unordered_mapunordered_set模拟实现
Posted 可乐不解渴
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了unordered_mapunordered_set模拟实现相关的知识,希望对你有一定的参考价值。
unordered_map、unordered_set模拟实现
不要沉沦,在任何环境中你都可以选择奋起。
开散列哈希表源代码
我们针对上期博客中讲述开散列哈希,来对这个K-V模型的哈希表来进行封装出unordered_map、unordered_set这两个在STL库当中容器,其中所用到开散列哈希代码如下:
template<class k>
struct hash
size_t operator()(const k& key)
return key;
;
template<class k, class v>
struct hashnode
hashnode<k, v>* _next;
pair<k, v> _kv;
hashnode(const pair<k, v>& kv)
:_next(nullptr)
, _kv(kv)
;
template<class k, class v, class hashfunc = hash>
class hashtable
typedef hashnode<k, v> node;
public:
size_t getnextprime(size_t prime)
const int primecount = 28;
static const size_t primelist[primecount] =
53ul, 97ul, 193ul, 389ul, 769ul,
1543ul, 3079ul, 6151ul, 12289ul, 24593ul,
49157ul, 98317ul, 196613ul, 393241ul, 786433ul,
1572869ul, 3145739ul, 6291469ul, 12582917ul, 25165843ul,
50331653ul, 100663319ul, 201326611ul, 402653189ul, 805306457ul,
1610612741ul, 3221225473ul, 4294967291ul
;
size_t i = 0;
for (; i < primecount; ++i)
if (primelist[i] > prime)
return primelist[i];
return primelist[i];
bool insert(const pair<k, v>& kv)
if (find(kv.first))
return false;
hashfunc hf;
// 负载因子到1时,进行增容
if (_n == _table.size())
vector<node*> newtable;
//size_t newsize = _table.size() == 0 ? 8 : _table.size() * 2;
//newtable.resize(newsize, nullptr);
newtable.resize(getnextprime(_table.size()));
// 遍历取旧表中节点,重新算映射到新表中的位置,挂到新表中
for (size_t i = 0; i < _table.size(); ++i)
if (_table[i])
node* cur = _table[i];
while (cur)
node* next = cur->_next;
size_t index = hf(cur->_kv.first) % newtable.size();
// 头插
cur->_next = newtable[index];
newtable[index] = cur;
cur = next;
_table[i] = nullptr;
_table.swap(newtable);
size_t index = hf(kv.first) % _table.size();
node* newnode = new node(kv);
// 头插
newnode->_next = _table[index];
_table[index] = newnode;
++_n;
return true;
node* find(const k& key)
if (_table.size() == 0)
return false;
hashfunc hf;
size_t index = hf(key) % _table.size();
node* cur = _table[index];
while (cur)
if (cur->_kv.first == key)
return cur;
else
cur = cur->_next;
return nullptr;
bool erase(const k& key)
hashfunc hf;
size_t index = hf(key) % _table.size();
node* prev = nullptr;
node* cur = _table[index];
while (cur)
if (cur->_kv.first == key)
if (_table[index] == cur)
_table[index] = cur->_next;
else
prev->_next = cur->_next;
--_n;
delete cur;
return true;
prev = cur;
cur = cur->_next;
return false;
private:
vector<node*> _table;
size_t _n; // 有效数据的个数
;
字符串类型无法取模问题
针对我们上面的代码,如果碰到的是内置的int、long、short等等类型,都是可以进行利用仿函数对象,去取得key值来给哈希函数去取模计算该元素所对应的哈希映射地址的。
但是字符串并不是整型,也就意味着字符串类型不能直接用于取模计算哈希地址,我们需要通过某种方法将字符串转换成整型后,才能代入哈希函数计算哈希地址。
注意:这里不要想当然的就将字符串类型强转为可以取模的类型,这样是不行的。
根据上面的分析,因此我们可以针对字符串类型写一个类模板特化版本,此时如果为string类型为key值时,该仿函数就会根据一定的算法来返回一个可以取模的整数。
而这里的针对string类型的算法,根据计算机的前辈们采取了大量的实验结果发现,BKDR哈希算法冲突率比其他算法较低,所以我们这里采用BDKR算法。
template<>
struct _hash<string>
size_t operator()(const string& key)
size_t size = key.size();
size_t ret = 0;
for (size_t i = 0; i < size; ++i)
ret *= 131;
ret += key[i];
return ret;
;
模板参数的控制
我们要想只用一份哈希表代码同时封装出K模型和KV模型的容器,我们必定要对哈希表的模板参数进行控制。这里就如同之前利用同一颗红黑树来实现map与set一样。
现在由于结点当中存储的是T类型,并且这个T类型可能是Key值,也可能是<Key, Value>键值对。
那么当我们需要利用T这个值进行结点的键值比较时,应该如何获取结点的键值呢?
答:我们可以再给红黑树中再增加一个模板参数,通过上层unordered_map与unordered_set传入仿函数给哈希表的
第三个仿函数类型,我就可以利用仿函数对象来调用重载的operator(),来获取到对应的Key值。
这里同样是将第二个模板参数类型名改为T类型,首先我们将哈希表第二个模板参数类型的名字改为T,这是为了与之前的K-V模型进行区分。并且这个T就不再是之前单单的表示Value了,这个T可能代表的是Key,也有可能是pair<Key,Value>共同构成的键值对。
并且就不再哈希表来给缺省哈希函数了,而是交给上层的unordered_map和unordered_set,并添加一个哈希函数的模板参数并给定缺省的哈希函数,并将该类型来传递给哈希表当中,由上层决定你的哈希函数。
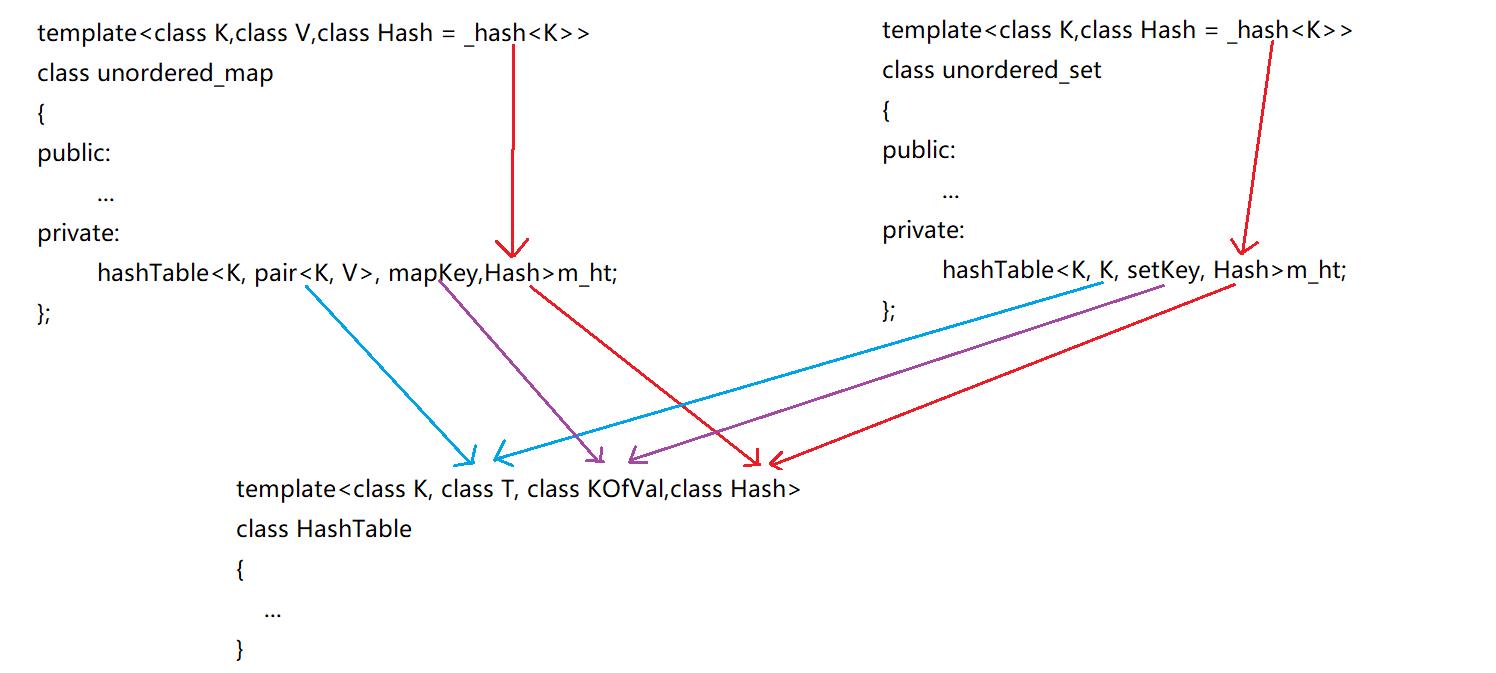
template<class K, class T, class KOfVal,class Hash>
class HashTable
其次是需要控制unordered_map和unordered_set传入底层哈希表的模板参数。
即unordered_map传给哈希表的T模板参数传入pair<K, V>类型。
template<class K,class V,class Hash = _hash<K>>
class unordered_map
public:
...
private:
hashTable<K, pair<K, V>, mapKey,Hash>m_ht;
;
而unordered_set传给哈希表的T模板参数传入K类型。
template<class K,class Hash = _hash<K>>
class unordered_set
public:
...
private:
hashTable<K, K, setKey, Hash>m_ht;
;
哈希表中的模板参数T的类型到底是什么,完全却决于上层所使用容器的种类。并且哈希函数完全也取决于上层容器传递下来的类型。
其中传递关系如下图所示:
上层更改模板参数后,那么底层的哈希结点也需要做一定的改变,定义如下:
template<class T>
struct hashNode //哈希节点
T m_data;
hashNode<T>* m_next;
hashNode(const T&data):m_data(data),m_next(nullptr)
;
哈希表默认成员函数
构造函数
在哈希表当中有4个成员变量,其中两个都是仿函数对象,一个用来获取到不同的两个容器的Key值,另外一个是哈希函数,用来获取到哈希映射地址。在构造函数中需要初始化的有两个成员。
- m_table是vector类型,它会自动调用vector的默认构造函数来进行初始化,并且我们在构造函数当中将其容量开辟到10个。
- m_size是一个无符号的整形,在构造函数当中我们将其值初始化为0。
hashTable():m_size(0)
m_table.resize(10, nullptr);
拷贝构造函数
由于我们在哈希表当中的每一个结点都是通过new出来的,最后都是要去通过析构函数来进行释放,所以我们在这里需要进行深拷贝,否则在最后析构函数当中崩溃。
其中实现逻辑如下:
- 将旧表的大小给新表利用resize函数来修改为旧表的大小;
- 将旧表当中的结点一个个的拷贝到新表当中;
- 更新新表的有效元素个数;
hashTable(const hashTable<K, T, KOfVal, Hash>& obj) //深拷贝
this->m_size = obj.m_size;
this->m_table.resize(obj.m_table.size());
for (size_t i = 0; i < obj.m_table.size(); ++i)
node* cur = obj.m_table[i];
while (cur != nullptr)
node* copy = new node(cur->m_data);
copy->m_next = m_table[i];
m_table[i] = copy;
cur = cur->m_next;
赋值运算符重载函数
与拷贝构造函数同理都是需要深拷贝,我们通过局部变量的声明周期来调用拷贝构造函数深拷贝。最后将拷贝构造出来的哈希表和当前哈希表的两个成员变量分别进行交换即可,当这个局部变量出了作用域会自动调用析构函数来进行释放内存。
hashTable& operator =(const hashTable<K, T, KOfVal, Hash>& obj) //深拷贝
if (this == &obj)
return *this;
else
hashTable<K, T, KOfVal, Hash> temp(obj);
this->m_table.swap(temp.m_table);
std::swap(this->m_size, temp.m_size);
析构函数
由于我们哈希表当中的结点都是通过new出来的,因此在释放时必须手动对结点进行释放。
思路:只需要依次取出非空的哈希桶的为止,遍历哈希桶当中的结点一个一个的进行释放即可。
void clear()
size_t length = static_cast<size_t>(m_table.size());
for (size_t i = 0; i < length; ++i)
node* cur = m_table[i];
while (cur != nullptr)
node* next = cur->m_next;
delete cur;
cur = next;
m_table[i] = nullptr;
this->m_size = 0;
~hashTable()
clear();
迭代器
哈希表的迭代器本质就是对哈希结点指针的一个封装。但由于我们要实现++运算符重载时,可能需要在哈希表当中查询当前指针在哈希桶的位置,因此还需要存储一个哈希表的对象。
template<class K,class T,class KOfVal,class Hash>
class hashIterator
public:
typedef hashIterator<K, T, KOfVal, Hash> self;
typedef class hashTable<K, T, KOfVal, Hash> HT;
HT* m_ht;
typedef hashNode<T> Node;
Node* m_node;
;
因此在构造迭代器时,我们不仅需要对应哈希结点的指针,还需要该哈希表对象,通过哈希表对象来算出当前迭代器所在的位置。而这个对象通过传this指针来给定。
hashIterator(Node*node, HT* ht) :m_node(node), m_ht(ht)
当对迭代器进行解引用操作时,我们要返回对应结点数据的引用。
T& operator*()
return m_node->m_data;
当对迭代器进行->操作时,我们要返回对应结点数据的地址。
T* operator->()
return &m_node->m_data;
当我们需要比较两个迭代器是否相等时,只需要判断这两个迭代器所封装的指针是否相等即可。
bool operator!=(const self&s)
return m_node != s.m_node;
bool operator==(const self& s)
return m_node == s.m_node;
而++运算符重载函数,首先就是要找到下一个结点的位置,其中实现思路如下:
- 若当前的迭代器是哈希表中的某一个桶的最后一个结点,则找到下一个非空哈希桶的第一个结点。
- 若当前结点不是哈希表中的某一个桶的最后一个结点,则通过结点当中的m_next,++后走到当前哈希桶的下一个结点。
而后置++完全可以复用前置++来实现。
self operator++(int)
self temp(*this);
this->operator++();
return temp;
注意: 在STL中unordered_map、unordered_set迭代器类型是单向迭代器,即没有实现- - 运算符的重载,并且不支持+、-。
封装好迭代器后,我们就在哈希表类当中添加begin()和end()两个函数。并且将迭代器类声明为哈希表类的友元。
template<class K,class T,class KOfVal,class Hash>
class hashTable
public:
typedef hashNode<T> node;
typedef hashIterator<K, T, KOfVal, Hash> iterator;
template<class K, class T, class KOfVal, class Hash>
friend class hashIterator;
iterator begin()
size_t length = static_cast<size_t>(m_table.size());
for (size_t i = 0; i < length; ++i)
if (m_table[i] != nullptr)
return iterator(m_table[i], this);
//如果不存在了,这里我们简单处理一下之间返回一个
return iterator(nullptr, this);
iterator end()
return iterator(nullptr, this);
private:
std::vector<node*> m_table; //拿一个动态数组vector来存储单链表,相当于指针数组
Hash hash; //不同的类型通过Hash来得到一个可以用来取模的数字。
size_t m_size; //记录表中存储的数据个数
KOfVal m_c;
;
unordered_map与unordered_set封装
实现unordered_map与unordered_set的各个接口时,就只需要调用底层哈希表对应的接口就行了。
其中代码如下:
template<class K,class Hash = _hash<K>>
class unordered_set
public:
struct setKey
const K& operator()(const K& k)
return k;
;
typedef class hashTable<K, K, setKey, Hash>::iterator iterator;
iterator begin()
return m_ht.begin();
iterator end()
return m_ht.end();
K insert(const K& k)
return m_ht.insert(k);
private:
hashTable<K, K, setKey, Hash>m_ht;
;
与unordered_set不同的是,unordered_map还需要多重载一个[]。
template<class K,class V,class Hash=_hash<K>>
class unordered_map
public:
struct mapKey
const K& operator()(const pair<K, V>& kv)
return kv.first;
;
typedef class hashTable<K, pair<K,V>, mapKey, Hash>::iterator iterator;
iterator begin()
return m_ht.begin();
iterator end()
return m_ht.end(