轻量级ORM框架——第二篇:Dapper中的一些复杂操作和inner join应该注意的坑
Posted LINYBO
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了轻量级ORM框架——第二篇:Dapper中的一些复杂操作和inner join应该注意的坑相关的知识,希望对你有一定的参考价值。
上一篇博文中我们快速的介绍了dapper的一些基本CURD操作,也是我们manipulate db不可或缺的最小单元,这一篇我们介绍下相对复杂
一点的操作,源码分析暂时就不在这里介绍了。
一:table sql
为了方便,这里我们生成两个表,一个Users,一个Product,sql如下:
<1> Users table

CREATE TABLE [dbo].[Users](
[UserID] [int] IDENTITY(1,1) NOT NULL,
[UserName] [varchar](50) NULL,
[Email] [varchar](100) NULL,
[Address] [varchar](100) NULL,
CONSTRAINT [PK_Users] PRIMARY KEY CLUSTERED
(
[UserID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
<2> Product table
CREATE TABLE [dbo].[Product](
[ProductID] [int] IDENTITY(1,1) NOT NULL,
[ProductName] [varchar](220) NULL,
[ProductDesc] [varchar](220) NULL,
[UserID] [int] NULL,
[CreateTime] [datetime] NULL,
CONSTRAINT [PK_Product] PRIMARY KEY CLUSTERED
(
[ProductID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
二:in操作
很多时候我们在manipulate table的时候,或多或少的都会用到 ”in关键字”,比如:我要找到User表中Email in (\'5qq.com\',\'8qq.com\')的
Users record。。。
static void Main(string[] args)
{
var connection = new SqlConnection("Data Source=.;Initial Catalog=Datamip;Integrated Security=True;MultipleActiveResultSets=True");
var sql = "select * from Users where Email in @emails";
var info = connection.Query<Users>(sql, new { emails = new string[2] { "5qq.com", "7qq.com" } });
}

看了上面的操作,是不是很简单,只要我们的参数类型是Array的时候,dappper会自动将其转化。。。
三:多条sql一起执行
有时候我们会想在一条sql中灌入很多的snippet sql,然后让其一起执行,此时让我想起了一个操作,我会在db中load data的时候会写到
select ... from marketing where id in (....); select .... from eventmarketing where in (...)类似这样的语句,然后进行结果合并,这篇
为了方便演示,在User上做一个*操作,在Product上做一个* 操作,比如下面这样:
static void Main(string[] args)
{
var connection = new SqlConnection("Data Source=.;Initial Catalog=Datamip;Integrated Security=True;MultipleActiveResultSets=True");
var sql = "select * from Product; select * from Users";
var multiReader = connection.QueryMultiple(sql);
var productList = multiReader.Read<Product>();
var userList = multiReader.Read<Users>();
multiReader.Dispose();
}

四:多表join操作
不管sql写的多么好或者多么烂,接触一个月还是接触到十年,都必然跑不了多表查询,那么在多表查询上dapper该如何使用呢???比如
说我要找到2015-12-12之后的商品信息和个人信息,很显然这是一个多表查询,可以先来看一下users和product的关系。

可以发现其实他们有一个外键关系,然后我们在Product Entity上做一下小修改,将Users作为Product的一个entity property。。。
public class Product
{
public int ProductID { get; set; }
public string ProductName { get; set; }
public string ProductDesc { get; set; }
public Users UserOwner { get; set; }
public string CreateTime { get; set; }
}
有了这些储备,我们大概就可以写出如下的sql。
static void Main(string[] args)
{
var connection = new SqlConnection("Data Source=.;Initial Catalog=Datamip;Integrated Security=True;MultipleActiveResultSets=True");
var sql = @"select p.ProductName,p.CreateTime,u.UserName
from Product as p
join Users as u
on p.UserID = u.UserID
where p.CreateTime > \'2015-12-12\'; ";
var result = connection.Query<Product, Users, Product>(sql,
(product, users) =>
{
product.UserOwner = users; return product;
});
}
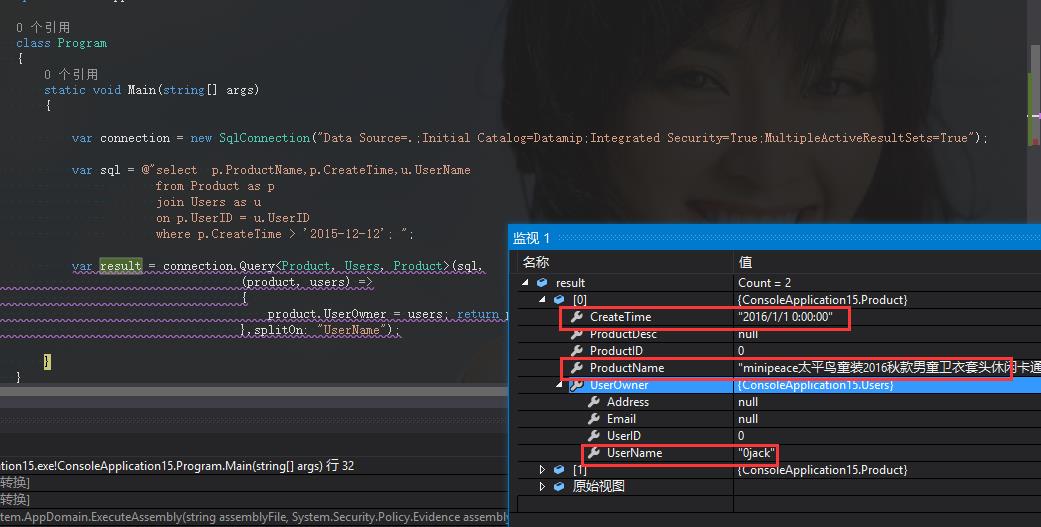
结果就是”操!!!!“。。。。。。。。。。。。

从错误信息中可以看到:当你使用multi-mapping的时候要确保设置了splitOn参数,除了Id。。。从这句话中好像也看不出什么名堂,也就是说
除了Id,你都需要设置SplitOn参数,好吧,这是逼着哥哥看源代码。。。。看看SplitOn到底是个什么样的鸟玩法。。。然后我从Call Stack往上
面找,发现了非常”至关重要“的一段话。

然来splitOn就是Dapper对DataReader进行”从右到左“的扫描,这样就可以从sequent中获取到一个subsequent,然后遇到设置的splitOn
就停止。。。然来是这样,哈哈。。。这回我就知道了,将splitOn设置为”userName“就好了。。。比如下面这样。。。
static void Main(string[] args)
{
var connection = new SqlConnection("Data Source=.;Initial Catalog=Datamip;Integrated Security=True;MultipleActiveResultSets=True");
var sql = @"select p.ProductName,p.CreateTime,u.UserName
from Product as p
join Users as u
on p.UserID = u.UserID
where p.CreateTime > \'2015-12-12\'; ";
var result = connection.Query<Product, Users, Product>(sql,
(product, users) =>
{
product.UserOwner = users; return product;
},splitOn: "UserName");
}
当然如果你觉得我上面说的太啰嗦了,注意事项还tmd的多,又是泛型,又是Lambda的。。。你也可以不指定这些具体Type,而默认使用
dynamic也是可以的,比如下面这样:

五:支持存储过程
对于存储过程,也是一个不得不说的话题,我们的dapper同样也是可以执行的,只需要在Query中的CommandType中标记一下当前就是一个
StoredProcedure就八九不离十了,比如现在在Users表上创建一个简单的StoredProcedure。
USE [Datamip] GO /****** Object: StoredProcedure [dbo].[sp_GetUsers] Script Date: 09/02/2016 09:14:04 ******/ SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO Create proc [dbo].[sp_GetUsers] @id int as begin select * from Users where UserID = @id ; end
在这里,我们需要向存储过程塞入一个@id参数,返回具体的Users EntityList,好了,下面再看一下Query如何构造。
static void Main(string[] args)
{
var connection = new SqlConnection("Data Source=.;Initial Catalog=Datamip;Integrated Security=True;MultipleActiveResultSets=True");
var info = connection.Query<Users>("sp_GetUsers", new { id = 5 },
commandType: CommandType.StoredProcedure);
}

搞定,感觉用Dapper是不是就这么简单,先就说到这里,希望对大家有帮助。
*******摘自:https://www.cnblogs.com/huangxincheng/p/5832281.html
以上是关于轻量级ORM框架——第二篇:Dapper中的一些复杂操作和inner join应该注意的坑的主要内容,如果未能解决你的问题,请参考以下文章