特征向量中心度(eigenvector centrality)算法原理与源码解析
Posted 咕噜大大
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了特征向量中心度(eigenvector centrality)算法原理与源码解析相关的知识,希望对你有一定的参考价值。
前言
随着图谱应用的普及,图深度学习技术也逐渐被越来越多的数据挖掘团队所青睐。传统机器学习主要是对独立同分布个体的统计学习,而图深度学习则是在此基础上扩展到了非欧式空间的图数据之上,通过借鉴NLP和CV方向的模型思想,衍生了很多对图谱这种非序列化数据的建模分析手段,帮助分析人员洞察数据之间隐含的复杂关系特征。
在深度学习技术没有普及之前,已经存在大量的图谱数据分析工作,而这些工作的主要思路是通过抽取图中节点的统计信息作为特征,并用作分类模型的输入。今天,在这里介绍的其中一个经典的图分析算法叫做特征向量中心度(eigenvector centrality),它的作用是衡量节点在整个网络中的重要性。图数据一个最常用的数据结构就是邻接矩阵,而这个算法的主要思想就是用到了矩阵分解的思想,经典的图深度学习算法GCN也是基于拉普拉斯矩阵的谱分解和傅立叶变换实现的。所以对于新人来说,特征向量中心度可以做为图数据挖掘的经典入门算法之一。
参考资料
[1] William L. Hamilton. Graph Representation Learning. Morgan and Claypool publishers, 2020
[2] Xinyu Chen. 幂迭代法[OL]. https://zhuanlan.zhihu.com/p/336250805
[3] Power method for approximating eigenvalues, https://ergodic.ugr.es/cphys/lecciones/fortran/power_method.pdf
[4] 柴静. 线性代数-山东大学. https://www.bilibili.com/video/av370427050/?p=42&vd_source=9ca707c71dee64c77d2f5f3d824e1c19
定义问题
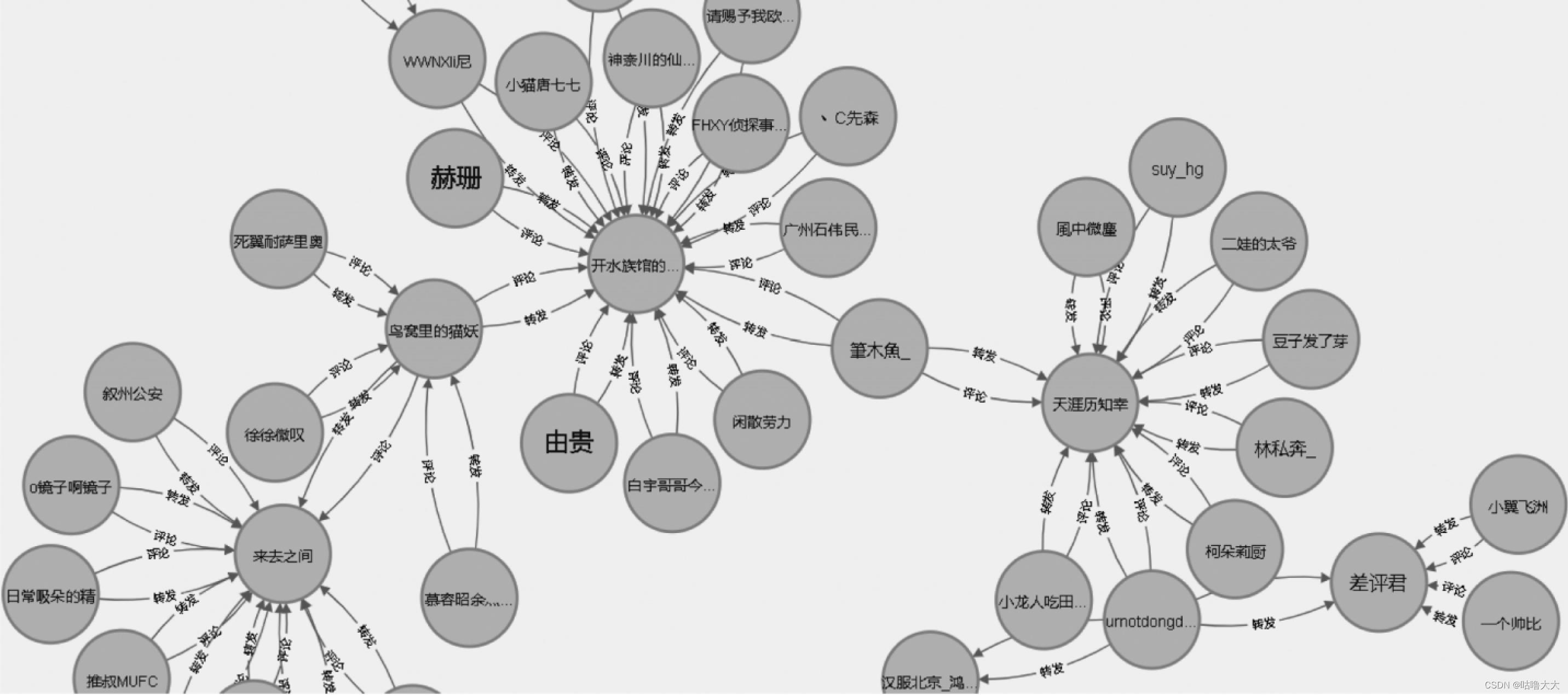 图片引用自 :《交网络舆情中意见领袖主题图谱构建及关系路径研究_基于网络谣言话题的分析》
图片引用自 :《交网络舆情中意见领袖主题图谱构建及关系路径研究_基于网络谣言话题的分析》
我们首先来定义特征向量中心度算法所要解决的问题。如上图所示,这是微博谣言话题中意见领袖节点关系图谱的一部分。如果用最简单直观的图统计方法来分析这个图谱,那就是使用节点的出入度的大小(有多少邻节点)来衡量这个节点在图谱中的重要性。我们可以看到”天涯历知幸“、“来去之间”和“开水族馆的XX”三位博主的出入度最高,是重要的意见领袖。但是,如果仅仅是通过博主周围的邻居节点的数量来衡量其影响力又是有失偏颇的,因为这些转发和关注的微博用户有可能是僵尸粉(现在僵尸粉都很智能的)。所以,我们还需要找到一种方式,不仅仅是通过当前节点关联的邻居节点数量来横量其重要性,还要将邻居节点本身的重要性也一起考虑进去。回到上图,“鸟窝里的猫妖”和“筆木鱼_”这两个节点虽然它的邻居节点数量很少,但是它们都关注转发了”天涯历知幸“、“来去之间”和“开水族馆的XX”三位重要博主的博文,所以他们也应该是重要的谣言传播者。
算法原理
我们先定义 e u e_u eu 节点的特征向量中心度由下面的递归等式表示:
e u = 1 λ ∑ v ∈ ν A [ u , v ] e v ∀ u ∈ ν e_u = \\frac1\\lambda\\sum_v\\in \\nu A[u,v] e_v\\;\\; \\forall u \\in \\nu eu=λ1∑v∈νA[u,v]ev∀u∈ν, (1),
这个等式的意思是
e
u
e_u
eu 节点的中心度是其周围邻节点
e
v
e_v
ev 中心度总和的
1
λ
\\frac1\\lambda
λ1, 其中
λ
\\lambda
λ是一个常量。
ν
\\nu
ν是图上所有节点的集合。
A
A
A是邻接矩阵,
A
∈
R
∣
ν
∣
×
∣
ν
∣
A \\in \\mathbbR^|\\nu| \\times |\\nu|
A∈R∣ν∣×∣ν∣,
A
[
u
,
v
]
=
1
A[u,v] = 1
A[u,v]=1 代表节点
u
u
u和节点
v
v
v之间相连(节点之间存在边关系),
A
[
u
,
v
]
=
0
A[u,v] = 0
A[u,v]=0 代表节点
u
u
u和节点
v
v
v之间不相连。
从上面的式子来看,如果在一个很大的图谱上做递归运算,且图谱的度数很深,甚至存在环路,则需要非常大的栈内存,同时计算效率也不高。
那么我们再对公式进行转换,假设 e e e是图谱上所有节点中心度的集合,也就是
e = e 1 , e 2 , e 3 , … … , e v T e = \\big\\e_1,e_2,e_3,……, e_v \\big\\^T e=e1,e2,e3,……,evT (2),
那么将式子(2) 代入式子 (1), 得我们可以得到下面的式子(3):
λ e = A e \\lambdae = Ae λe=Ae (3),
我们可以发现,式子(3)就是一个典型的特征值方程,其中 e e e是邻接矩阵 A A A的特征向量, λ \\lambda λ是邻接矩阵的特征值。
定义:设A是n阶矩阵, λ \\lambda λ为一个数,若存在非零向量X,使得 λ X = A X \\lambdaX = AX λX=AX, 则称数 λ \\lambda λ为矩阵A的特征值,非零向量X为矩阵A的对应于特征值 λ \\lambda λ的特征向量。
则我们可以将图谱领接矩阵A的特征向量 e e e做为其每个节点的中心度度量值。同时,我们也希望衡量节点中心度的值为正数,那么通过Perron-Frobenius定理,我们可以证明特征向量 e e e中的每一个分量都是正值,满足节点中心度的度量值的要求。
Perron–Frobenius定理证明了存在一个方阵,如果其行列的元素为正值,则存在最大的特征值 λ p f \\lambda_pf λpf,并且该特征值所对应的特征向量的每个元素都是正数。
由上面的公式和定理可以得知,一个矩阵如果存在最大的特征值,那么这个特征值就是该矩阵的主特征值,其对应的特征向量则是主特征向量,并且主特征向量里面的每一个元素都是正数。我们可以将邻接矩阵A的主特征向量 e e e的每一个分量值,作为其节点所对应的中心度度量值,它体现了节点所连接的邻节点的数量以及所连接邻节点的重要性。
那么我们来看看特征向量的一般求法,以公式(3)为例,A是n阶邻接矩阵,移项后公式(3)可以写成
(
A
−
λ
E
)
e
=
0
(A-\\lambdaE)e=0
(A−λE)e=0 (4),
其中
E
E
E是n阶单位矩阵。又因为
e
e
e是非零向量,那么可以进一步得出
|
A
−
λ
E
|
=
0
|A-\\lambdaE|=0
|A−λE|=0 (5),
解此行列式,即公式(5),获得的值
λ
i
\\lambda_i
λi即为矩阵A的特征值 ,再将
λ
i
\\lambda_i
λi值代入公式(4)中,就可以求出对应的特征向量。
例如:
A
=
∣
1
−
2
2
−
2
−
2
4
2
4
−
2
∣
A = \\beginvmatrix1&-2&2\\\\-2&-2&4\\\\2&4&-2\\endvmatrix
A=
1−22−2−2424−2
那么
|
A
−
λ
E
|
=
∣
1
−
λ
−
2
2
−
2
−
2
−
λ
4
2
4
−
2
−
λ
∣
=
0
|A-\\lambdaE|= \\beginvmatrix1-\\lambda&-2&2\\\\-2&-2-\\lambda&4\\\\2&4&-2-\\lambda\\endvmatrix=0
|A−λE|=
1−λ−22−2−2−λ424−2−λ
=0
=
(
1
−
λ
)
(
2
+
λ
)
2
−
16
−
16
+
4
(
2
+
λ
)
−
16
(
1
−
λ
)
+
4
(
2
+
λ
)
=
0
=(1-\\lambda)(2+\\lambda)^2-16-16+4(2+\\lambda)-16(1-\\lambda)+4(2+\\lambda)=0
=(1−λ)(2+λ)2−16−16+4(2+λ)−16(1−λ)+4(2+λ)=0
=
−
λ
3
−
3
λ
2
+
24
λ
−
28
=
0
=-\\lambda^3-3\\lambda^2+24\\lambda-28=0
=−λ3−3λ2+24λ−28=0
我们看见一个3阶矩阵的行列式方程就有3个根
λ
1
,
λ
2
,
λ
3
\\lambda_1,\\lambda_2,\\lambda_3
λ1,λ2,λ3。那么如果图谱是100万的节点,那么就会组成一个100万阶的邻接矩阵,它的行列式方程将有100万个根。由此可见,我们需要找到一个更加合理的办法去求出大图的特征向量。
这时候我们要引入幂迭代 (power iteration) 法。
幂迭代 (power iteration) 法是线性代数中一种非常重要的方法,可对特征值分解和奇异值分解等问题进行求解。比较特别的是,当我们要对来自真实世界的大规模数据进行奇异值分解时,基于幂迭代法的奇异值分解在保证精度的同时可以极大提高计算效率。[2]
类似于Jacobi和Gauss-Seidel两个迭代算法,幂迭代 (power iteration) 法也是采取迭代计算的方式去得到一个近似值逼近主特征向量。假设我们有一个具有主特征值的邻接矩阵 A A A,我们选取一个非零向量 x 0 x_0 x