免app下载笔趣阁小说
Posted yuantup
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了免app下载笔趣阁小说相关的知识,希望对你有一定的参考价值。
第一次更新:发现一个问题,就是有时候网页排版有问题的话容易下载到多余章节,如下图所示:
网站抽风多了一个正文一栏,这样的话就会重复下载1603--1703章节。

解决办法:
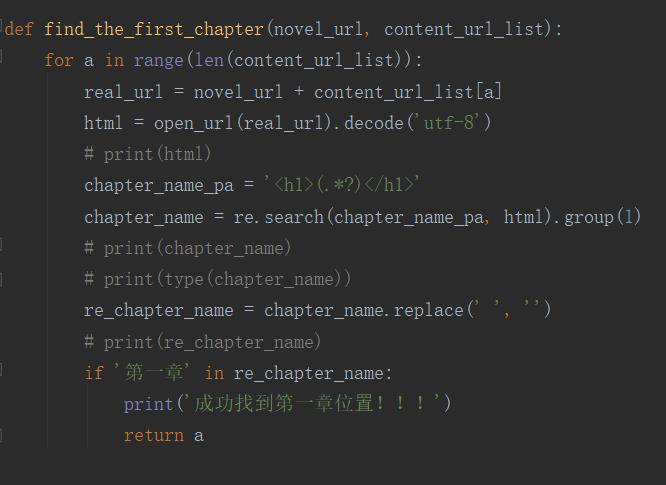
于是在写入内容前加了一个章节判断,让内容获取从第一章开始,这样就能避免此类问题。如下图:
这个是对最近学习的一次总结吧。前两天写的,今天才有时间写博客。
偶然点开笔趣阁的网址(https://www.biquge.cc/),突然觉得我应该可以用爬虫实现小说下载。有这个想法我就开始尝试了。
爬虫呀,说白了就是程序自动模拟浏览器操作来获取网页的内容。
先用F12查看元素,查看章节网址链接,和章节正文内容。
结构很简单。
想法很快就有了,通过网站的搜索打开小说详情页,然后获取每一章的网址url,依次访问每一章网址,再通过正则表达式匹配章节内容,
最后将匹配的内容保存到本地。
中间忘了一个小的知识点,就是我使用re.findall()来匹配的,它最后返回的时一个列表!!!
运行结果如下图:

代码如下:
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2018/10/20 15:46 # @Author : yuantup # @Site : # @File : biquge.py # @Software: PyCharm import urllib.request import re import time import os def open_url(url): # 打开网址专用 # 以字典的形式设置headers head = {\'Accept\': \'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8\', # \'Accept-Encoding\': \'gzip\', # 接受编码如果是gzip,deflate之类的,可能会报错 \'Accept-Language\': \'zh-CN,zh;q=0.9\', \'Connection\': \'keep-alive\', \'Host\': \'sou.xanbhx.com\', \'Referer\': \'https://www.biquge.cc/\', \'Upgrade-Insecure-Requests\': \'1\', \'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) \' \'Chrome/63.0.3239.132 Safari/537.36\', } # 设置cookies # proxy = urllib.request.ProxyHandler({\'http\': \'127.0.0.1:8888\'}) opener = urllib.request.build_opener() # 遍历字典,将其转换为指定格式(外层列表,里层元组) headers = [] for key, value in head.items(): item = (key, value) headers.append(item) opener.addheaders = headers urllib.request.install_opener(opener) response = urllib.request.urlopen(url) html = response.read() time.sleep(1) return html def novel_detail(book_name): # 根据传入的小说名字获取到小说的详情页,并提取出小说内容(详情,每个章节的网址) # 小说存在重名情况!!!待解决 zh_book_name = urllib.request.quote(book_name) url = \'https://sou.xanbhx.com/search?siteid=biqugecc&q=\' + zh_book_name html = open_url(url).decode(\'utf-8\') # print(html) name_pa = \'<span class="s2">.*?<a href="(.*?)" target="_blank">.*?(\\S*?)</a>\' name_list = re.findall(name_pa, html, re.S) # print(name_list[1]) if name_list[0][1] == book_name: book_url = name_list[0][0] print(book_url) elif not name_list: print(\'\') print(\'对不起,该网址没有找到你需要的书。\') return book_url def content(url): # 获取小说正文 html = open_url(url).decode(\'utf-8\') # print(html) main_body_pa = r\'最新章节(提示:已启用缓存技术,最新章节可能会延时显示,登录书架即可实时查看。).*?<dt>(.*?)</div>\' chapter_url_pa = r\'<a style="" href="(.*?)">\' main_body = re.findall(main_body_pa, html, re.S) # print(main_body, \' 1\') # 记住re.findall()方法返回的时一个列表!!! chapter_url = re.findall(chapter_url_pa, main_body[0]) # print(chapter_url, \' 2\') time.sleep(2) return chapter_url def save_novel(novel_url, content_url_list, book_name): # 保存小说内容 for i in range(len(content_url_list)): real_url = novel_url + content_url_list[i] html = open_url(real_url).decode(\'utf-8\') # print(html) chapter_name_pa = \'<h1>(.*?)</h1>\' chapter_name = re.search(chapter_name_pa, html).group(1) # print(chapter_name) # print(type(chapter_name)) content_pa = r\'<div id="content">(.*?)<script>\' content1 = re.findall(content_pa, html, re.S) content2 = content1[0].replace(\' \', \' \') content3 = content2.replace(\'<br/>\', \'\\n\') content4 = content3.replace(\'</br>\', \'\') re_chapter_name = chapter_name.replace(\' \', \'\') content5 = content4.replace(re_chapter_name, \'\') # 有些章节内容包括章节名,这里替换掉它们。 whole_content = \' \' + chapter_name + \'\\n\' + content5 # print(whole_content) # print(chapter_name) with open(book_name + \'.txt\', \'a\', encoding=\'utf-8\') as f: f.write(whole_content) print(\'成功下载 {}\'.format(chapter_name)) time.sleep(1) def main(): path = r\'E:\\spiser_sons\\books\' a = os.getcwd() print(a) if os.path.exists(path): os.chdir(path) print(os.getcwd()) else: os.mkdir(path) os.chdir(path) book_name = input(\'请输入想下载小说的名字:\') novel_url = novel_detail(book_name) content_url_list = content(novel_url) save_novel(novel_url, content_url_list, book_name) if __name__ == \'__main__\': main()
还有几个问题有待解决:
1.下载速度过慢,基本上一章2秒钟,几百万字的网文(1500+章)基本就要快一个小时了,亲测。。。。
2.小说有重名的话就很麻烦,只会下载排第一的。不过这个再添加一个作者判断应该可以解决。
以上是关于免app下载笔趣阁小说的主要内容,如果未能解决你的问题,请参考以下文章