kafka 生产者发送流程
Posted jxj_cd
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kafka 生产者发送流程相关的知识,希望对你有一定的参考价值。
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。
kafka的基础架构: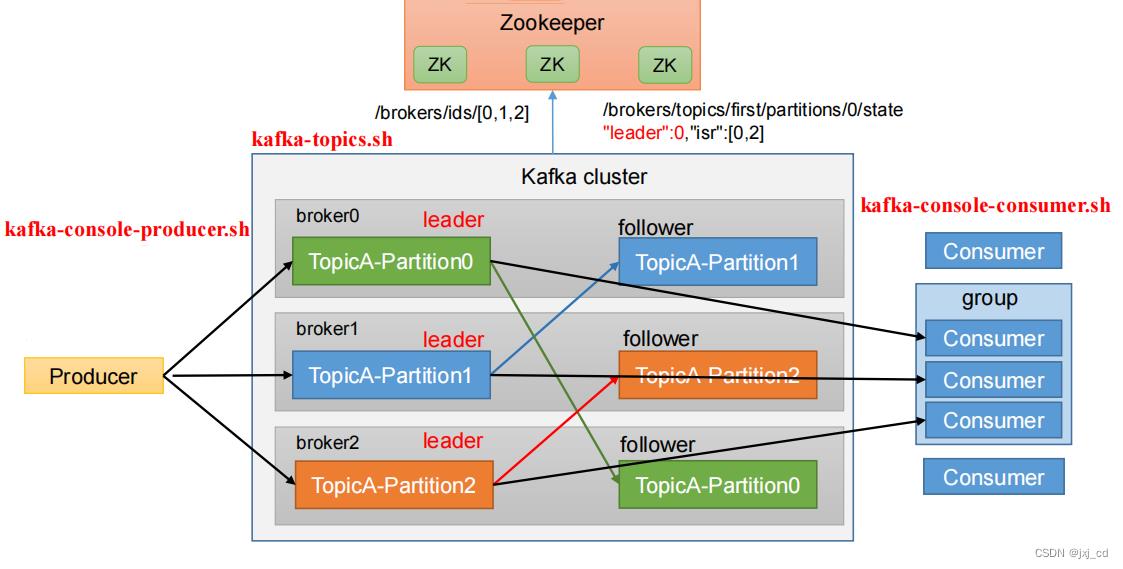
Kafka生产者发送流程详解 :
拦截器
序列化器
分区器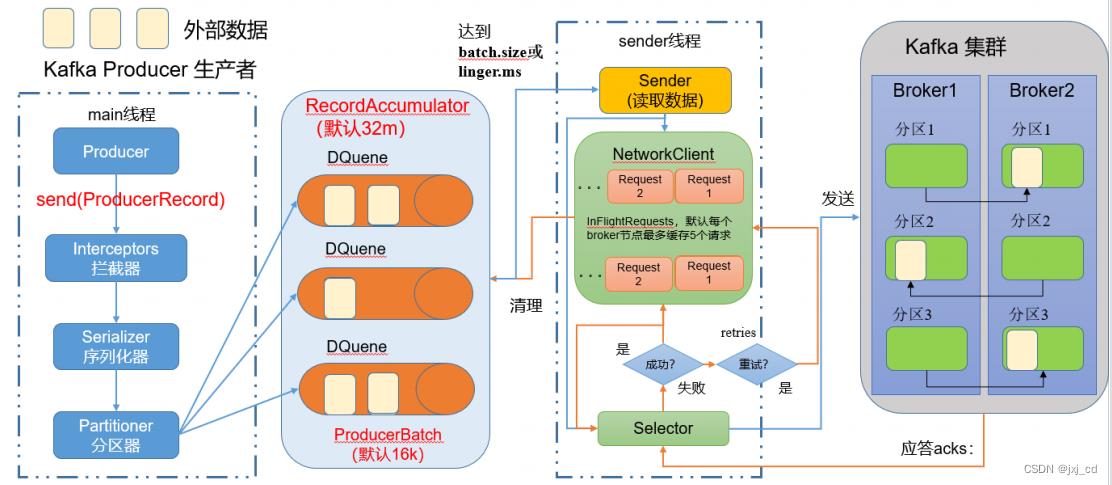
生产者端由两个线程协调完成,分别是main线程和Sender线程。main线程在将消息通过拦截器、序列化器和分区器处理后缓存到消息累加器(RecordAccumlator)中。Sender线程负载从RecordAccumulator中获取消息并将其发送到Kafka集群中。
- main线程:在客户端将数据放入双端队列里
- Sender线程:从队列里读取数据发送到kafka集群
- DQueue:双端队列,每个分区对应一个双端队列。队列中的内容就是ProducerBatch,即DQueue<ProducerBatch>,写入缓存时放入尾部,Sender读取消息时从头部读取。
- batch.size:只有数据积累到batch.size之后,sender才会取数据发送,默认大小为16k。
- linger.ms:如果数据迟迟没有到达batch.size,那么sender线程在等待linger.ms设置的实践到达后就会取数据发送。(默认是0,表示不等待)
- ProducerBatch:就是一个消息批次,包含很多ProducerRecord
- RecordAccumulator主要用来缓存消息以便 Sender 线程可以批量发送,减少网络传输的资源消耗以提升性能。可通过生产者客户端参数buffer.memory配置,默认大小为32M。当生产者的缓冲区已满,这些方法就会阻塞。在阻塞时间达到
max.block.ms时,生产者抛出超时异常。 - InFlightRequests:缓存已经发出去但还没有收到响应的请求,配置参数为max.in.flight.requests.per.connection,默认值为5,即最多只能缓存5个未收到响应的请求。
拦截器
拦截器可以在消息发送前做一些准备工作,如过滤某些不要的信息、修改消息的内容等等。
序列化器
序列化器(Serializer)用于把对象转换成字节数组能通过网络发送给broker。消费者需要用反序列化器(Deserializer)把从Kafka中收到的字节数组转换成相应的对象。
分区器
主要有以下策略
-
指定partition 如果在创建ProducerRecord的时候,指定了分区号,那么就会存储到这个分区中去。
- 指定Key 将key的hash值与topic的分区数取余得到最终的分区号。
- 即没有key,也没有分区号,采用默认的RoundRobin轮询分配。(kafka2.4后使用StickyPartitioning Strategy分区)。
ack应答级别
producer发送给broker有以下三种应答级别
- 0:生产者发送到服务端即可,不需要等待应答如果服务端接收到消息后突然宕机都就会导致数据丢失 ,此种级别可靠性很差但效率很高。
- 1:leader收到即可,如果leader还未同步到follower就挂了,那么也会导致丢数问题 ,此种级别可靠性中等效率中等。
- -1:ISR队列里的所有节点都收到消息后返回 ,此种级别可靠性很高但效率很低。
注意: 数据完全可靠条件 = ACK级别设置为-1 + 分区副本大于等于2 + ISR里应答的最小副本数量大于等于2
数据重复问题
产生重复消息的原因:生产者发出一条消息,Broker 落盘以后因为网络等原因,发送端得到一个发送失败的响应或者网络中断,重试消息导致消息重复;ack为-1时生产者发送数据到leader,leader写完数据,ISR中的follower也拉取完数据,但是在返回ack之前,leader宕机了,此时生产者的没拿到ack,重发数据。kafka就又会重新保存这份数据,这种情况也会导致数据重复。
数据去重
数据传递语义
- 至少一次 (At Least Once) = ACK级别设置为- 1 + 分区副本大于等于2 + ISR里应答的最小副本数量大于等于2(以保证数据不丢失,但是不能保证数据不重复)
- 最多一次 (At Most Once) = ACK级别设置为0(可以保证数据不重复,但是不能保证数据不丢失)
- 精确一次 (Exactly Once) :对于一些非常重要的数据,比如和钱相关的数据,要求数据既不能重复也不丢失。
Kafka 0. 11版本以后,引入了一项重大特性:幂等性和事务。
幂等性原理
幂等性就是指Producer不论向Broker发送多少次重复数据,Broker端都只会持久化一条,保证了不重复。精确一次 (Exactly Once) = 幂等性 + 至少一次 。重复数据的判断标准:具有相同<PID, Partition, SeqNumber>的消息提交时,Broker只会持久化一条。其 中PID是Kafka每次重启都会分配一个新的;Partition 表示分区号;Sequence Number是单调自增的。
所以幂等性只能保证的是在单分区单会话内不重复。如果需要实现重启幂等可以使用事务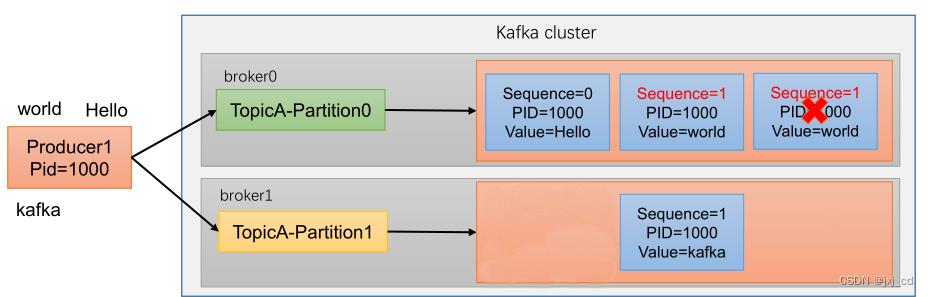
事务原理
开启事务,必须开启幂等性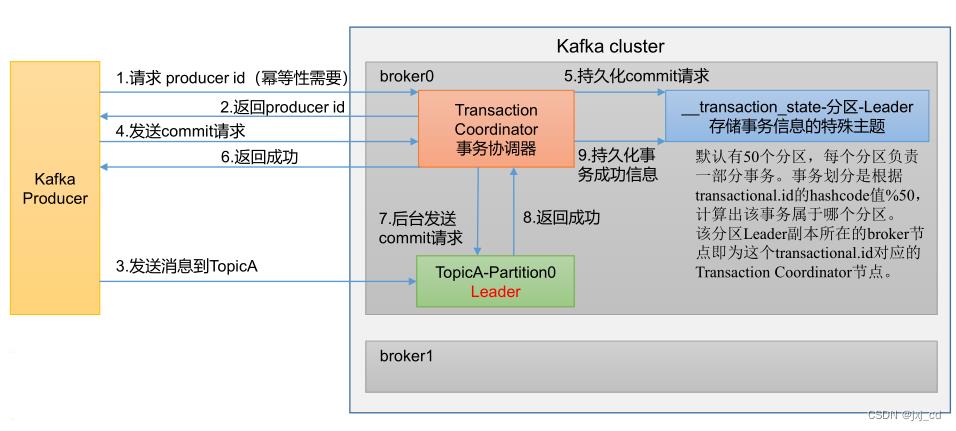
Producer 在使用事务功能前,必须先自定义一个唯一的 transactional.id 。有了 transactional.id ,即使客户端挂掉了, 它重启后也能继续处理未完成的事务。
数据有序
- kafka在1.x版本之前保证数据单分区有序,只需配置max.in.flight.requests.per.connection=1(不需要考虑是否开启幂等性)。
- kafka在1.x及以后版本保证数据单分区有序,分两种情况
第一种:未开启幂等性 max.in.flight.requests.per.connection 需要设置为1。
第二种:开启幂等性 max.in.flight.requests.per.connection 需要设置为小于等于5。
原因:因为在kafka1.x以后,启用幂等后,kafka服务端会缓存producer发来的最近5个request的元数据,所以可以保证最近5个request的数据都是有序的。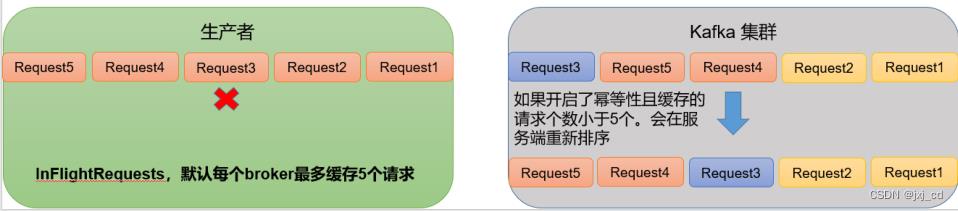
以上是关于kafka 生产者发送流程的主要内容,如果未能解决你的问题,请参考以下文章