MindSpore安装和使用MindSpore 2.0.0版本简单实现数据变换Transforms功能
Posted 小5聊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MindSpore安装和使用MindSpore 2.0.0版本简单实现数据变换Transforms功能相关的知识,希望对你有一定的参考价值。
本篇文章主要是讲讲MindSpore的安装以及根据官方提供的例子实现数据变换功能。
昇思MindSpore是一款开源的AI框架,旨在实现易开发、高效执行、全场景覆盖三大目标。
目录
1、加入MindSpore社区

2、安装前准备
2.1、获取安装命令
官方提供版本和环境配置信息,非常的方便,直接根据自己环境选择即可
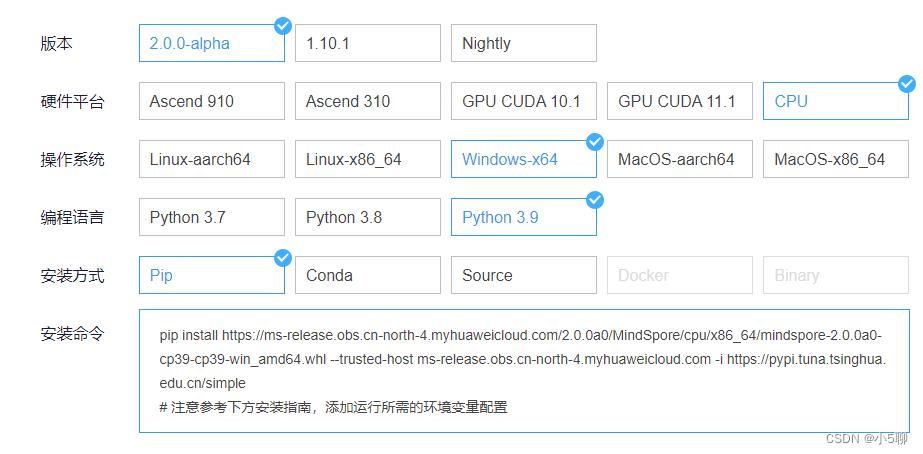
pip install https://ms-release.obs.cn-north-4.myhuaweicloud.com/2.0.0a0/MindSpore/cpu/x86_64/mindspore-2.0.0a0-cp39-cp39-win_amd64.whl --trusted-host ms-release.obs.cn-north-4.myhuaweicloud.com -i https://pypi.tuna.tsinghua.edu.cn/simple
# 注意参考下方安装指南,添加运行所需的环境变量配置
2.2、安装pip
确保自己环境已经安装pip,若还没有安装,推荐如下两种方式安装
1)官方推荐
pip方式安装MindSpore CPU版本-Windows
2)博客文章
可参考下面我这篇文章写的【小5聊】Python基础学习之python版本对应pip版本查看
2.3、确认系统环境
1)操作系统
确认安装Windows 10是x86架构64位操作系统。

2)Python版本
确认安装Python(>=3.7.5)。可以从Python官网或者华为云选择合适的版本进行安装

3、安装MindSpore
3.1、完整性校验
set MS_VERSION=2.0.0a0

3.2、命令安装
复制自己选择的安装命令
pip install https://ms-release.obs.cn-north-4.myhuaweicloud.com/2.0.0a0/MindSpore/cpu/x86_64/mindspore-2.0.0a0-cp39-cp39-win_amd64.whl --trusted-host ms-release.obs.cn-north-4.myhuaweicloud.com -i https://pypi.tuna.tsinghua.edu.cn/simple
以下为安装过程


3.3、验证安装
python -c "import mindspore;mindspore.run_check()"
3.4、升级版本
当需要升级版本时,可执行如下命令
pip install --upgrade mindspore==version
温馨提示:升级到rc版本时,需要手动指定version为rc版本号,例如1.5.0rc1;如果升级到正式版本,==version字段可以缺省。
4、数据准备
mindspore.dataset提供了面向图像、文本、音频等不同数据类型的Transforms,同时也支持使用Lambda函数。
4.1、背景
通常情况下,直接加载的原始数据并不能直接送入神经网络进行训练,此时我们需要对其进行数据预处理。MindSpore提供不同种类的数据变换(Transforms),配合数据处理Pipeline来实现数据预处理。所有的Transforms均可通过map方法传入,实现对指定数据列的处理。
4.2、安装download模块
pip install download

4.3、下载数据
根据官方提供的例子代码,会将数据下载到根目录
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# 2023-02-25
import numpy as np
from PIL import Image
from download import download
from mindspore.dataset import transforms, vision, text
from mindspore.dataset import GeneratorDataset, MnistDataset
# Download data from open datasets
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/" \\
"notebook/datasets/MNIST_Data.zip"
path = download(url, "./", kind="zip", replace=True)
train_dataset = MnistDataset('MNIST_Data/train')

5、数据变换 Transforms
5.1、Common Transforms
mindspore.dataset.transforms模块支持一系列通用Transforms
5.1.1、Compose
Compose接收一个数据增强操作序列,然后将其组合成单个数据增强操作。我们仍基于Mnist数据集呈现Transforms的应用效果。
1)根据上一步下载好的数据,可加载并输出,如下
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# 2023-02-25
import numpy as np
from PIL import Image
from download import download
from mindspore.dataset import transforms, vision, text
from mindspore.dataset import GeneratorDataset, MnistDataset
train_dataset = MnistDataset('MNIST_Data/train')
image, label = next(train_dataset.create_tuple_iterator())
print(image.shape)

2)数据变换
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# 2023-02-25
import numpy as np
from PIL import Image
from download import download
from mindspore.dataset import transforms, vision, text
from mindspore.dataset import GeneratorDataset, MnistDataset
# 先加载到数据
train_dataset = MnistDataset('MNIST_Data/train')
# 设置数据变换参数
composed = transforms.Compose(
[
vision.Rescale(1.0 / 255.0, 0),
vision.Normalize(mean=(0.1307,), std=(0.3081,)),
vision.HWC2CHW()
]
)
# 输出数据变换后的内容
train_dataset = train_dataset.map(composed, 'image')
image, label = next(train_dataset.create_tuple_iterator())
print(image.shape)

5.2、Vision Transforms
mindspore.dataset.vision模块提供一系列针对图像数据的Transforms。在Mnist数据处理过程中,使用了Rescale、Normalize和HWC2CHW变换。
5.2.1、Rescale
Rescale变换用于调整图像像素值的大小,包括两个参数:
rescale:缩放因子。
shift:平移因子。
1)像素值进行缩放
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# 2023-02-25
import numpy as np
from PIL import Image
from download import download
from mindspore.dataset import transforms, vision, text
from mindspore.dataset import GeneratorDataset, MnistDataset
random_np = np.random.randint(0, 255, (48, 48), np.uint8)
random_image = Image.fromarray(random_np)
print(random_np)

2)数据处理
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# 2023-02-25
import numpy as np
from PIL import Image
from download import download
from mindspore.dataset import transforms, vision, text
from mindspore.dataset import GeneratorDataset, MnistDataset
random_np = np.random.randint(0, 255, (48, 48), np.uint8)
random_image = Image.fromarray(random_np)
rescale = vision.Rescale(1.0 / 255.0, 0)
rescaled_image = rescale(random_image)
print(rescaled_image)

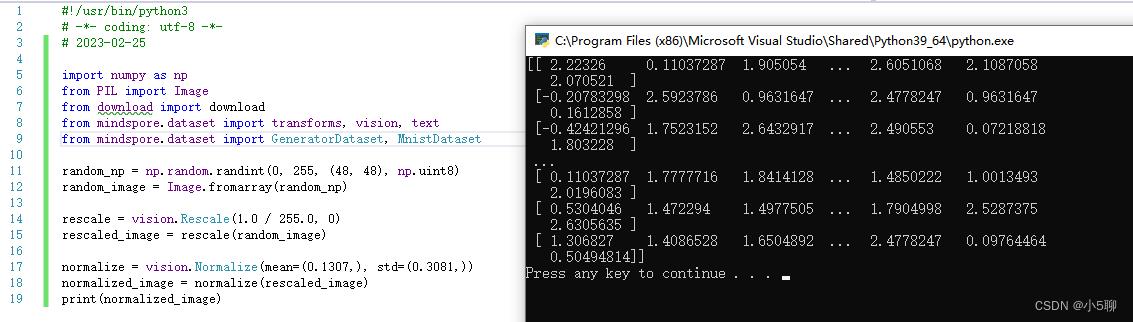
5.2.2、Normalize
Normalize变换用于对输入图像的归一化
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# 2023-02-25
import numpy as np
from PIL import Image
from download import download
from mindspore.dataset import transforms, vision, text
from mindspore.dataset import GeneratorDataset, MnistDataset
random_np = np.random.randint(0, 255, (48, 48), np.uint8)
random_image = Image.fromarray(random_np)
rescale = vision.Rescale(1.0 / 255.0, 0)
rescaled_image = rescale(random_image)
normalize = vision.Normalize(mean=(0.1307,), std=(0.3081,))
normalized_image = normalize(rescaled_image)
print(normalized_image)
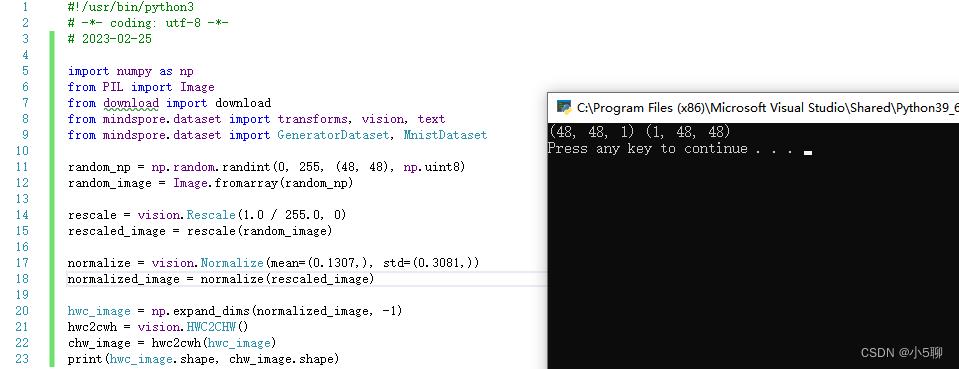
5.2.3、HWC2CWH
HWC2CWH变换用于转换图像格式。
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# 2023-02-25
import numpy as np
from PIL import Image
from download import download
from mindspore.dataset import transforms, vision, text
from mindspore.dataset import GeneratorDataset, MnistDataset
random_np = np.random.randint(0, 255, (48, 48), np.uint8)
random_image = Image.fromarray(random_np)
rescale = vision.Rescale(1.0 / 255.0, 0)
rescaled_image = rescale(random_image)
normalize = vision.Normalize(mean=(0.1307,), std=(0.3081,))
normalized_image = normalize(rescaled_image)
hwc_image = np.expand_dims(normalized_image, -1)
hwc2cwh = vision.HWC2CHW()
chw_image = hwc2cwh(hwc_image)
print(hwc_image.shape, chw_image.shape)
5.3、Text Transforms
mindspore.dataset.text模块提供一系列针对文本数据的Transforms。与图像数据不同,文本数据需要有分词(Tokenize)、构建词表、Token转Index等操作。这里简单介绍其使用方法。
首先我们定义三段文本,作为待处理的数据,并使用GeneratorDataset进行加载。
5.3.1、BasicTokenizer
分词(Tokenize)操作是文本数据的基础处理方法,MindSpore提供多种不同的Tokenizer。这里我们选择基础的BasicTokenizer举例。配合map,将三段文本进行分词,可以看到处理后的数据成功分词。
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# 2023-02-25
import numpy as np
from PIL import Image
from download import download
from mindspore.dataset import transforms, vision, text
from mindspore.dataset import GeneratorDataset, MnistDataset
texts = [
'Welcome to Beijing',
'北京欢迎您!',
'我喜欢China!',
]
test_dataset = GeneratorDataset(texts, 'text')
fdfds=text.BasicTokenizer()
test_dataset = test_dataset.map(text.BasicTokenizer())
报错原因:BasicTokenizer接口不支持windows平台

5.3.2、Lookup
Lookup为词表映射变换,用来将Token转换为Index。在使用Lookup前,需要构造词表,一般可以加载已有的词表,或使用Vocab生成词表。这里我们选择使用Vocab.from_dataset方法从数据集中生成词表。
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# 2023-02-25
import numpy as np
from PIL import Image
from download import download
from mindspore.dataset import transforms, vision, text
from mindspore.dataset import GeneratorDataset, MnistDataset
texts = [
'Welcome to Beijing',
'北京欢迎您!',
'我喜欢China!',
]
test_dataset = GeneratorDataset(texts, 'text')
vocab = text.Vocab.from_dataset(test_dataset)
print(vocab.vocab())

5.4、Lambda Transforms
Lambda函数是一种不需要名字、由一个单独表达式组成的匿名函数,表达式会在调用时被求值。Lambda Transforms可以加载任意定义的Lambda函数,提供足够的灵活度。在这里,我们首先使用一个简单的Lambda函数,对输入数据乘2
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# 2023-02-25
import numpy as np
from PIL import Image
from download import download
from mindspore.dataset import transforms, vision, text
from mindspore.dataset import GeneratorDataset, MnistDataset
test_dataset = GeneratorDataset([1, 2, 3], 'data', shuffle=False)
test_dataset = test_dataset.map(lambda x: x * 2)
print(list(test_dataset.create_tuple_iterator()))

总结:第一次体验MindSpore的AI框架,我感觉视野一下子就被打开了,体验非常的棒,给MindSpore点赞,官方提供的例子也非常清晰明了!感兴趣的小伙伴也可以体验一下!
以上是关于MindSpore安装和使用MindSpore 2.0.0版本简单实现数据变换Transforms功能的主要内容,如果未能解决你的问题,请参考以下文章