网络层-第七节:IPv4数据报首部格式
Posted 快乐江湖
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了网络层-第七节:IPv4数据报首部格式相关的知识,希望对你有一定的参考价值。
文章目录
本节对应视频如下
一:IP数据报首部格式概述
IP数据报首部格式:一个IP分组由首部和数据载荷两部分组成。IP数据报首部由固定部分(20B)和可变部分(最大40B)
- 固定部分:每个IP数据报首部所必须包含的部分
- 可变部分:用于增加IP数据报的功能
IP数据报常以32个比特为单位(4B)进行描述,也即下图中的每一行,其中每个小格子称之为字段(或域),每个字段或某些字段的组合用来表达IP协议的相关功能
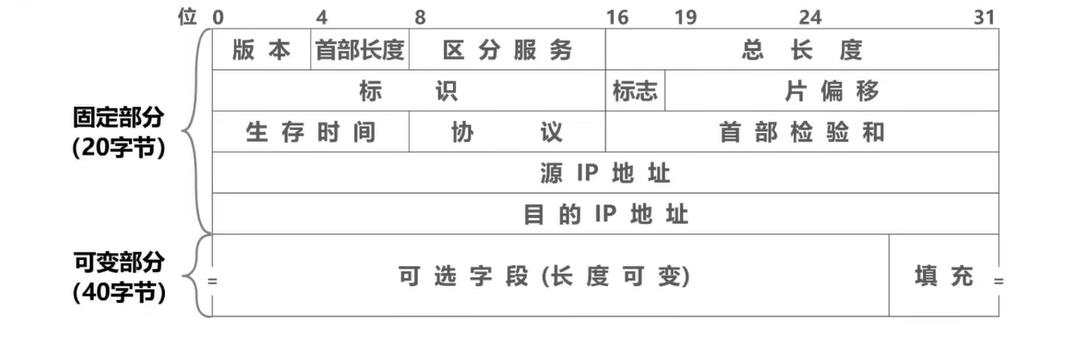
二:各字段作用概述
(1)版本
版本:占4个比特,表示IP协议的版本,通信双方使用的IP协议版本必须一致。目前广泛使用的IP协议版本号为4,也即IPv4
(2)首部长度和可选字段
首部长度:占4个比特,表示IP数据报首部的长度,该字段取值以4B为单位
- 最小十进制取值为5,表示IP数据报首部只有20B的固定部分
- 最大十进制取值为15,表示IP数据报首部包含20B的固定部分和最大40B的可变部分
可选字段: 占1B到40B不等,用来支持排错、测量及安全等措施。可选字段增加了IP数据报的功能,但这同时也使得IP数据报的首部长度成为可变的。这就增加了每一个路由器处理IP数据报的开销。实际上可选字段很少被使用
(3)填充
填充: 用来确保首部长度应该是4B的整数倍,使用全0进行填充
(4)区分服务
区分服务: 占8个比特,用来获得更好的服务。该字段在旧标准中叫作服务类型,但实际上一直没有被使用过。1998年,因特网工程任务组IETF把这个字段改名为区分服务。利用该字段的不同数值可提供不同等级的服务质量。只有在使用区分服务时,该字段才起作用。一般情况下都不使用该字段
(5)总长度
A:概述
总长度: 占16个比特,用来表示IP数据报的总长度(首部+数据载荷)
- 最大取值为十进制的65535,以字节为单位。在实际应用中,很少会传输这么长的IP数据报文
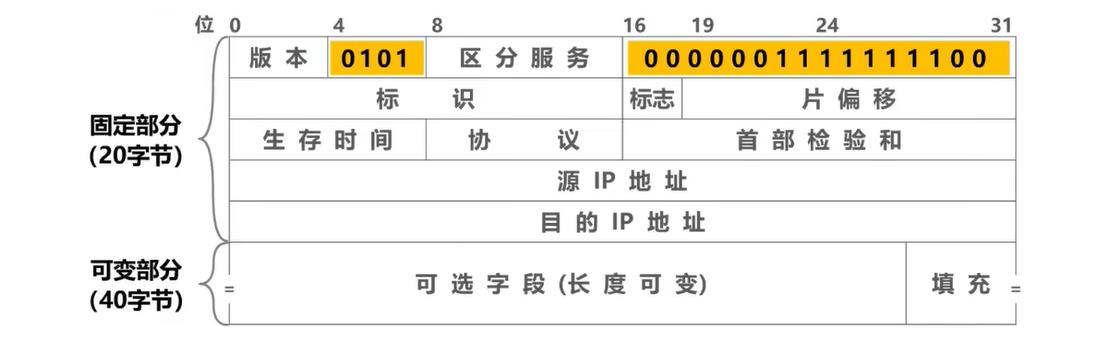
B:首部长度和总长度字段区别
下图可说明首部长度字段和总长度字段的区别
- 首部长度: ( 0101 ) 2 × 4 = 5 × 4 = 20 B (0101)_2×4=5×4=20B (0101)2×4=5×4=20B
- 总长度: ( 0000001111111100 ) 2 = 1020 B (0000001111111100)_2=1020B (0000001111111100)2=1020B
- 数据载荷长度: 1020 − 20 = 1000 B 1020-20=1000B 1020−20=1000B

(6)标识、标志和片偏移(用于IP数据报分片)
A:IP数据报分片
IP数据报分片:如下图,网际层封装出的IP数据报将会在数据链路层封装成帧。每一种数据链路层协议都规定了帧的数据载荷的最大长度,称之为最大传输单元MTU(例如以太网数据链路层规定MTU值为1500B)。如果某个IP数据报总长度超过MTU时,将无法封装成帧,需要将原IP数据报分片为很小的IP数据报,再将各分片IP数据报封装成帧。而这里的标识、标志和片偏移三个字段共同用于IP数据报分片

B:标识、标志和片偏移
标识: 占16个比特,属于同一个数据报的各分片数据报应具有相同的标识。IP软件维持一个计数器,每产生一个数据报,计数器值+1,并将此值赋给标识字段
标志: 占3个比特,各比特含义如下
- DF位:
1:不允许分片0:允许分片
- MF位:
1:后面还有分片0:这是最后一个分片
- 保留位:必须设置为0
片偏移: 占13个比特,用于指出分片数据报的数据载荷部分偏移其在原数据报的位置有多少个单位,片偏移以8个字节为单位
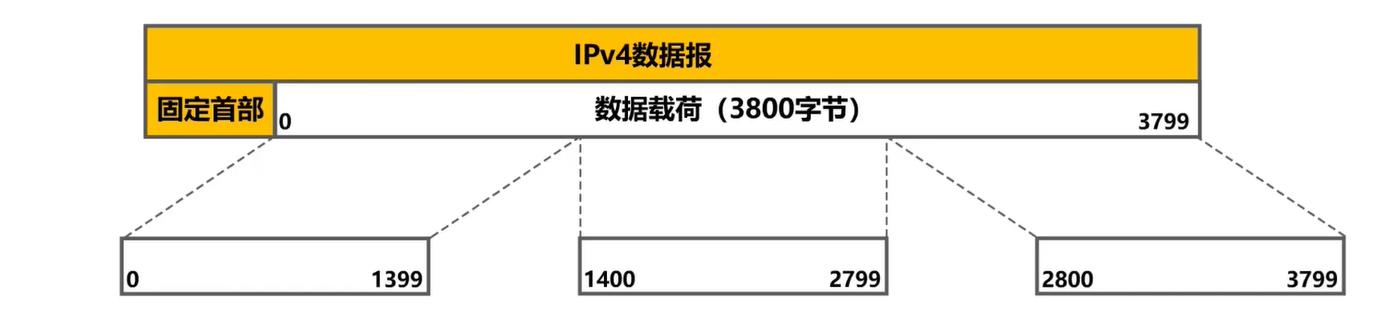
C:IP数据报分片例子
如下图有一IP数据报,其首部为20B,数据载荷部分3800B,所以总长度为3820B。假设使用以太网传送该IP数据报,其MTU为1500B,显然无法封装3820B长的IP数据报,因此需要把该IP数据报分片为几个更小的IP数据报,每个长度不能大于1500B,然后再将每个分片IP数据报封装成一个以太网帧进行传输。为了更好地描述后续分片工作,这里我们将原IP数据报数据载荷部分的每一个字节都编上号,范围为0-3799

我们可将原IP数据报的数据载荷部分分为3个更小的分片
- 第一个分片:共1400字节,范围0-1399
- 第二个分片:共1400字节,范围1400-2799
- 第一个分片:共1000字节,范围2800-3799
分片结束后,给每个分片重新添加一个首部使之成为IP数据报,每个分片添加的首部自然不能完全相同,根据上面对标识、标志和片偏移字段的理解,可以填写下表
| 总长度 | 标识 | MF | DF | 片偏移 | |
|---|---|---|---|---|---|
| 原始数据报 | 3800+20 | 12345 | 0 | 0 | 0 |
| 分片1的数据报 | 1400+20 | 12345 | 1 | 0 | 0/8 |
| 分片2的数据报 | 1400+20 | 12345 | 1 | 0 | 1400/8 |
| 分片3的数据报 | 1000+20 | 12345 | 0 | 0 | 2800/00 |

假设分片2的IP数据报经过某个网络时还需要再进行分片,其中一个分片长度为800B,另一个分片长度为600B,分片结束后给每个分片添加一个首部使之称为IP数据报,填写下表如下
| 总长度 | 标识 | MF | DF | 片偏移 |
|---|---|---|---|---|
| 原始数据报 | 3800+20 | 12345 | 0 | 0 |
| 分片2的分片1数据报 | 800+20 | 12345 | 1 | 0 |
| 分片2的分片2数据报 | 600+20 | 12345 | 1 | 0 |
(7)生存时间
A:概述
生存时间:
- 占8比特,最初以秒为单位,最大生存周期为255秒;路由器转发IP数据报时,将IP数据报首部中的该字段的值减去IP数据报在本路由器上所耗费的时间,若不为0就转发,否则就丢弃
- 现在以“跳数”为单位,路由器转发IP数据报时,将IP数据报首部中的该字段的值减1,若不为0就转发,否则就丢弃
B:作用
生存时间字段的最大作用就是防止IP数据报在网络中永久兜圈
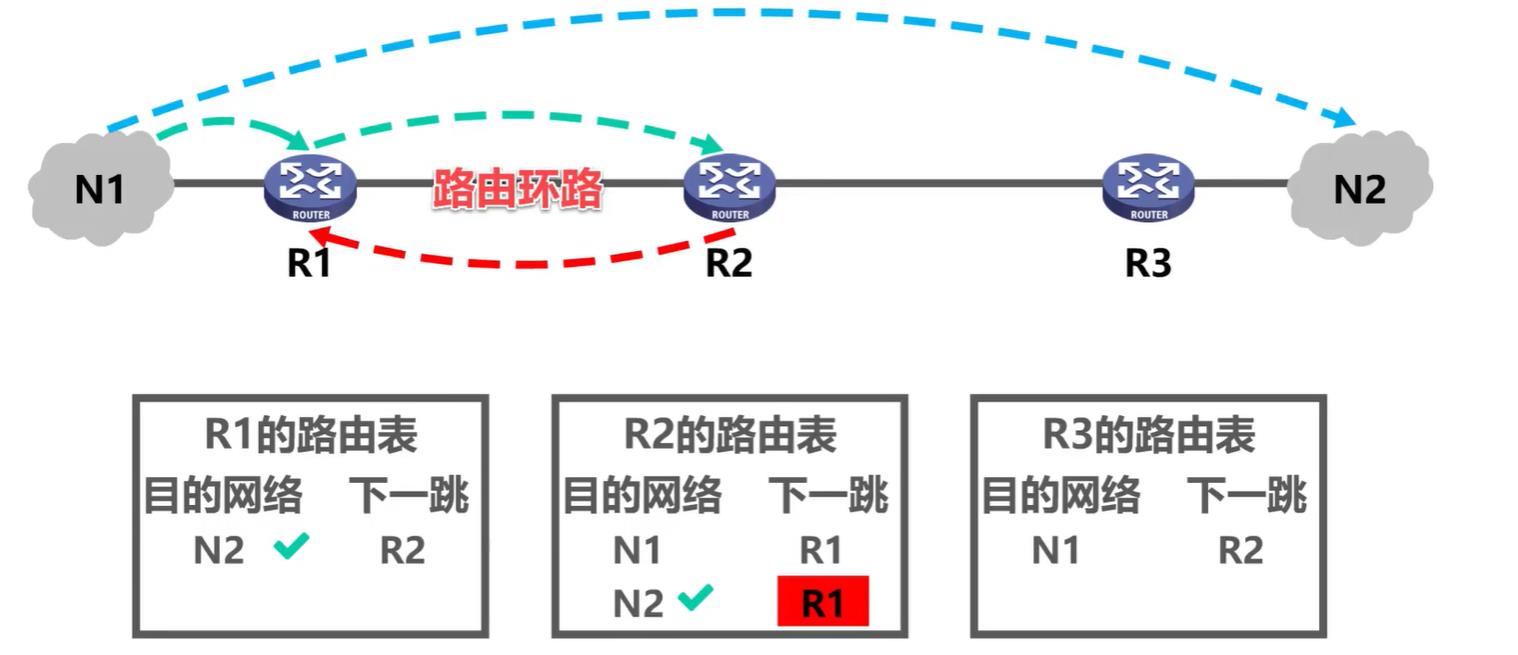
如下图,假设路由器R2路由表目的网络为N2的条目其下一跳被错误的配置成了R1(本来是R3),这会导致去往网络N2的IP数据报错误地转发给路由器R1
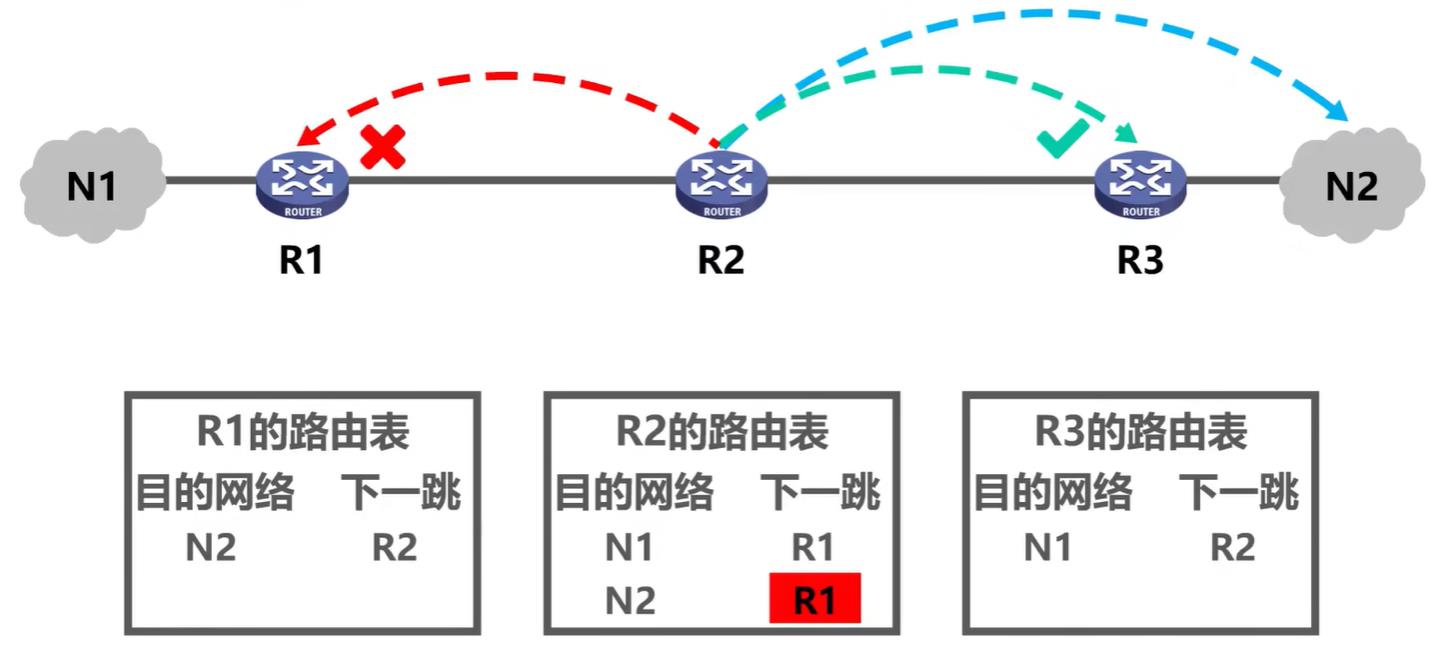
假设某个IP数据报从网络N1发往N2,该IP数据报达到R1后,R1进行查表转发,发现了匹配的路由条目,其下一条指示转发给R2,于是R1将该IP数据报转发给了R2。R2收到该IP数据报后,进行查表转发,发现了匹配的路由条目,其下一条指示转发给R1,于是R2将该IP数据报又转发回了R1。很显然,这形成了路由环路,如果没有生存时间字段,IP数据报将在此路由环路中永久兜圈
(8)协议
协议: 占8比特,指明IPv4数据报的数据部分是何种协议数据单元,常用的一些协议和相应协议字段的值如下表
| 协议名称 | ICMP | IGMP | TCP | UDP | IPv6 | OSPF |
|---|---|---|---|---|---|---|
| 协议字段值 | 1 | 2 | 6 | 17 | 41 | 89 |
(9)首部校验和
首部校验和: 占16个比特,用来检测首部在传输过程中是否出现差错。IP数据报每经过一个路由器,路由器都要重新计算首部检验和,因为某些字段(生存时间、标志、片偏移等)的取值可能发生变化。由于IP层本身并不提供可靠传输的服务,并且计算首部校验和是一项耗时的操作,因此在IPv6中,路由器不再计算首部校验和,从而更快转发IP数据报
(10)源IP地址和目的IP地址
源IP地址和目的IP地址: 各占32比特,用来填写发送该IP数据报的源主机的IP地址和接收该IP数据报的目的主机的IP地址
三:总结
| 字段名 | 长度 | 作用 |
|---|---|---|
| 版本 | 4个比特 | IP协议版本 |
| 首部长度 | 4个比特 | IP数据报首部长度 |
| 总长度 | 16个比特 | IP数据报总长度 |
| 标识 | 16个比特 | 同一个数据报各分片相同 |
| 标志 | 3个比特 | DF;MF;保留位 |
| 生存时间 | 8个比特 | 防止永久兜圈 |
| 协议 | 8个比特 | 何种协议数据单元 |
| 首部校验和 | 16个比特 | 检测差错 |
| 源IP地址 | 32个比特 | 源主机IP地址 |
| 目的IP地址 | 32个比特 | 目的主机IP地址 |
| 可选字段 | 0-40字节 | 支持排错、测量及安全等措施 |
以上是关于网络层-第七节:IPv4数据报首部格式的主要内容,如果未能解决你的问题,请参考以下文章