退化到策略二。DB和Cache存在较长时间的数据不一致,这个时间会一直持续到Cache过期,比如说4个小时(以项目中的配置时间为准)。
如何解决策略四的以上两个问题呢?可以使用策略五:先更数据库,再基于队列删缓存。
这里的内容,来自于《[Java高并发核心编程 卷3加强版]《Java高并发核心编程 卷3加强版》 (注意,是加强版)的 策略4
策略4的代码实操介绍,请参见 尼恩的 100Wqps三级缓存组件实操
策略五:逻辑删除/逻辑过期的问题
首先什么是逻辑过期时间呢。
逻辑代表什么,假的删除,不是真正的删除。而是空间换时间,设置一些额外的标志
比如:
在存储数据的时候加个字段,比如 logicExpireTime 给它设置值。
这个值,跟我们缓存key的有效时间肯定不一样。
比如,永不过期
比如,当前时间再加上 几个小时 转为时间戳的方式跟数据一起存入redis。
逻辑过期时间= 业务过期时间
物理过期时间= 逻辑过期时间 + 高并发冗余时间
查询的时候,检查 logicExpireTime ,如果发现到时间了,
另外有一个缓存的重建线程,进行异步重建
更新的时候, 更改 逻辑过期时间 = 当前时间
这里在 写《Java高并发核心编程 卷3加强版》 (注意,是加强版)的 时候,没有介绍, 没有写逻辑删除策略
策略5的代码实操介绍,请参见 尼恩的 100Wqps三级缓存组件实操
策略六:先更数据库,再基于队列删缓存
来到策略六:先更数据库,再基于队列删缓存。那么,如何基于任务队列删缓存呢?实质上,策略六是基于策略三进行改进。首先回顾一下策略三的问题?
(1)写DB(操作1)和删Cache(操作2)之间,存在短时间的数据不一致;
(2)如果删Cache失败,存在较长时间的数据不一致,这个时间会一直持续到Cache过期;
策略六主要的操作次序,和策略三保持一致,依然是先写DB后删除Cache。不同的是,策略六引入队列,把删Cache的操作加入队列,后台会有一个异步线程、或者进程去异步消费队列中的删除任务,去执行删Cache的操作。
基于队列删缓存,可以细分为:
-
第1种细分的方案:基于内存队列删除缓存
-
第2种细分的方案:基于消息队列删除缓存
-
第3种细分的方案:基于binlog+消息队列删除缓存
首先来看第一种细分的方案:基于内存队列删除缓存。
此策略把删Cache的操作加入任务队列,后台会有一个异步线程去异步消费任务队列里面的删除任务,去执行删Cache的操作,如果缓存删除失败,可以重试多次,确保删除成功。
在实际的业务场景中,一种常见的并发场景是:微服务Provider实例A进行数据的写入,而服务Provider实例 B同时进行同一个数据的读取操作。Provider实例A先写DB,然后将删Cache加入任务队列;Provider实例 B则是先读缓存,没有数据再读DB。微服务Provider实例A、B可能会出现下面的执行次序:
-
step 1:微服务A去执行update DB
-
step 2:微服务A将delete Cache操作进入任务队列
-
step 3:微服务B去执行load from Cache
-
step 4:消费线程从任务队列提取delete Cache操作,执行删除Cache的操作,直到删除成功。
上面的执行流程,具体如下图所示:
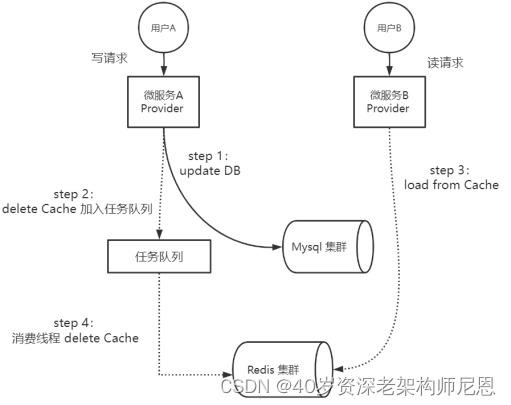
图:先更数据库,后基于内存队列删缓存的并发执行案例
在图中的并发读写的场景中,Provider A进行数据的写入,Provider B进行数据的查询。
微服务Provider实例A先写DB(操作1),再将删Cache操作加入任务队列(操作2)。在删除Cache操作真正执行完成之前,其他的数据读取操作,都会读取Cache中的过期数据,出现DB和Cache数据不一致问题。但是这种不一致,是短暂的。任务队列的消费线程,会异步执行删除Cache的任务,并且会不断重试确保成功,删除Cache之后,DB和Cache数据不一致问题就会得到解决。
说 明
保存删除Cache任务的队列,建议使用阻塞队列。任务队列的消费线程,可参考Rocketmq源码中的ServiceThread异步服务线程,其设计思想和执行性能都非常优越。后面尼恩会通过视频,介绍一下基于队列删除缓存的实操。
策略六也会出现这个DB和Cache的不一致问题,尤其是如果写操作非常频繁,队列的任务比较多,可能消费会比较慢,导致DB和Cache的不一致的时间会延长。在这种情况下,可以根据任务队列的拥塞程度,开启多个线程,提升并发执行的效率。
与策略四相比,策略六的优势是:
(1)在写操作比较频繁的场景,策略四有两次删Cache操作,可能会对Redis造成一定的压力;策略六只有一次删Cache操作,Redis压力小一半。
(2)策略四如果删Cache失败,没有引入重试策略;策略六会多次重试,确保删Cache成功,如果重试多次仍然不成功,可以执行运维预警。
(3)策略四将写DB、删Cache这两个操作耦合在了一起,没有很好的做到单一职责;策略六将写DB、删Cache两个操作解耦,模块职责更加单一。
那么,策略六的问题是啥呢?
(1)如果写操作非常频繁,队列的任务比较多,可能消费会比较慢;需要引入多线程机制,加快消费速度。
(2)程序复杂度成倍上升,引入消费线程、任务队列,并且还需要不断进行性能优化。
(3)内存队列是JVM进程的内部队列,如果JVM崩溃,内存队列没有来得及处理的Cache记录删除任务会丢失,这些数据的Cache记录和DB记录会长时间不一致。
其次,来看第二种细分的方案:基于消息队列删除缓存。
在前面的第一种细分方案中,将删除Cache的任务保存在内存队列,并不是高可靠的。
为了保证高可靠的删除Cache记录,这里引入高可用的独立组件——Rocketmq消息队列。需要注意的是,这里引入的RocketMq消息队列是高可用的类型消息队列,不是单节点的类型消息队列,从而保障消息记录的高可用,保障Cache的删除操作只要没有被执行成功,就不会丢失。
引入高可用RocketMq消息队列之后,执行双写操作的Provider A的操作流程,有小幅度的调整。Provider A需要将删除Cache的操作,序列化成Rocketmq消息,然后写入高可用Rocketmq消息队列中间件即可。然后,由专门的消费者(Cache Delete Consumer)进行消息的消费,根据消息内容执行Cache记录删除工作。
DB和Redis双写的场景下,Provider A先更数据库,后基于消息队列删缓存的并发执行案例的执行流程,具体如下图所示:

图:先更数据库,后基于消息队列删缓存的并发执行案例
引入高可用的独立组件RocketMq消息队列之后,Provider A的写入逻辑变得很简单,删Cache的时候,只需要发送消息到RocketMq即可,大大简化了Provider A程序的写入逻辑。只是为了保证消息的高可靠传递,这里Provider A在发送消息的时候,需要使用同步发送模式,而不能使用异步发送的模式。
在消息投递的环节,由RocketMq高可用组件的ACK机制保证消息的高可靠投递。如果消息第一次消费失败,RocketMq会重复多次进行投递,确保消息被正常消费,如果一直不能被成功消费,在重复投递一定的次数之后(默认16次),消息会进入死信队列。系统的监控程序会对死信队列进行监控,一旦发现死信消息,监控程序会进行运维告警,由运维人员解决最终的缓存删除问题。除非Redis集群崩溃,一般都不会出现这样的极端情况。
和基于内存队列删除缓存,基于消息队列删除缓存的方案的优势是:
增加了Cache删除的可靠性,避免了因JVM崩溃所导致的内存队列中的记录丢失的问题。
那么,Provider在执行DB和Cache双写时,能不能进一步减少双写的负担,将发送删除Cache消息的操作,从双写逻辑中剥离,交给其他的组件去完成呢?答案是可以的。具体来说,就是使用基于基于binlog+消息队列去删除Cache的方案。
最后,来看第三种细分的方案:基于binlog+消息队列删除缓存。
以Mysql为例,可以使用阿里的Canal中间件,采集在数据写入Mysql时生成的binlog日志,然后将日志发送到RocketMq队列。在消费端,可以编写一个专门的消费者(Cache Delete Consumer)完成缓存binlog日志订阅,筛选出其中的更新类型log,解析之后进行对应Cache的删除操作,并且通过RocketMq队列ACK机制确认处理这条更新log,保证Cache删除能够得到最终的删除。
DB和Redis双写的场景下,Provider A先更数据库,后基于基于binlog+消息队列删除缓存的并发执行案例的执行流程,具体如下图所示:
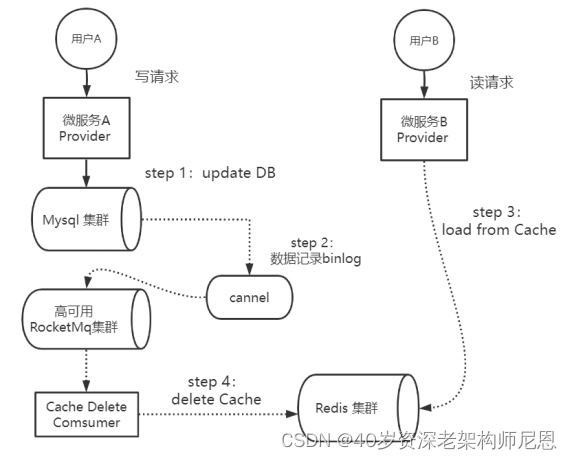
图:先更数据库,后基于消息队列删缓存的并发执行案例
基于binlog+消息队列去删除Cache的方案的优势是:
微服务Provider在执行DB和Cache双写时,只需要执行写入DB的操作就可以了,大大简化了微服务Provider的业务逻辑。Cache的删除工作已经完全被Canal、RocketMq、专门的消费者(Cache Delete Consumer)三者相互结合去接管了。
如何选型呢
这么多的Cache-Aside如何保证双写的数据一致性方案,改如何选型呢?只有更合适、没有最合适。大家可以根据项目和团队的情况选择最合适的。具体的方案选型,大家可以在高并发社群——疯狂创客圈的微信群里边交流。
这里对应到 《Java高并发核心编程 卷3 加强版的 策略5》,写书的时候, 没有写逻辑删除策略
策略6的代码实操介绍,请参见 尼恩的 100Wqps三级缓存组件实操
基于队列的方案,主要有两种:
- 第2种细分的方案:基于消息队列删除缓存
- 第3种细分的方案:基于binlog+消息队列删除缓存
如何选型呢?
很多小伙伴选择基于binlog+消息队列删除缓存, 但是这种方案, 在很多场景下是不可以使用的。具体原因比较复杂,请参考尼恩的 100Wqps三级缓存组件实操,里边有详细的介绍。
从CAP视角分析DB与Cache的数据一致性
CAP理论作为分布式系统的基础理论,它描述的是一个分布式系统在以下三个特性中:
-
一致性(Consistency)
-
可用性(Availability)
-
分区容错性(Partition tolerance)
分布式系统最多满足其中的两个特性:要么满足CA,要么CP,要么AP,无法同时满足CAP。也就是说AP和CP是一组天敌,要满足AP高性能,只能舍弃CP。
在DB和Cache的分布式架构中,加入分布式Cache的目的是为了获得高性能、高吞吐,就是为了获得分布式系统的AP特性。所以,如果需要数据库和缓存数据保持强一致(强CP特性),就不适合使用缓存。
所以,从CAP的理论出发,使用缓存提升性能,就是会有数据更新的延迟,就会产生数据的不一致。
使用分布式Cache,可以通过一些方案优化,保证弱一致性,最终一致性的。我们只能通过不断的方案迭代,减少不一致性的时间长度。这需要Cache设计时:结合业务仔细思考是否适合用缓存;结合业务仔细思考缓存过期时间。
缓存一定要设置过期时间,这个时间太短、或者太长都不好。
如果过期时间太短,请求可能会比较多的落到数据库上,这也意味着失去了缓存的优势。如果过期时间太长,缓存中的脏数据会使系统长时间处于一个延迟的状态,而且,系统中长时间没有人访问的数据一直存在内存中不过期,浪费内存。
为啥DB和Cache没有办法强一致呢?
主要是写DB和删Cache是两个独立的操作,两个操作并没有保证原子性。如果一定要强CP,就需要非常复杂的低性能方案保证写DB和删Cache两个操作的原子性,比如引入分布式锁,并且需要引入CP类型的Zookeeper分布式锁,或者引入CP类型的Redis RedLock,而不是引入AP类型的普通Redis分布式锁。
所以,如果一定要强CP,就需要非常复杂的低性能方案,有点得不偿失。
说在后面
如果遇到难题,可以来找尼恩,给大家做起底式、绞杀式、系统化梳理, 帮大家真正让面试官爱到死去活来。
参考文献:
尼恩的10Wqps秒杀架构笔记
尼恩的10Wqps三级缓存架构笔记
推荐阅读:
《干翻 nio ,王炸 io_uring 来了 !!(图解+史上最全)》
《4次迭代,让我的 Client 优化 100倍!泄漏一个 人人可用的极品方案!》
《阿里一面:你做过哪些代码优化?来一个人人可以用的极品案例》
《阿里二面:千万级、亿级数据,如何性能优化? 教科书级 答案来了》
《峰值21WQps、亿级DAU,小游戏《羊了个羊》是怎么架构的?》
《Springcloud gateway 底层原理、核心实战 (史上最全)》
《分库分表 Sharding-JDBC 底层原理、核心实战(史上最全)》
《clickhouse 超底层原理 + 高可用实操 (史上最全)》
《队列之王: Disruptor 原理、架构、源码 一文穿透》
《环形队列、 条带环形队列 Striped-RingBuffer (史上最全)》
《一文搞定:SpringBoot、SLF4j、Log4j、Logback、Netty之间混乱关系(史上最全)》
《缓存之王:Caffeine 源码、架构、原理(史上最全,10W字 超级长文)》
《Java Agent 探针、字节码增强 ByteBuddy(史上最全)》
《Zookeeper Curator 事件监听 - 10分钟看懂》
以上是关于美团2面:如何保障 MySQL 和 Redis 数据一致性?这样答,让面试官爱到 死去活来的主要内容,如果未能解决你的问题,请参考以下文章