kafka broker详解
Posted jxj_cd
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kafka broker详解相关的知识,希望对你有一定的参考价值。
broker总体工作流程图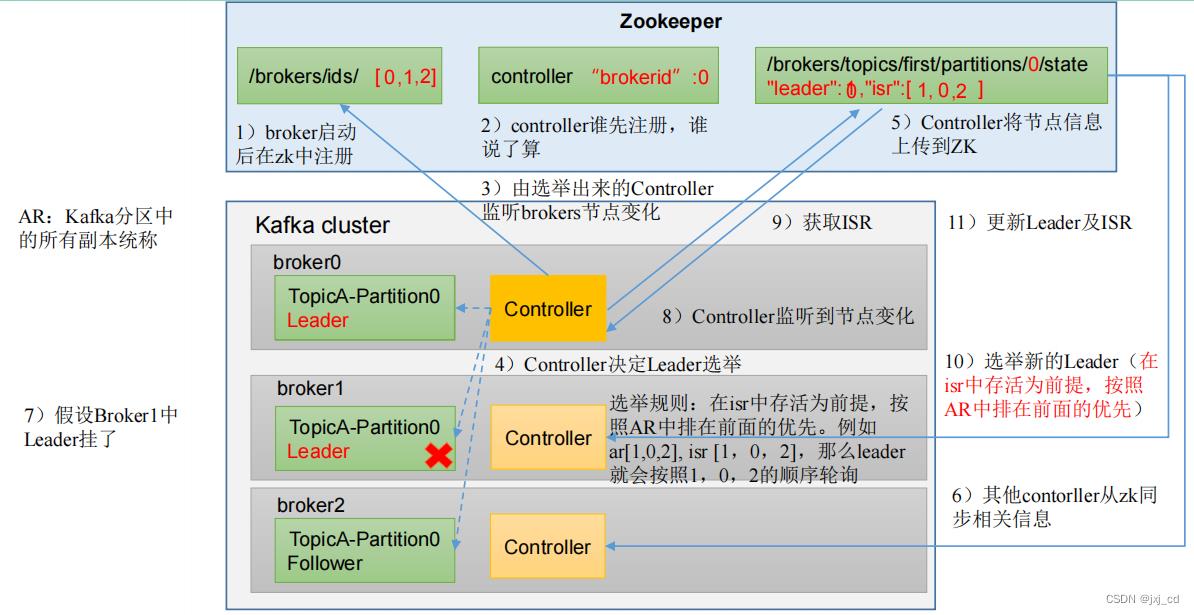
副本机制
- 副本作用提高数据可靠性。
- Kafka 默认副本 1 个,生产环境一般配置为 2 个,保证数据可靠性;过多副本会增加磁盘存储空间,增加网络上数据传输,降低效率。
- Kafka 中副本分为:Leader 和 Follower。Kafka 生产者只会把数据发往 Leader,然后 Follower 找 Leader 进行同步数据。
- Kafka 分区中的所有副本统称为 AR(Assigned Repllicas)。AR = ISR + OSR ISR,表示和 Leader 保持同步的 Follower 集合。如果 Follower 长时间未向 Leader 发送 通信请求或同步数据,则该 Follower 将被踢出 ISR。该时间阈值由 replica.lag.time.max.ms
参数设定,默认 30s。Leader 发生故障之后,就会从 ISR中选举新的 Leader。
OSR ,表示 Follower 与 Leader副本同步时,延迟过多的副本。
leader选举过程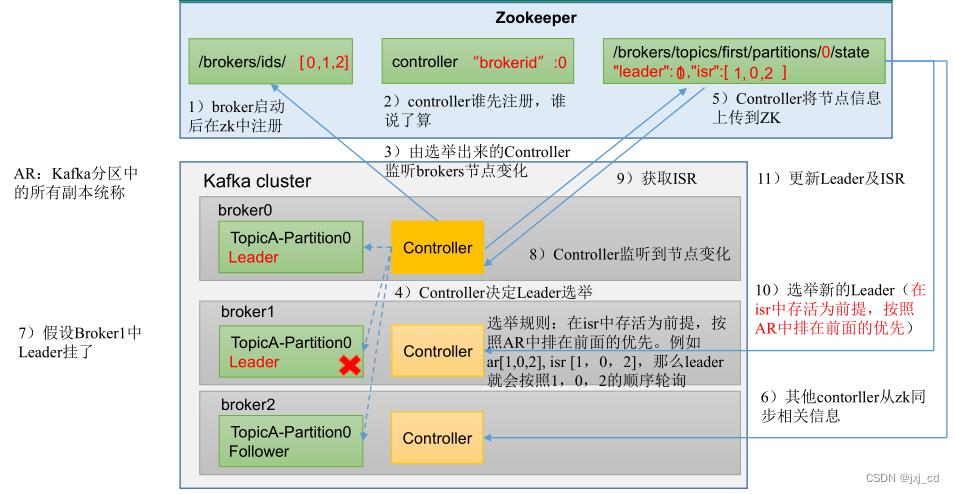
副本同步机制
- LEO(Log End Offset):每个副本的最后一个offset,LEO其实就是最新的offset + 1。
- HW(High Watermark):所有副本中最小的LEO 。用来判定副本的备份进度,HW以外的消息消费者不可见。leader持有的HW即为分区的HW,同时leader所在broker还保存了所有follower副本的LEO。

Follower故障
1) Follower发生故障后会被临时踢出ISR
2) 这个期间Leader和Follower继续接收数据
3) 待该Follower恢复后, Follower会读取本地磁盘记录的
上次的HW,并将log文件高于HW的部分截取掉,从HW开始向Leader进行同步。
4) 等该Follower的LEO大于等于该Partition的HW(leader的HW),即
Follower追上Leader之后,就可以重新加入ISR了。
Leader 故障
1)Leader发生故障之后,会从ISR中选出一个新的Leader。
2)为保证多个副本之间的数据一致性,其余的Follower会先将各自的log文件高于HW的 部分截掉,然后从新的Leader同步数据。
注意:这只能保证副本之间的数据一致性,并不能保证数据不丢失或者不重复。
Leader Partition自动平衡
正常情况下,Kafka本身会自动把Leader Partition均匀分散在各个机器上,来保证每台机器的读写吞吐量是均匀的。但是如果某些broker宕机,会导致Leader Partition过于集中在其他少部分几台broker上,这会导致少数几台broker的读写请求压力过高,其他宕机的broker重启之后都是follower partition,读写请求很低,造成集群负载不均衡。
- auto.leader.rebalance.enable,默认是true。自动Leader Partition 平衡
- leader.imbalance.per.broker.percentage,默认是10%。每个broker允许的不平衡的leader的比率。如果每个broker超过了这个值,控制器会触发leader的平衡。
- leader.imbalance.check.interval.seconds,默认值300秒。检查leader负载是否平衡的间隔时间。
Kafka文件存储机制
Topic是逻辑上的概念,而partition是物理上的概念,每个partition对应于一个log文件,该log文件中存储的就是Producer生产的数据。Producer生产的数据会被不断追加到该log文件末尾,为防止log文件过大导致数据定位效率低下,Kafka采取了分片和索引机制,将每个partition分为多个segment。每个segment包括:“.index”文件、“.log”文件和.timeindex等文件。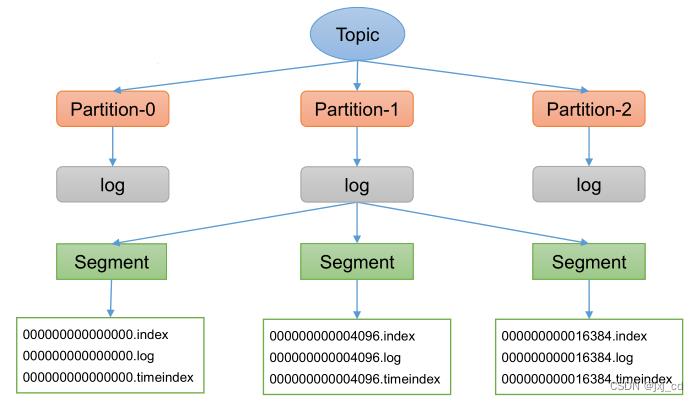
.log 数据日志文件 .index偏移量索引文件 .timeindex 时间戳索引文件。index和log文件以当前
segment的第一条消息的offset命名。
高效 读写 数据
- Kafka 本身是分布式集群,可以采用分区技术,并行度高。
- 读数据采用稀疏索引,可以快速定位要消费的数据。
- 顺序写磁盘
- Page Cache 技术 虽磁盘顺序写已经很快了,但是对比内存顺序写仍然慢了几个数量级,Page Cache 简单理解就是利用了操作系统本身的缓存技术,在读写磁盘日志文件时,其实操作的都是内存,由操作系统决定什么时候将 Page Cache 里的数据真正刷入磁盘。
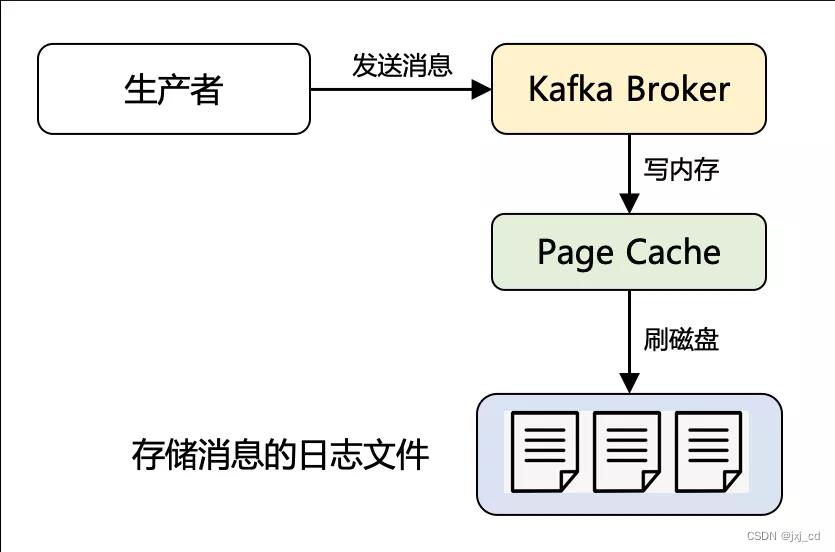
Page Cache 一般缓存的是最近被使用的数据,最近访问的数据很可能接下来再访问到。而预读到 Page Cache 中的磁盘数据,又利用空间局部性原理,数据往往是连续访问的。而 Kafka 消息先是顺序写入,而且很有可能立马又会被消费者读取到。因此,页缓存可以说是 Kafka 做到高吞吐的重要因素之一。
mmap+sendfile
kafak 利用稀疏索引,已经基本解决了高效查询的问题,但是这个过程中仍有进一步的优化空间,就是通过mmap(memory mapped files) 读写稀疏索引文件,进一步提高查询消息的效率。
消息借助稀疏索引被查询到后,将消息从磁盘文件中读出来,然后通过网卡发给消费者,这一步Kafka 用到了零拷贝(Zero-Copy)技术来提升性能。与传统IO不同所谓的零拷贝是指数据直接从磁盘文件复制到网卡设备,而无需经过应用程序,减少了内核和用户模式之间的上下文切换和内存的拷贝次数。
传统IO:
零拷贝: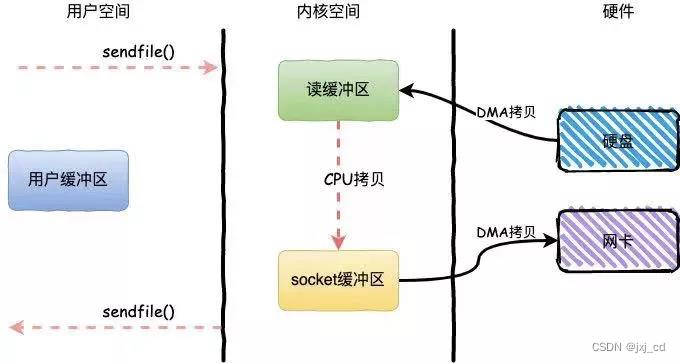
以上是关于kafka broker详解的主要内容,如果未能解决你的问题,请参考以下文章