Linux操作系统&&进程概念
Posted 星河万里᭄ꦿ࿐
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux操作系统&&进程概念相关的知识,希望对你有一定的参考价值。
文章目录
1. 冯诺依曼体系结构
冯·诺依曼结构也称普林斯顿结构,是一种将程序指令存储器和数据存储器合并在一起的存储器结构。数学家冯·诺依曼提出了计算机制造的三个基本原则,即采用二进制逻辑、程序存储执行以及计算机由五个部分组成(运算器、控制器、存储器、输入设备、输出设备),这套理论被称为冯·诺依曼体系结构。
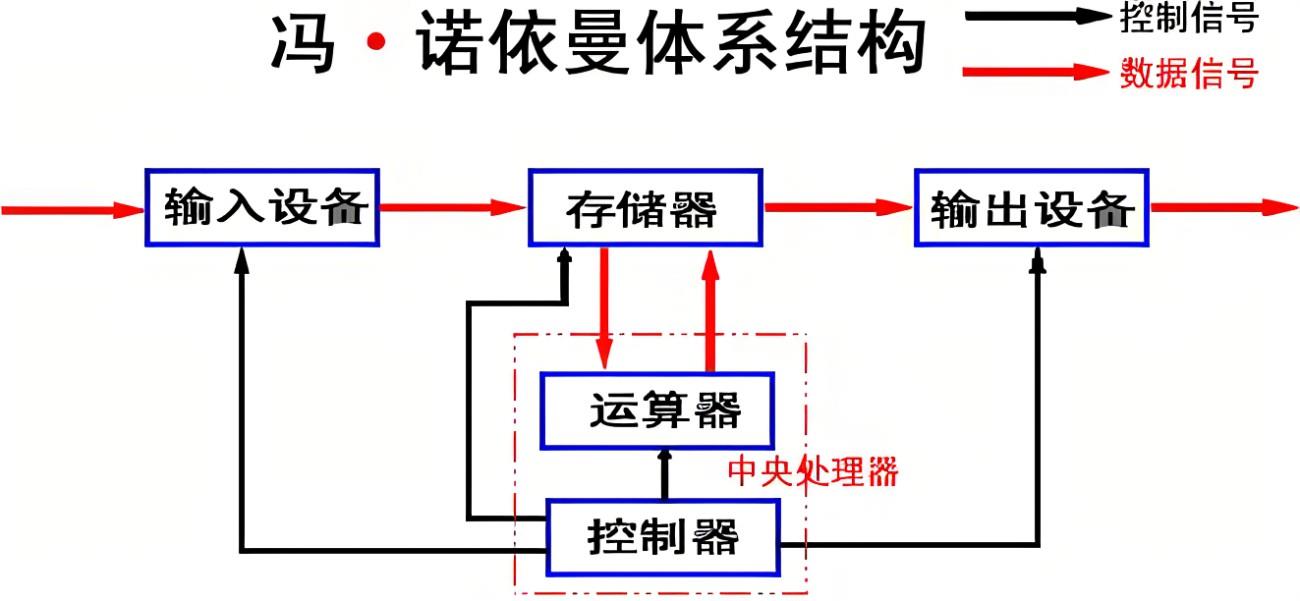
这里我们来介绍一下组成冯诺依曼体系结构的五个部分:
输入设备:键盘、摄像头、网卡、磁盘等
输出设备:显示器、磁盘、网卡、声卡音响等
存储器:内存(掉电易失)
运算器和控制器:CPU
关于冯诺依曼,我们必须强调几点:
- 这里的存储器指的是内存
- 不考虑缓存情况,这里的CPU能且只能对内存进行读写,不能访问外设(输入或输出设备)
- 外设(输入或输出设备)要输入或者输出数据,也只能写入内存或者从内存中读取。
我们知道,我们的数据需要先从磁盘加载到内存中,然后由CPU读取并进行计算,将计算的结果再次加载到内存中,最后再由内存写入磁盘,通过输出设备将数据交给我们。那么,为什么CPU为什么不能直接访问外设呢?
其实原因也很简单,输入输出设备称之为外围设备,外设一般是很慢的,比如说磁盘,相对于内存,他的速度是非常慢的,但CPU的计算速度确是非常快的。就好比从磁盘的读取速度很慢,但是CPU的计算速度却很快,但是整体的速度还是以磁盘的读取速度为主的,所以整体效率就以外设为主。
所以在这里得出了两个结论:
- 在数据层面上,一般CPU不和外设直接沟通,而是直接和内存打交道。
- 在数据层面上,外设指挥和内存打交道。
所以说,程序的运行必须加载到内存中,因为CPU想要执行我们的程序,访问我们的数据,就必须从内存中读取,这是冯诺依曼体系结构规定的。
💕 那么,在硬件层面,单机和跨主机之间的数据流是如何流向的呢?
对冯诺依曼的理解,不能停留在概念上,要深入到对软件数据流理解上,那么,当你从登录上qq开始和某位朋友聊天开始,整个信息是如何在体系结构中流动的?
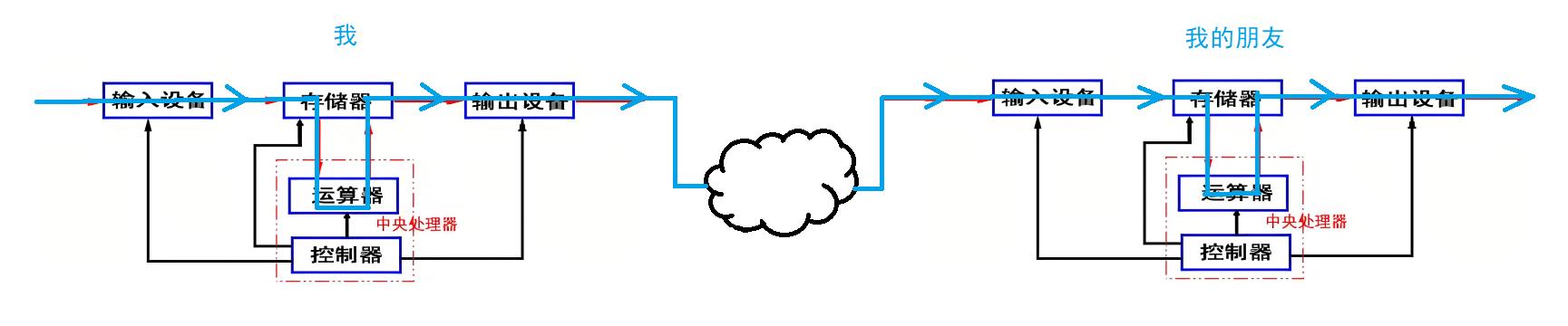
当我和我的朋友同时打开QQ时,我们的QQ其实已经被加载到内存中了,然后当我们在对话框中输入消息时,我们的数据已经被输入到内存中了,下面我们的数据在内存中被加密计算,计算完之后将数据返回到内存,然后显示到输出设备,也就是我们的显示器和网卡上,这时我们就可以在显示器上看到我们所发送的消息了。
紧接着,我们的数据还会通过网卡输入到对方的电脑上,对方通过网卡接收到数据后,加载到内存中,然后通过CPU将数据进行解密操作并写回内存,最后通过输出设备显示到对方的显示器上。
2. 操作系统
操作系统是一款进行软硬件资源管理的软件,在这里我们先来解释一下,为什么操作系统要对软硬件进行管理呢?
其实是因为,操作系统对下要管理好软硬件资源,对上需要给用户提供良好(安全、稳定、高效、功能丰富等)的执行环境。
那么我们应该如何理解操作系统对硬件做管理呢?其实,管理的本质就是对数据进行管理,管理的方法是:先描述、后组织。
💖 管理的本质是对数据进行管理
对于这一点,我们应该如何理解呢?我们可以以学校为例:假设学校只有校长、辅导员和学生。那么在这里,校长就是我们的管理者,同时也是做决策的人,而辅导员呢就是执行者,最后辅导员把决策交给我们学生,学生才是真正的被管理者。
因为管理的本质就是数据进行管理,但在这里我们需要考虑的是,管理者是如何拿到被管理者的数据的呢?就好比说,校长是如何拿到我们学生的数据的呢?其实也很简单,通过辅导员拿到的了。而校长只要管理好我们学生的这些数据,就能将学生管理起来了,所以管理的本质就是对数据做管理。
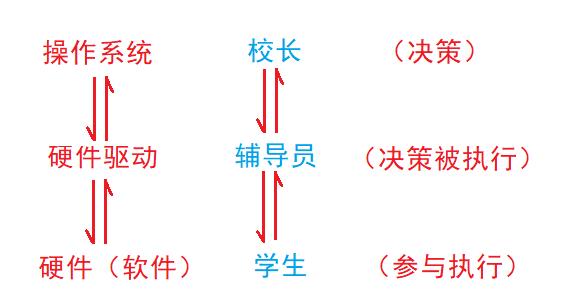
💕 管理的方法是先描述、后组织
这里我们可以想一下,学校的学生那么多,校长是如何管理的呢?这里我们提出了一种方法,叫做 ‘先描述、后组织’,
先描述,就好比先将将被管理者的数据抽象成一个结构体(类),后组织,就是使用各种数据结构将数据管理起来,这里我们可以先将学生的各种信息定义一个结构体,然后,将学生们通过链表链接起来,那么现在对学生数据做管理就变成了,对链表的管理。
当然了,对应到我们的计算机中,操作系统就相当于我们的管理者,而硬件驱动就相当于我们的执行者,而硬件(软件)就是我们被管理者。
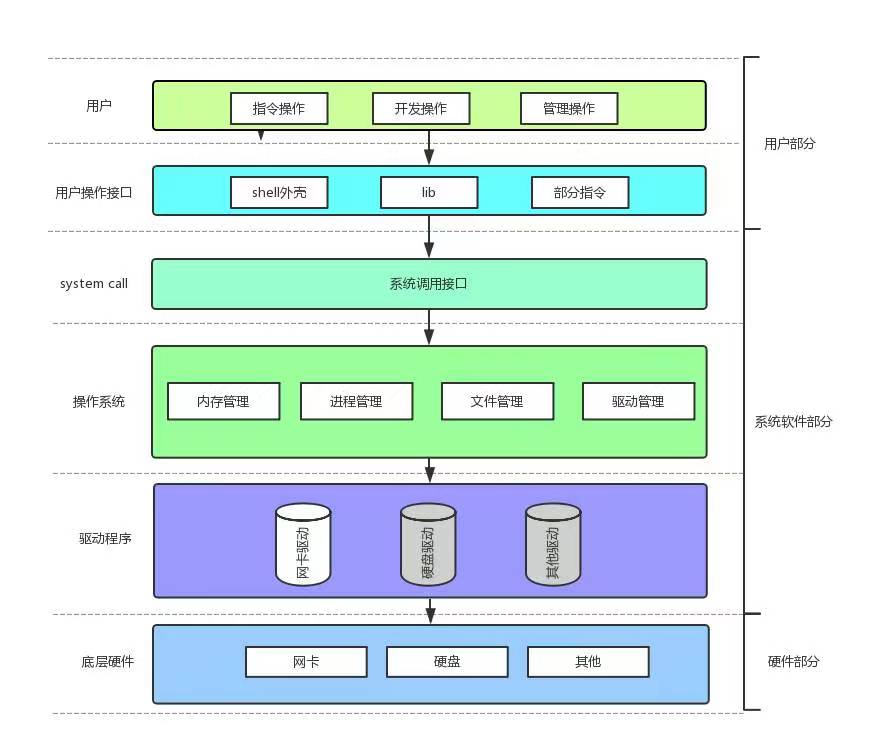
当然了,我们的操作系统也是不相信任何人的,为了保护操作系统不受到任何的侵害,但是又必须又必须给上层用户提供服务,在用户和操作系统之间有一层系统调用接口,但由于系统调用接口的使用成本很高,所以相关人员就在系统调用上面进行了二次软件开发,例如:图形化界面、shell和工具集等。
系统调用和库函数:
- 在开发角度,操作系统对外会表现为一个整体,但是会暴露自己的部分接口,供上层开发使用,这部分由操作系统提供的接口,叫做系统调用。
- 系统调用在使用上,功能比较基础,对用户的要求相对也比较高,所以,有心的开发者可以对部分系统调用进行适度封装,从而形成库,有了库,就很有利于更上层用户或者开发者进行二次开发。
计算机的体系结构图
3. 进程
进程的基本概念
进程 在课本中的描述一般为:程序的一个执行实例,正在执行的程序,或者是一个程序运行起来(程序被加载到内存)就是进程,进程的内核观点是担当分配系统资源(CPU时间,内存)的实体。但是这些概念都很肤浅,我们应该如何去描述一个进程呢?
💕 描述进程
- 进程信息被放在一个叫做进程控制块的数据结构中,可以理解为进程属性的集合。
- 课本上称之为PCB(process control block), Linux操作系统下的PCB是:
task_struct
当我们把多个程序加载到内存中时,操作系统会对这些程序进行先描述,后组织。那么操作系统是如何对我们的程序进行描述和组织的呢?
我们将写好的代码编译链接形成可执行程序存放在磁盘上,然后我们运行这个程序时,需要先将这个程序加载到内存中,然后通过CPU进行运算。当我们的程序加载到内存中时,操作系统会对我们的程序进行管理,对程序的管理方法我们在上面也提及到了:先描述,在组织。
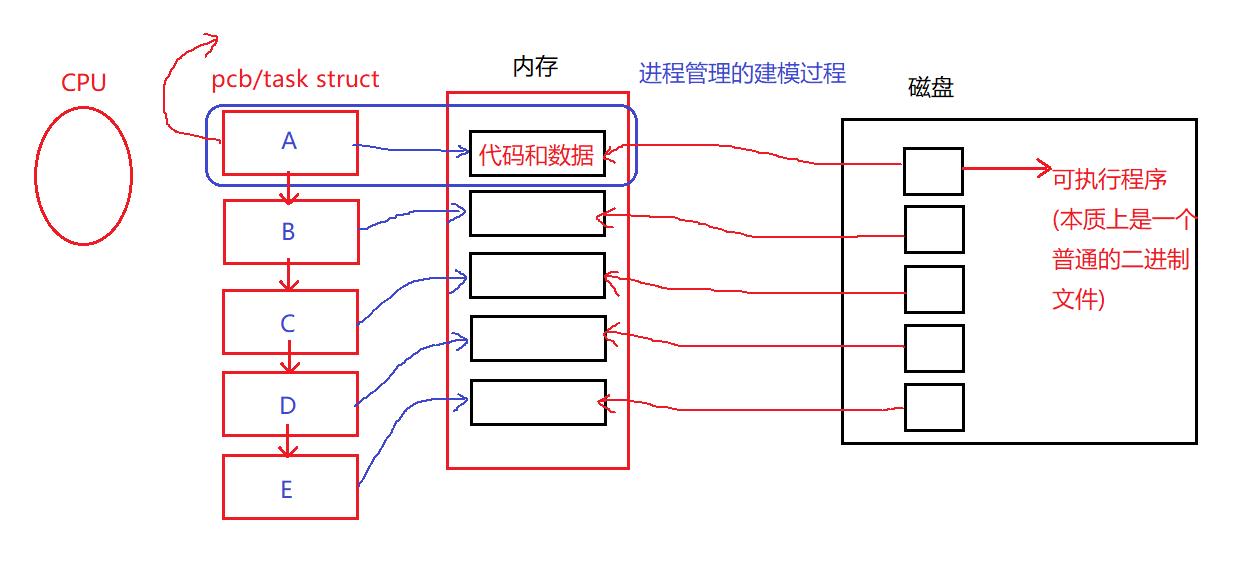
操作系统在对我们的进程进行先描述,后组织的时候,会先将我们的程序的共有属性创建一个结构体,然后对我们的每一个进程创建一个结构体对象,这就是先描述的过程。接下来我们的操作系统会使用特性的数据结构(比如链表)将我们的结构体对象组织起来,这就是后组织的过程。然后我们的操作系统对进程的管理就会转换成对特定数据结构的管理。当然了,这个描述和组织进程的东西就被称为进程控制块(PCB)。
所以,在这里我们也引出了进程真正的概念:进程=内核关于进程的相关数据结构+当前进程的代码和数据。
进程控制块(PCB) 是我们操作系统用来描述进程的工具,他包含了进程属性的集合。在Linux中描述进程的结构体叫做task_struct。他是Linux内核的一种数据结构,它会被装载到
RAM(内存)里并且包含着进程的信息。
下面我们看一下task_ struct内容分类:
- 标示符: 描述本进程的唯一标示符,用来区别其他进程。
- 状态: 任务状态,退出代码,退出信号等。
- 优先级: 相对于其他进程的优先级。
- 程序计数器: 程序中即将被执行的下一条指令的地址。
- 内存指针: 包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针
- 上下文数据: 进程执行时处理器的寄存器中的数据[休学例子,要加图CPU,寄存器]。
- I/ O状态信息: 包括显示的I/O请求,分配给进程的I/ O设备和被进程使用的文件列表。
- 记账信息: 可能包括处理器时间总和,使用的时钟数总和,时间限制,记账号等。
- 其他信息
查看进程和杀死进程
💕 查看进程
再查看进程之前我们需要先创建写一段普通的C语言代码:
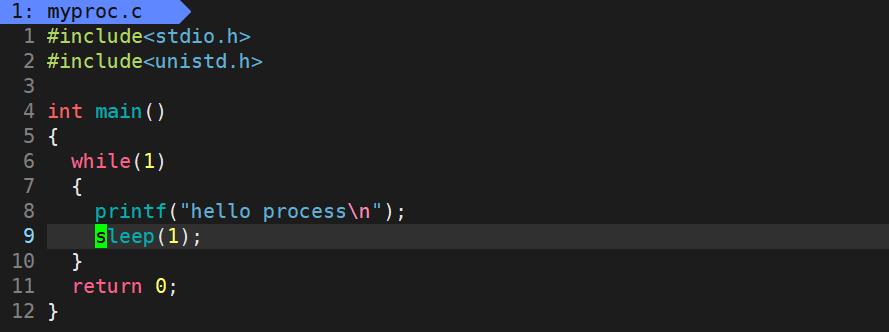
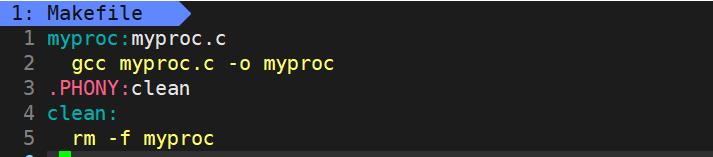
查看进程有两种方式,这里我们先来讲解第一种:
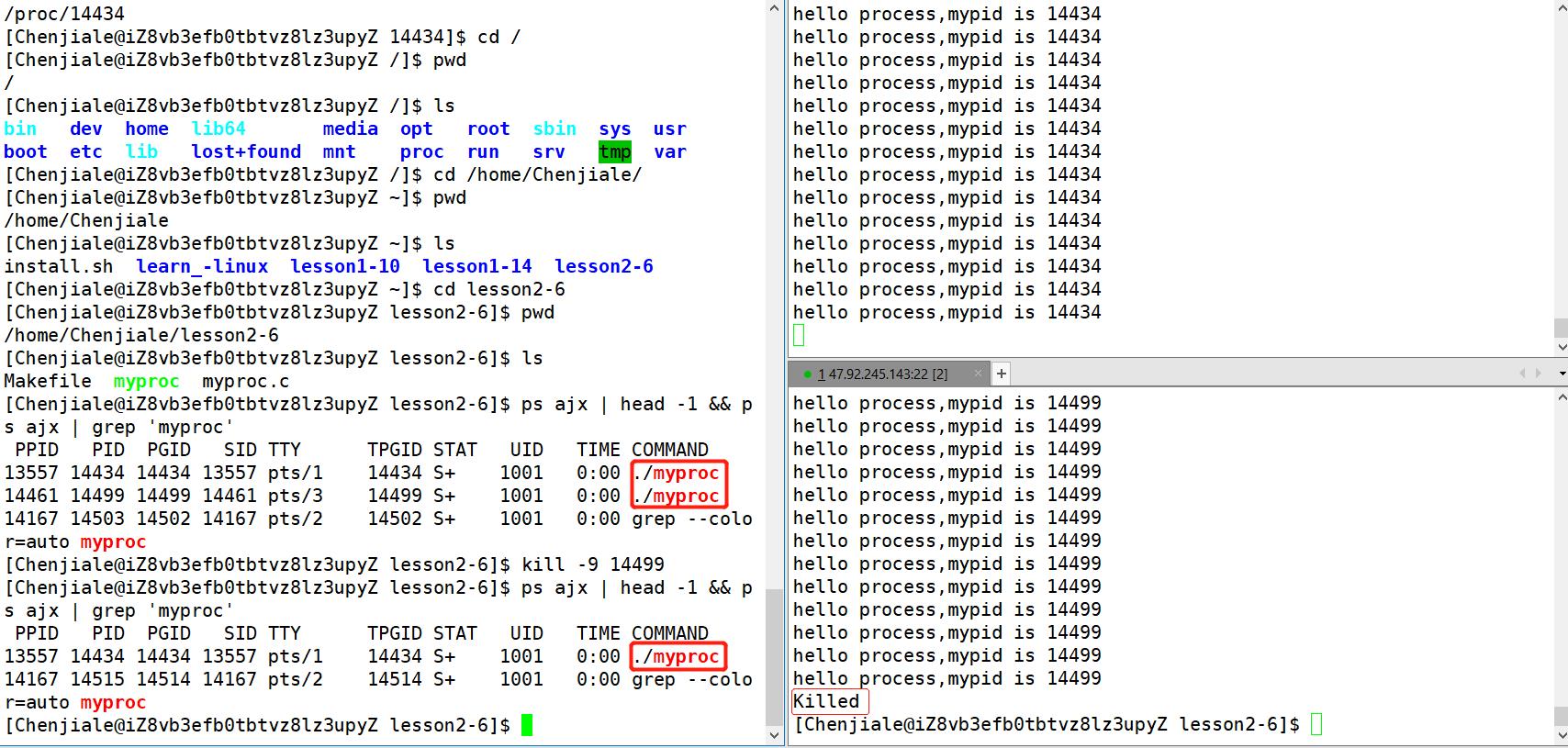
ps ajx | head -1 && ps ajx | grep '进程名'
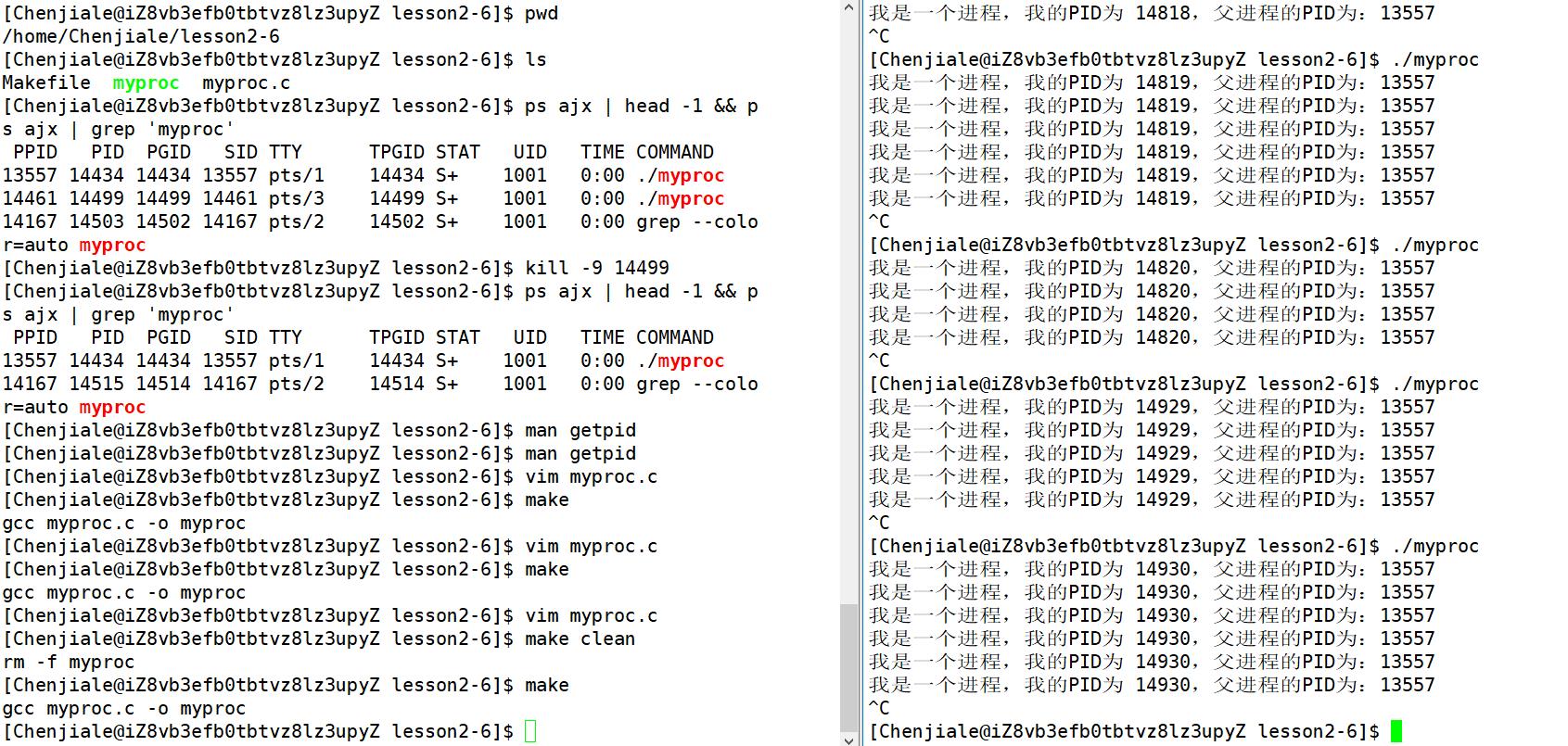
当然了我们需要先将我们的程序运行起来:
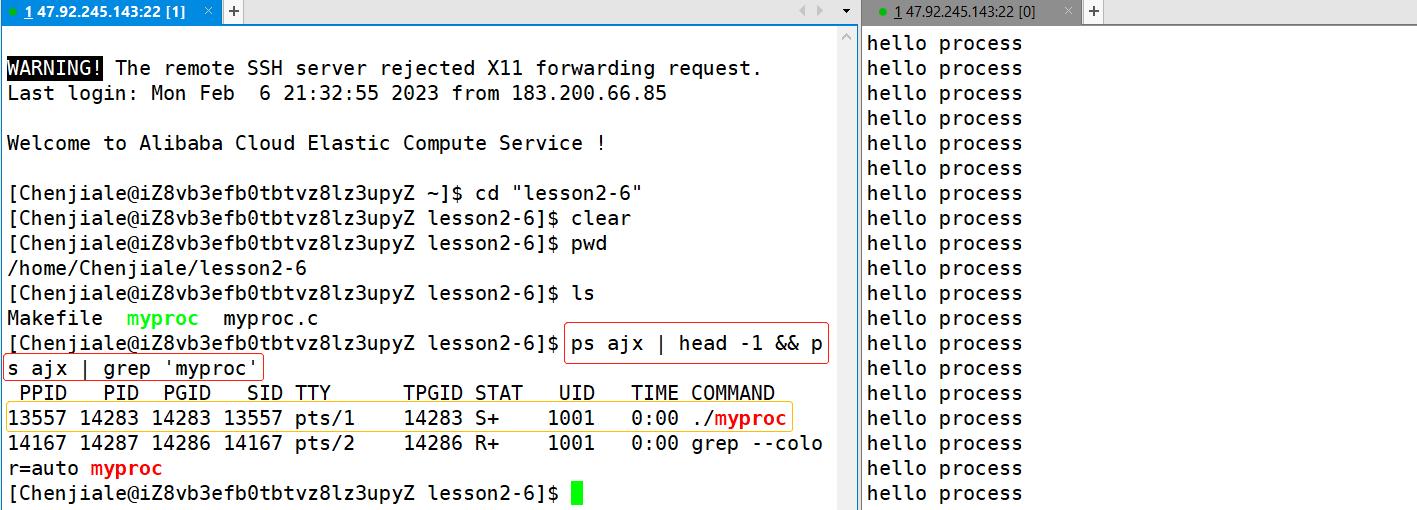
这里我们还可以看到在我们的myproc进程的下面还有一个grep进程,这是因为grep指令也是一个进程,进程在调度的时候是具有动态属性的。这里我们还需要解释一个概念那就是PID和PPID的概念,操作系统里指进程识别号,也就是进程标识符。操作系统里每打开一个程序都会创建一个进程ID,即PID。 当然了,PPID就是父进程的进程ID号。
查看进程的第二种方式:通过查看进程目录 ls /proc 来查看进程
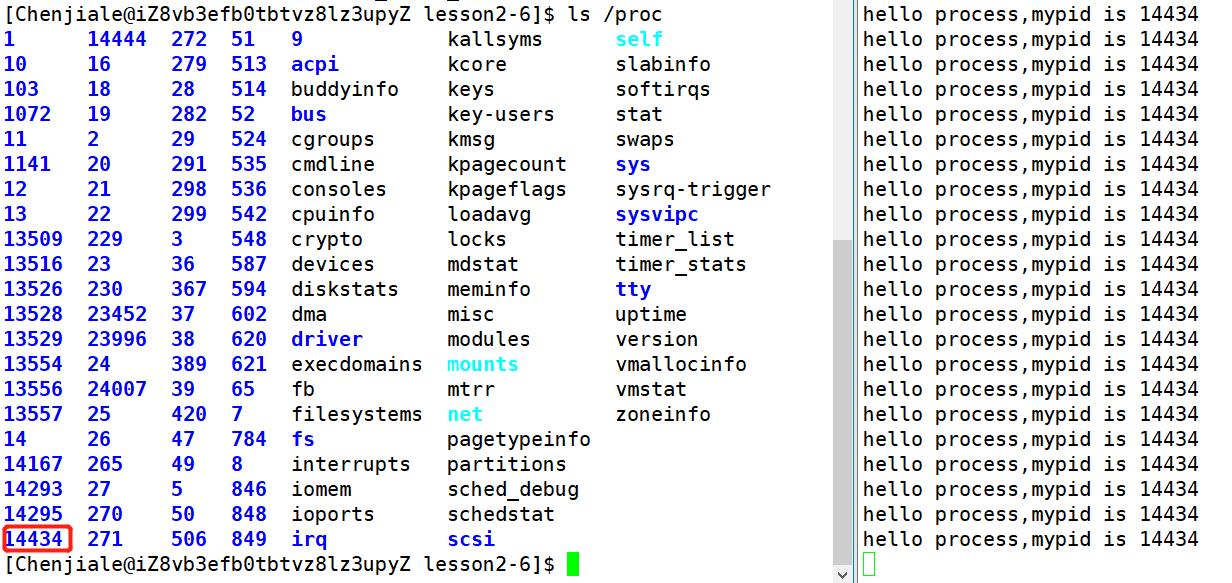
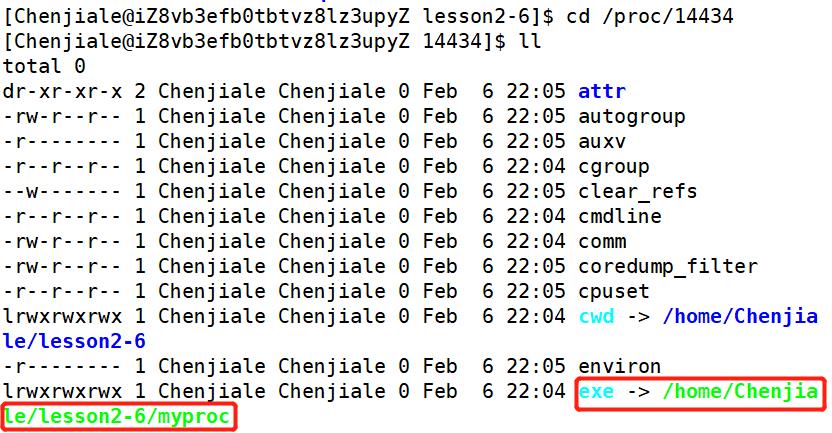
当然了我们还可以直接到==/proc/进程pid==目录下去查看进程对应的可执行程序。
💕 杀死进程
我们要结束我们的进程可以有两种方法:直接按ctrl+c结束进程或者杀死进程。杀死进程需要的命令是:kill -9 进程标识符
父进程和子进程
上面我们已经介绍了父进程和子进程有各自的进程ID,但是究竟什么是父进程呢?什么又是子进程呢?其实,我们平常所写的进程都是由bash这个父进程来创建的,bash其实就是shell外壳,shell为了防止自身奔溃,一帮会通过派生子进程的方式去执行我们的指令。
我们可以通过getpid和getppid函数来获取当前进程的ID和当前进程父进程的ID。下面我们来看一下这两个函数:
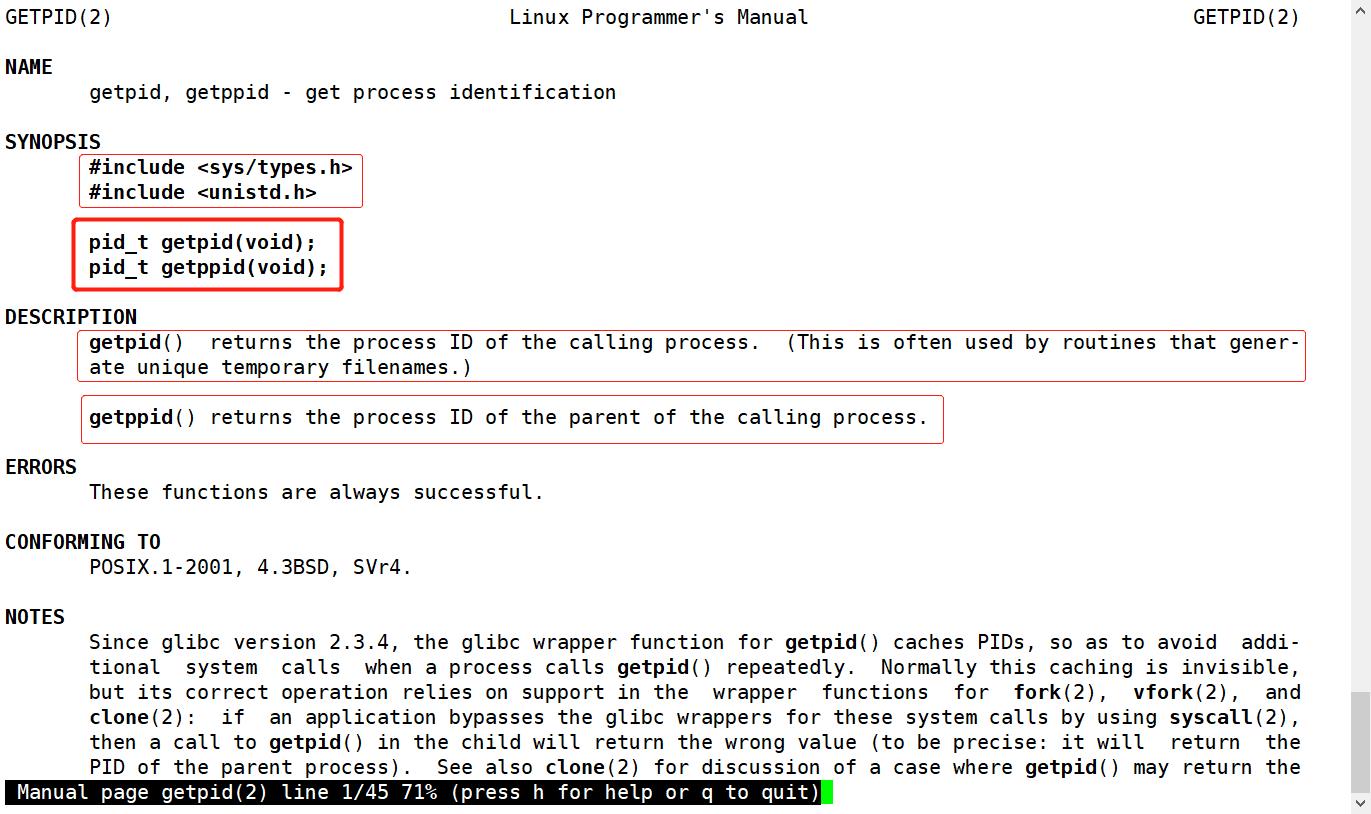
这里我们修改一下我们的程序,看一下父进程和子进程的ID:
如果我们把我们的程序终止掉,然后再次运行的时候,就会发现子进程的ID一直在变,而父进程的ID却不变。那么我们现在来看一下这个父进程究竟是什么?

这是我们就可以恍然大悟了,原来该父进程就是bash,bash通过创建子进程的方式来运行我们的程序,那么shell是如何创建子进程的呢?下面就让我们来认识一下如何创建子进程。
通过系统调用创建子进程
我们先通过 man fork 来认识一下fork函数:
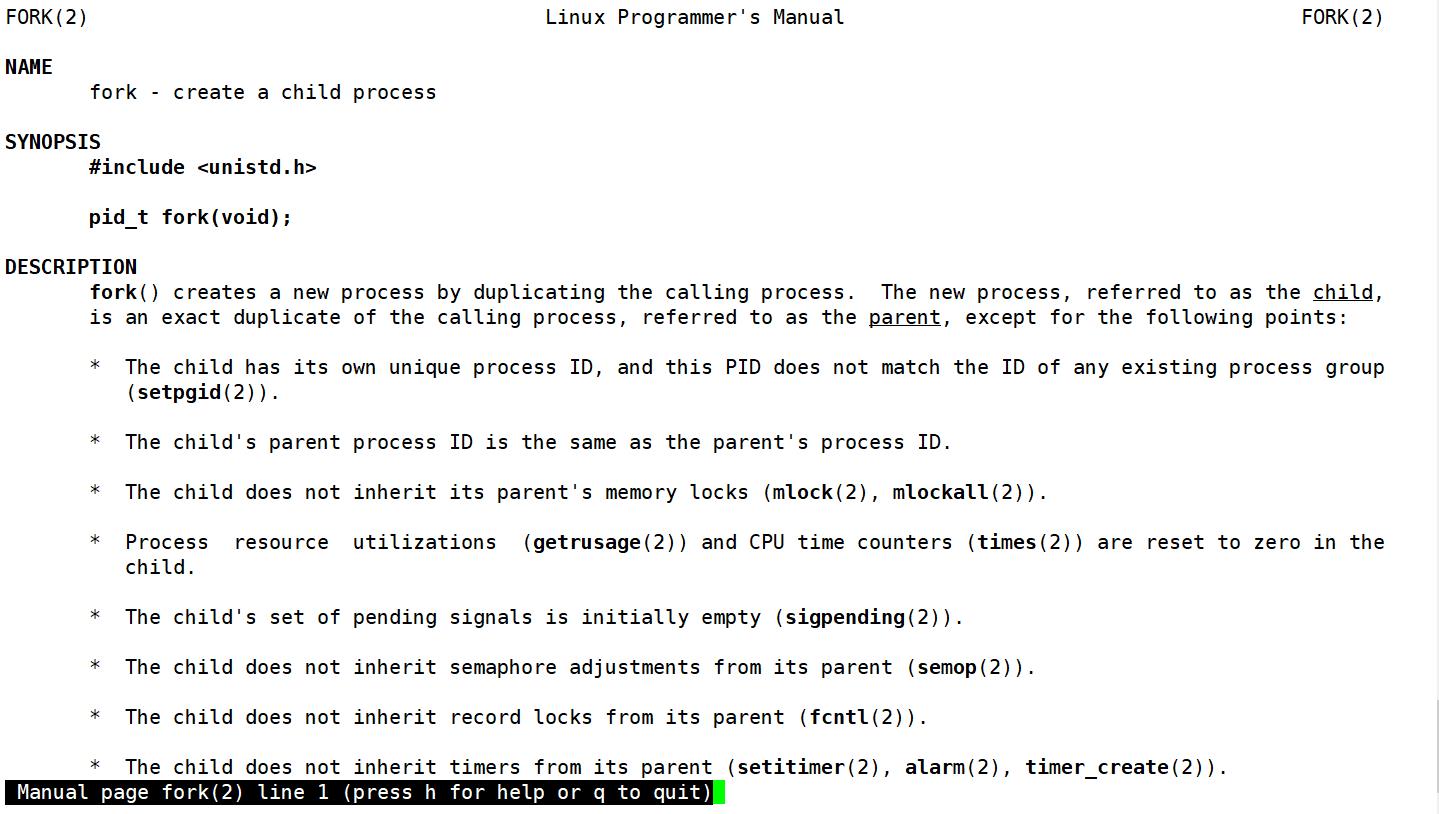
fork函数的返回值是fork函数的重点,如果子进程创建成功,fork函数给父进程返回子进程的id,给子进程返回0,如果子进程创建失败将会给父进程返回-1。
这里我们先修改一下我们的代码:
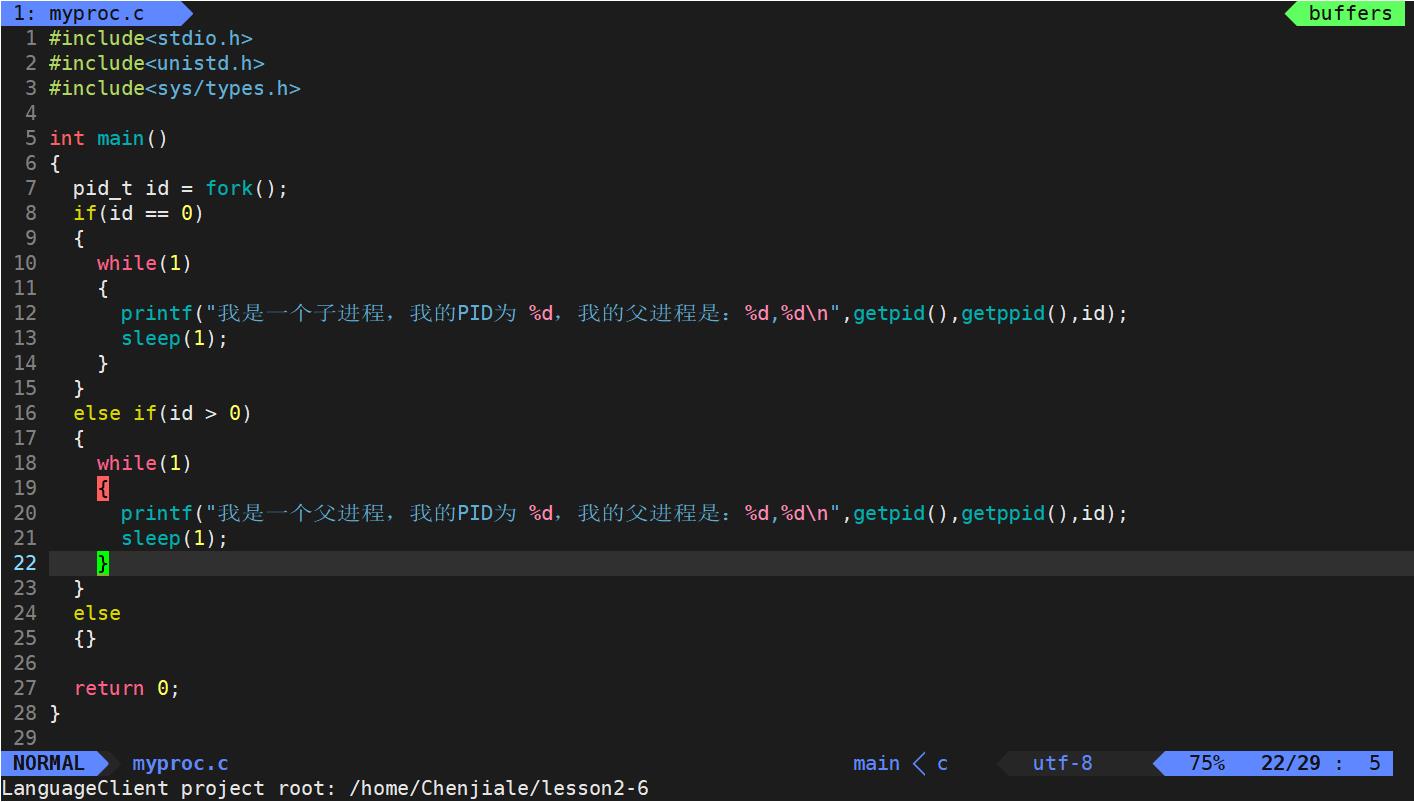

但是这个代码为什么可以既执行if里面的语句,又可以执行if else里面的代码呢?
结论:
- fork之后,执行流会变成2个执行流。
- fork之后,谁先运行由调度器决定。
- fork之后的代码共享,通常通过
if和elseif来进行执行流分流。
下面我们再来看一个更离谱的事情,我们将代码中的内容做出如下修改:


以上问题我们都可以归结为三点:
- fork做了什么?
- fork是如何看待代码和数据的?
- fork如何理解两个返回值问题?
💕 fork做了什么?
子进程会创建一份独立的pcb结构,但子进程的pcb的大部分属性都是以父进程为模板进行拷贝的,当然了对于PID和PPID这些值是不能拷贝的。

💕 fork是如何看待代码和数据的?
进程在运行的时候,是具有独立性的,当然父子进程再运行的时候也是具有独立性的,如果我们父子进程同时运行但我们把其中任意一个进程杀死后,并不会影响另一个进程。当然如果父子进程中有相同的变量,但我们修改父进程或子进程中的任意一个数据时,操作系统会在当前进程中触发
写时拷贝。
💕 fork是如何理解两个返回值问题的?
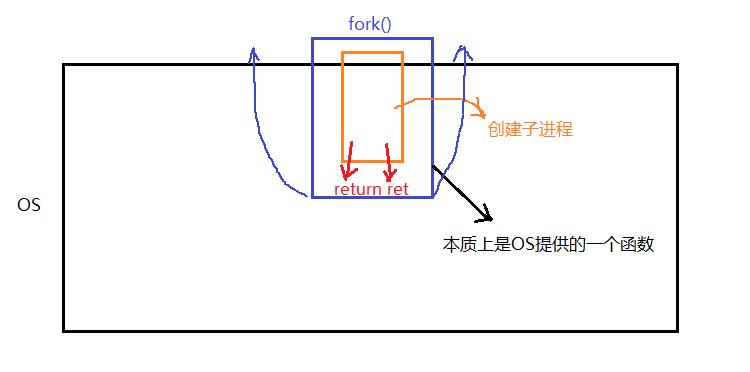
当我们的函数执行return功能之前其实函数中的主体部分就已经完成了,但是return也是一条语句,在这之前子进程已经被创建,甚至可能已经被调度,我们在执行return时,父进程可以被调度执行一次,而子进程也有它的执行流,所以return也会被调度执行一次。所以一条return就被执行了两次,好像让我们看到了两个返回值。
以上是关于Linux操作系统&&进程概念的主要内容,如果未能解决你的问题,请参考以下文章