Pandas学习2
Posted Zephyr丶J
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Pandas学习2相关的知识,希望对你有一定的参考价值。
Pandas学习2
None
两种缺失数据:None、np.nan(NaN)
None是python自带的,不能参与计算。类型是object

np.nan
浮点类型,说明能参与计算,但是结果是nan

pandas中的None和np.nan
pandas中的None和np.nan都视为np.nan
如果列中有一个数变成了浮点数,那么整个列都会变成浮点数
判断是否有缺失
isnull()
notnull()
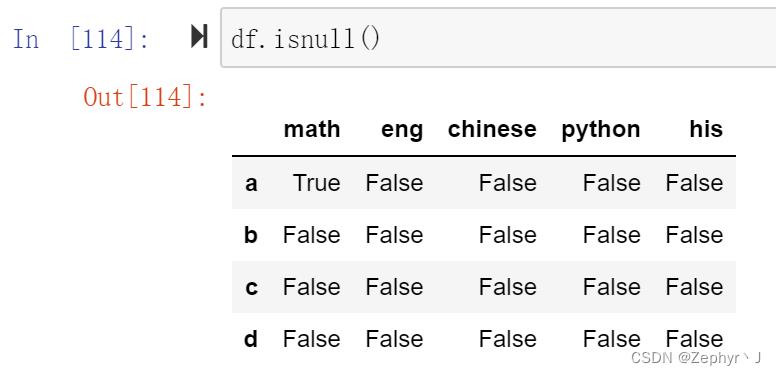
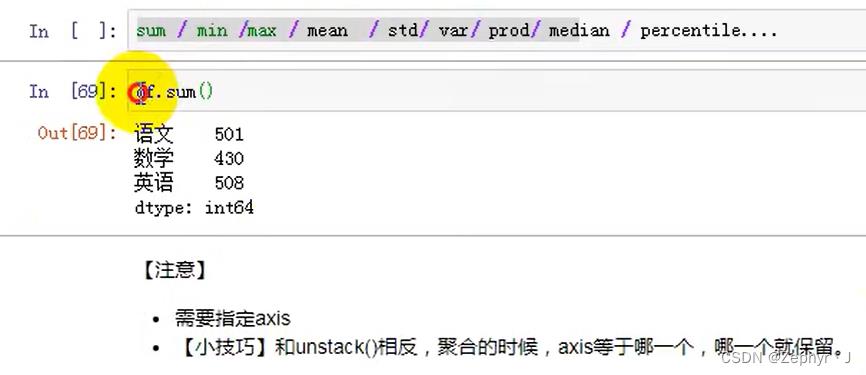
any() 默认对行处理,判断每一列是否有空数据

加入axis改成判断行

删除缺失值
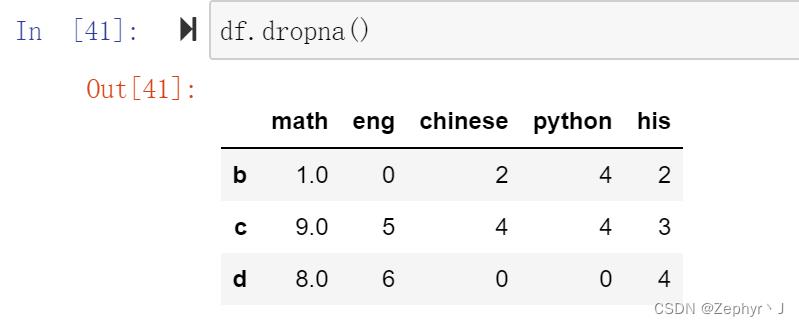
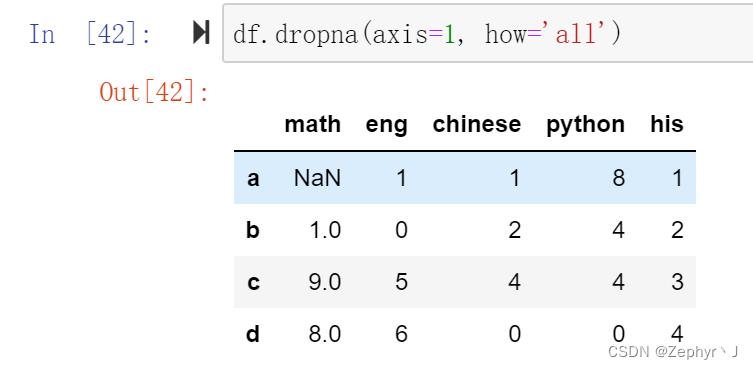
默认axis=0,删除行;加上how=‘all’,只有全部是nan才删除
并且注意这个方法不会修改原来的数据,需要接收返回值
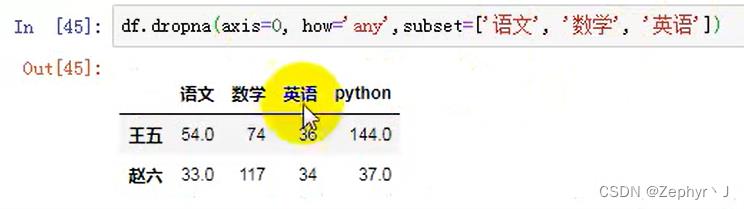
子集的功能,用于判断子集中是否有空,有空就删除
参数thresh,应该是保留至少有n个非NaN数据的行/列
In [6]: data
Out[6]:
0 1 2 3 4
0 32 38.0 11.0 69.0 34
1 59 NaN NaN NaN 62
2 14 79.0 NaN NaN 78
3 77 76.0 17.0 NaN 89
4 6 40.0 53.0 60.0 70
In [7]: data.dropna(thresh=1)
Out[7]:
0 1 2 3 4
0 32 38.0 11.0 69.0 34
1 59 NaN NaN NaN 62
2 14 79.0 NaN NaN 78
3 77 76.0 17.0 NaN 89
4 6 40.0 53.0 60.0 70
In [8]: data.dropna(thresh=2)
Out[8]:
0 1 2 3 4
0 32 38.0 11.0 69.0 34
1 59 NaN NaN NaN 62
2 14 79.0 NaN NaN 78
3 77 76.0 17.0 NaN 89
4 6 40.0 53.0 60.0 70
In [9]: data.dropna(thresh=3)
Out[9]:
0 1 2 3 4
0 32 38.0 11.0 69.0 34
2 14 79.0 NaN NaN 78
3 77 76.0 17.0 NaN 89
4 6 40.0 53.0 60.0 70
填充缺失
用指定的值去填充
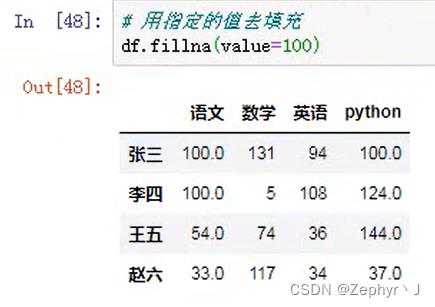
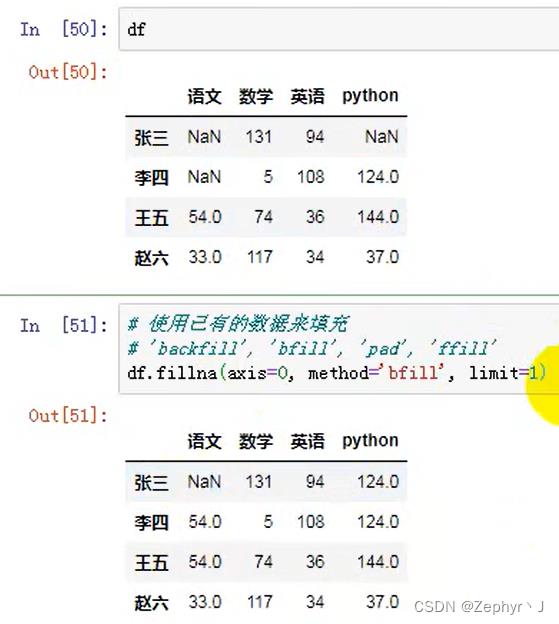
用其他值去填充,这里可以设置填充方向和填充方法,b开头的是向后,其他是向前填充;这里limit是限制一个数填充的次数,1表示一个数只能填充一个位置
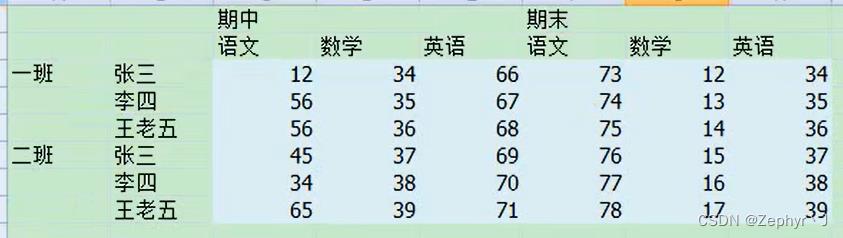
层级索引
是指这种多层级的索引
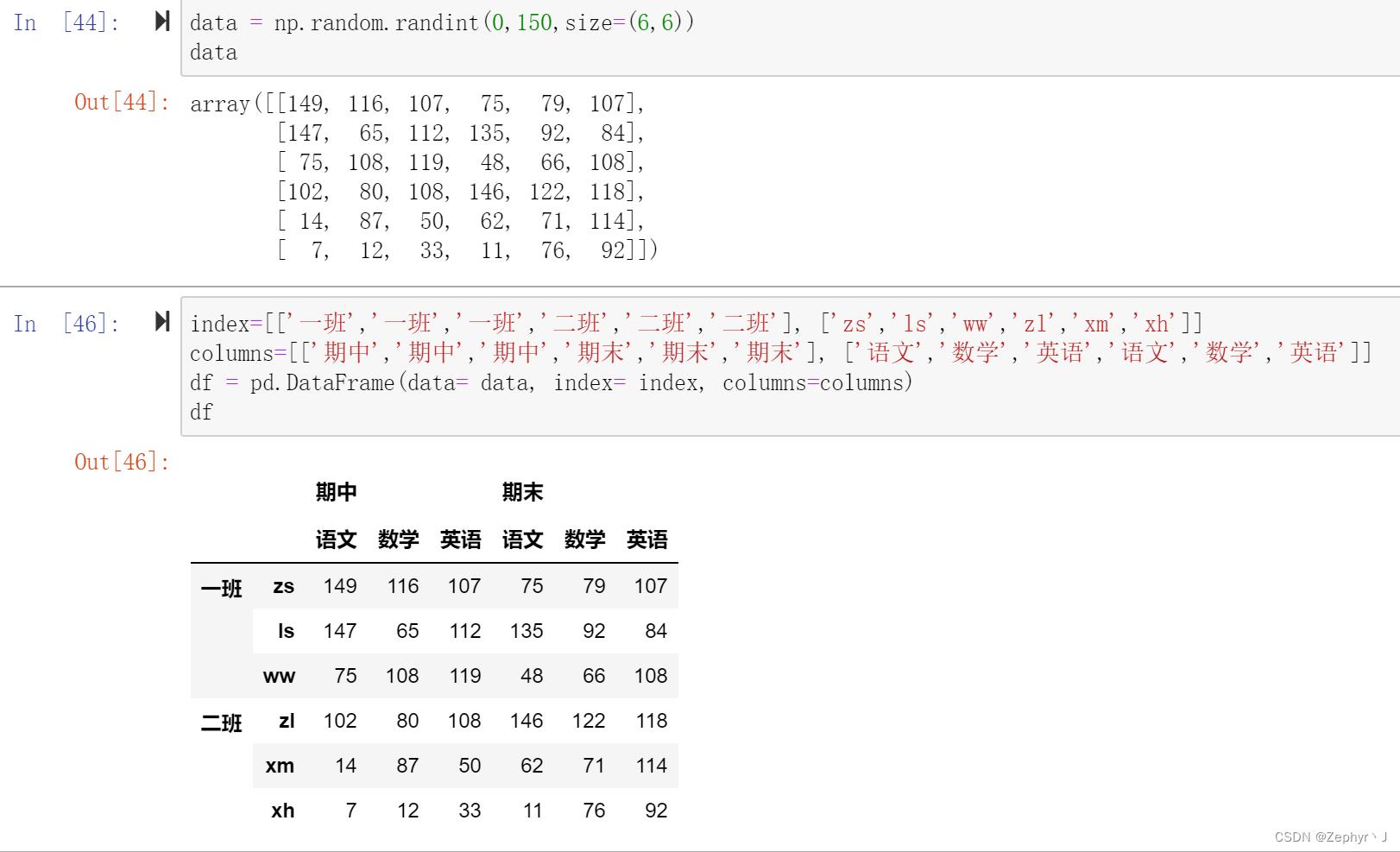
创建层级数据框
隐式创建,即直接写,索引变成两个数组,这样创建出来的索引就是多层的索引
同理,series也可以创建多层索引
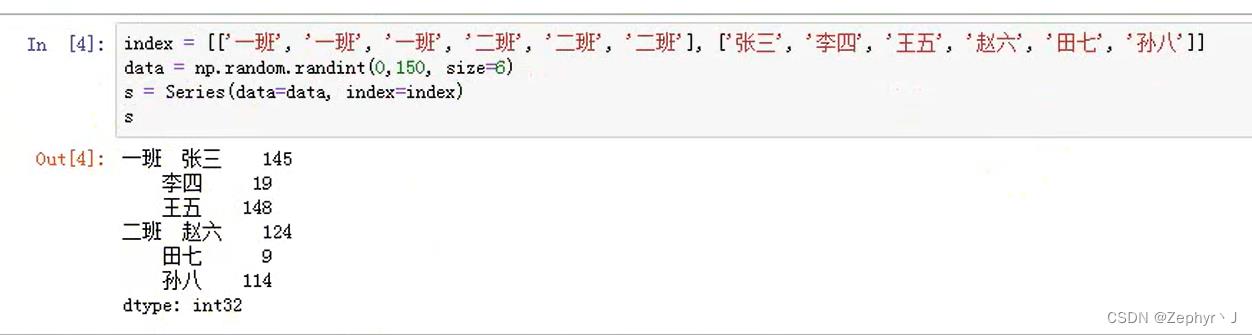
显式构造pd.MultiIndex,这种和上种基本一致
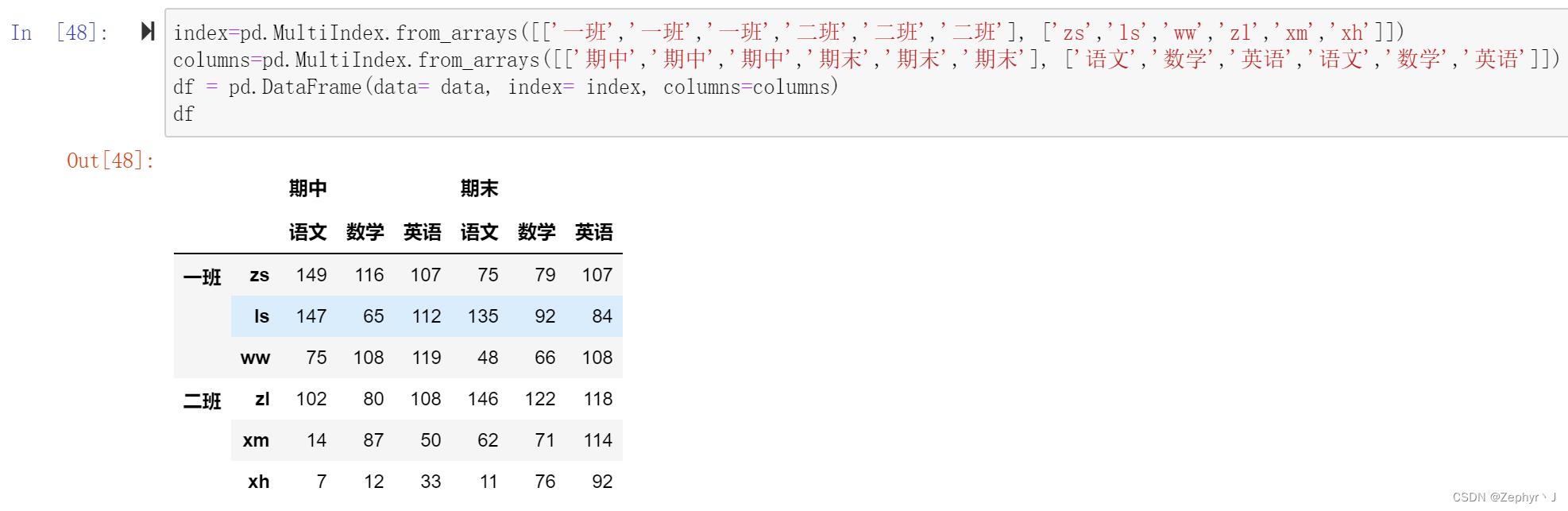
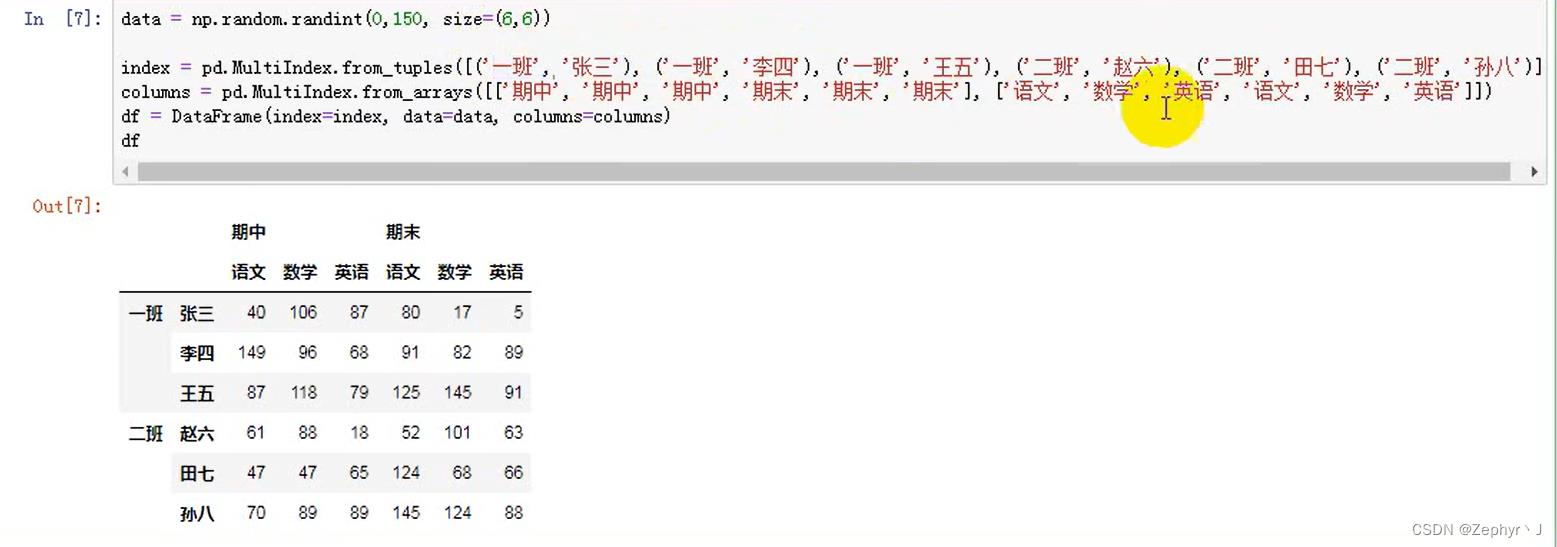
使用元祖tuple
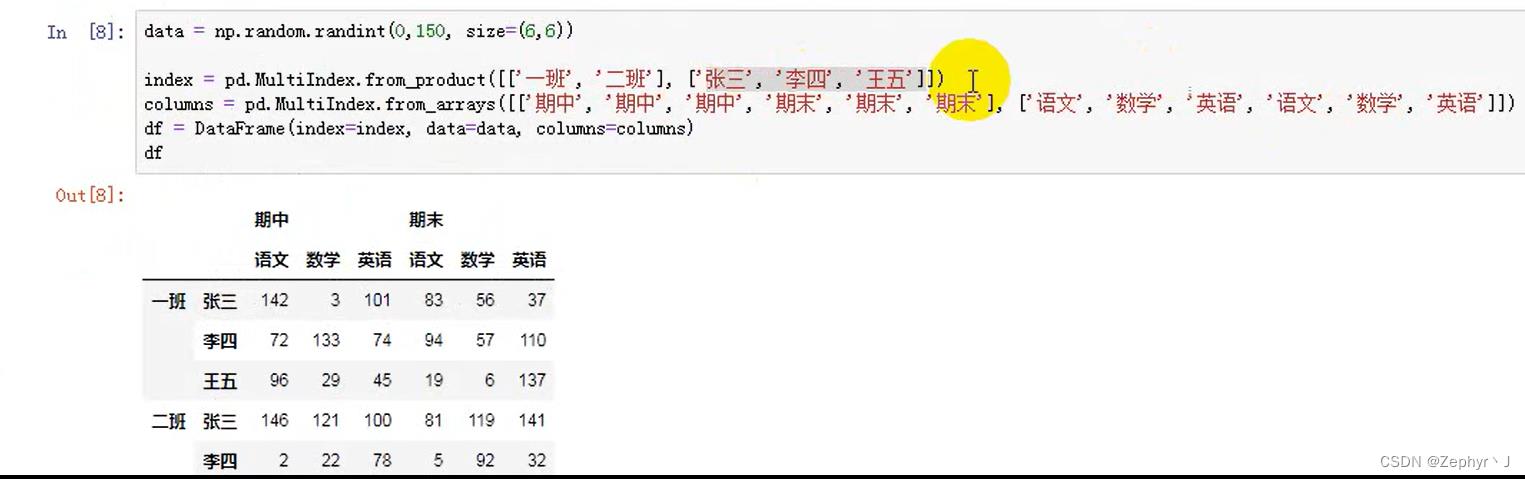
使用product,即乘积的方式,相对方便,但是也要看情况使用,比如这里两个班的学生名字都一样明显不太合适
多层索引对象的索引或切片操作
原则:当有多层索引的时候,不能直接使用内层索引
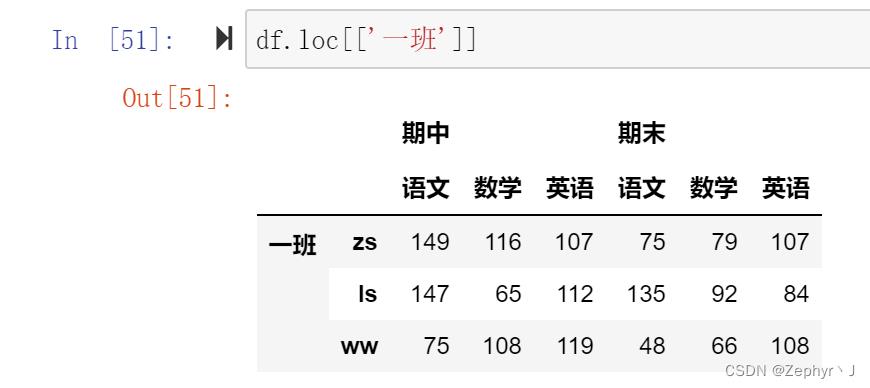


切片只能切外层的索引,如果要切出想要的结果,可以使用iloc进行切片

对列索引同样的道理,也不能直接切内层,可以使用隐式索引
在改变其中数据的时候,直接该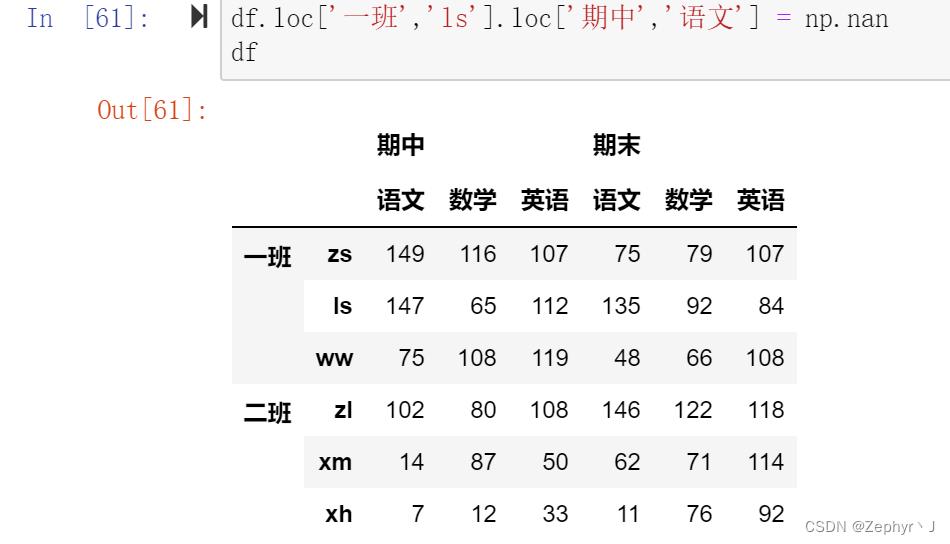
先将int类型修改为float类型,再修改
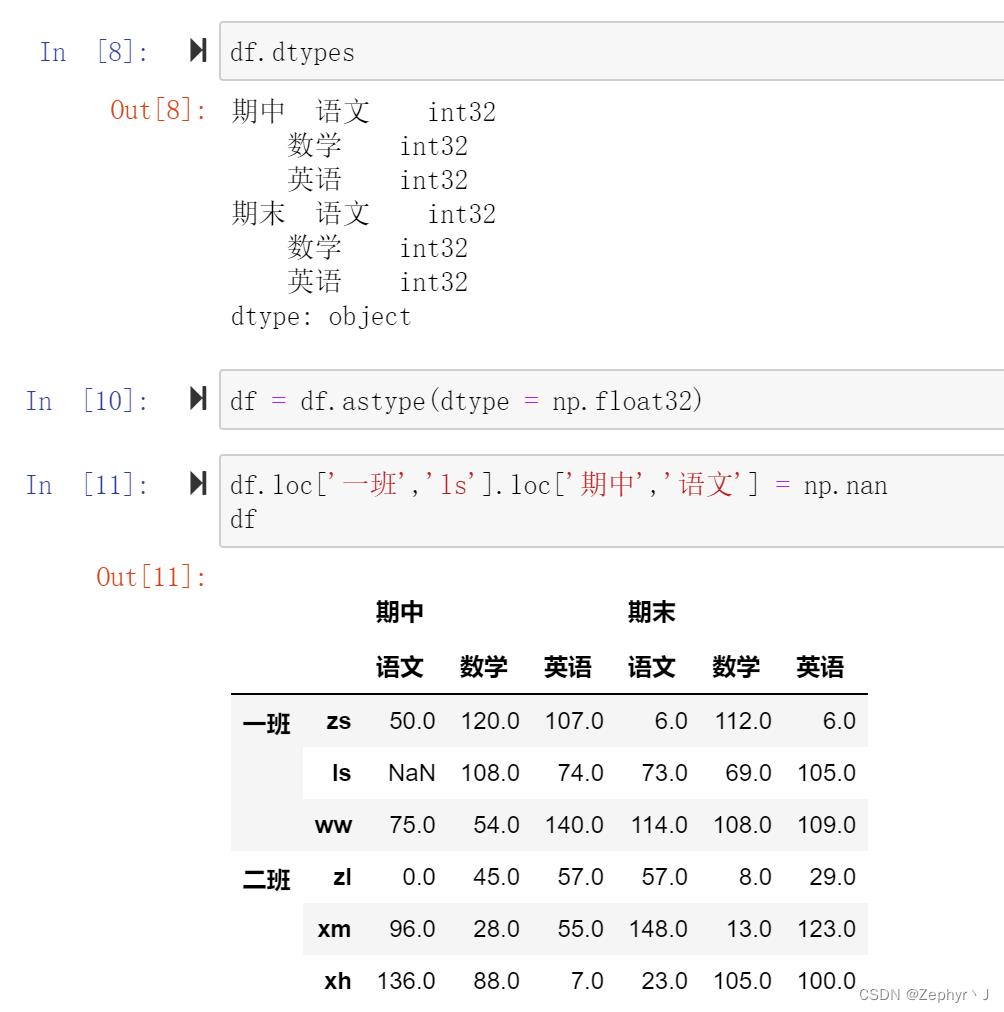
这种可以直接改
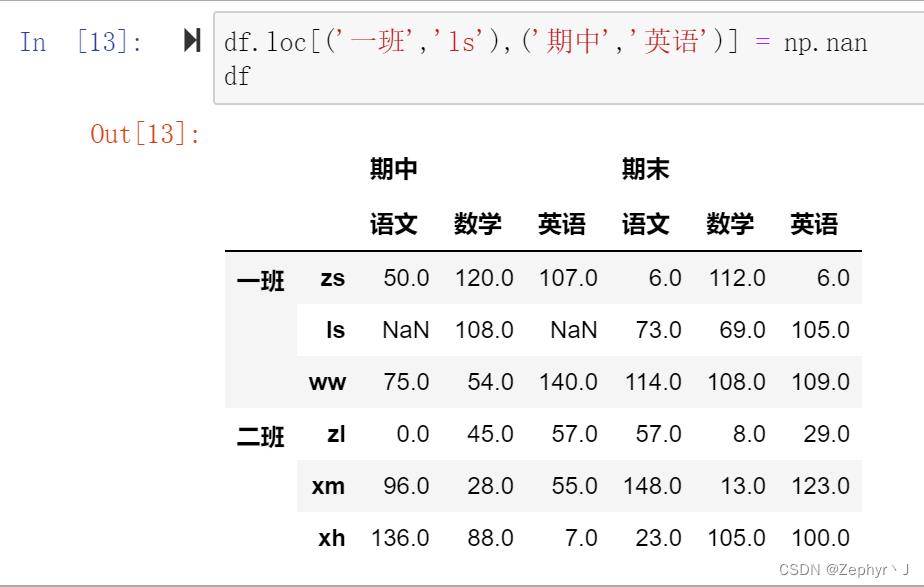
索引的堆(stack)
索引的堆指的是 多层索引中行索引和列索引的转换
行着的索引变成竖着是stack,反之是unstack
这里看到有返回值,说明不会修改原数据
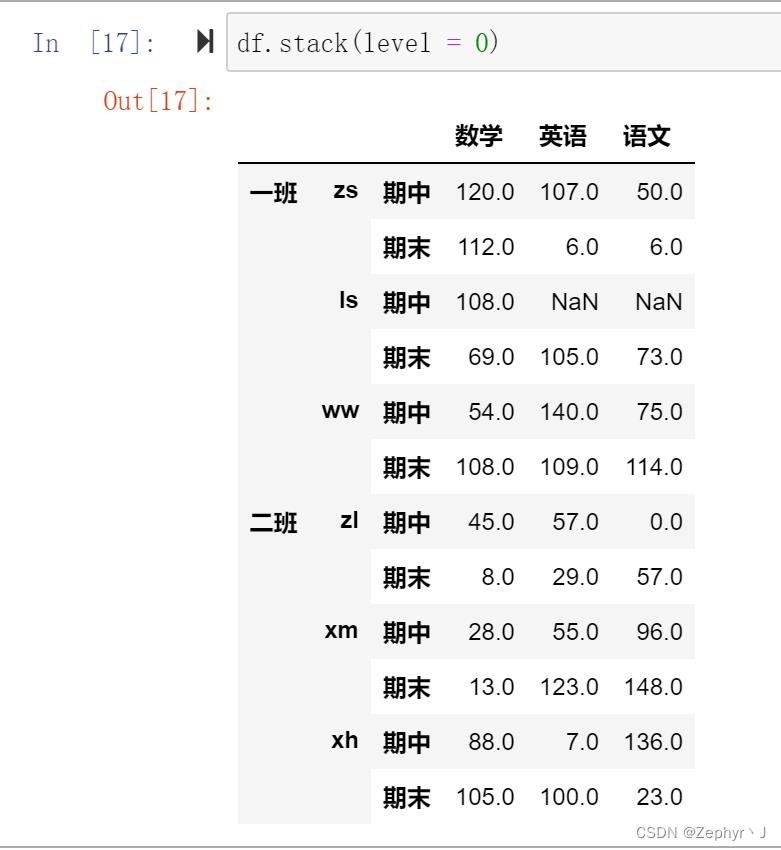
这里操作的是最里层,因为有个参数是level,默认是-1,就是最里层;
默认最外层是0,里面是1

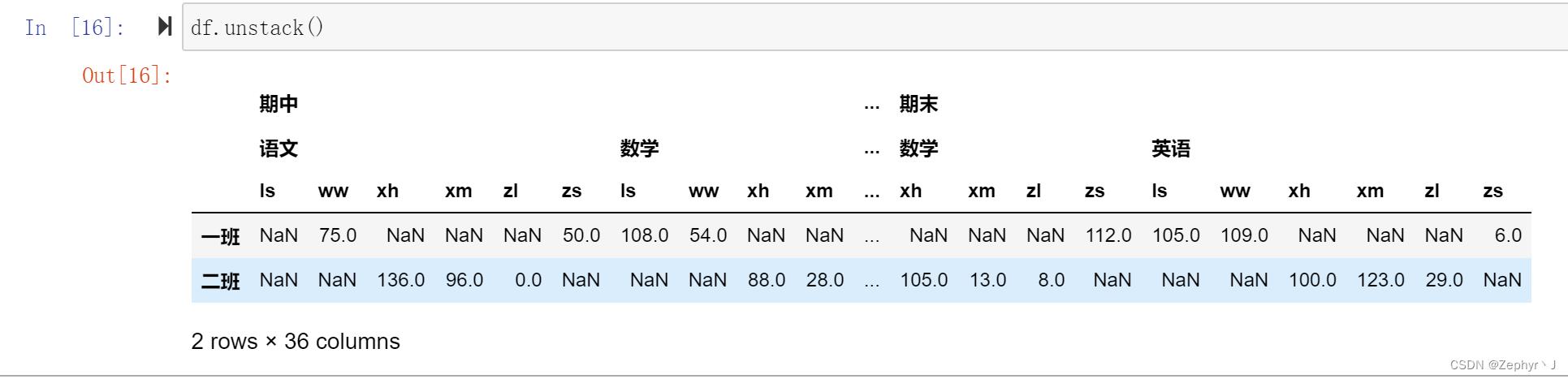
如果加上level参数,转换后总是出现在最里层

聚合

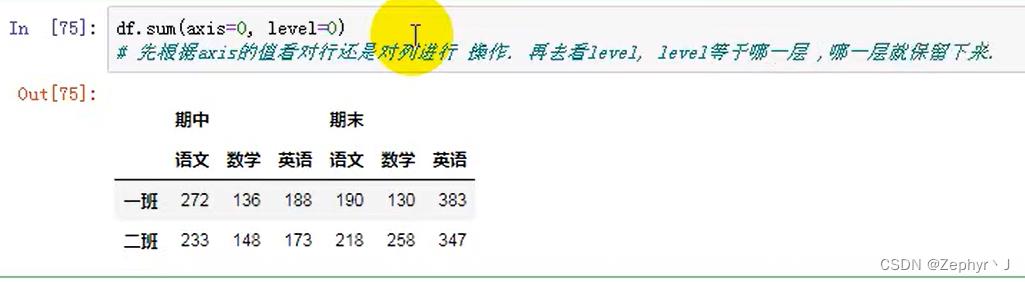
多层聚合
将日期转化为可以运算的数据类型
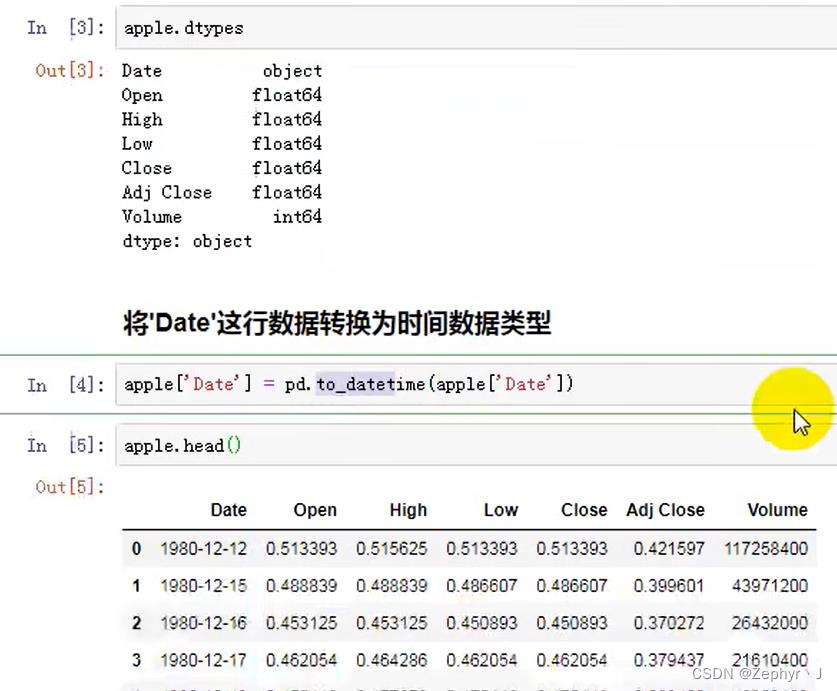

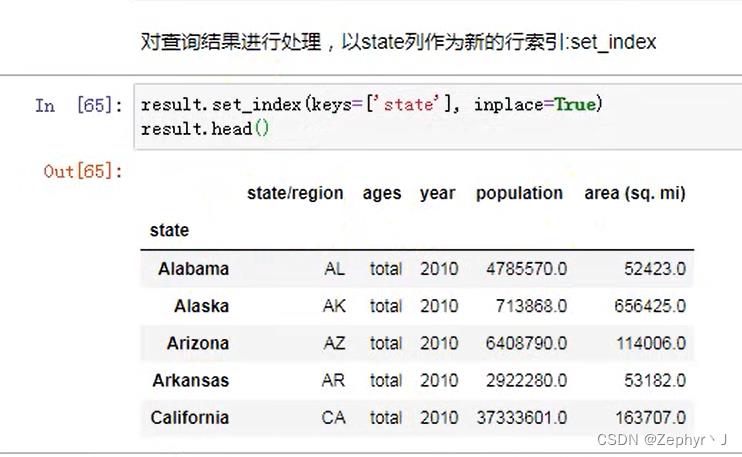
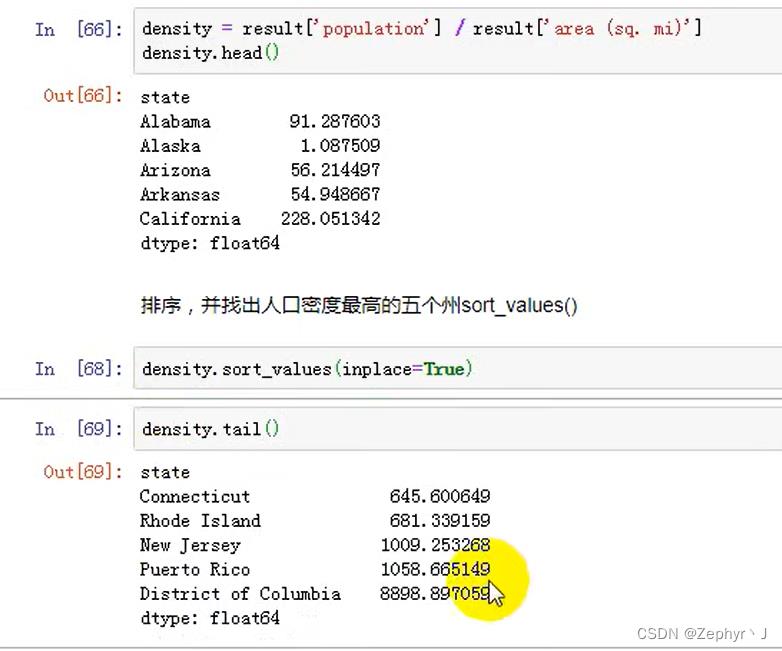
将date 设置为行索引,keys为要设置为索引的列
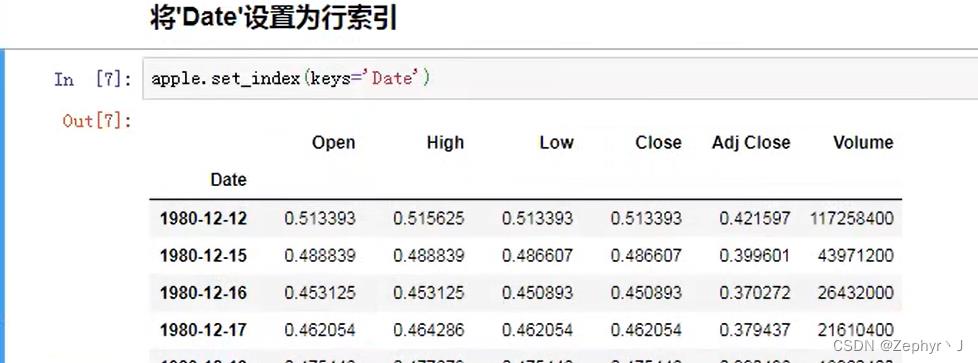
重新将索引变成数据
拼接(级联和合并)
pd.concat 和 df.append 是级联操作
pd.merge 是合并操作
生成一个df的函数


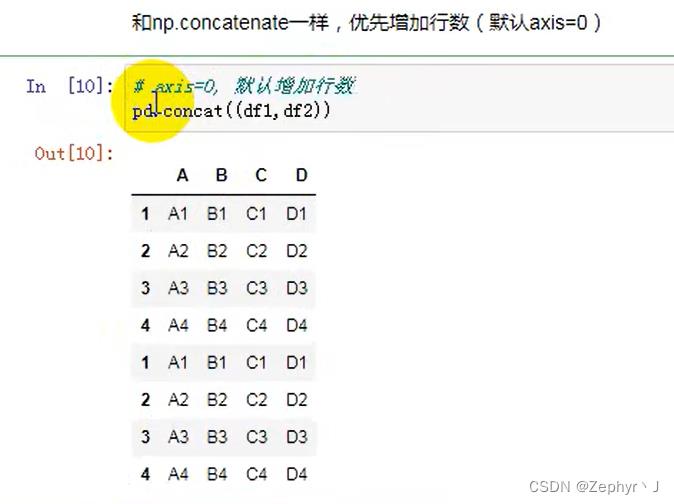
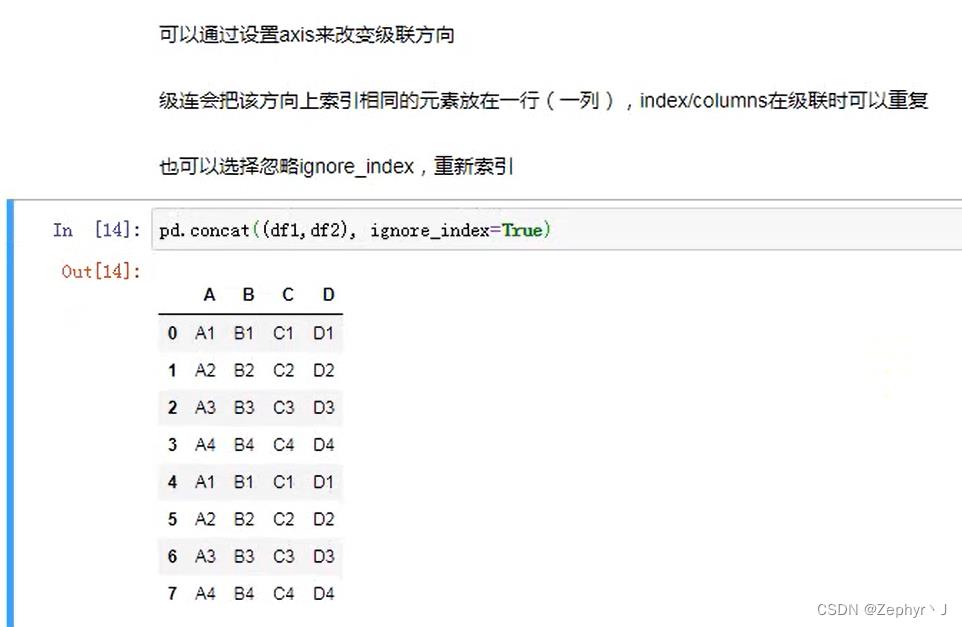
不匹配级联,匹配的级联,不匹配的索引,补nan


左连接

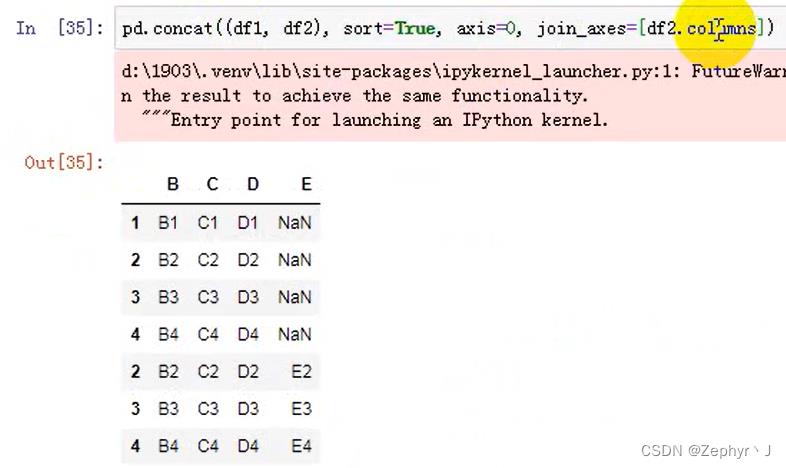
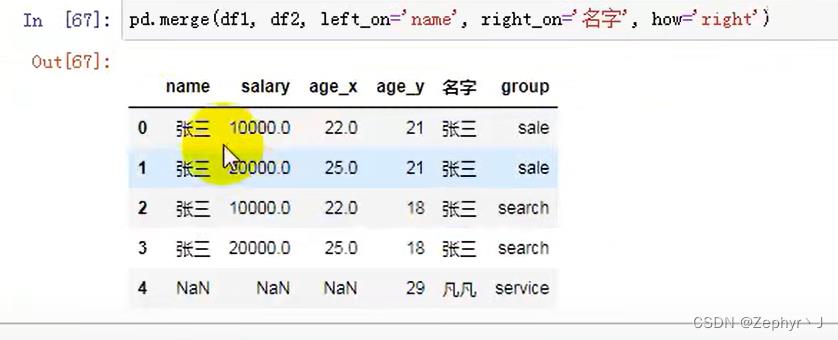
右连接,保留df2的列
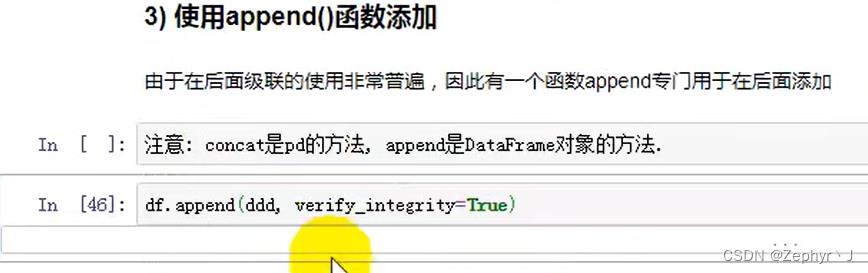
append
verify这个参数的意思是检查拼接的数据是否有重复,如果重复就报错了

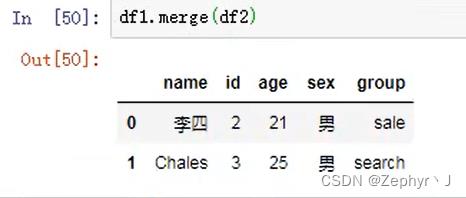
合并merge

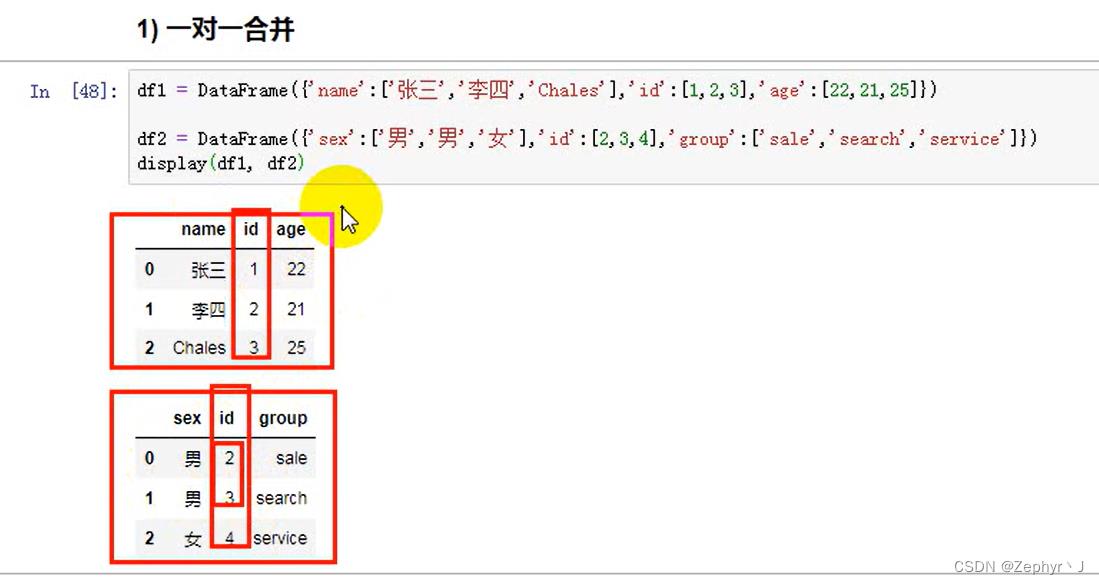
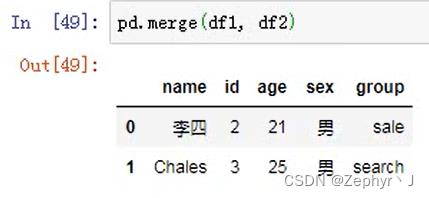
也可以用df调用
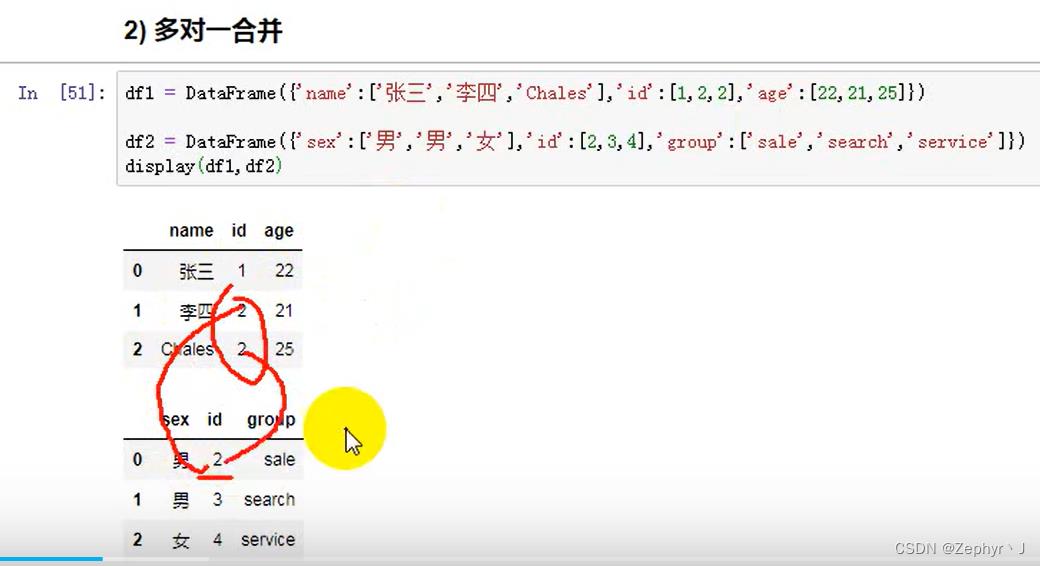
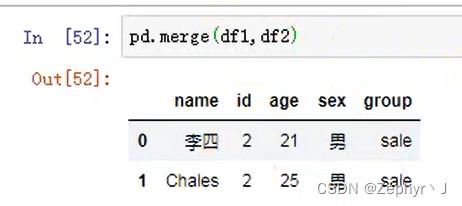
多对多,笛卡尔积

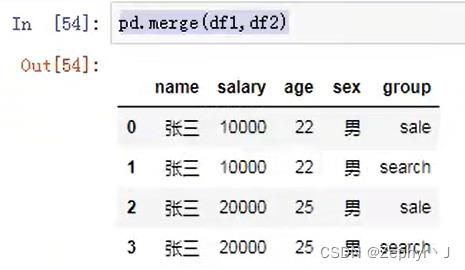
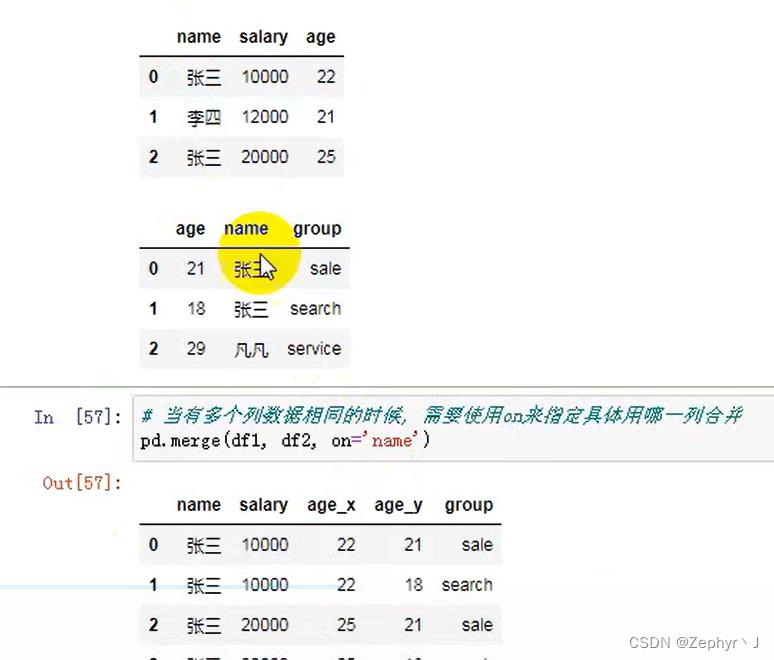
多个列相同,需要指定按照哪个列合并,并且另一个列合并以后会自动区分
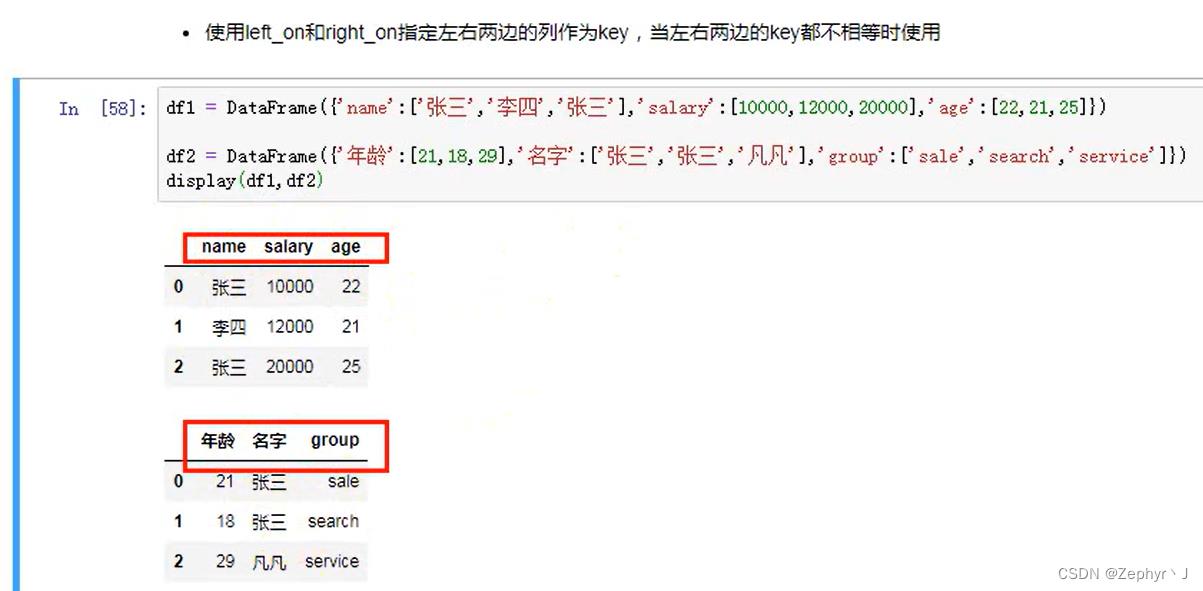
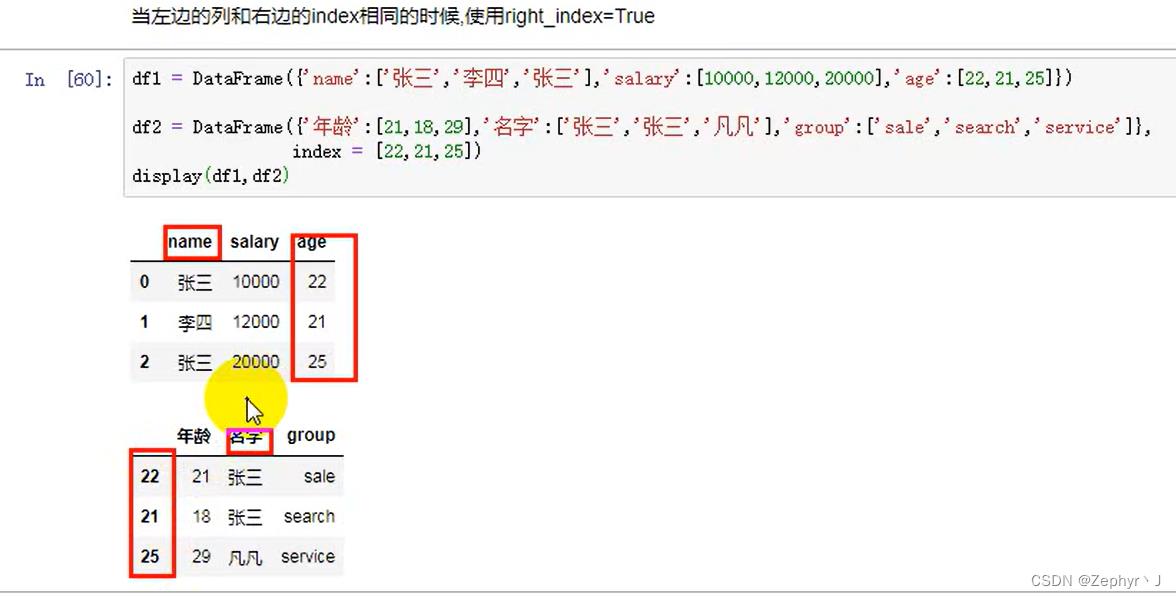
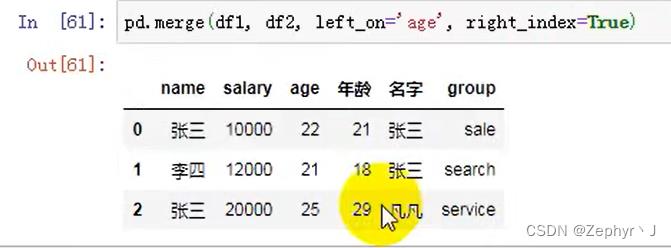
内合并,默认是内合并
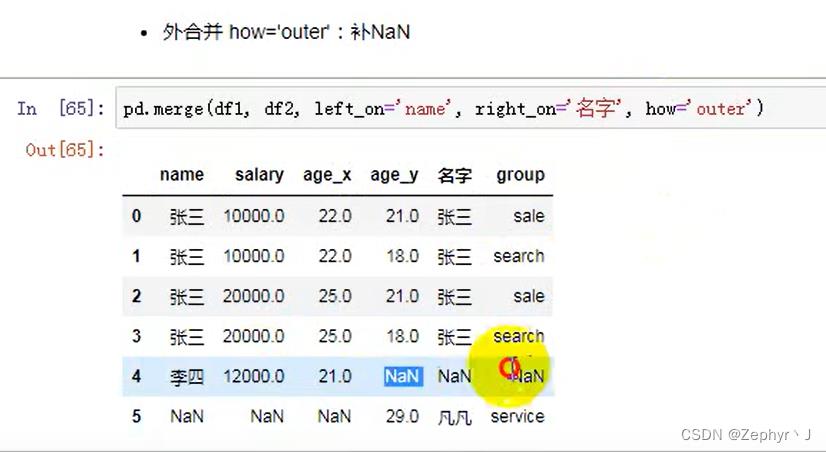
左右合并
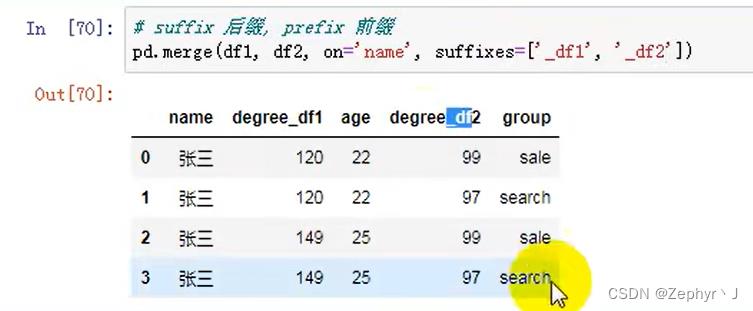

补充知识点
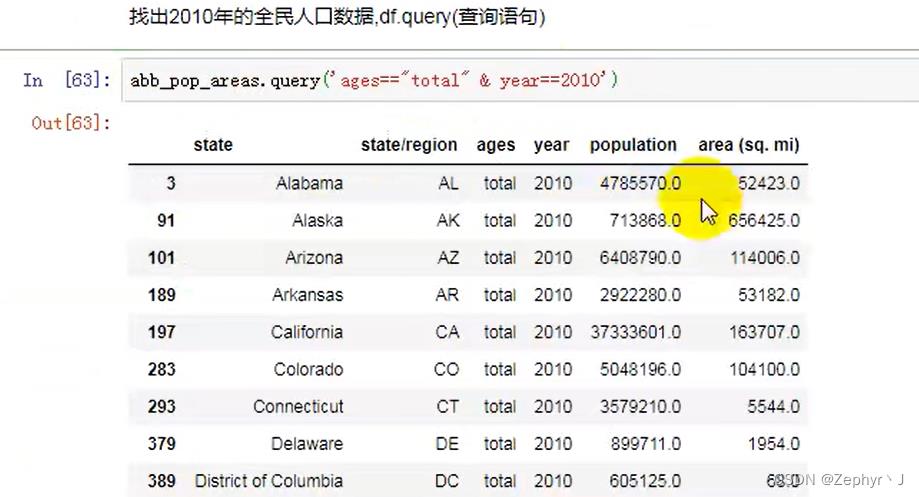
query 应该很常用
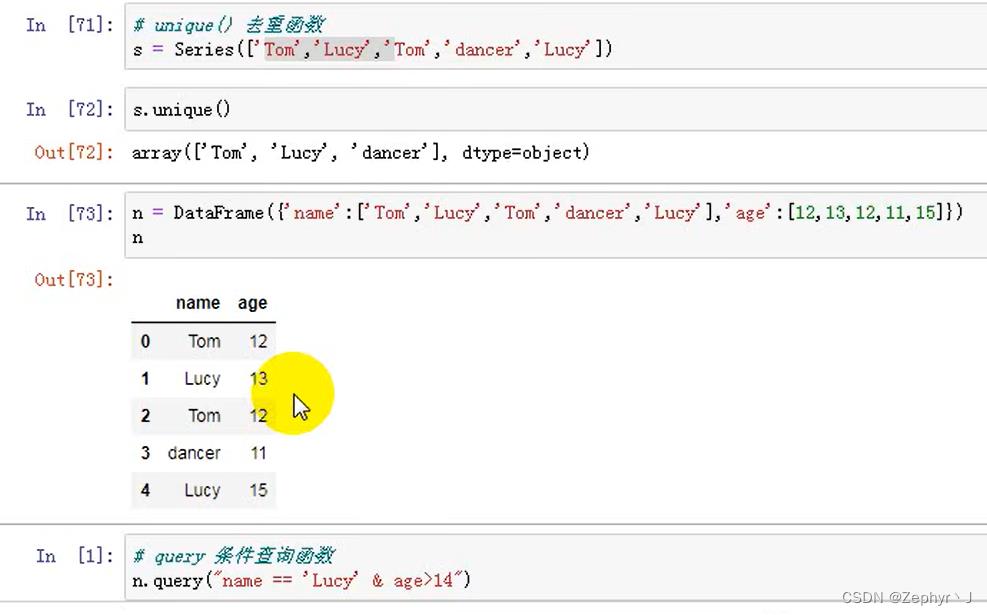
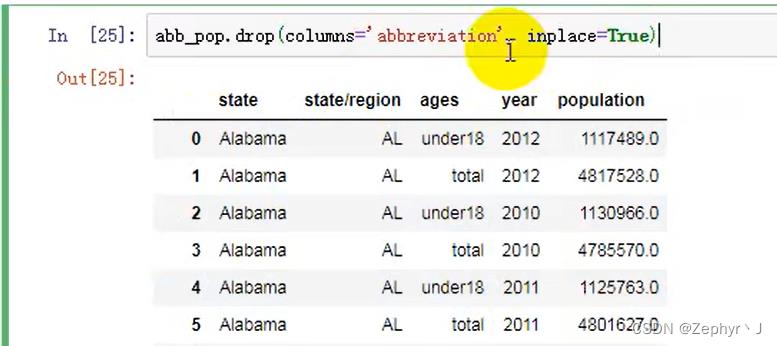
删除数据中的行或者列,drop()
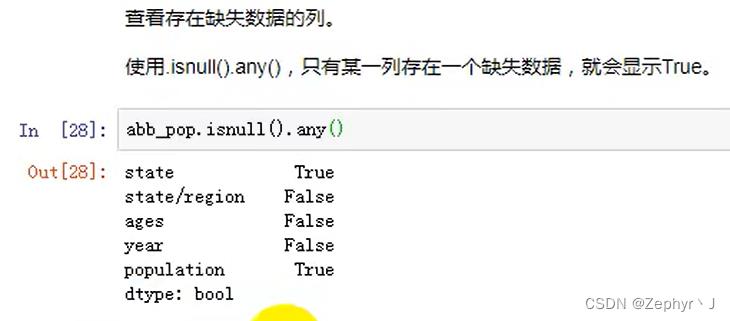
查看缺失数据的行(学会使用条件的这种写法)
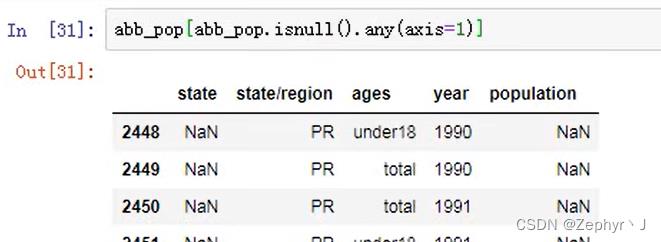

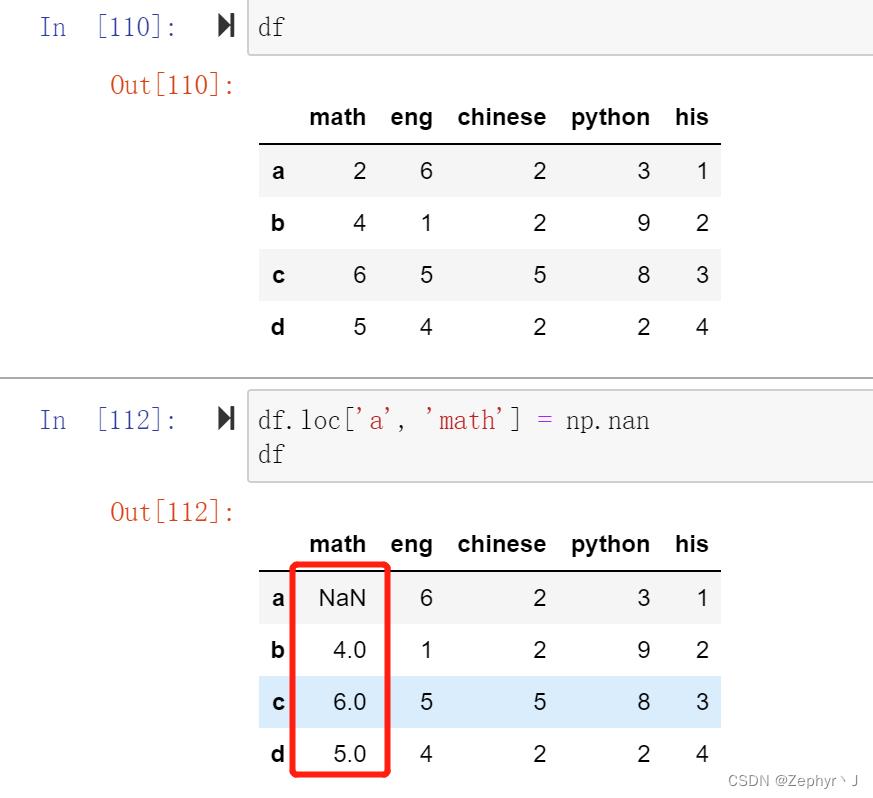
这个警告的意思是说是对数据框df的一个部分进行赋值,但是内存里没有直接生成这个部分,所以赋值失败

所以需要将这个部分创造出来,再进行赋值
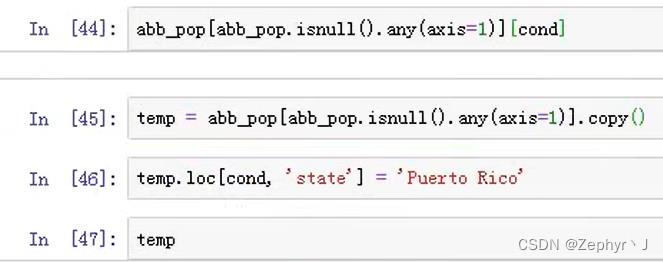
那么如何将赋值后的结果再重新给到数据框呢?

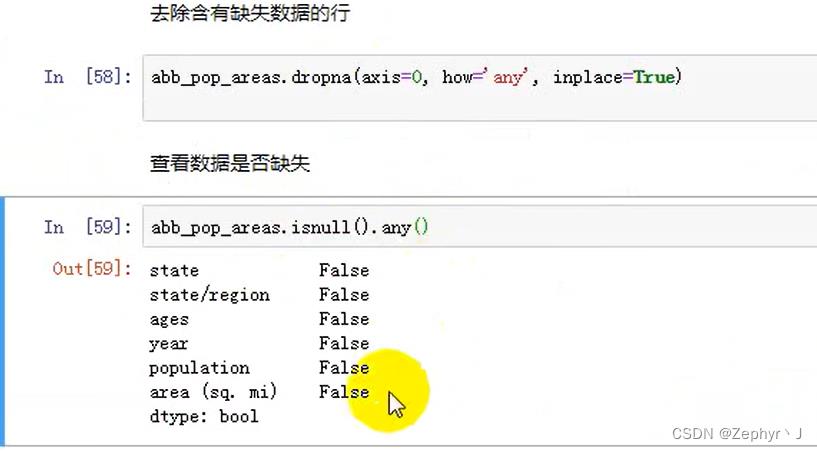
删除缺失数据
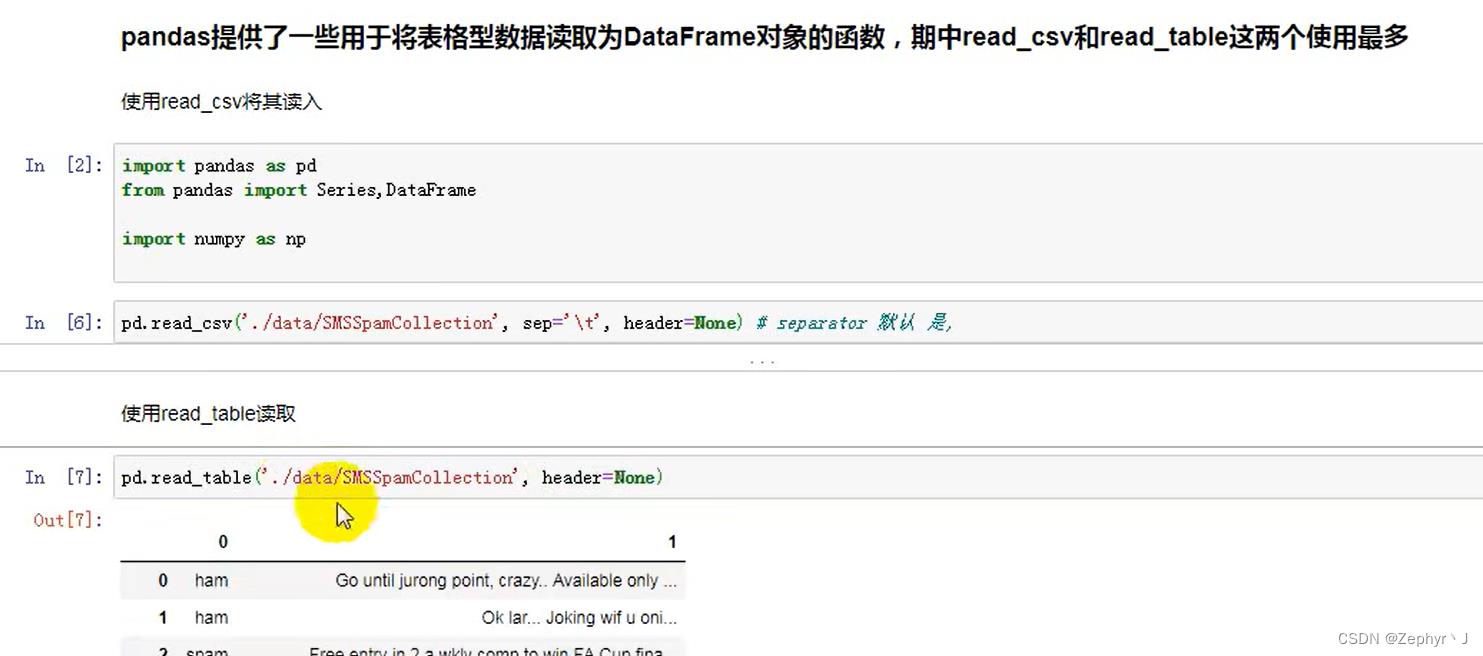
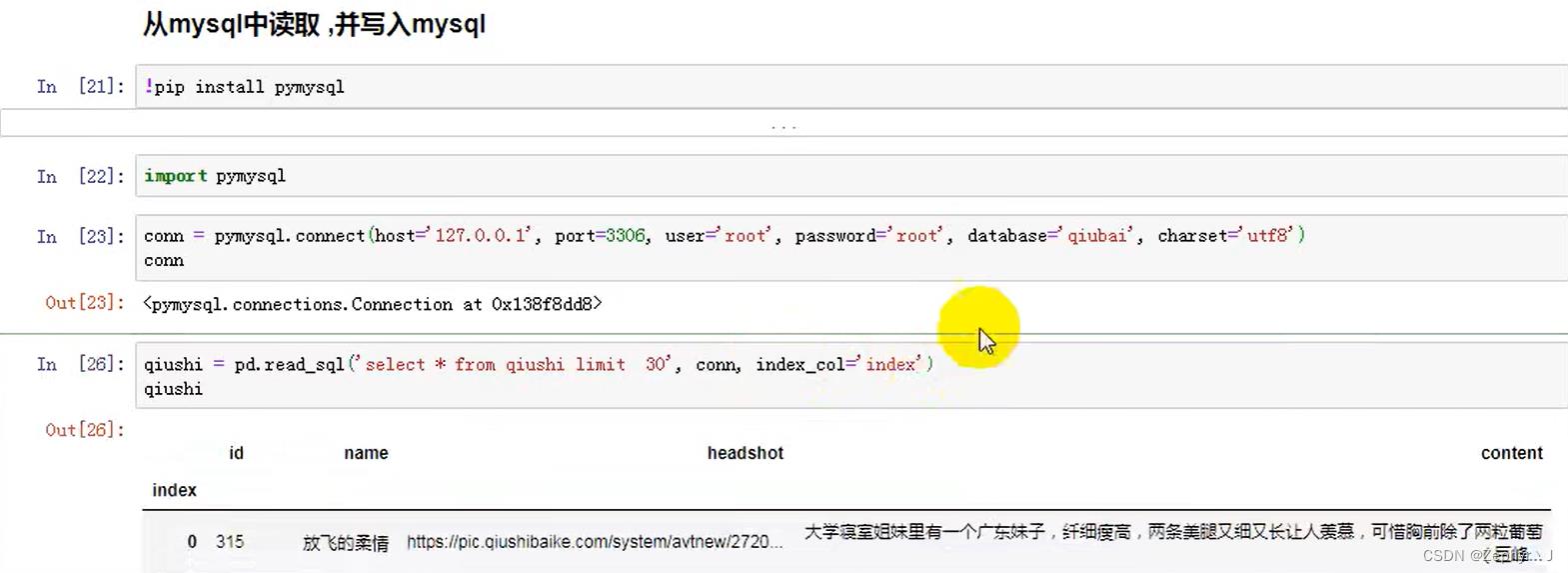
读取数据
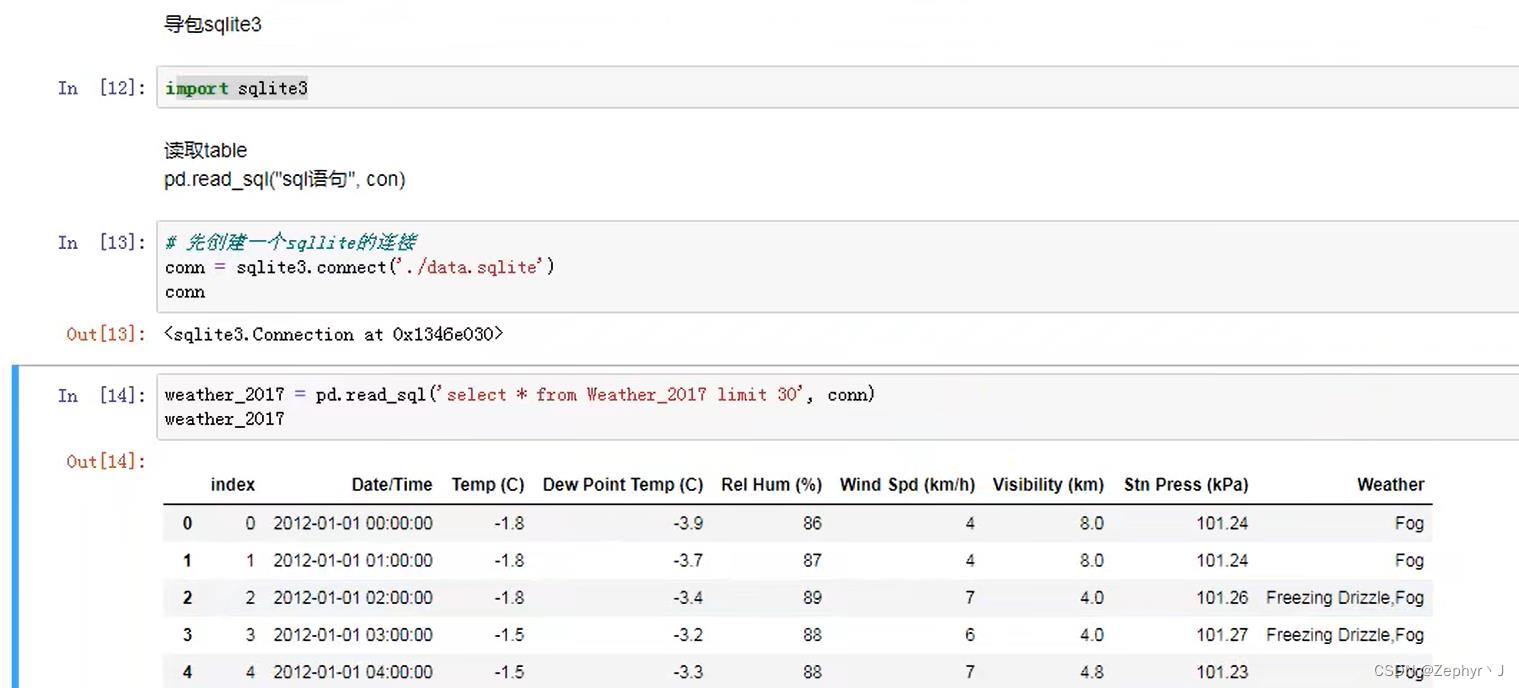
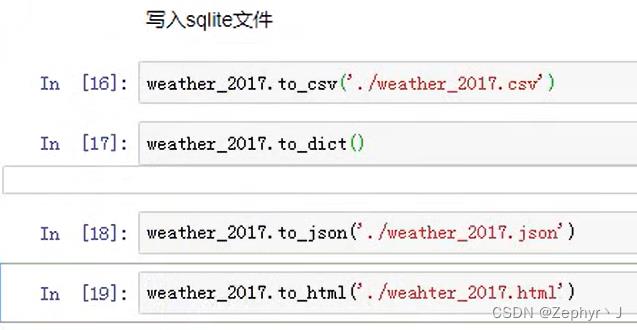

从mysql中读取
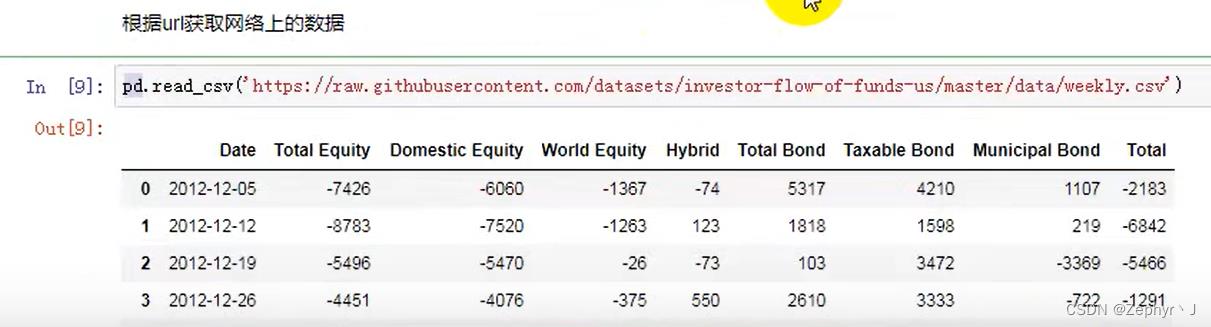
从url中读取
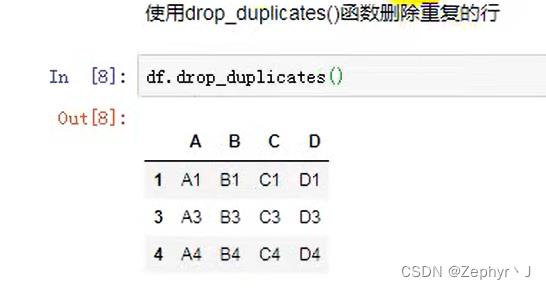
重复数据检测
df.duplicated()

df.drop_duplicates()
或者直接用条件,采用逻辑符号写

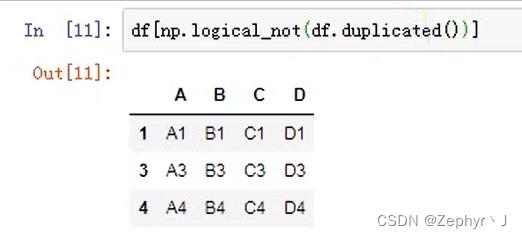
keep= ‘last’,从后往前看

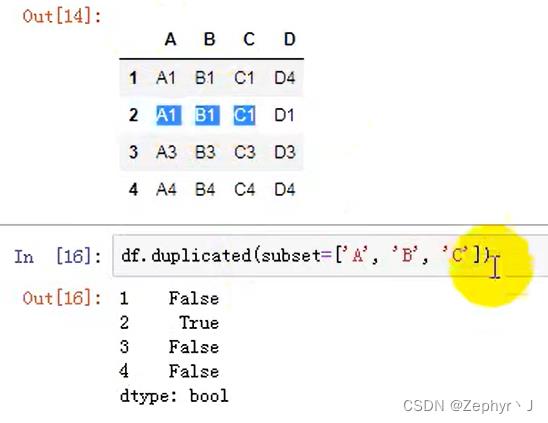
用subset定义在子集中查看
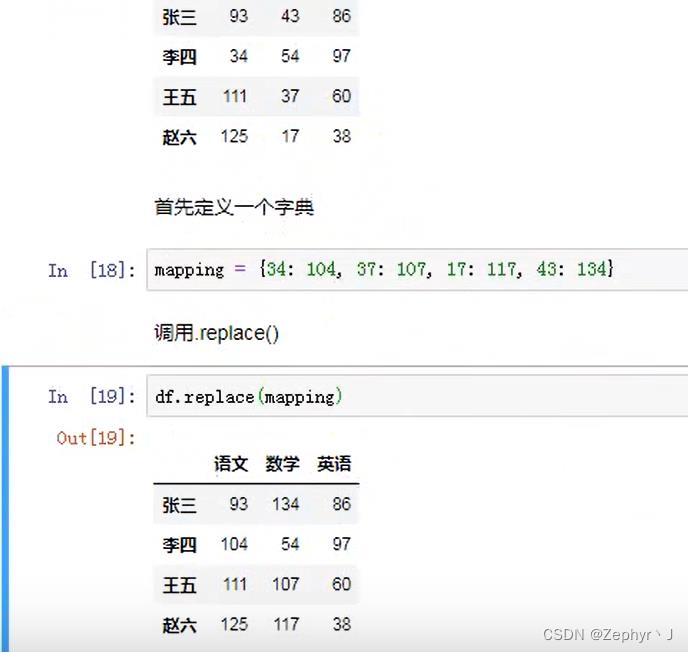
映射

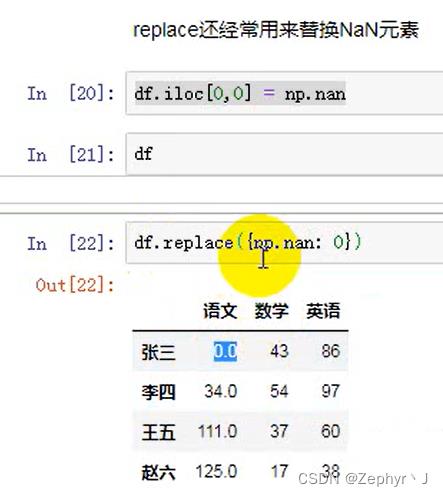
replace替换函数
map函数

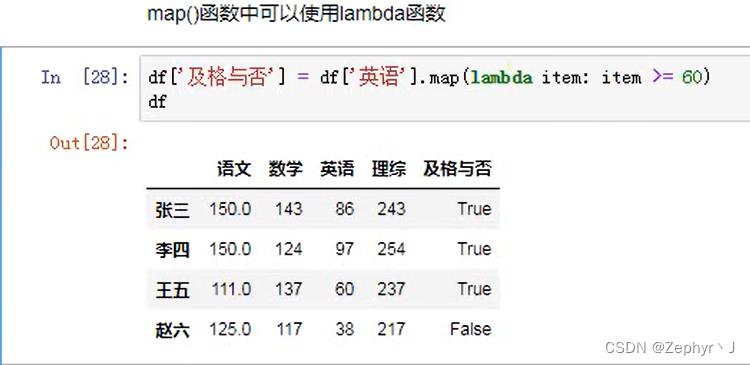
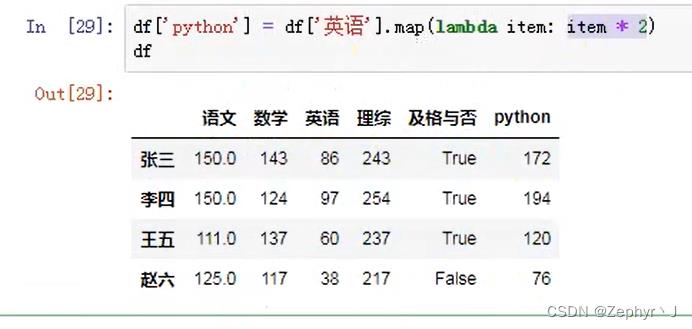
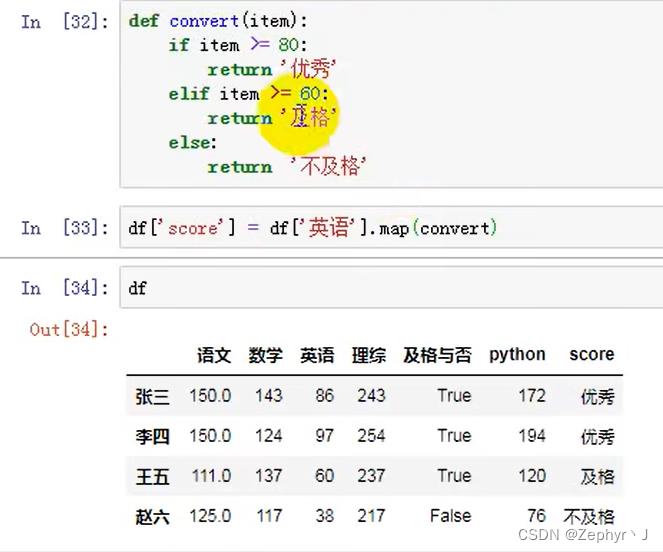
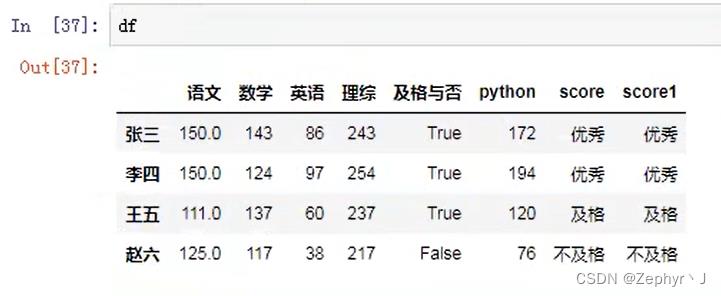
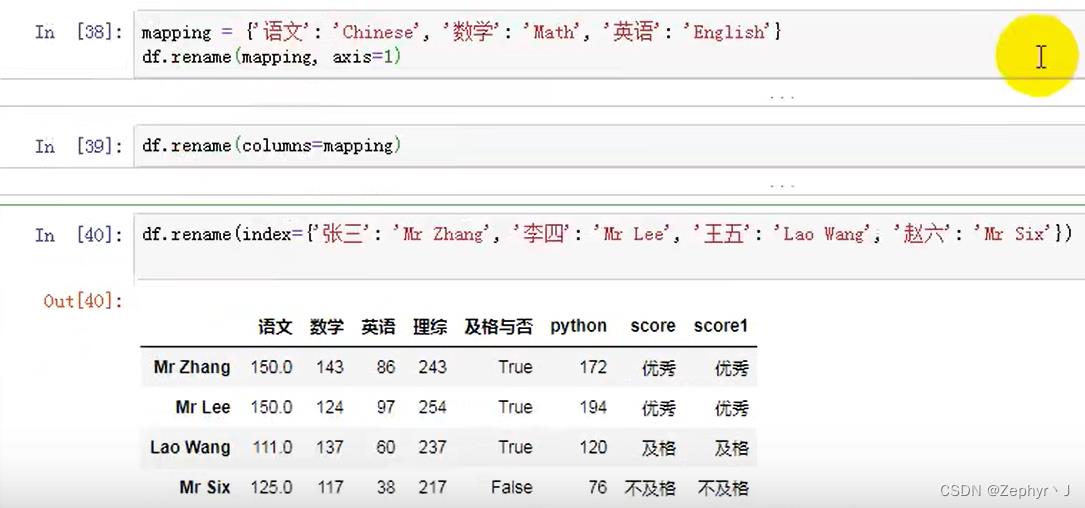
rename 替换索引
对于一个字典:
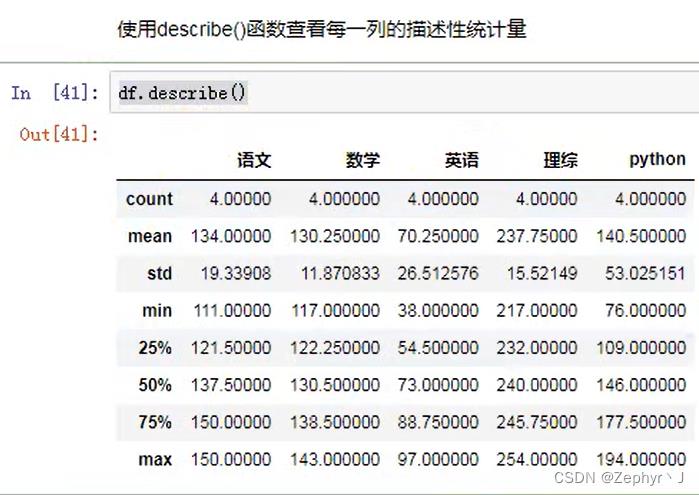
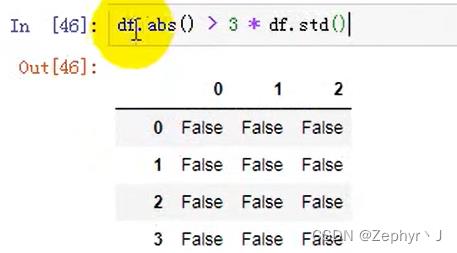
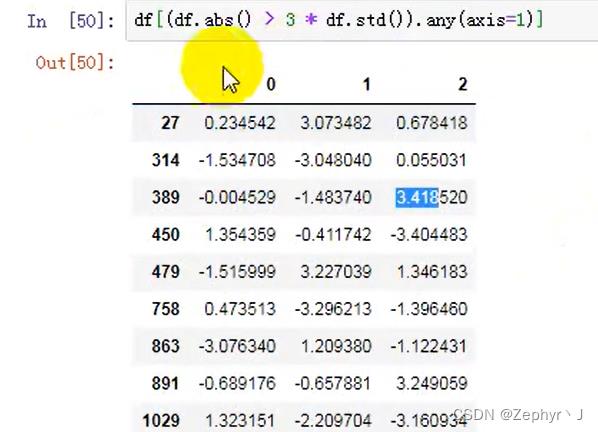
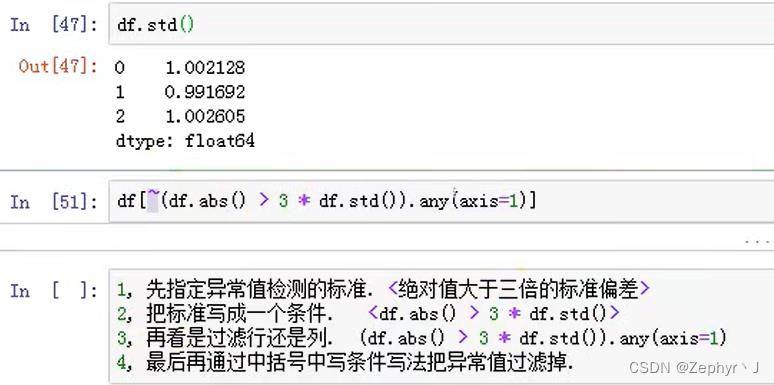
异常值判断

describe()
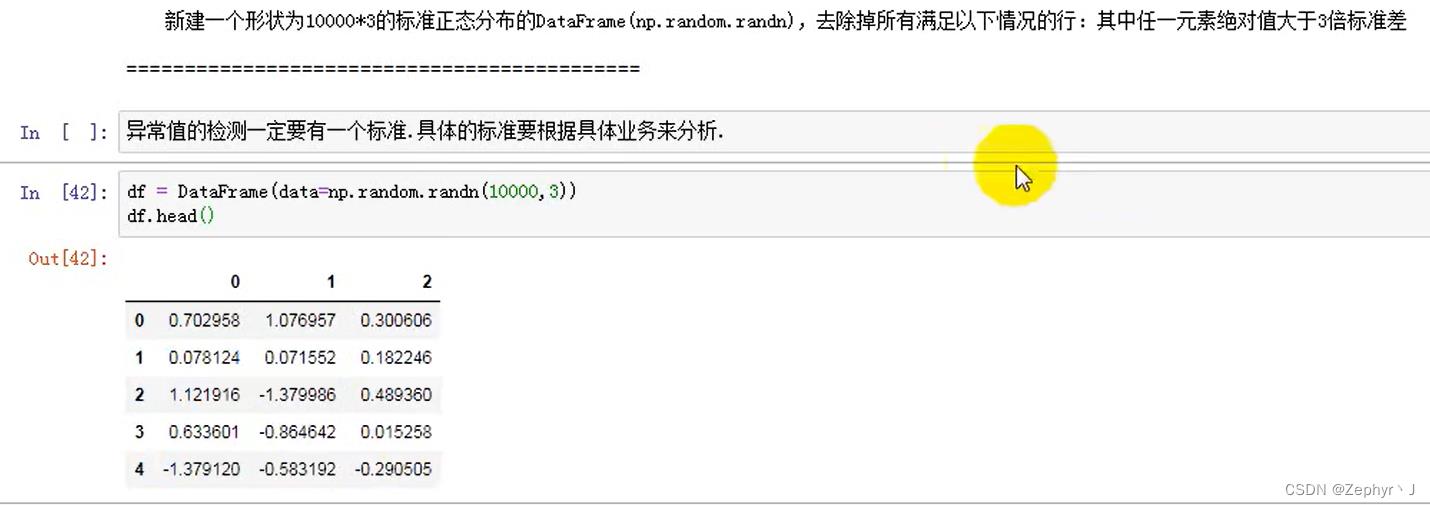
抽样
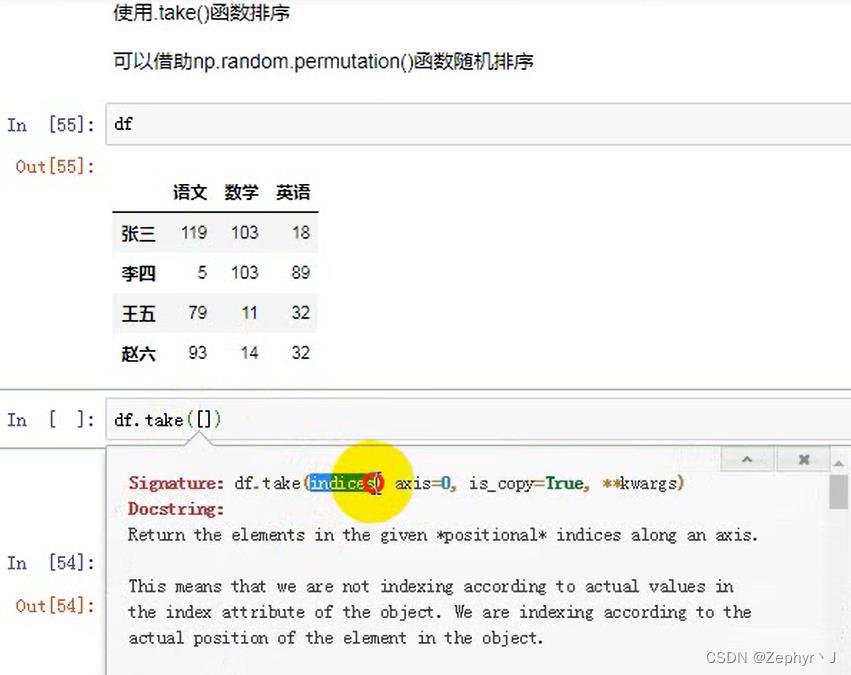
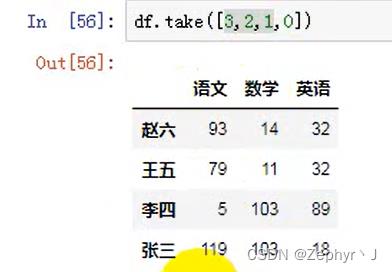
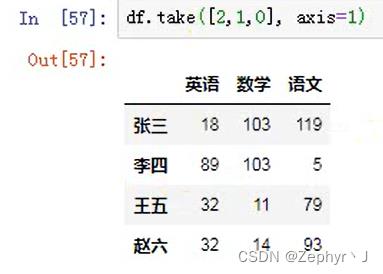
按照take中的顺序拿数据
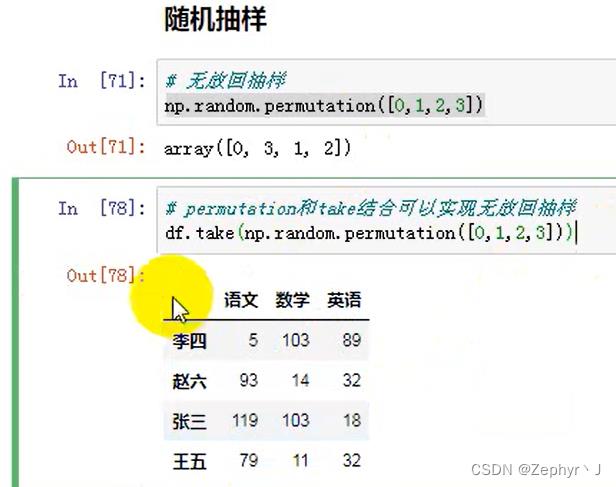
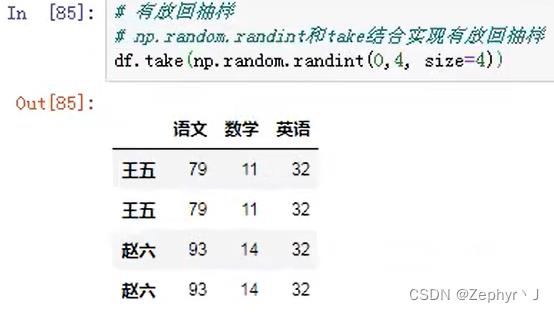
用随机数和take结合实现又放回抽样
分组聚合

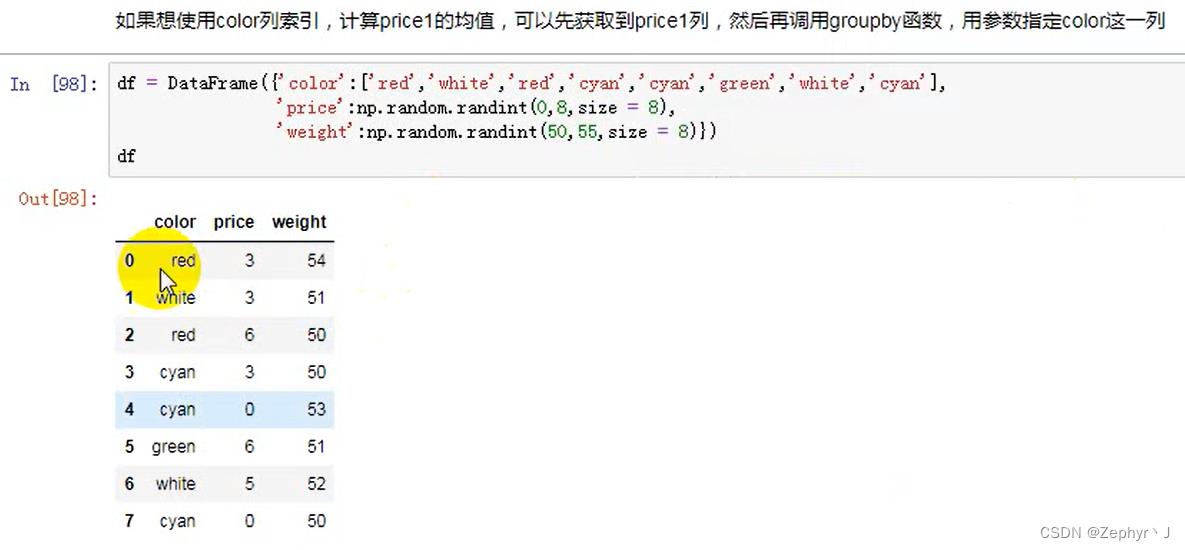
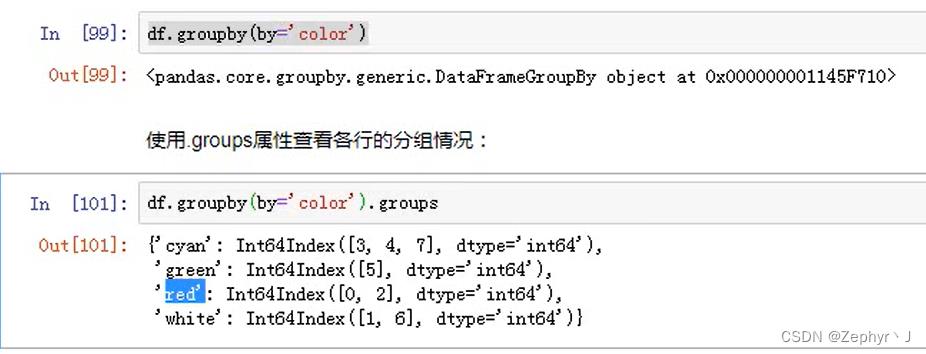

推荐先取值再聚合
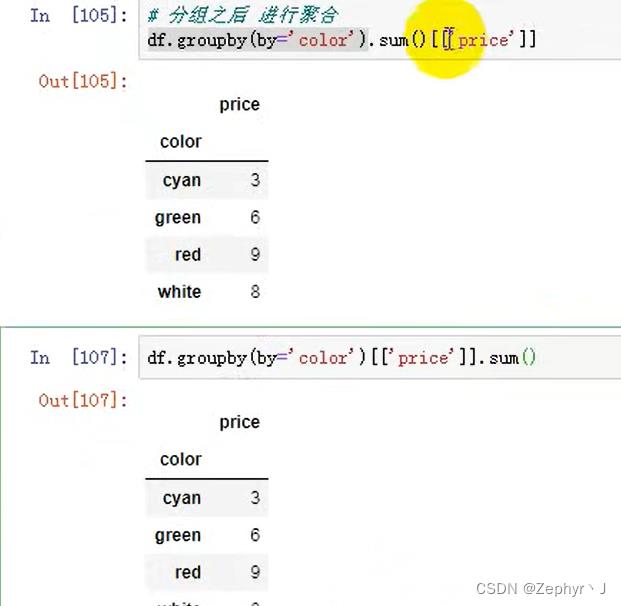
将和的那一列追加到原列表中
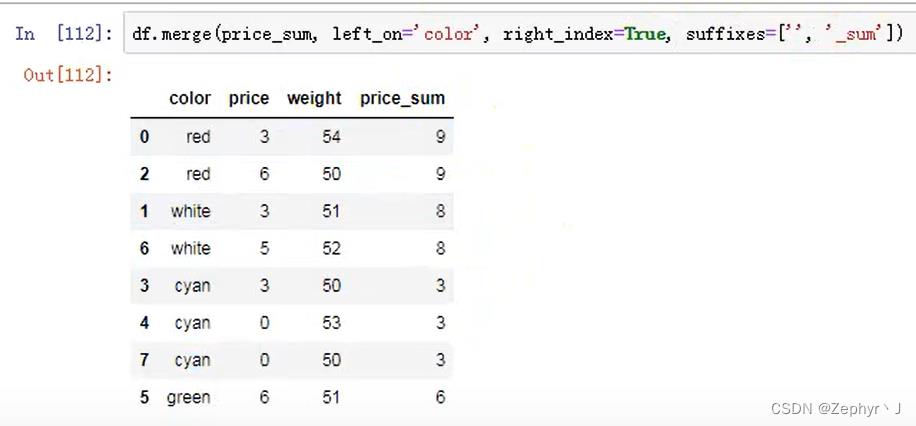
练习
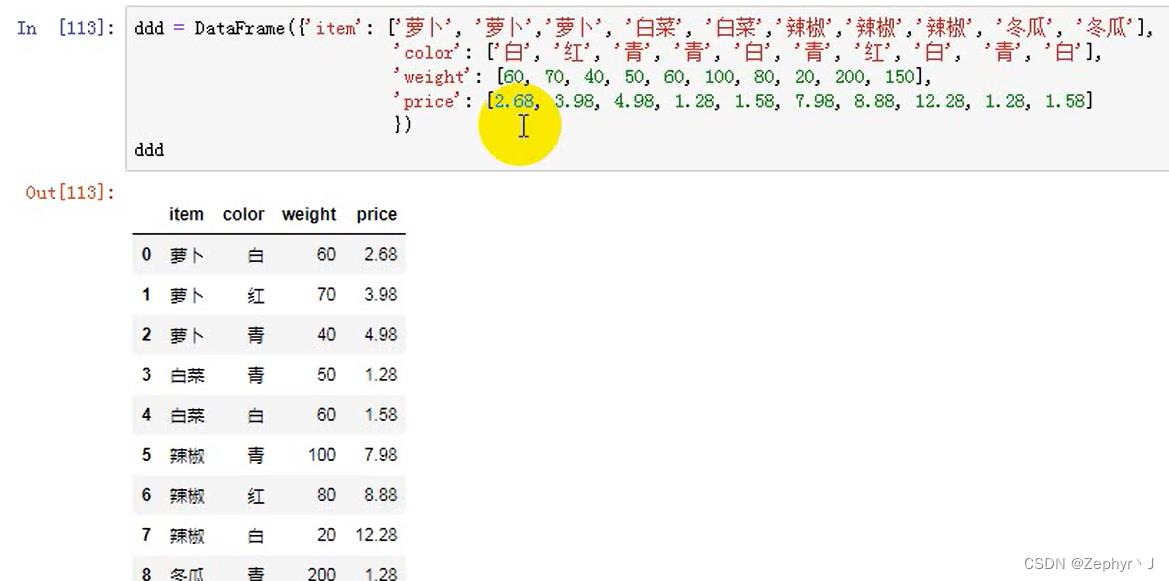
求白色的总价
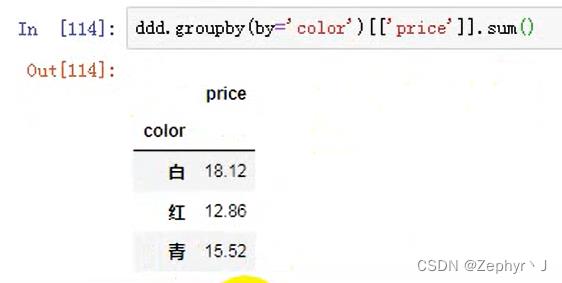
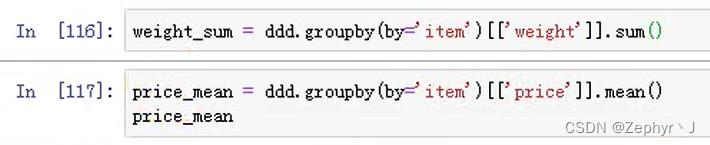
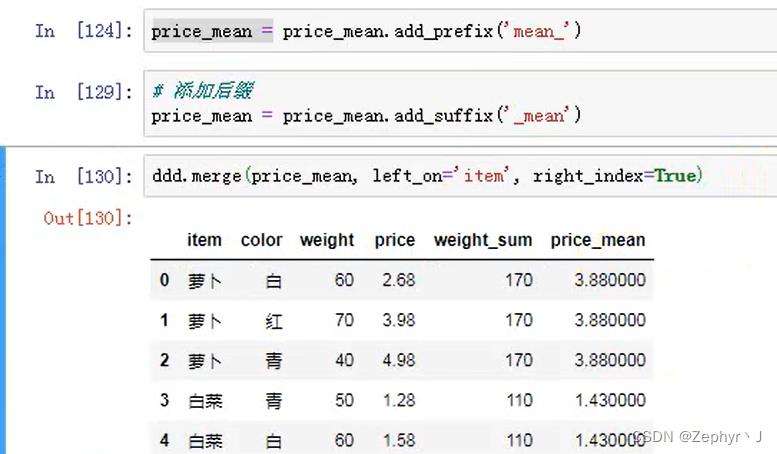
合并到原数据中
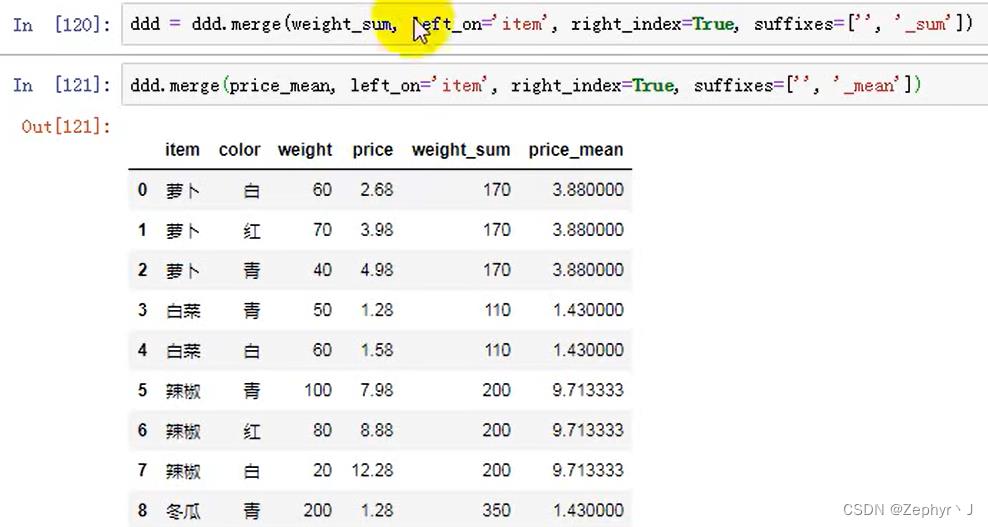
添加前后缀
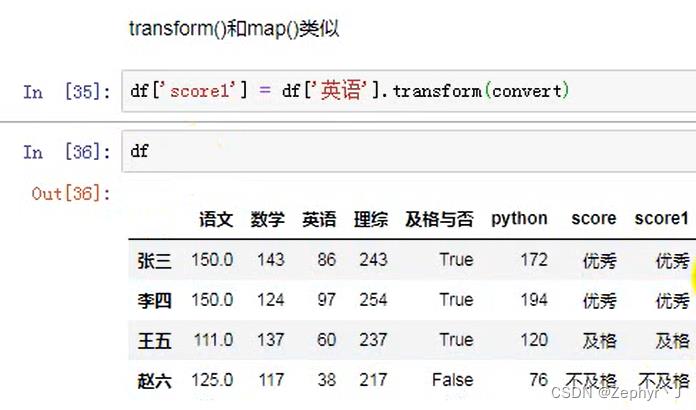
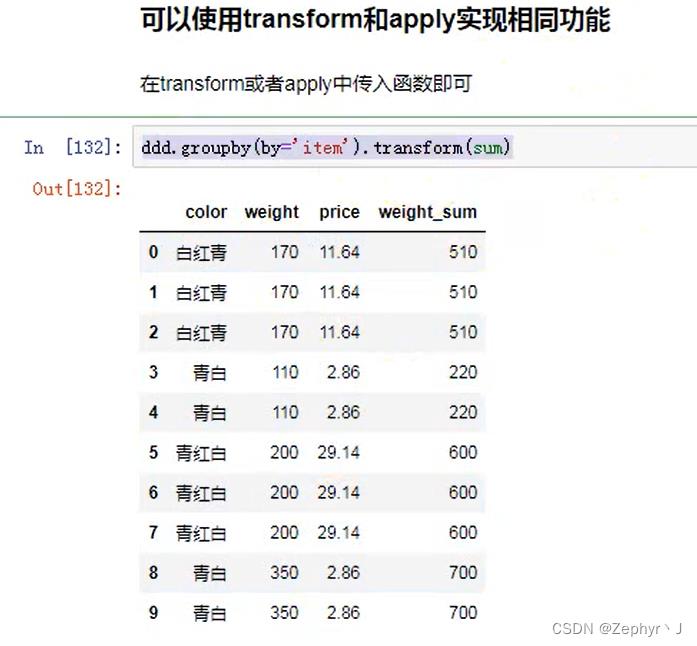
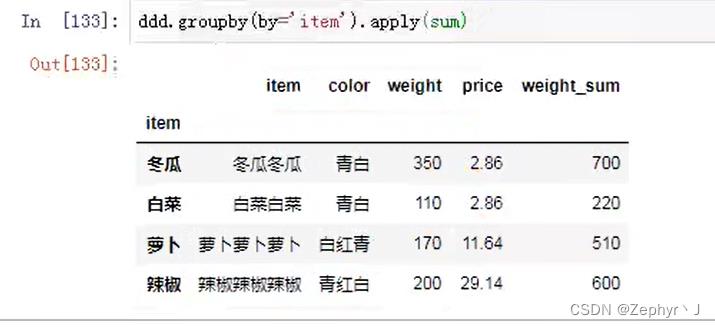
使用transform和apply实现
以上是关于Pandas学习2的主要内容,如果未能解决你的问题,请参考以下文章