11.采集手机端app企查查上司公司数据
Posted 五杀摇滚小拉夫
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了11.采集手机端app企查查上司公司数据相关的知识,希望对你有一定的参考价值。
---恢复内容开始---
采集企查查手机端app数据:
1.首先手机端安装app并usb连接电脑端,fiddler监控手机请求数据对数据进行分析抓取。
手机端界面与fiddler界面参照:
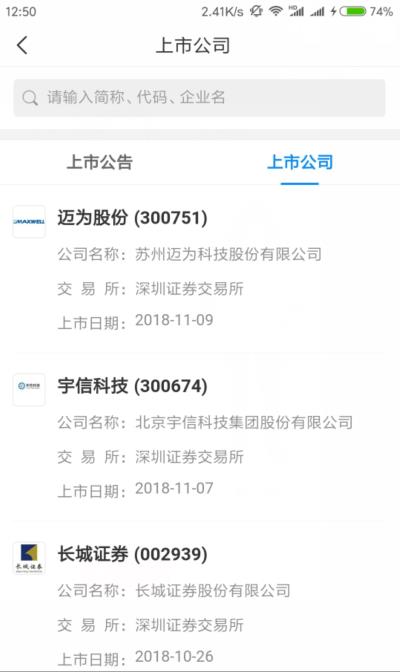
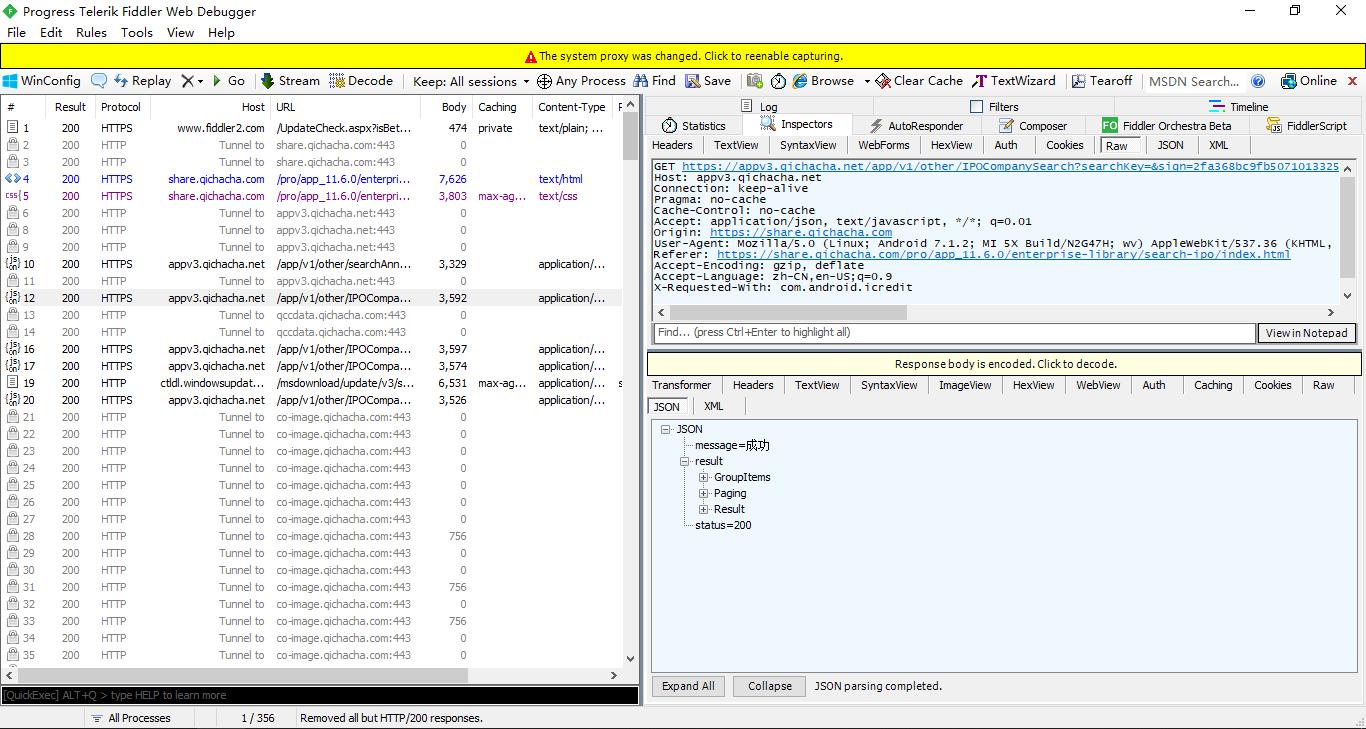
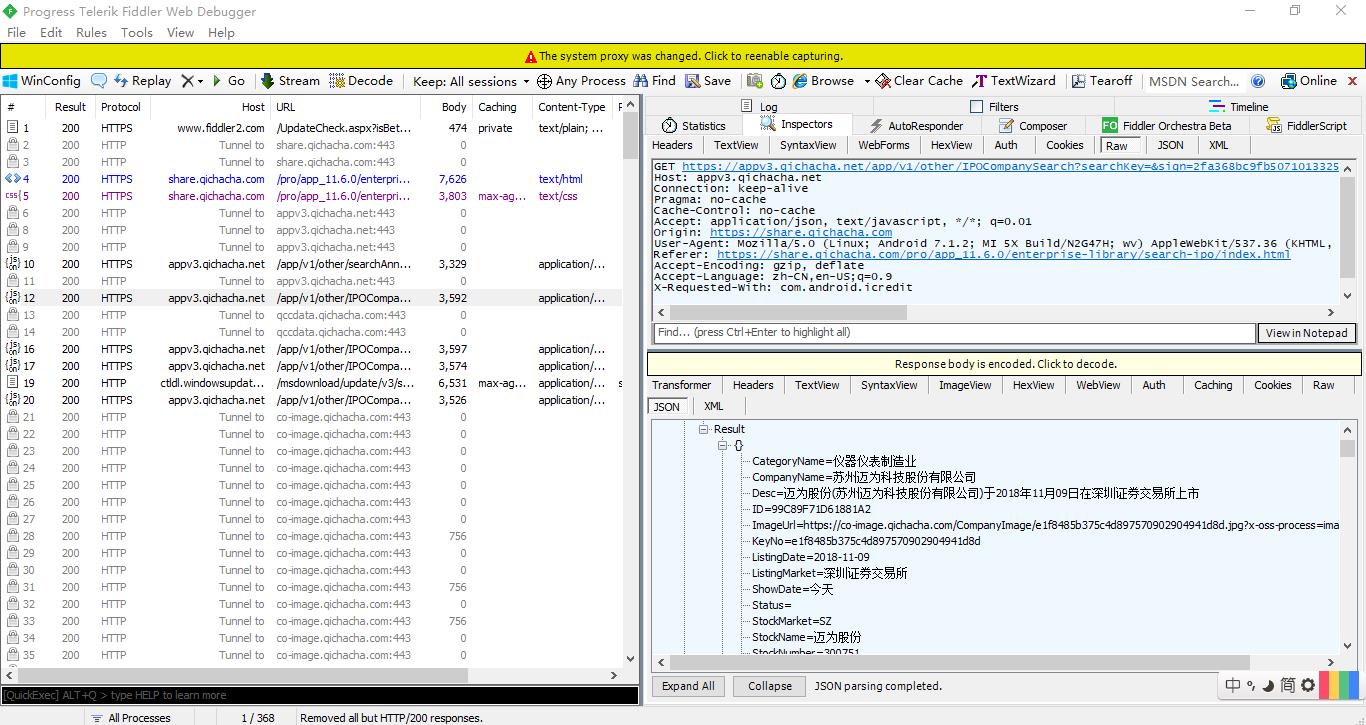
2.对获取到url进行分析
试采集当前页面信息:
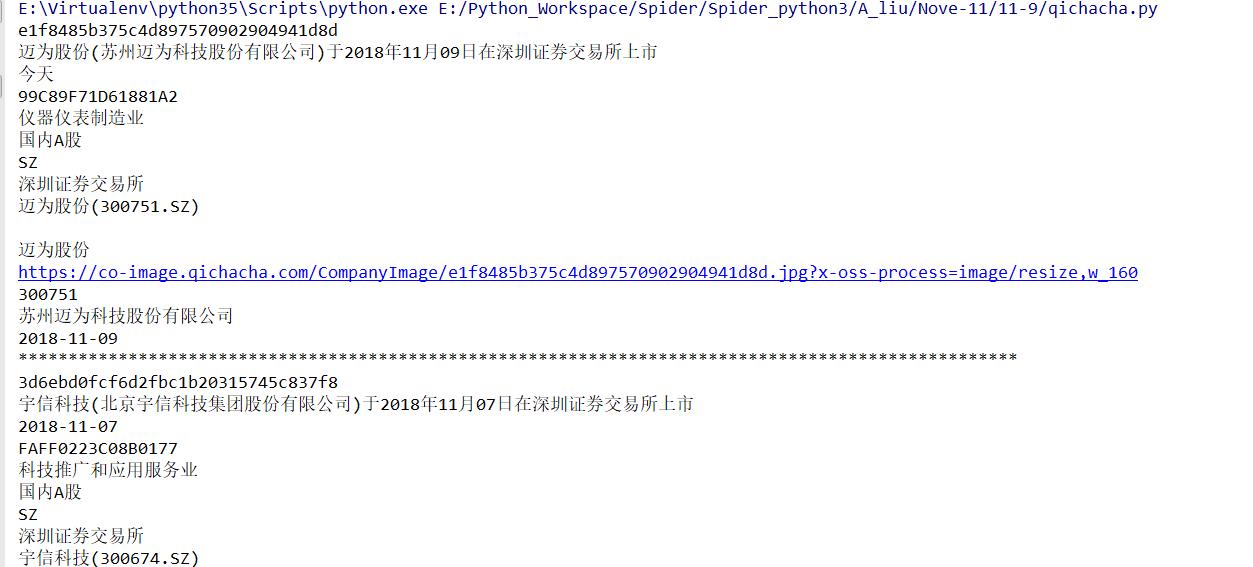
3.分析动态加载需要请求的参数及进一步深度url
https://appv3.qichacha.net/app/v1/other/IPOCompanySearch?searchKey=&sign=bbdb1ed793cb244e4bfb4b9b120984ce383940b0&sortField=date&isSortAsc=false&token=NmM2ZjA3M2Q5ZGU4NDAwM2JmNGQwYWFlMTM1YmVlYzg%3D×tamp=1541741269760&from=h5&pageIndex=1&platform=other
https://appv3.qichacha.net/app/v1/other/IPOCompanySearch?searchKey=&sign=bbdb1ed793cb244e4bfb4b9b120984ce383940b0&sortField=date&isSortAsc=false&token=NmM2ZjA3M2Q5ZGU4NDAwM2JmNGQwYWFlMTM1YmVlYzg%3D×tamp=1541741269760&from=h5&pageIndex=2&platform=other
https://appv3.qichacha.net/app/v1/other/IPOCompanySearch?searchKey=&sign=bbdb1ed793cb244e4bfb4b9b120984ce383940b0&sortField=date&isSortAsc=false&token=NmM2ZjA3M2Q5ZGU4NDAwM2JmNGQwYWFlMTM1YmVlYzg%3D×tamp=1541741269760&from=h5&pageIndex=3&platform=other
https://appv3.qichacha.net/app/v1/other/IPOCompanySearch?searchKey=&sign=bbdb1ed793cb244e4bfb4b9b120984ce383940b0&sortField=date&isSortAsc=false&token=NmM2ZjA3M2Q5ZGU4NDAwM2JmNGQwYWFlMTM1YmVlYzg%3D×tamp=1541741269760&from=h5&pageIndex=4&platform=other
https://appv3.qichacha.net/app/v1/other/IPOCompanySearch?searchKey=&sign=bbdb1ed793cb244e4bfb4b9b120984ce383940b0&sortField=date&isSortAsc=false&token=NmM2ZjA3M2Q5ZGU4NDAwM2JmNGQwYWFlMTM1YmVlYzg%3D×tamp=1541741269760&from=h5&pageIndex=5&platform=other
可以明显看出滑动加载数据url是有规律的变化的:
pageIndex=1,2,3,4,5
手机端滑动加载,每次加载20条,pageIndex+1,其他参数保持不变。
但是这里只给访问了3572条数据就不再给数据返回了,而且不设置休眠还会被检测到异常请求。
import requests import time,random def main(): headers = { # 将Fiddler右上方的内容填在headers中 "Host": "appv3.qichacha.net", "Connection": "keep-alive", "Pragma": "no-cache", "Cache-Control": "no-cache", "Accept": "application/json,text/javascript,*/*;q=0.01", "Origin": "https://share.qichacha.com", "User-Agent":"Mozilla/5.0 (Linux; android 7.1.2; MI 5X Build/N2G47H; wv) AppleWebKit/537.36 (Khtml, like Gecko) Version/4.0 Chrome/64.0.3282.137 Mobile Safari/537.36", "Referer": "https://share.qichacha.com/pro/app_11.6.0/enterprise-library/search-ipo/index.html", "Accept-Encoding": "gzip, deflate", "Accept-Language": "zh-CN,en-US;q=0.9", "X-Requested-With": "com.android.icredit", } for i in range(1,251): url = "http://appv3.qichacha.net/app/v1/other/IPOCompanySearch?searchKey=&sign=c1db45756855fb049b8b8f43b699db2148f9c048&sortField=date&isSortAsc=false&token=NmM2ZjA3M2Q5ZGU4NDAwM2JmNGQwYWFlMTM1YmVlYzg%3D×tamp=1541739365501&from=h5&pageIndex={}&platform=other".format(i) # 表显示在json格式下 time.sleep(random.randint(1,2)) res = requests.get(url=url, headers=headers).json() Results = (res[\'result\'])[\'Result\'] # print(Results #获取当前页面20条数据 for result in Results: KeyNo = result[\'KeyNo\'] print(KeyNo) Desc = result[\'Desc\'] print(Desc) ShowDate =result[\'ShowDate\'] print(ShowDate) ID = result[\'ID\'] print(ID) CategoryName = result[\'CategoryName\'] print(CategoryName) StockType = result[\'StockType\'] print(StockType) StockMarket = result[\'StockMarket\'] print(StockMarket) ListingMarket = result[\'ListingMarket\'] print(ListingMarket) Title = result[\'Title\'] print(Title) Status =result[\'Status\'] print(Status) StockName = result[\'StockName\'] print(StockName) ImageUrl = result[\'ImageUrl\'] print(ImageUrl) StockNumber = result[\'StockNumber\'] print(StockNumber) CompanyName = result[\'CompanyName\'] print(CompanyName) ListingDate = result[\'ListingDate\'] print(ListingDate) print(\'*\'*100) # 以追加的方式及打开一个文件,文件指针放在文件结尾,追加读写! with open(\'text\', \'a\', encoding=\'utf-8\')as f: f.write(\'\\n\'.join([KeyNo, Desc, ShowDate, CategoryName, StockType,StockMarket,ListingMarket,Title,Status,StockName,ImageUrl,StockNumber,CompanyName,ListingDate])) f.write(\'\\n\' + \'=\' * 50 + \'\\n\') if __name__ == "__main__": main()
采集情况:
采集 53580/15=3572条数据,能拿到的数据只有这些。
上市公司数据 3572条,而且进入详情url,app是不给返回接口的,fiddler抓不到包,所以数据就没办法拿到,这个数据就抓取不到。
其他的数据就没有给返回结果的,只能放弃了采集另寻其他方法。
以上是关于11.采集手机端app企查查上司公司数据的主要内容,如果未能解决你的问题,请参考以下文章