AI自给自足!用合成数据做训练,效果比真实数据还好丨ICLR 2023
Posted QbitAl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AI自给自足!用合成数据做训练,效果比真实数据还好丨ICLR 2023相关的知识,希望对你有一定的参考价值。
Brilliant 投稿
量子位 | 公众号 QbitAI
AI生成的图像太逼真,为什么不能拿来训练AI呢?
可别说,现在还真有人这么做了。
来自香港大学、牛津大学和字节跳动的几名研究人员,决定尝试一下能否使用高质量AI合成图片,来提升图像分类模型的性能。
为了避免AI合成的图像过于单一、或是质量不稳定,他们还提出了几类提升数据多样性和可靠性的方法,帮助AI合成更好的数据集(来喂给AI的同类doge)。
结果他们发现,不仅效果不错,有的AI在训练后,效果竟然比用真实数据训练还要好!

目前这篇论文已经被ICLR 2023收录。

把AI生成的数据喂给AI
作者们分别从零样本(zero-shot)、少样本(few-shot)图像分类、模型预训练(pre-training)与迁移学习三个⽅⾯进⾏了探讨,并给出了提升数据多样性与可靠性的方法。
零样本图像分类
零样本(Zero-shot)图像分类任务,指没有任何⽬标类别的训练图⽚,只有对⽬标类别的描述。
作者们先是提出了一种名为语言增强(Language Enhancement,LE)的⽅法,用于增强合成数据多样性。
具体来说,这种方法会给标签“扩句”,如果原标签是简单的“飞机”,那么经过“扩句”后的提示词就会变成“一架盘旋在海滩和城市上空的白色飞机”。
随后,还采用了一种叫做CLIP过滤器(CLIP Filter)的⽅法确保合成数据的可靠性,即过滤掉合成质量不行的图片,确保AI数据质量过硬。
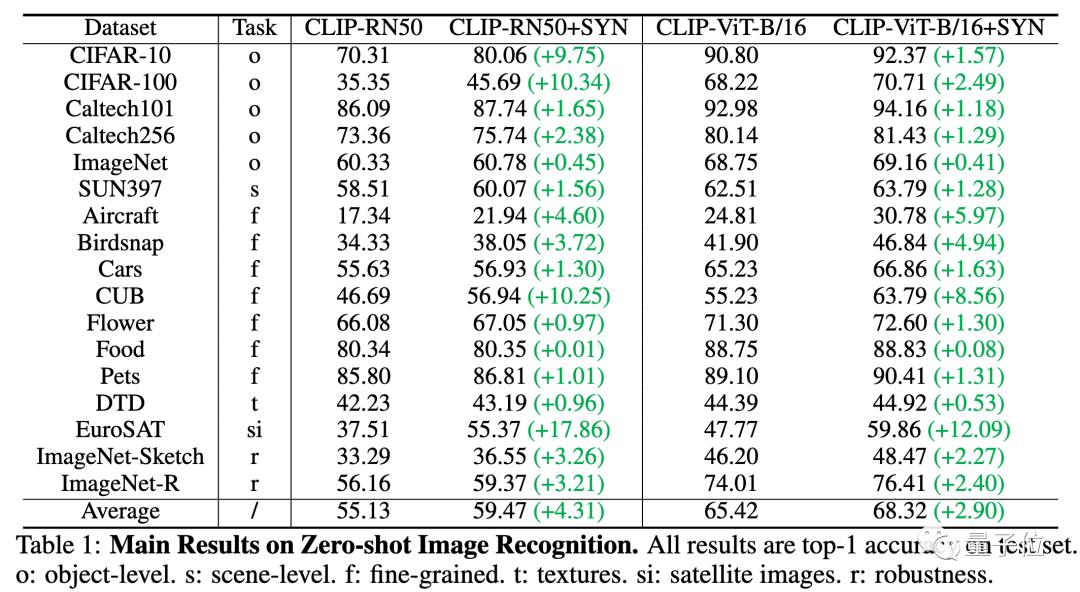
在17个数据集上,相⽐此前效果最好的CLIP模型,相关⼤⼩模型均获得了显著提升(4.31%/2.90%),展示了合成数据的有效性。
少样本图像分类
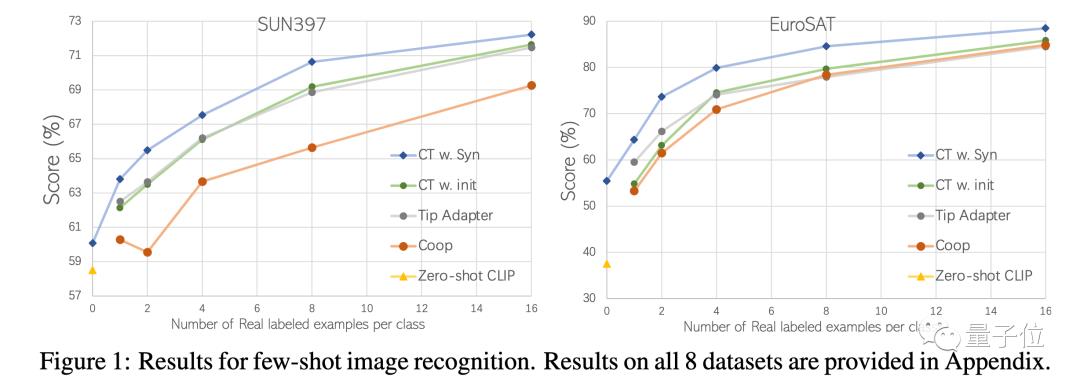
少样本图像(Few-shot)分类任务,通常仅有极少数量(1~16张)的⽬标类别图⽚,与零样本任务的区别是增加了类别与任务特定领域信息。
因此,作者们决定将域内数据(in-domain)的知识⽤于图像⽣成,即将少量的⽬标类别图⽚⽤于噪声叠加的初始状态(Real Guidance),进⼀步发挥⽣成模型的能⼒,从而进⼀步提升性能。

预训练与迁移学习
模型预训练(pre-training)任务,即将模型在⼤量数据上进⾏训练,将训练后的模型作为“起始点”,来帮助提升下游任务的性能。
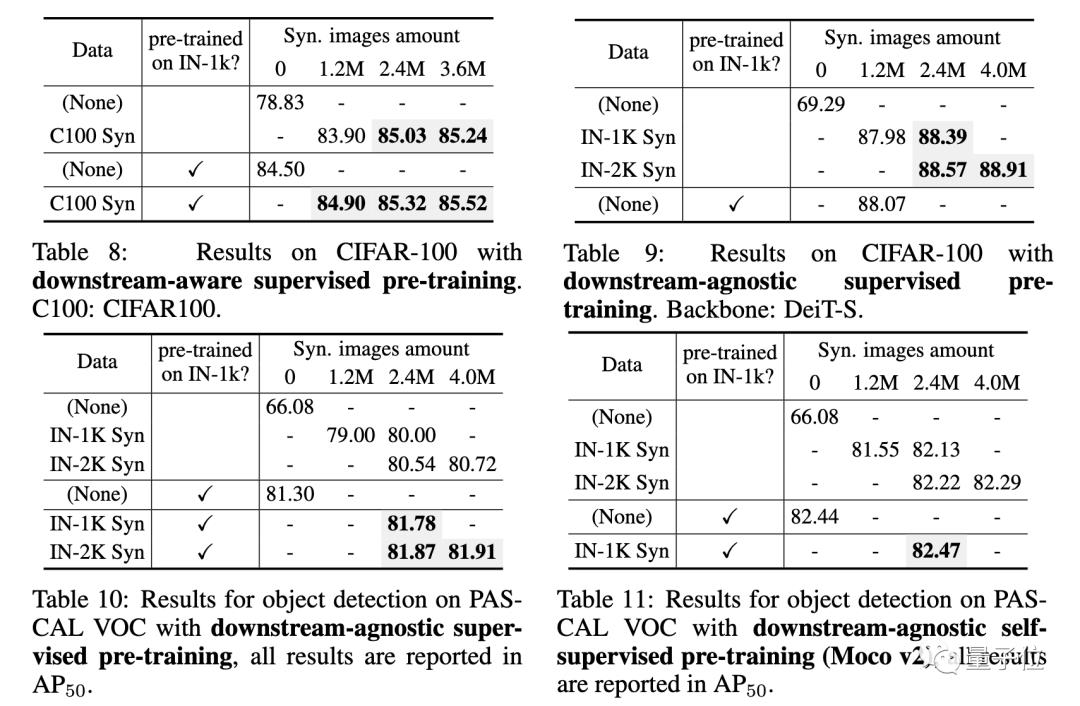
作者们利⽤合成数据,对模型进⾏了预训练,并对数据量、数据多样性程度、预训练模型结构和预训练⽅法进⾏了实验研究。
最终发现:
⽤合成数据进⾏预训练。已经可以达到甚⾄超越⽤真实数据预训练的效果。
⽤更⼤的数据量和数据多样性的合成数据,可以获得更好的预训练效果。
从模型结构和预训练⽅法来看,ViT-based模型(相比convolutional-based模型)、⾃监督⽅法(相比有监督⽅法)会更适合合成数据下的预训练。
论文认为,利⽤⽣成模型产⽣的合成数据来帮助图像分类任务是可行的,不过也存在⼀定的局限性。
例如,如何处理特定任务的domain gap和数据多样性之间的trade-off,以及如何更有效地利⽤潜在⽆穷量的合成图⽚⽤于预训练,都是需要进一步去解决的问题。
作者介绍

一作何睿飞,香港大学在读博士生@CVMI Lab,指导老师为齐晓娟老师,本科毕业于浙江大学竺可桢学院,研究方向是data-efficient learning, vision-language model, knowledge distillation, semi/self-supervised learning。CVMI Lab 正在招收计算机视觉与深度学习方向的博士生,感兴趣的伙伴可以直接email老师!
对于将AI合成图像用于预训练模型这件事,你还能想到更高效的方法吗?
欢迎感兴趣的小伙伴一起讨论~
论文地址:
https://arxiv.org/abs/2210.07574
项目地址:
https://github.com/CVMI-Lab/SyntheticData
以上是关于AI自给自足!用合成数据做训练,效果比真实数据还好丨ICLR 2023的主要内容,如果未能解决你的问题,请参考以下文章