助力工业物联网,工业大数据之分层总体设计
Posted Maynor996
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了助力工业物联网,工业大数据之分层总体设计相关的知识,希望对你有一定的参考价值。
数仓设计及数据采集
01:课程回顾
-
一站制造项目的需求是什么?
- 行业:工业物联网
- 项目:加油站服务商数据分析平台
- 需求
- 提高服务质量:安装、维修、巡检、改造工单分析,回访分析
- 合理规划成本运算:收益分析、报销分析、物料成本
-
一站制造项目的技术选型是什么?
- 数据来源:Oracle【CRM系统、客服系统、报销系统】
- 数据采集:Sqoop
- 数据存储:Hive数据仓库
- 数据计算:SparkSQL【离线+实时、DSL + SQL】
- 数据应用:mysql + Grafana
- 调度工具:Airflow
- 服务监控:Prometheus
- 资源容器:Docker
-
Docker中的基本容器管理命令是什么?
- 启动和关闭:docker start|stop 容器名称
- 进入和退出
- docker exec -it 容器名称 bash
- exit
-
问题
-
DG连接问题
-
原理:JDBC:用Java代码连接数据库
-
Hive/SparkSQL:端口有区别
-
可以为同一个端口,只要不在同一台机器
-
项目:一台机器
-
HiveServer:10000
hiveserver.port = 10000 -
SparkSQL:10001
start-thriftserver.sh --hiveserver.prot = 10001
-
-
-
MySQL:hostname、port、username、password
-
Oracle:hostname、port、username、password、sid
-
驱动导入
- 自动导入:MYSQL、Oracle
- 手动导入:Hive、SparkSQL
- step1:清空所有自带的包
- step2:导入所有的包
- hive-2.1.0
- hive-2.1.0-spark
-
-
CS模式设计问题
- Thrift启动问题
- CS模式:客户端服务端模式
- Client:客户端
- Hive:Beeline、Hue
- SparkSQL
- Server:服务端
- Hive:Hiveserver2【负责解析SQL语句】
- HiveServer作为Metastore的客户端
- MetaStore作为HiveServer的服务端
- SparkSQL:ThriftServer【负责解析SQL语句转换为SparkCore程序】
- 放入hive-site.xml文件到Spark的conf目录的目的?
- 让SparkSQL能够访问Hive的元数据服务的地址:metastore、
- 为了访问Hive
- 不放行不行:可以
- 启动ThriftServer或者HiveServer
- docker start hadoop
- docker start hive
- docker start spark
- 放入hive-site.xml文件到Spark的conf目录的目的?
- Hive:Hiveserver2【负责解析SQL语句】
- Client:客户端
-
问题:思路
-
现象:异常
- Python:error:xxxxxx
- Java:throw Exception:xxxxxxxxx
- 进程没有明显报错:找日志文件
- 日志文件:logs
- 查看日志:tail -100f logs/xxxxxxxx.log
-
分析错误
- ArrayoutofIndex
- NullException
- ClassNotFound
- 自己先尝试解决
- 如果解决不了,就问老师
-
-
02:课程目标
- 数据仓库设计
- 建模:维度建模:【事实表、维度表】
- 分层:ODS、DW【DWD、DWM、DWS】、APP
- 掌握本次项目中数仓的分层
- ODS、DWD、DWB、DWS、ST、DM
- 业务系统流程和数据来源
- 数据源
- 常见的数据表
- 数据采集
- 核心1:实现自动化增量采集
- 核心2:Sqoop采集中的一个特殊问题以及解决方案
03:数仓设计回顾
-
目标:了解数据仓库设计的核心
-
路径
- step1:分层
- step2:建模
-
实施
-
分层
- 什么是分层?
- 本质:规范化数据的处理流程
- 实现:每一层在Hive中就是一个数据库
- 为什么要分层?
- 清晰数据结构:每一个数据分层都有它的作用域,这样我们在使用表的时候能更方便地定位和理解。
- 数据血缘追踪:简单来讲可以这样理解,我们最终给业务诚信的是一能直接使用的张业务表,但是它的来源有很多,如果有一张来源表出问题了,我们希望能够快速准确地定位到问题,并清楚它的危害范围。
- 减少重复开发:规范数据分层,开发一些通用的中间层数据,能够减少极大的重复计算。
- 把复杂问题简单化:一个复杂的任务分解成多个步骤来完成,每一层只处理单一的步骤,比较简单和容易理解。
- 屏蔽原始数据的异常对业务的影响:不必改一次业务就需要重新接入数据
- 怎么分层?
- ODS:原始数据层/操作数据层,最接近与原始数据的层次,数据基本与原始数据保持一致
- DW:数据仓库层,实现数据的处理转换
- DWD:实现ETL
- DWM:轻度聚合
- DWS:最终聚合
- ADS/APP/DA:数据应用层
- 什么是分层?
-
建模
-
什么是建模?
- 本质:决定了数据存储的方式,表的设计
-
为什么要建模?
- 大数据系统需要数据模型方法来帮助更好地组织和存储数据,以便在性能、成本、效率和质量之间取得最佳平衡。
- 性能:良好的数据模型能帮助我们快速查询所需要的数据,减少数据的I/O吞吐
- 成本:良好的数据模型能极大地减少不必要的数据冗余,也能实现计算结果复用,极大地降低大数据系统中的存储和计算成本
- 效率:良好的数据模型能极大地改善用户使用数据的体验,提高使用数据的效率
- 质量:良好的数据模型能改善数据统计口径的不一致性,减少数据计算错误的可能性
-
有哪些建模方法?
- ER模型:从全企业的高度设计一个 3NF 【三范式】模型,用实体关系模型描述企业业务,满足业务需求的存储
- 维度模型:从分析决策的需求出发构建模型,为分析需求服务,重点关注用户如何更快速的完成需求分析,具有较好的大规模复杂查询的响应性能
- Data Vault:ER 模型的衍生,基于主题概念将企业数据进行结构化组织,并引入了更进一步的范式处理来优化模型,以应对源系统变更的扩展性
- Anchor:一个高度可扩展的模型,核心思想是所有的扩展知识添加而不是修改,因此将模型规范到 6NF,基本变成了 k-v 结构化模型
-
怎么构建维度模型步骤?
- a.选择业务过程:你要做什么?
- b.声明粒度:你的分析基于什么样的颗粒度?
- c.确认环境的维度:你的整体有哪些维度?
- d.确认用于度量的事实:你要基于这些维度构建哪些指标?
-
具体的实施流程是什么?
-
a.需求调研:业务调研和数据调研
- 业务调研:明确分析整个业务实现的过程
- 数据调研:数据的内容是什么
-
b.划分主题域:面向业务将业务划分主题
-
构建哪些主题域以及每个主题域中有哪些主题
-
服务域:工单主题、回访主题、物料主题
-
-
-
c.构建维度总线矩阵:明确每个业务主题对应的维度关系
主题域:主题 时间维度 地区维度 工单主题 Y Y 回访主题 N Y 物料主题 Y N -
d.明确指标统计:明确所有原生指标与衍生指标
-
工单主题:安装工单个数、维修工单个数……
- 回访主题:用户满意个数、不满意个数、服务态度不满意个数、技术能力不满意个数
-
e.定义事实与维度规范
- 分层规范
- 开发规范
-
……
-
-
f.代码开发
-
-
事实表
-
表的分类
- 事务事实表:原始的事务事实的数据表,原始业务数据表
- 周期快照事实表:周期性对事务事实进行聚合的结果
- 累计快照事实表:随着时间的变化,事实是不定的,不断完善的过程
-
无事实事实表:特殊的事实表,里面没有事实,是多个维度的组合,用于求事实的差值
-
值的分类
- 可累加事实:在任何维度下指标的值都可以进行累加
- 半可累加事实:在一定维度下指标的值都可以进行累加
- 不可累加事实:在任何维度下指标的值都不可以进行累加
-
维度表
- 维度设计模型
- 雪花模型:维度表拥有子维度表,部分维度表关联在维度表中,间接的关联事实表
- 星型模型/星座模型:维度表没有子维度,直接关联在事实表上,星座模型中有多个事实
- 上卷与下钻
- 上卷:从小维度到一个大的维度,颗粒度从细到粗
- 下钻:从大维度到一个小的维度,颗粒度从粗到细
- 维度设计模型
-
拉链表
-
功能:解决事实中渐变维度发生变化的问题,通过时间来标记维度的每一种状态,存储所有状态
-
实现
- step1:先采集所有增量数据到更新表中
- step2:将更新表的数据与老的拉链表的数据进行合并写入一张临时表
- step3:将临时表的结果覆盖到拉链表中
-
-
-
-
小结
- 了解数据仓库设计的核心
04:分层整体设计
-
目标:掌握油站分析项目中的分层整体设计
-
实施
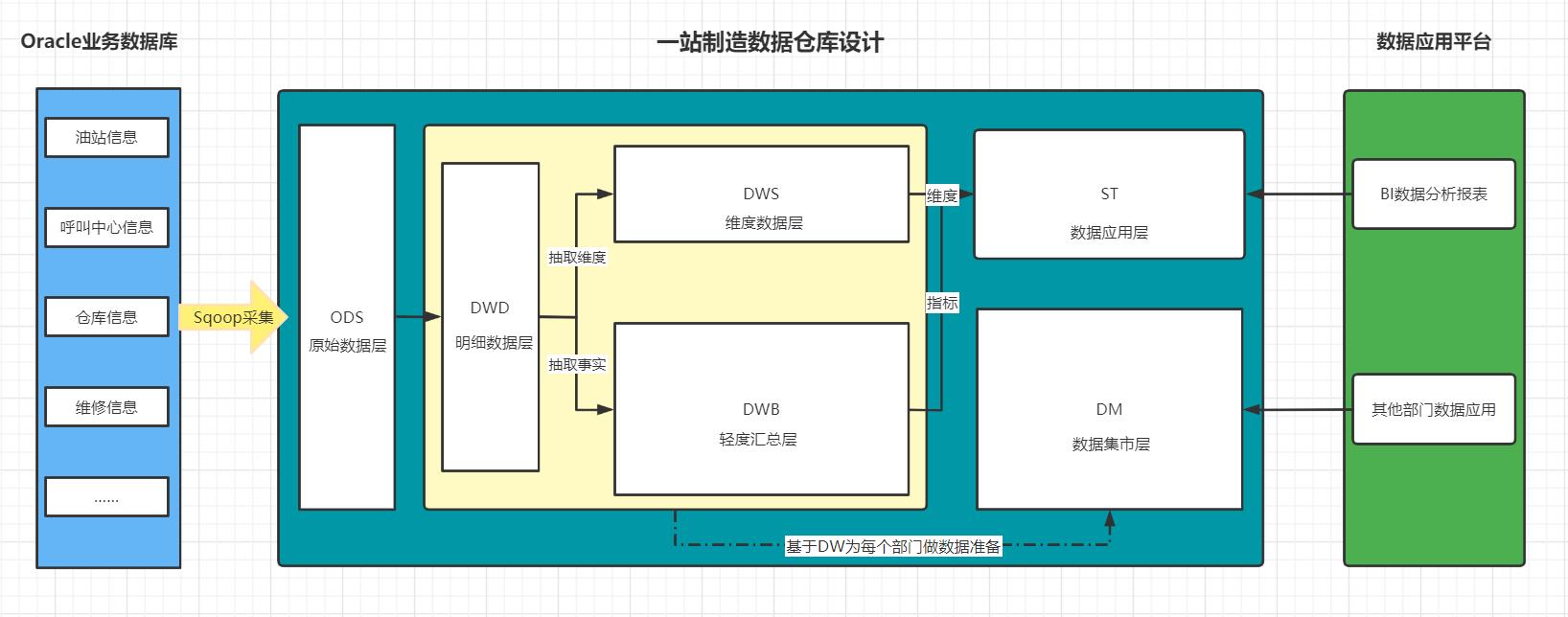
-
ODS:原始数据层:最接近于原始数据的层次,直接采集写入层次:原始事务事实表
-
DWD:明细数据层:对ODS层的数据根据业务需求实现ETL以后的结果:ETL以后事务事实表
-
DWB:基础数据层:
类似于以前讲解的DWM,轻度聚合- 关联:将主题事实的表进行关联,所有与这个主题相关的字段合并到一张表
- 聚合:基于主题的事务事实构建基础指标
- 主题事务事实表
-
ST:数据应用层:
类似于以前讲解的APP,存储每个主题基于维度分析聚合的结果:周期快照事实表- 供数据分析的报表
-
DM:数据集市:按照不同部门的数据需求,将暂时没有实际主题需求的数据存储
- 做部门数据归档,方便以后新的业务需求的迭代开发
-
DWS:维度数据层:类似于以前讲解的DIM:存储维度数据表
-
数据仓库设计方案
- 从上到下:在线教育:先明确需求和主题,然后基于主题的需求采集数据,处理数据
- 场景:数据应用比较少,需求比较简单
- 上下到上:一站制造:将整个公司所有数据统一化在数据仓库中存储准备,根据以后的需求,动态直接获取数据
- 场景:数据应用比较多,业务比较复杂
- 从上到下:在线教育:先明确需求和主题,然后基于主题的需求采集数据,处理数据
-
-
小结
- 掌握油站分析项目中的分层整体设计
- ODS:原始数据层
- DWD:明细数据层
- DWB:轻度汇总层
- ST:数据应用层
- DM:数据集市层
- DWS:维度数据层
- 掌握油站分析项目中的分层整体设计
05:分层具体功能
-
目标:掌握油站分析的每层的具体功能
-
实施
-
ODS
- 数据内容:存储所有原始业务数据,基本与Oracle数据库中的业务数据保持一致
- 数据来源:使用Sqoop从Oracle中同步采集
- 存储设计:Hive分区表,avro文件格式存储,保留3个月
-
DWD
- 数据内容:存储所有业务数据的明细数据
- 数据来源:对ODS层的数据进行ETL扁平化处理得到
- 存储设计:Hive分区表,
orc文件格式存储,保留所有数据
-
DWB
- 数据内容:存储所有事实与维度的基本关联、基本事实指标等数据
- 数据来源:对DWD层的数据进行清洗过滤、轻度聚合以后的数据
- 存储设计:Hive分区表,orc文件格式存储,保留所有数据
-
ST
- 数据内容:存储所有报表分析的事实数据
- 数据来源:基于DWB和DWS层,通过对不同维度的统计聚合得到所有报表事实的指标
-
DM
- 数据内容:存储不同部门所需要的不同主题的数据
- 数据来源:对DW层的数据进行聚合统计按照不同部门划分
-
DWS
-
数据内容:存储所有业务的维度数据:日期、地区、油站、呼叫中心、仓库等维度表
- 数据来源:对DWD的明细数据中抽取维度数据
- 存储设计:Hive普通表,orc文件 + Snappy压缩
- 特点:数量小、很少发生变化、全量采集
-
-
-
小结
- 掌握油站分析的每层的具体功能
以上是关于助力工业物联网,工业大数据之分层总体设计的主要内容,如果未能解决你的问题,请参考以下文章