python进阶--pandas基本功能
Posted 文仙草
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python进阶--pandas基本功能相关的知识,希望对你有一定的参考价值。
一、调用pandas
- import pandas:导入pandas包,后续代码就可以使用pandas包里定义好的功能了。
- import pandas as pd:
相当于将pandas包重命名为pd,这样之后使用pandas包的功能的时候,直接写pd,而不需要写pandas,更省事。
二、打开和保存文件
(一)打开文件
1. 打开excel、csv文件
- pd.read_csv(filepath)
import pandas as pd
filepath = 'E:\\\\python\\\\test.csv'
df = pd.read_csv(filepath)
- pd.read_excel(filepath)
import pandas as pd
filepath = 'E:\\\\python\\\\test.xlsx'
df = pd.read_excel(filepath)
2. 打开json文件
- json.load
import json
with open ('filename.json','r') as openfile:
json_object = json.load(openfile)
3. 打开XML文件
python没有专门的包可以直接打开xml文件,可以parse
import pandas as pd
import xml.etree.ElementTree as etree
tree = etree.parse('filexmaple.xml')
root = tree.getroot()
columns = ['name', 'age', 'birthday']
df = pd.DataFrame(columns = columns)
for node in root:
name = node.find('name').text
age = node.find('age').text
bday = node.fine('birthday').text
可以在打开文件的时候,将第一行设置为header(即列名称)。或者可以手动添加header
- 设置第一行:df = pd.read_xlsx(filepath, header = 0)
- 手动添加:df.columns = [‘name’, ‘class’, ‘age’]
(二)保存文件
- df.to_csv(filepath&name)
将文件保存为csv格式,注意不要忘记写后缀。
如果参数index = False,表示行名称不会被保存.
df.to_csv('new_file.csv')
df.to_csv('E:\\\\python\\\\new_file.csv')
-
其他文件格式的打开和保存
| Data Formate | Read | Save |
|---|---|---|
| csv | pd.read_csv() | df.to_csv() |
| json | pd.read_json() | df.to_json() |
| excel | pd.read_excel() | df.to_excel() |
| hdf | pd.read_hdf() | df.to_hdf() |
| sql | pd.read_sql() | df.to_sql() |
| … | … | … |
三、初查和清理数据
(一)初查数据
- df.head(): 展示前五行数据
- df.tail(): 展示后五行数据
- df.info(): 展示df的基本信息,包括列名及数据类型、每列非Na数据的计数、内存使用等。
- df[‘name’].unique(): 剔除该列数据的重复项。
- df.describe(): 展示数据类型为数字(int, float)的列数据的统计信息,比如计数、平均值、最大值、最小值、方差等;
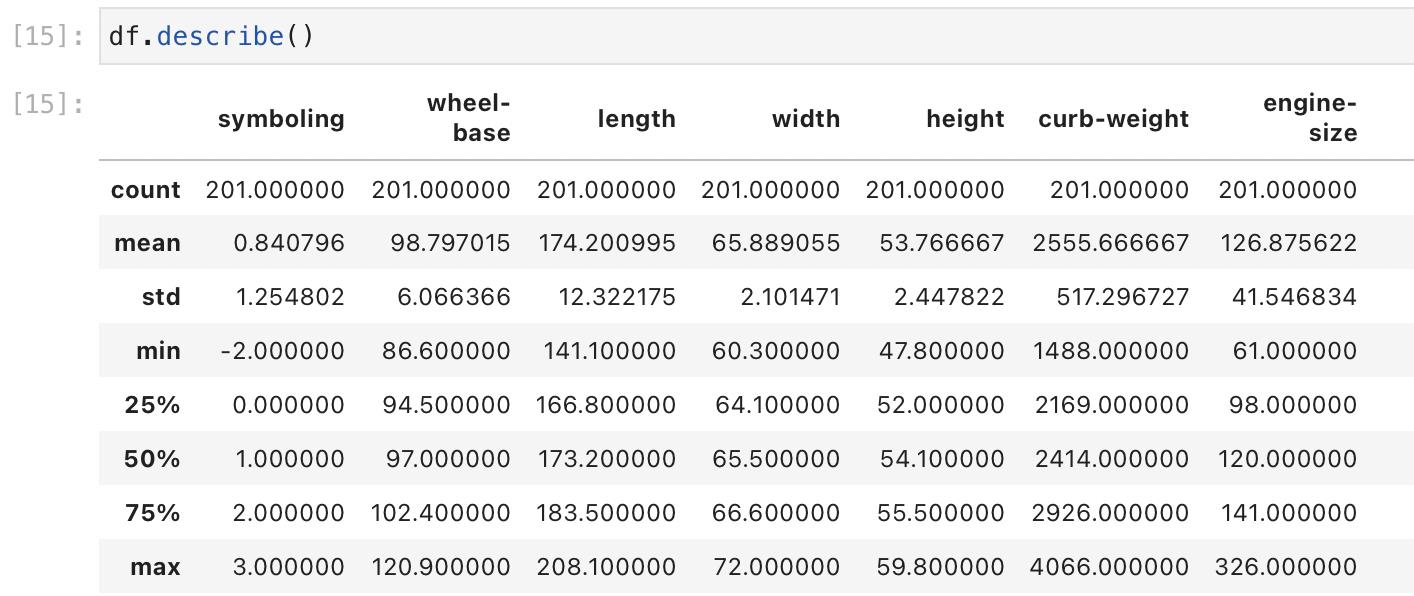
- df.describe(include = ‘all’)用于展示所有列数据(包括非数据类型的列数据)的统计信息,对于非数字类型的列数据,平均值、最大值、最小值等返回NaN。

- df.dtypes: 查看各列数据的数据类型
- df[‘column_name’].value_counts(): 查看该列中各值出现的次数。
- df[‘column_name’].value_counts().idxmax():查看该列中数值出现最高的。
df['door_num'].value_counts()
#结果
#four 114
#two 89
#Name: num-of-doors, dtype: int64
df['door_num'].value_counts().idxmax()
#结果
#'four'
(二)清理数据
- 修改index列:将df的index修改为df中的’Date’列
- df.index = df[[‘Date’]]
- df.set_index('Date)
- 重置index列:df.reset_index(),将index重置为以0开头的整数
reset_index功能里有inplace参数,inplace=True会在数据里增加一列index(如下图)
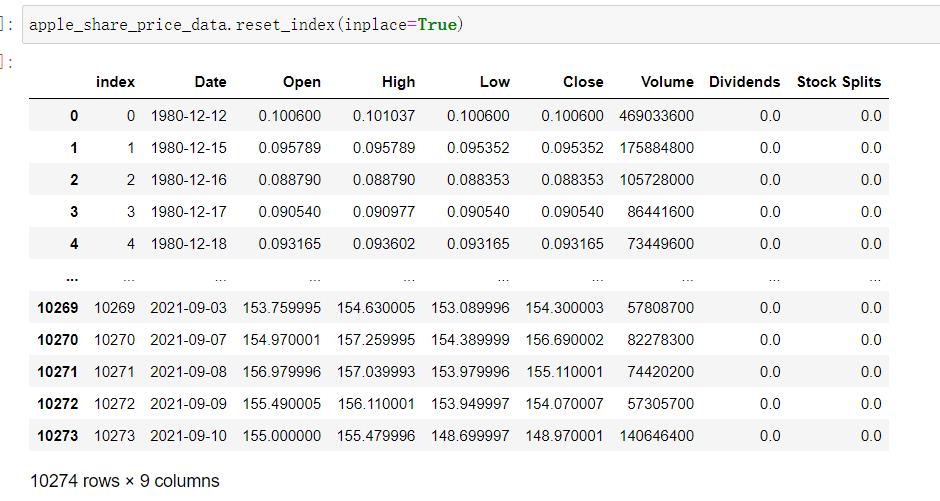
inplace=False,不会在数据里增加一列index(如下图)

- df.columns = [“symboling”,“normalized-losses”,“make”] :添加列名称
- df.rename(columns = ‘old-name’:‘new-name’, inplace = True):修改列名称,将old-name修改为new-name
- df.replace(missing_value, new_value):
df1 = df.replace(’?’,np.NaN) :将数值为“?”的单元格替换为NaN,替换后的新dataframe返回给df1。该功能搭配.dropna()可用于删除缺失数据。 - df1.dropna(subset=[“price”], axis=0, inplace = True) ,将price列中数值为NaN单元格所在行的数据整行删除。 如果axis = 1,表示删除NaN数值所在列(即price列)。inplace = True代表对df本身改动,inplace = False代表生成新的df
#删除na数据所在行,inplace=True
df1.dropna(subset=["price"], axis=0, inplace = True)
#删除na数据所在行,inplace=False
df = df1.dropna(subset=["price"], axis=0, inplace = False)
#因为删除了na列,所以重置index列
df.reset_index()
- df.astype(): 修改数据类型。
#price列的数据类型修改为int。
df['price'] = df['price'].astype(int)
#或者也可以
df[['price']] = df[['price']].astype(int)
#修改bore和stroke两列的数据类型
df[["bore", "stroke"]] = df[["bore", "stroke"]].astype("float")
示例1 - 将列名为stroke列中的缺失数据替换成该列的平均值
#由于不确定该列数据的数据类型是否为数字,所以先将该列数据的数据类型修改为float
avg_stroke = df['stroke'].astype('float').mean(axis = 0)
#print(avg_stroke)
df['stroke'].replace(np.nan, avg_stroke, inplace = True)
(三)数据标准化和标注
1、simple scaling
将不同范围大小的数据进行标准化,使其范围控制住0-1之间,从而使不同范围的数据具有可比性。常见方法是用原数据除以该列数据的最大值,即用 (原数据)/(数据最大值)替换原数据
# 用(original value)/(maximum value)替换original value
df['length'] = df['length']/df['length'].max()
df['width'] = df['width']/df['width'].max()
2、数据分组
将连续数据按照一定规则进行分组,使原连续数据离散。
- 使用numpy的函数np.linspace(start_value, end_value, numbers_generated),设定范围和组数
- group_names = [‘Low’, ‘Medium’, ‘High’]创建各组名称
- 利用pandas里的cut函数,将列中的数值划分至设定好的组别中。
#将horsepower列分成3组,以最小值开始,以最大值结束,分三组,所以需要4个切割点)
bins = np.linspace(min(df["horsepower"]), max(df["horsepower"]), 4)
bins
#结果:创建的3个组别的边界值
#array([ 48. , 119.33333333, 190.66666667, 262. ])
group_names = ['Low', 'Medium', 'High']
df['horsepower-binned'] = pd.cut(df['horsepower'], bins, labels=group_names, include_lowest=True )
df[['horsepower','horsepower-binned']].head(5)
运行结果
| horsepower | horsepower-binned | |
|---|---|---|
| 0 | 111 | Low |
| 1 | 111 | Low |
| 2 | 154 | Medium |
| 3 | 102 | Low |
| 4 | 115 | Low |
3. indicator variable(也称为dummy variable)
An indicator variable (or dummy variable) 是一种用数值对变量进行标注的方式(例如:在员工统计中将男性标为1,女性标为0)。这种方法被称为“dummy”,是因为用于标注的数据与数值本身的含义没有关系。这种数据标注方法常用于回归分析。
函数 pd.get_dummies(需要打标的列)
df['fuel-type'].value_counts()
#结果:fuel-type列有两个值gas和diesel
#gas 181
#diesel 20
#Name: fuel-type, dtype: int64
#对fuel-type列进行标注,即
四、创建DataFrame
- 将字典变成DataFrame结构:key是列名,value是每列数值
python student = 'name': ['Eva', 'Bob', 'John','Cathy', 'Kate'], 'age': ['15', '16', '15','17','16'], 'gender': ['f', 'm', 'f', 'f', 'm'] student_df = pd.DataFrame(student)
五、常用方法
(一)从DataFrame结构的数据中选取一列数据
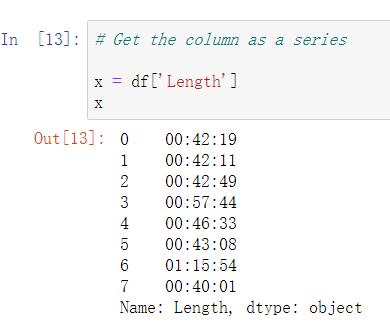
-
直接选取,Series格式:df[‘列名’] (注意:是一个方括号)
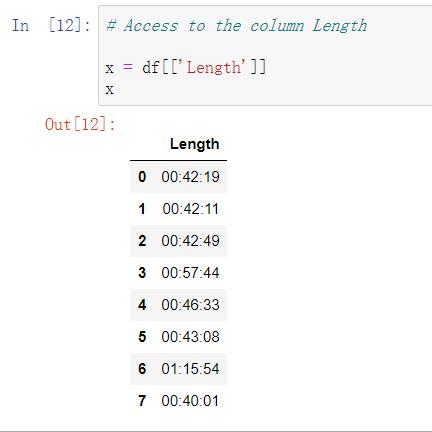
- 按dataframe格式:df[[‘列名’]] (注意:是两个方括号)
- 按dataframe格式:df[[‘列名’]] (注意:是两个方括号)
(二)从DataFrame结构的数据中选取多列数据
格式:df[[‘列名1’,‘列名2’,‘列名3’]] ,注意是两个方括号
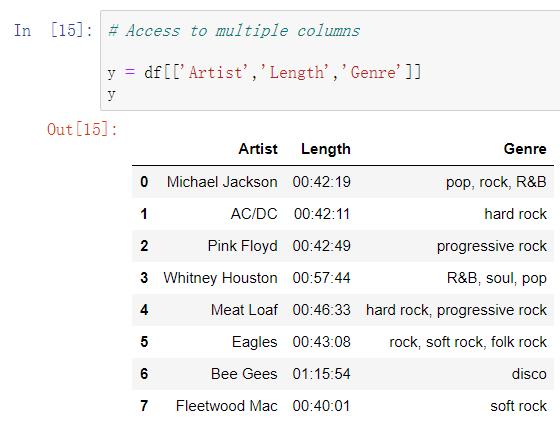
如果只有一个方括号会报错

(三)获取第n行、第m列单元格的数值
- 用数字定位:df.iloc[n,m]
注意:标题列不算行数,行数据和列数据的序号n、m均从0开始,所以获取第一行、第一列单元格数据时,应该是df.iloc[0,0]
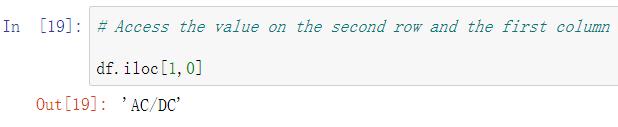
2)用列名定位获取数据
获取第二行中’Artist‘列的数据(注意,此处的第二行是指实际数据的第二行,而其行序号为1),如图

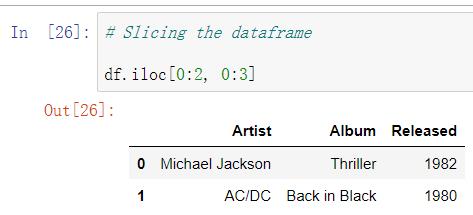
(四)获取多行多列数据(数据切片)
- 用序号:df.iloc[i:j, n:m]
例如获取第1到2行、1到3列的数据,如下图:
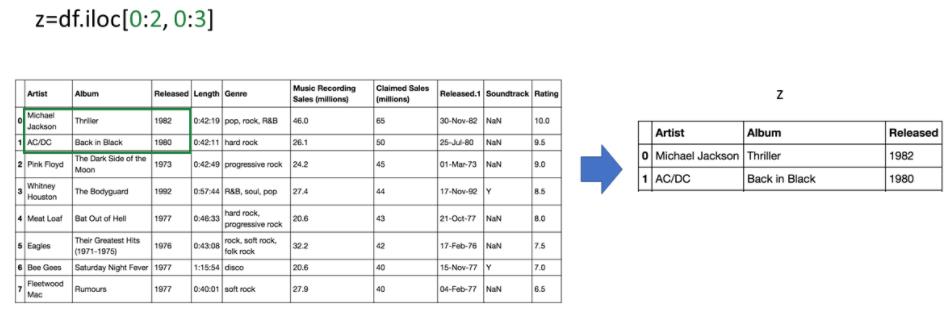
上图获取的数据在整个数据表中的位置如下图:
- 用列名: df.loc[i:j, ‘列名’:‘列名’]
.loc与.iloc对行数据切片的不同之处,需特别注意!! df.loc[i:j]是获取行序号从第i行到第j行;而在使用df.iloc[i:j]时获取第i行到第j-1行数据。
如下图,df.loc[0:2, :]获取了前三行数据,而上面df.iloc[0:2,:]获取了前两行数据。

(三)选择列数据满足特定要求的行数据
df1 = df[df[‘gender’] = ‘f’]: 满足条件的返回True, 反之返回False; 为True的行被选中,为False的行被剔除。 df2 = df[df[‘age’]>16]
(四)选择满足特定值的行数据
可以对特定的列:选择A列中包含任一数值’1’,‘2’,'3’的行,df[df[‘A’].isin([‘1’,‘2’,‘3’])]
也可以对整个dataframe:df.isin([‘1’,‘2’,‘3’])
可以对多列进行筛选:df[df[某列].isin(条件)&df[某列].isin(条件)]
以上是关于python进阶--pandas基本功能的主要内容,如果未能解决你的问题,请参考以下文章