2.kafka入门
Posted do__something
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2.kafka入门相关的知识,希望对你有一定的参考价值。
文章目录
2.kafka入门
2.1 基本概念
kafka是一个多分区、多副本且基于ZooKeeper协调的分布式消息系统。目前已经定位为一个分布式流式处理平台,具有高吞吐、可持久化、可水平扩展、支持流数据处理等多种特性。基本架构图如下:
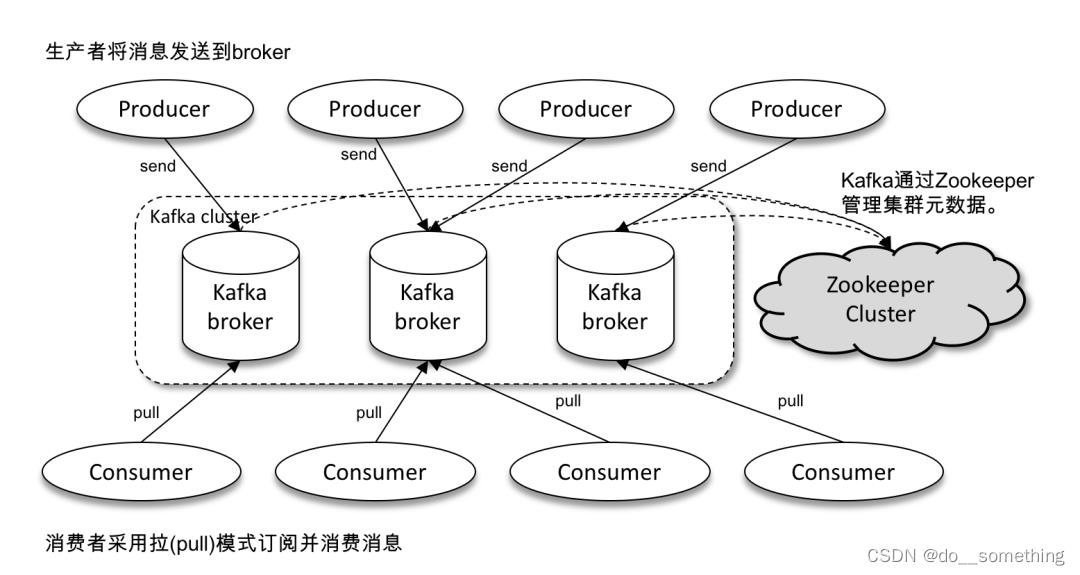
基本概念如下:
-
Producer:生产者,消息发送方
-
Consumer:消费者,消息接收方
-
broker:服务代理节点,可以看作是一台部署了kafka实例的服务器
-
Topic:主题,是一个逻辑上的概念。kafka中的消息以主题进行归类,生产者将消息发送到特定的主题,消费者负责订阅主题并进行消费
-
Partition:分区,在存储层面可以看作一个可追加的日志文件。一个主题可以包含一个或者多个分区,每个分区可以分在不同的broker节点中以提高kakfa的性能。
-
Replica:副本,每个分区可以包含一个或者多个副本,副本之间是一主多从的关系,通过副本机制可以提升kafka的容灾能力。
-
AR(Assigned Replicas):所有的副本。AR=ISR + OSR
-
ISR(In-Sync Replicas):所有与leader副本保持一定程度同步的副本(包括leader副本在内),当leader副本发生故障时,只有在ISR集合中的副本才有资格被选举为新的leader
-
OSR(Out-of-Sync Replicas):与leader副本同步滞后过多的副本。
-
HW(High Watermark):高水位,用来标识一个特定的消息偏移量(offset),消费者只能拉取到这个offset之前的消息
-
LEO(Log End Offset):标识当前日志文件中下一条待写入消息的offset。
▲分区ISR集合中的每个副本都会维护自身的LEO,而ISR集合中最小的LEO即为分区的HW

(12)consumer group:消费者组,其内部有可以有多个消费者,这些消费者共用一个Group ID。一个主题的一个分区只能由该消费者组中的一个消费者消费。消费者组之间互不影响。
2.2 生产者入门
一个生产者生产消息需要以下几个步骤:
①配置生产者客户端参数及创建相应的生产者实例。
②构建待发送的消息。
③发送消息。
④关闭生产者实例
public class KafkaProducerTest
//kafka broker的ip和端口
public static final String brokerList = "hadoop101:9092";
//发送消息的主题
public static final String topic = "topic-demo";
public static Properties initConfig()
Properties props = new Properties();
props.put("bootstrap.servers", brokerList);
//设置序列化器
props.put("key.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
props.put("client.id", "producer.client.id.demo");
return props;
public static void main(String[] args) throws InterruptedException
//1.配置生产者客户端参数
Properties props = initConfig();
//创建生产者实例
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
//2.构建待发送的消息ProducerRecord
ProducerRecord<String, String> record = new ProducerRecord<>(topic, "hello, Kafka!");
try
//3.发送消息
producer.send(record);
catch (Exception e)
e.printStackTrace();
finally
//4.关闭生产者实例
producer.close();
(1)消息类ProducerRecord
ProducerRecord用来存储发送消息相关信息,其数据结构如下:
public class ProducerRecord<K, V>
private final String topic; //消息主题
private final Integer partition; //分区
private final Headers headers; //消息头
private final K key; //消息的键
private final V value; //消息值
private final Long timestamp; //消息的时间戳
(2)发生消息的三种模式
发送消息主要有三种模式:发后即忘(fire-and-forget)、同步(sync)及异步(async)
①发后就忘
只管往Kafka中发送消息而并不关心消息是否正确到达,性能最高,可靠性也最差。
producer.send(record);
②同步发送
可以利用返回的Future对象实现,调用其get()方法来阻塞等待Kafka的响应,直到消息发送成功,或者发生异常。同步发送可靠性高,消息要么发送成功,要么发生失败。如果发生异常,则可以捕获并进行相应的处理
producer.send(record).get()
③异步发送
通过指定send方法中一个回调函Callback实现,其回调参数互斥,消息发送成功时,metadata 不为 null 而exception为null;消息发送异常时,metadata为null而exception不为null。
producer.send(record, new Callback()
@Override
public void onCompletion(RecordMetadata metadata, Exception exception)
if (exception == null)
System.out.println(metadata.partition() + ":" + metadata.offset());
);
2.3 消费者入门
(1)消费者组的理解
每个消费者都有一个对应的消费组。当消息发布到主题后,只会被投递给订阅它的每个消费组中的一个消费者。也即每个分区只能被一个消费组中的一个消费者所消费。

消费者与消费组这种模型可以让整体的消费能力具备横向伸缩性,我们可以增加(或减少)消费者的个数来提高(或降低)整体的消费能力。
(2)消费消息代码
一个正常的消费逻辑需要具备以下几个步骤:
①配置消费者客户端参数及创建相应的消费者实例。
②订阅主题。
③拉取消息并消费。
④提交消费位移。
⑤关闭消费者实例
public class KafkaConsumerTest
public static final String brokerList = "hadoop101:9092";
public static final String topic = "topic-demo";
public static final String groupId = "group.demo";
public static final AtomicBoolean isRunning = new AtomicBoolean(true);
public static Properties initConfig()
Properties props = new Properties();
//消息key的反序列化其
props.put("key.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
//消费者value的反序列化器
props.put("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
//kafka broker的ip和端口
props.put("bootstrap.servers", brokerList);
//订阅的主题
props.put("group.id", groupId);
//消费者组的名字
props.put("client.id", "consumer.client.id.demo");
return props;
public static void main(String[] args)
//1.配置消费者客户端参数
Properties props = initConfig();
//创建消费者实例
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
//2.订阅主题
consumer.subscribe(Arrays.asList(topic));
try
while (isRunning.get())
//3.拉取消息消费 提交消费位移
ConsumerRecords<String, String> records =
consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records)
System.out.println("topic = " + record.topic()
+ ", partition = " + record.partition()
+ ", offset = " + record.offset());
System.out.println("key = " + record.key()
+ ", value = " + record.value());
//do something to process record.
catch (Exception e)
log.error("occur exception ", e);
finally
//4.关闭消费者实例
consumer.close();
(3)订阅主题的三种方式
①subscribe(Collection)
集合订阅的方式。该方式可以根据分区分配策略自动分配各个消费者与分区的关系。当消费组内的消费者增加或减少时,分区分配关系会自动调整,以实现消费负载均衡及故障自动转移
②subscribe(Pattern)
正则表达式的订阅方式。在订阅之后,如果又创建了与该表达式匹配的主题,那么该消费者可以自动消费新主题的消息。
③assign(TopicPartition):分区订阅的方式。通过TopicPartition来指定订阅的主题和分区
(4)消费位移的提交
消费者使用offset来表示消费到分区中某个消息所在的位置,在每次调用poll()方法时,返回的还没有被消费过的消息集,要做到这一点,就需要记录上一次消费时的消费位移。并且这个消费位移必须做持久化保存。

默认的位移提交是自动提交,由参数enable.auto.commit和(是否开启自动提交)参数auto.commit.interval.ms(自动提交的时间间隔)控制,默认5s
提交时机:
①拉取到消息就进行位移提交,如果在消费的过程中出现故障,则发生消息丢失
②消费完消息再进行提交:如果在消费的过程中出现故障,则发生消息重复消费
由于kafka默认是定时自动提交,因此消息丢失和重复均可能发生
我们可以选择关闭kafka位移自动提交(设置enable.auto.commit=false),然后可以使用同步提交和异步提交的方式:
//无参数同步提交
commitSync();
//带参数同步提交,可以每消费一条消息就提交一次消费位移,但是性能较差(生产中应用较少)
commitSync(Map<TopicPartition, OffsetAndMetadata> offsets)
//异步提交
commitAsync();
commitAsync(OffsetCommitCallback callback); //指定回调函数
commitAsync(Map<TopicPartition, OffsetAndMetadata> offsets, OffsetCommitCallback callback); //指定按分区提交的位移和回调函数
当一个新的消费组建立的时候,该消费者组查找不到记录的消费位移,便会根据消费者客户端参数auto.offset.reset来决定从何处开始进行消费。
指定位移消费:
auto.offset.reset默认值为lastes,表示从分区末尾开始消费消息。
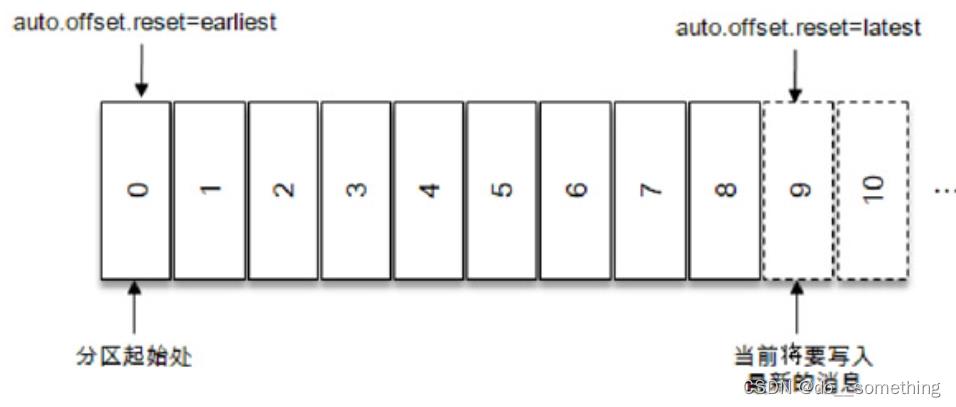
如果需要更细粒度的掌控,可以通过seek()方法实现:
//重置消费者在分区中的消费位置 partition指定分区,offset指定从分区哪个位置进行消费
seek(TopicPartition partition, long offset)
seek()方法为我们提供了从特定位置读取消息的能力,可以通过这个方法来向前跳过若干消息,也可以通过这个方法来向后回溯若干消息,这样为消息的消费提供了很大的灵活性。
主要参考:
朱忠华:深入理解kafka:核心设计与实现原理
博主微信,欢迎交流:jhy2496085873
以上是关于2.kafka入门的主要内容,如果未能解决你的问题,请参考以下文章