2023年数学建模美赛D题(Prioritizing the UN Sustainability Goals)分析与编程
Posted YouCans
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2023年数学建模美赛D题(Prioritizing the UN Sustainability Goals)分析与编程相关的知识,希望对你有一定的参考价值。
2023年数学建模美赛D题分析建模与编程
文章目录
- 2023年数学建模美赛D题分析建模与编程
1. D题:Prioritizing the UN Sustainability Goals(联合国可持续发展目标的优先级)
1.1 背景
联合国制定了17个可持续发展目标(SDGs)。实现这些目标将最终改善世界上许多人的生活。这些目标并不是相互独立的,因此一些目标的积极进展往往会对其他目标产生影响(正面影响,或负面影响,或两者兼有)。这种相互关系使得所有目标的实现成为一个动态过程,例如由于资金的限制和其他国家与国际组织的优先事项的影响。此外,技术进步、全球流行病、气候变化、区域战争和难民运动等各种因素,都对许多目标产生了严重影响。
1.2 要求
探索目标之间的关系:
- 创建17个SDGs之间关系的网络。
- 利用个别SDGs以及网络的结构,设定优先次序,以最有效地推进联合国的工作。您如何评估每个优先事项的有效性?如果您的优先事项得以实施,未来10年内可以实现什么合理的目标?
- 如果实现了其中一个SDG(例如,没有贫困或没有饥饿),那么结果网络的结构将是什么样的?这个成就将对您团队的优先事项产生什么影响?是否有其他目标应该提出给联合国考虑?
- 讨论技术进步、全球流行病、气候变化、区域战争和难民运动或其他国际危机对您团队的网络和选择优先事项的影响。从网络的角度来看,这对联合国的进展有什么重大影响?
- 讨论您的网络方法如何帮助其他公司和组织确定他们的目标优先顺序。
2. 可持续发展目标体系分析与讨论
2.1 SDGs 的提出
联合国可持续发展目标由17项目标(Goals)、169项具体目标(Targets)以及232 项指标(Indicators)构成。17项SDGs是整体的,不可分割的,并兼顾了可持续发展的三个方面:经济发展、社会进步和环境保护。
-
2012年里约地球峰会,提出可持续发展目标(Sustainable development goals, SDGs)的宏伟愿望。
-
2015年,在包括中国和美国等193个国家共同签署的《改变我们的未来:2030可持续发展议程》中,正式提出了17项SDGs和169项具体目标。
-
2017年,可持续发展目标指标机构间专家组(IAEG-SDGs)制定了232项全球指标框架,以评估各项目标的实施进展。
SDGs的提出,使可持续发展从一个概念性的政治议程,转变为具有数据和科学手段支撑的衡量标准。
2.2 SDGs 的相互关系
SDGs具有综合性的特征,一个目标的进展往往与其他目标的复杂反馈联系在一起,因此明确各项SDGs之间的关系,对于有效的管理这些相互作用,在区域、国家和全球尺度上实现可持续发展至关重要。
SDGs的制定充分考虑了MDGs中存在的问题和不足。SDGs涉及消除贫困、性别平等、环境保护和经济发展等多个方面,正如在2030 议程中指出的“17 项SDGs是整体的,不可分割的,并兼顾了可持续发展的三个方面:经济发展、社会进步和环境保护” 。尽管在2030 议程中表明各项SDGs 之间是相互关联的,但并没有说明它们之间是如何相互关联。了解各项目标之间、具体目标之间以及指标之间的相互联系对于实现SDGs的政策一致性至关重要,这主要是由于针对某一个目标采取的行动或措施可能与另一项目标存在协同效应(相互促进)或权衡取舍(相互矛盾) 。可持续发展的实现并不是各项目标的简单结合,而是不同目标、具体目标以及指标之间协同作用的结果,并且要最大限度的降低不同要素的权衡影响。因此,明确不同SDGs之间的相互作用过程和机制,对于有效的管理这些相互作用,并最终在区域、国家和全球尺度上实现可持续发展至关重要。
2.2.1 基于联结途径的研究
“联结(nexus)”表示两个或多个事物之间的联系或一系列联系。长期以来,该术语被广泛使用于哲学、细胞生物学和经济学领域。
“联结途径”被定义为一种系统的分析不同类别事物内部(或之间)关系的思路与方法 。应用“联结途径”包含着对一系列事物的聚类过程,从而在整体的角度上探讨不同类别事物之间的协同/权衡关系。
当前基于“联结途径”分析各项SDGs 之间的关系,已被看作是理清各项目标之间复杂性的有效方法之一,并被国内外学者广泛使用。基于各项目标之间的相互作用(协同和权衡)特征以及Raworth 提出的框架,Waage 和Yap 对17 项SDGs 进行了分类(图1) 。
来自:Jeff Waage, Thinking Beyond Sectors for Sustainable Development, 2015
图1 中的内部圈层是“以人为本”的目标,旨在通过改善健康和教育以及促进国家内部和国家之间的包容和平等(包含目标1、3—5 和10 和16)来实现人类福祉。而“以人为本”目标的实现需要以中间圈层目标的实现为基础,这些目标主要是关于相关产品和服务的生产、分配与运输(包括目标2、6—9 和11—12)。同时,中间圈层目标需要可持续的自然环境的支撑,因此外部包含了三个环境目标(目标13—15),涉及土地、海洋、生物多样性和气候变化等方面的内容。Waage 和Yap 认为归入同一圈层的目标具有高度协同效应,并且实现中间圈层的目标有助于降低内部圈层和外部圈层目标之间的权衡作用[32] 。
Waage 和 Yap 提出的可持续发展目标分类框架

2.2.2 基于功能的分类
Elder 等从功能的角度出发,将SDGs 分为六个主要类别,分别是社会目标、资源、经济、环境、教育和管理 。该研究认为环境是经济、社会目标以及最终人类福祉实现的基础。此外,资源是经济活动的原材料,而经济活动则为社会目标的实现提供相应的产品与服务。管理则是指制度和决策过程,用于调节如何从环境中提取资源,如何将资源融入到经济活动,如何将经济结果服务于社会目标,以及如何管理教育和健康问题。
MarkElder, An Optimistic Analysis of the Means of Implementation for Sustainable Development Goals: Thinking about Goals as Means, (https://pdfs.semanticscholar.org/f5a1/3adc13b65424d6fd08950efb5eb881c3d233.pdf)


2.2.3 中国可持续发展指标体系
全球指标框架当前用于评价全球和区域可持续发展目标进展情况,但当其应用至具体某个国家评价时,尚存在诸多问题,包括:①未对目标的重视度加以区分,不同国家距离达成17项目标的绝对绩效差距不同,因此各国应当根据实现目标的差距和难度,确定优先任务,并予以足够的关注,优先考核。②部分指标仅适用于全球或区域层面可持续发展进展的考核,并不适合国家层面的评价。③指标本身属性差距大,既有定量和定性评价的指标,还有难以评估的指导性、预期性指标。④部分SDGs指标与中国统计指标表述存在差异,或者从未统计过,指标数据获取难度大,无法直接应用到中国SDGs进展评估。
基于上述原因,必须对全球指标框架进行适应中国国情、结合中国考核要求的本土化,用以评估中国可持续发展目标进展情况。系统考虑全球指标框架下各目标指标的考核基础条件,统筹国内外SDGs本土化的进展,优先保留IAEG-SDGs提出的中国有可靠数据来源的指标,充分对接国家重大政策行动及规划中明确考核的指标。
在充分考虑全球可持续发展的紧迫性和中国经济发展和生态文明建设的长久目标下,中国国际经济交流
中心与哥伦比亚大学地球研究院,联合设计了适用于中国可持续发展指标体系(CSDIS)。
CSDIS 由五个主题构成,不仅包括社会民生、经济发展和资源环境三个传统的可持续发展研究主题,也加入消耗排放和治理保护两个主题, 五类一级指标下共包含22个子指标,包括GDP增长率、人均水资源量等 。
这五个主题存在着明确的因果关系。其中资源环境是一切人类活动的基础,消耗与排放是指人类通过消耗自然资源促进经济发展,经济的稳定增长有助于保障社会福利、改善生活方式,而社会民生的改善则可以促进人们的环境保护意识,并通过合理的治理保护来增加自然存量 。此外,在CSDIS 中也针对省级、大中城市级别分别设定了相适应的评估指标,因此该体系对于支撑中国实现完成全球可持续发展的国际承诺,促进中国的经济发展和生态文明建设有重要的作用。

2.2.4 世界银行提出的网络构架
基于网络理论的度量结构
可持续发展目标指标网络的构建基于两个理念:
(i) 一个国家在给定可持续发展目标中表现超出预期的概率指标取决于表现超出预期的可能性
其他可持续发展目标指标;和
(ii)具有类似SDG交付机制的SDG指标更有可能各国共同遵守。
因此,可持续发展目标的成就反映了可持续发展目标交付的潜在相似性各国机制
绩效指标基于世界银行的国家发展诊断框架(CDDF)(Gable等人,2015年),尽管有一些变化。本文采用了一种类似的分类方法,衡量可持续发展目标的进展,并考虑到一个国家目前的能力水平(以人均国民总收入为代表)。对于国家和SDG系列的任何组合,如果SDG系列在统计上优于给定国家能力的预期,则该国可被归类为表现出色的国家。从形式上讲,如果SDG系列的值高于平均值的95%置信区间,则c国在SDG系列i中具有明显的比较优势:
CDDF使用低收入和中等收入国家的对数线性回归来估计上述公式的预期值。我们的方法在以下方面有所不同:i)我们将高收入国家纳入样本中,ii)使用了核加权局部多项式估计值,而不是常数弹性假设,这是因为在较高的人均国民总收入水平下,这种关系会发生变化。图1用SDG系列的跨国散点图说明了该方法,二氧化碳排放量(2005年GDP的千克/美元)与人均国民总收入的关系。拟合线代表不同人均国民总收入水平的国家的预期人均二氧化碳排放水平。阴影区以外的国家相对于其人均国民总收入而言,表现明显过高或表现不佳。因此,在这个排放量越多意味着结果越差的例子中,乌干达在二氧化碳水平方面表现得越出色——即,与其他国家相比,乌干达在可持续发展目标系列中的表现越出色。
在可持续发展目标之间使用能力的容易程度取决于它们的共同性程度,概念化为它们之间的接近程度。例如,“每1000人医生人数”和“营养不良,5岁以下儿童患病率”这两个指标之间的共同点预计将大于“每1000名医生人数”与“海洋保护区份额”之间的共同之处。因此,在实现可持续发展目标方面,在能力水平上已经遥遥领先于其他国家的国家是那些实现了更好的可持续发展目标的国家机制。
两个SDG指标A和B之间的接近度定义为两个条件概率中的最小值:找到给定B的A的条件概率;以及在给定A的情况下找到B的概率;因为条件概率不是对称的。
3. SDGs 优先事项的选择
3.1 基于SDG密度分布图选择优先事项
虽然每个可持续发展目标的接近度矩阵和中心性度量的结果是通用的,并创建了基本的可持续发展目标网络,但由于各国在网络的不同部分取得了成功,因此每个可持续发展的密度水平因国而异。如果一个国家在网络的密集部分取得了成功,这意味着其当前的能力可以用于实现可持续发展目标的实施重点多样化。如果它位于网络的稀疏部分,则机会集是有限的。在这两种情况下,都需要从长远的角度来确保可持续发展目标议程的可持续改善,这意味着,即使目前接近度较低,也可能建议跳到高中心度的可持续发展目标。然后,该国必须投资于新的能力,这些能力将来将在更多的多样性选择中获得回报。本节以乌干达为例,说明如何使用这些概念来评估政策选项。
图2和图3显示了乌干达目前表现不佳的两个可持续发展目标,也就是说,与乌干达人均收入水平的典型国家相比,乌干达目前没有成功。乌干达应该优先考虑哪一项?
当然,要回答这个问题,需要考虑许多因素,但其中包括:(i) 考虑到目前的能力(密度),成功的容易程度,以及(ii)它创造的进一步改进的潜力(中心性)
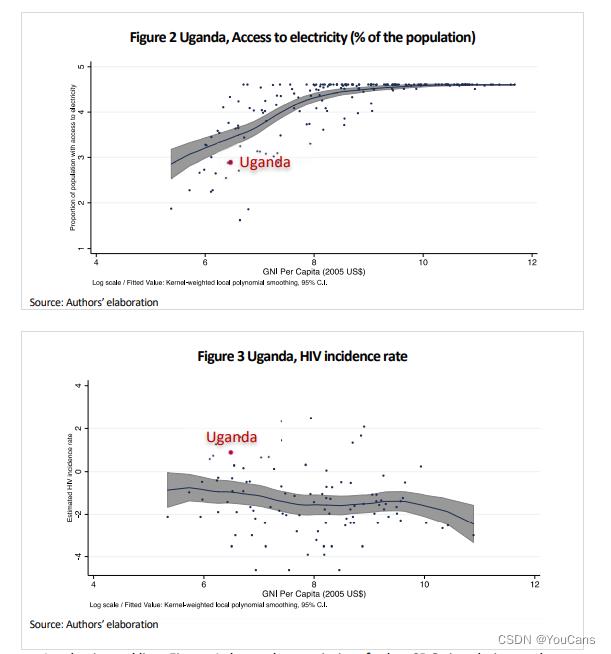
在一条水平线中,图4显示了其他可持续发展目标与所讨论的两个可持续发展目标的接近程度。可持续发展目标(a)是获得电力(占人口的百分比),可持续发展目标目标(b)是艾滋病毒发病率(比率,总人口)。每个灰色圆圈或绿色圆点表示另一个SDG指示符,并且它们离红色圆圈越远(表示归一化最大中心度为1的SDG(a)或SDG(b)),接近度越低。绿色圆点代表乌干达目前成功的可持续发展目标,而圆圈代表乌干达不成功的地方。

a)获得电力的中心值为255,b)HIV发病率为212。问题是,鉴于乌干达目前的能力,即其目前成功的可持续发展目标,乌干达在网络中处于何处。计算乌干达在每一个可持续发展目标方面的密度,结果表明,乌干达在能力上更接近于a)获得电力,密度为0.594,而b)艾滋病毒发病率为0.590。因此,获得电力具有更高的密度和中心性,这一事实表明,电力应优先于艾滋病毒发病率(所有其他方面都是平等的,不同的目标没有权重)。
图5显示了两个SDG的示例,其中优先级排序不那么简单;可持续发展目标(a)是获得电力(占人口的%),可持续发展目标是童婚(15岁之前结婚的女性(20-24岁女性的比例))。
供电中心有256个,童婚中心有185个。因此,如果您没有特定国家的信息,那么获得电力将是实现可持续发展目标议程总体成功的最佳选择。然而,计算乌干达的人口密度(获得电力的人口密度为0.594,童婚人口密度为0.602)表明,乌干达在童婚方面比在获得电力方面更容易表现出色。因此,在本例中,乌干达需要在
考虑到目前的能力(优先考虑童婚),成功的可能性更高,或者考虑到成功的结果(优先考虑获得电力),进一步实现可持续发展目标的可能性更大。
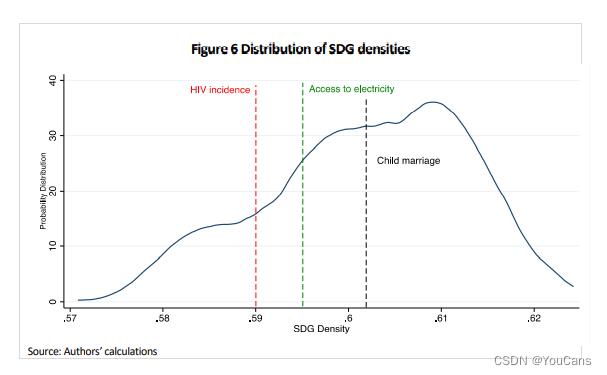
图6显示了乌干达所有SDG密度的分布,并附有一些示例。成功的可持续发展目标在更高的密度水平上更为常见,反之亦然。如果每个可持续发展目标的中心性相同,乌干达应优先考虑乌干达特定密度最高的尚未成功的可持续发展目标。
3.2 基于SDG密度分布图比较不同国家的总体潜力
SDG密度分布图也可用于跨国比较。
在图7中,我们看到在选定的国家中,墨西哥拥有平均密度最高的是玻利维亚、乌干达、肯尼亚、美国和南非。这表明,在这些国家中,墨西哥控制人均国民总收入在追求可持续发展目标议程时,取得超额成就的可能性最大;而南非将面临最大的挑战。墨西哥的收入水平在可持续发展目标的数量已经达到,而南非的国民总收入却落后于其他国家人均水平。当然,在较高的人均收入水平,如美国,竞争与其他国家相比,更为艰难,在发展成果方面取得了巨大成就高收入国家是一个重大的政策挑战。

分布的形状很重要。狭窄的概率分布意味着大多数可持续发展目标在所涉国家的密度水平相似。广泛的概率分布意味着SDG之间的密度显著不同。因此,该国实现某些目标的可能性较高,但实现其他目标的可能性较低,这表明可持续发展目标网络分析将非常有助于确定可持续发展目标倡议的优先顺序。根据每个国家的平均密度,可以根据国家的可持续发展目标改善潜力(而非实现的可持续发展水平)对其进行排名。表5列出了前15名和后15名国家。

另一个展示可持续发展目标网络方法的例子将各国成功实现可持续发展目标的数量与其密度进行了比较。墨西哥和玻利维亚在这项研究中纳入的可持续发展目标指标数量大致相同:墨西哥282项,玻利维亚271项。尽管如此,墨西哥的人口密度明显高于玻利维亚。这意味着墨西哥的成功位于可持续发展目标网络中更密集的部分,即墨西哥在可持续发展目标方面做得很好,这些目标很有可能使其他可持续发展目标的发展取得成功。这意味着墨西哥比玻利维亚更容易利用其机会。
假设有一个全球性或区域性的可持续发展目标问题,或者一个组织在几个国家处理当地问题,那么国家之间的优先事项就摆在桌面上了。表6显示了可持续发展目标指标“获得电力”的例子,其中三个非洲国家的人均收入水平目前表现不佳。除此之外,对卢旺达的投资将带来更大的成功概率,因为该国在更多的可持续发展目标中取得了成功,接近“通电”。与密度较低的其他国家相比特别是可持续发展目标,卢旺达的基本能力更符合改善“电力供应”的需要。

3.3 小结
世界各国领导人于2015年9月通过的《联合国2030年议程》和《可持续发展目标》(SDG)具有全面性和整体性,包括17项目标和169项目标,涵盖了发展的经济、社会和环境层面(UN 2015)。雄心勃勃的议程表明,任何人都不能掉队,所有人都将集体受益于所有可持续发展目标的发展成果。个别国家现在面临着艰巨的挑战,要将这一议程转化为可行、现实但雄心勃勃的发展计划,并确定全面反映其初始条件和优先事项的政策。这项研究的基础是,可持续发展目标既是各国当前能力的产物,也是未来能力的贡献者。因此,在各国优先考虑可持续发展目标政策时,需要考虑路径依赖因素。
SDG网络基于与Hausmann和Klinger(2006)和Hildalgo等人(2007)开发的产品空间相同的理念,并将其与2015年后国家发展诊断框架(Gable等人,2015)的见解相结合。可持续发展目标的成就反映了拥有并结合了该国现有投入的基础结构(基础能力)。输入可以在两个SDG之间移动的容易程度取决于它们的共同程度,概念化为它们之间的接近程度。
接近度是两个可持续发展目标指标一起“成功”的条件概率。成功的定义是,一个国家的人均收入水平高于预期,或如预期。集中度是SDG与所有其他SDG指标的成对接近度之和。因此,这是一种潜在多样性的衡量标准,也是对该国可持续发展目标总体议程成功的贡献。
毫不奇怪,不同的电力获取措施是最相关的可持续发展目标之一,因此意味着如果一个国家成功地提供了电力,其他可持续发展目标也很可能取得成功。如附件表A.1中的成对相关矩阵所示,表现出高中心性的可持续发展目标组包括改善的水和卫生设施、互联网连接、学校入学和免疫接种。然而,联系最少的群体似乎更为多样。然而,需要注意的是,如果可持续发展目标与其他可持续发展目标的成功联系有限,这并不意味着可持续发展目标无关紧要。
然后通过引入密度的概念,将该方法用于特定国家的评估。密度是根据可持续发展目标与国家成功的其他可持续发展目标的接近程度来定义的。因此,这是一项针对特定国家的措施,每个可持续发展目标指标都有所不同。非成功的可持续发展目标密度越高,其所需能力就越接近国家现有能力,国家就越容易将其转变为成功的可持续增长目标。
当比较一个国家的两个可持续发展目标政策选项时,每个可持续发展目标指标的国家特定密度(即其成功的容易程度)必须与每个可持续发展指标的跨国家中心性(即其与其他可持续发展目标的联系性以及进一步改进的潜力)进行权衡。此外,可以根据国家的平均密度或特定SDG的密度对国家进行排名。对于每个国家实现可持续发展目标议程的高效和成功的优先顺序,了解特定国家的路径依赖性至关重要。
然而,它需要考虑到数据的局限性,并与其他研究相结合,尤其是成本效益分析和政治经济分析。此外,该方法假设所有可持续发展目标本身具有相同的价值,而这些价值在可持续发展目标之间和每个国家可能有所不同。

5. 参考资料
5.1 联合国可持续发展目标:
- 目标1:没有贫困
- 目标2:零饥饿
- 目标3:良好的健康和福祉
- 目标4:高质量教育
- 目标5:性别平等
- 目标6:清洁水源和卫生设施
- 目标7:可负担且清洁的能源
- 目标8:体面工作和经济增长
- 目标9:工业、创新和基础设施
- 目标10:减少不平等
- 目标11:可持续城市和社区
- 目标12:负责任的消费和生产
- 目标13:气候行动
- 目标14:生活在水下
- 目标15:生活在陆地上
- 目标16:和平和正义的强有力的制度
- 目标17:实现目标的伙伴关系

5.2 SGDs 目标彼此间的作用:
- 波茨坦气候影响研究所研究员普贾·普拉德汉(PrajalPradhan)说,我们试图将这些关系复杂的目标分解成更容易理解的内容,并通过不同研究分析它们彼此间的作用。可持续发展目标之间总体来看发挥了协同作用,但有一个目标,即采取可持续的消费和生产模式与其他目标之间存在部分冲突。因为增加消费会导致环境污染和材料消耗。因此这些具有冲突性的目标需要被识别、管理和解决。
- 波茨坦气候影响研究所气候影响与脆弱性专业副主席尤尔根·克罗普(JürgenKropp)说,到目前为止,研究者对联合国可持续发展目标之间的相互作用主要采用了定性分析方法,且该研究仍局限在少数国家、个别区域。我们通过涉及200多个国家、122个指标的大量数据,分析不同目标间的协同效应。研究结果不仅揭示了联合国可持续发展目标之间存在一定冲突,还发现在消除贫困、饥饿等方面,各目标之间协同效应潜力巨大。消除贫困、改善公共卫生对其他可持续发展目标会产生积极影响。例如,全球30亿人因使用了清洁用水,卫生条件得到改善后,其健康状况和生活质量得到大幅提升。另一个例子是,一个国家在气候行动上取得的成绩越好,其城市越能得到可持续发展。
- 克罗普说,可持续发展目标代表了一个全面的、多维度的发展视角,我们的研究可以为《2030年联合国可持续发展议程》的成功实施作出一定贡献,可以让大家知道可持续发展目标不是各种目标的集合,而是一个协同的执行系统。只有各个目标相互协调,形成完整体系,世界才会变成一个更加安全的空间。
6. 相关性分析(本节与本文无关)
import statsmodels.api as sm
import matplotlib.pyplot as plt
from statsmodels.graphics.gofplots import qqline
foodexp = sm.datasets.engel.load(as_pandas=False)
x = foodexp.exog
y = foodexp.endog
ax = plt.subplot(111)
plt.scatter(x, y)
qqline(ax, "r", x, y)
plt.show()
# 主程序
def main():
# 读取数据文件
readPath = "../data/toothpaste.csv" # 数据文件的地址和文件名
try:
if (readPath[-4:] == ".csv"):
dfOpenFile = pd.read_csv(readPath, header=0, sep=",") # 间隔符为逗号,首行为标题行
# dfOpenFile = pd.read_csv(filePath, header=None, sep=",") # sep: 间隔符,无标题行
elif (readPath[-4:] == ".xls") or (readPath[-5:] == ".xlsx"): # sheet_name 默认为 0
dfOpenFile = pd.read_excel(readPath, header=0) # 首行为标题行
# dfOpenFile = pd.read_excel(filePath, header=None) # 无标题行
elif (readPath[-4:] == ".dat"): # sep: 间隔符,header:首行是否为标题行
dfOpenFile = pd.read_table(readPath, sep=" ", header=0) # 间隔符为空格,首行为标题行
# dfOpenFile = pd.read_table(filePath,sep=",",header=None) # 间隔符为逗号,无标题行
else:
print("不支持的文件格式。")
print(dfOpenFile.head())
except Exception as e:
print("读取数据文件失败:".format(str(e)))
return
# 数据预处理
dfData = dfOpenFile.dropna() # 删除含有缺失值的数据
print(dfData.dtypes) # 查看 df 各列的数据类型
print(dfData.shape) # 查看 df 的行数和列数
# colNameList = dfData.columns.tolist() # 将 df 的列名转换为列表 list
# print(colNameList) # 查看列名列表 list
# featureCols = ['price', 'average', 'advertise', 'difference'] # 筛选列,建立自变量列名 list
# X = dfData[['price', 'average', 'advertise', 'difference']] # 根据自变量列名 list,建立 自变量数据集
# 准备建模数据:分析因变量 Y(sales) 与 自变量 x1~x4 的关系
y = dfData.sales # 根据因变量列名 list,建立 因变量数据集
x0 = np.ones(dfData.shape[0]) # 截距列 x0=[1,...1]
x1 = dfData.price # 销售价格
x2 = dfData.average # 市场均价
x3 = dfData.advertise # 广告费
x4 = dfData.difference # 价格差,x4 = x1 - x2
X = np.column_stack((x0,x1,x2,x3,x4)) #[x0,x1,x2,...,x4]
# 建立模型与参数估计
# Model 1:Y = b0 + b1*X1 + b2*X2 + b3*X3 + b4*X4 + e
model = sm.OLS(y, X) # 建立 OLS 模型
results = model.fit() # 返回模型拟合结果
yFit = results.fittedvalues # 模型拟合的 y 值
print(results.summary()) # 输出回归分析的摘要
print("\\nOLS model: Y = b0 + b1*X + ... + bm*Xm")
print('Parameters: ', results.params) # 输出:拟合模型的系数
# 拟合结果绘图
fig, ax = plt.subplots(figsize=(10, 8))
ax.plot(range(len(y)), y, 'bo', label='sample')
ax.plot(range(len(yFit)), yFit, 'r--', label='predict')
ax.legend(loc='best') # 显示图例
plt.show()
return
if __name__ == '__main__':
main()
程序运行结果:
period price average advertise difference sales
0 1 3.85 3.80 5.50 -0.05 7.38
1 2 3.75 4.00 6.75 0.25 8.51
2 3 3.70 4.30 7.25 0.60 9.52
3 4 3.70 3.70 5.50 0.00 7.50
4 5 3.60 3.85 7.00 0.25 9.33
OLS Regression Results
==============================================================================
Dep. Variable: sales R-squared: 0.895
Model: OLS Adj. R-squared: 0.883
Method: Least Squares F-statistic: 74.20
Date: Fri, 07 May 2021 Prob (F-statistic): 7.12e-13
Time: 11:51:52 Log-Likelihood: 3.3225
No. Observations: 30 AIC: 1.355
Df Residuals: 26 BIC: 6.960
Df Model: 3
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const 8.0368 2.480 3.241 0.003 2.940 13.134
x1 -1.1184 0.398 -2.811 0.009 -1.936 -0.300
x2 0.2648 0.199 1.332 0.195 -0.144 0.674
x3 0.4927 0.125 3.938 0.001 0.236 0.750
x4 1.3832 0.288 4.798 0.000 0.791 1.976
==============================================================================
Omnibus: 0.141 Durbin-Watson: 1.762
Prob(Omnibus): 0.932 Jarque-Bera (JB): 0.030
Skew: 0.052 Prob(JB): 0.985
Kurtosis: 2.885 Cond. No. 2.68e+16
==============================================================================
OLS model: Y = b0 + b1*X + ... + bm*Xm
Parameters: const 8.036813
x1 -1.118418
x2 0.264789
x3 0.492728
x4 1.383207
【本节完】
以上是关于2023年数学建模美赛D题(Prioritizing the UN Sustainability Goals)分析与编程的主要内容,如果未能解决你的问题,请参考以下文章