Batch Normalization原理介绍
Posted tostq
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Batch Normalization原理介绍相关的知识,希望对你有一定的参考价值。
1)Batch Normalization解决的问题
Batch Normalization(BN)主要用于解决Internal Covariate Shift。由于训练过程中,网络各层数据x分布会发生变化(偏移),这个偏移可能是受不同batch间(或者训练集和测试集)的数据本身分布不同,或者是在训练过程,由于梯度回传,导致不同batch间各层数据分布前后不一致。
这个现象会导致模型训练更为困难,而且由于某些层数据偏移如果过大,导致其经过某些激活层(sigmoid函数等)后其梯度会趋于0,从而造成梯度消失的问题。
早期解决这个问题是对输入进行归一化到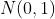 的高斯分布(白化),在网络层较小时,通过此类对输入数据初始化操作确实能解决这类问题,但随着网络层数加大,中间层仍然会出现偏移过大的情况。
的高斯分布(白化),在网络层较小时,通过此类对输入数据初始化操作确实能解决这类问题,但随着网络层数加大,中间层仍然会出现偏移过大的情况。
一种直观的解决思路是对每一层都进行归一化操作,但这样会破坏每层原本的表达,特别是对于某些激活函数(如sigmoid函数),归一化操作还会使得数据分布都在线性区域,而失去了非线性的表达。
2)Batch Normalization的计算方式
BN的思路是在归一化操作后,加一个还原操作,通过这种方式实现训练过程中减少数据分布变化带来的偏移。
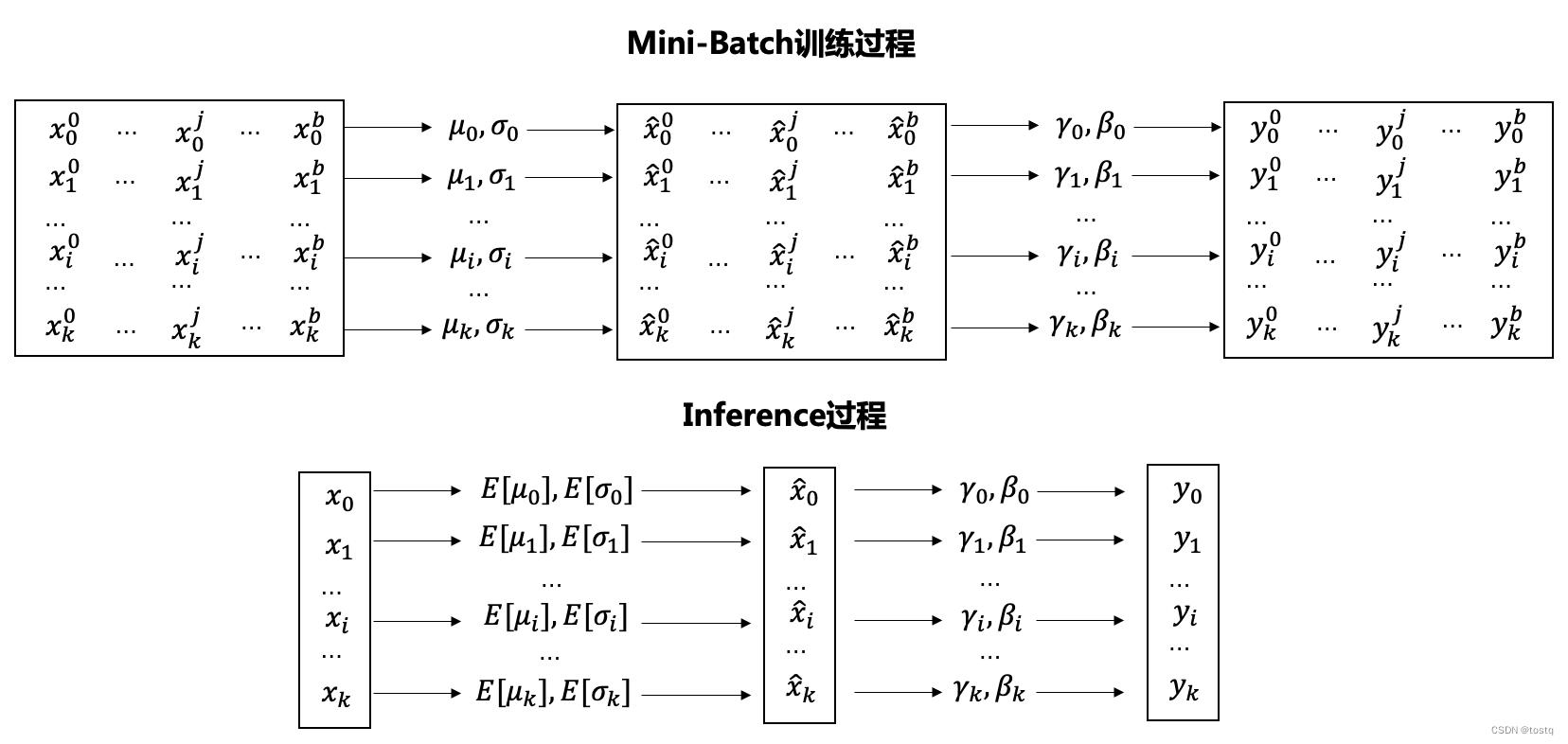
上图显示了BN的计算过程,其中在训练过程中,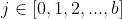 表示batch内的样本标签,
表示batch内的样本标签,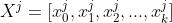 表示batch内一条输入样本,
表示batch内一条输入样本,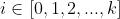 表示输入样本特征的标识,其中
表示输入样本特征的标识,其中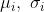 表示输入样本特征i在当前batch内的均值和方差:
表示输入样本特征i在当前batch内的均值和方差:
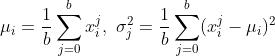
其中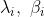 表示输入样本特征
表示输入样本特征 在BN层的还原操作的学习参数,其会随梯度回传时进行更新,当其值恰好等于时,输入经过样本后是完全还原的。
在BN层的还原操作的学习参数,其会随梯度回传时进行更新,当其值恰好等于时,输入经过样本后是完全还原的。
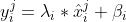
在Inference过程中,没有所谓的batch内的均值和方差,此时用的是整体的均值和方差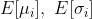 。
。
3)Batch Normalization的训练
BN的训练参数主要为,梯度回传的计算逻辑为:
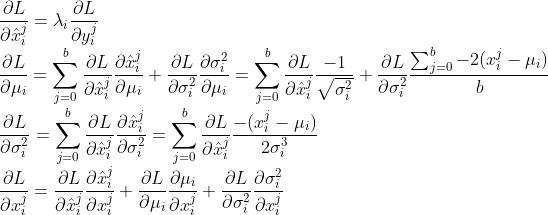
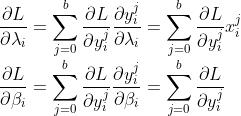
4)Batch Normalization的优点
- 减少Internal Covariate Shift:BN可以减少训练过程中各层数据分布的偏移。
- 加速训练过程:在训练过程中,如何各层参数增大过快,会导致各层输出值偏大,在经过激活函数时,会造成梯度消失的问题。而通过BN可以避免这类问题,因此可以设置更高的学习率。另外当权重参数扩大时,BN下梯度回传不会受到影响,而且当权重参数增大时,其学习率也会相应减少,可以保存在训练过程的稳定性。
-
Regularizes Model(模型正则化):BN通过类似向样本中添加了白噪声,可以取代Dropout用于避免模型过拟合。
以上是关于Batch Normalization原理介绍的主要内容,如果未能解决你的问题,请参考以下文章