中文关键词提取算法
Posted 狮子座明仔
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了中文关键词提取算法相关的知识,希望对你有一定的参考价值。
中文关键词提取算法
如何提取query或者文档的关键词?
一般有两种解决思路:
- 有监督方法,把关键词提取问题当做分类问题,文本分词后标记各词的重要性打分,然后挑出重要的topK个词;
- 无监督方法,使用TextRank、TFIDF等统计算法区分各词的term weight,然后按weight排序后挑出重要的topK个词。
有监督方法
有监督的关键词提取分两种做法。
特征工程方法
用一个树模型(如Xgboost)做分类模型,提取句子分词后各词的文本特征、统计特征、语言模型特征等,再把特征喂给分类模型,模型区分出各词的重要性得分,这样挑出topK个词就是提取的结果;分类模型的训练集是事先人工标注过的,每个词一个label。
特征工程可以参考:https://github.com/shibing624/pke_zh
- 文本特征:包括Query长度、Term长度,Term在Query中的偏移量,term词性、长度信息、term数目、位置信息、句法依存tag、是否数字、是否英文、是否停用词、是否专名实体、是否重要行业词、embedding模长、删词差异度、以及短语生成树得到term权重等
- 统计特征:包括PMI、IDF、TextRank值、前后词互信息、左右邻熵、独立检索占比(term单独作为query的qv/所有包含term的query的qv和)、统计概率、idf变种iqf
- 语言模型特征:整个query的语言模型概率 / 去掉该Term后的Query的语言模型概率
训练样本形如:
邪御天娇 免费 阅读,3 1 1
重要度label共分4级:
- Super important:3级,主要包括POI核心词,比如“方特、欢乐谷”
- Required:2级,包括行政区词、品类词等,比如“北京 温泉”中“北京”和“温泉”都很重要
- Important:1级,包括品类词、门票等,比如“顺景 温泉”中“温泉”相对没有那么重要,用户搜“顺景”大部分都是温泉的需求
- Unimportant:0级,包括语气词、代词、泛需求词、停用词等
深度学习方法
比较朴素的思路是直接用深度模型做分类任务,取代人工提取特征,模型端到端产出分类预测label。
此处的深度模型可以是TextCNN、Fasttext、Transformer等,也可以是BERT预训练模型,适用于分类任务的模型都行。分类任务可以参考:https://github.com/shibing624/pytextclassifier
还有一种方法是Seq2Seq生成模型,基于query生成式给出关键词结果,或者生成句子摘要,代表性的模型有T5、Bart、Seq2Seq等。生成任务可以参考:https://github.com/shibing624/textgen
以上方法的实现可以参考我写的开源项目,此处不再赘述,本文重点介绍无监督方法。
无监督方法
无监督的关键词提取算法有:
- 统计方法
- TFIDF
- YAKE
- 图方法
- TextRank
- SingleRank
- TopicRank
- MultipartiteRank
- PositionRank
- 语义模型
- KeyBert
经验来看,TFIDF是很强的baseline,有较强普适性,基本能应付大部分关键词抽取场景,简单有效,速度很快。TextRank虽然算法复杂些,但其应用效果不比TFIDF强,而且涉及网络构建和随机游走迭代,效率极低。
TFIDF
TF-IDF是一种很简单但却很有效的方法,计算文本中的每个term会考虑两个因素。一是term本身在文档中的词频TF,另一个是倒文本频率(Inverse Document Frequency)IDF,这个指标衡量的是有多少文本包含了该term。IDF主要用来惩罚那些在很多文本中都有出现的term,往往这些term都是一些无关紧要的停用词等。
TFIDF整个核心思想就是,term在一个文档的重要程度取决于该term在该文档的频率和在其它文档的出现的次数。意思是term在该文档出现了多次,而在其他文档不常出现,那么该term很能代表该文档的含义。这种思想也是TFIDF经常用来做文本分类任务的特征提取的原因。
小结
- 优点:能够识别出独特性强的词语
- 缺点:不能识别复杂的词语关系,并且有时候会识别出不相关的关键词。效率较高,因为算法简单且只需要计算词频和逆文档频率。
YAKE
paper:A Text Feature Based Automatic Keyword Extraction Method for Single Documents
YAKE(Yet Another Keyword Extractor)是一种无监督的关键词提取算法,基于词语分散性的关键词提取算法。特征提取主要考虑五个因素(去除停用词后):
- 是否大写:英文大写字母的term(除了每句话的开头单词)的重要程度比那些小写字母的term重要程度要大
- 词的位置:文本越开头的部分句子的重要程度比后面的句子重要程度要大
- 词频:一个词在文本中出现的频率越大,相对来说越重要,同时为了避免长文本词频过高的问题,会进行归一化操作
- 上下文关系:一个词与越多不相同的词共现,该词的重要程度越低
- 词在句中频率:一个词在越多句子中出现,相对更重要
中文只用后4个指标来计算候选词的得分,从而筛选TopK关键词。
小结
- 优点:效率高,不需要考虑语义关系和词语位置,因此适用于大量文档的关键词提取
- 缺点:语义关系和词语位置的考虑不足,因此可能会提取到不够重要的关键词
TextRank
PageRank算法
PageRank算法通过计算网页链接的数量和质量来粗略估计网页的重要性,算法创立之初即应用在谷歌的搜索引擎中,对网页进行排名。
PageRank算法的核心思想如下:
- 链接数量:如果一个网页被越多的其他网页链接,说明这个网页越重要,即该网页的PR值(PageRank值)会相对较高;
- 链接质量:如果一个网页被一个越高权值的网页链接,也能表明这个网页越重要,即一个PR值很高的网页链接到一个其他网页,那么被链接到的网页的PR值会相应地因此而提高。
TextRank算法
paper:TextRank: Bringing Order into Texts
TextRank算法是一种基于图的用于关键词抽取和文档摘要的排序算法,由谷歌的网页重要性排序算法PageRank算法改进而来,它利用一篇文档内部的词语间的共现信息(语义)便可以抽取关键词,它能够从一个给定的文本中抽取出该文本的关键词、关键词组,并使用抽取式的自动文摘方法抽取出该文本的关键句。
TextRank算法的基本思想是将文档看作一个词的网络,该网络中的链接表示词与词之间的语义关系。
TextRank算法主要包括:关键词抽取、关键短语抽取、关键句抽取。
-
关键词抽取(keyword extraction)
关键词抽取是指从文本中抽取几个能描述该文本的词的过程。
对关键词抽取而言,用于构建顶点集的文本单元可以是句子中的一个或多个字(词);根据这些字之间的关系(比如:在一个框中同时出现)构建边。根据任务的需要,可以使用语法过滤器(syntactic filters)对顶点集进行优化。语法过滤器的主要作用是将某一类或者某几类词性(如名词、形容词)的词过滤出来作为顶点集。 -
关键短语抽取(keyphrase extration)
关键词抽取结束后,我们可以得到的N个关键词,在原始文本中相邻的关键词构成关键短语,然后分析关键词是否存在相邻的情况,最后确定哪些是关键短语。 -
关键句抽取(sentence extraction)
句子抽取任务主要针对的是自动摘要这个场景,将每一个sentence作为一个顶点,根据两个句子之间的内容重复程度来计算他们之间的“相似度”,以这个相似度作为联系,由于不同句子之间相似度大小不一致,在这个场景下构建的是以相似度大小作为edge权重的有权图。
小结
- 优点:能够识别出复杂的词语关系
- 缺点:复杂度较高,需要调整许多参数,而且可能误识别关键词。效率一般,因为需要建立关系图并进行多次遍历。
SingleRank
paper:CollabRank: Towards a Collaborative Approach to Single-Document Keyphrase Extraction
SingleRank是PageRank的变体,主要有两个变化:
- 不同于PageRank,每个边都有相同的分值,SingleRank会根据窗口大小词之间的距离计算不同的边权重
- 与TextRank不同的是,SingleRank保留所有的unigrams词,然后类似TextRank方法,滑动窗口方式计算更高的n-grams词,背后的原理是,两个分值较低的unigram,有可能产生较高分值的bi-gram。
小结
- 优点:实现简单
- 缺点:词频不能反映词的重要性,可能识别出不相关的关键词。效率较高
TopicRank
paper:TopicRank: Graph-Based Topic Ranking for Keyphrase Extraction
TopicRank把主题当做相似关键短语的簇,这些topics会根据在文档的重要性进行排序,然后选取topK个最相关的topics,每个topic选择一个最重要的关键短语来代表文档的核心关键词。
TopicRank算法的步骤如下:
- 主题识别:主要抽取名词短语来表征文档的主题,短语中有超过25%重合的单词就考虑为相似短语,用 Hierarchical Agglomerative Clustering (HAC) algorithm进行了聚类相似的短语。
- 图构建:这里的图中的节点是topics,边的权重,根据两个topics之间的语义关系进行分配,而语义关系的强弱根据两个主题的关键短语之间的距离公式。
- 关键短语选择:一旦topic进行排序后,选择topK个topics,每个topic选择一个最重要的关键短语作为输出,所有topics总共产生topK个关键短语。有三个策略选择一个topic最适合的关键短语:1) 选择关键短语中最开始出现在文档的那个关键短语;2) 选择频率最高的那个关键短语;3) 选择聚焦的群簇中心的那个关键短语。
小结
- 优点:可以考虑文档中词语的语义关系,因此可以更好地提取出与文档主题相关的关键词
- 缺点:效率不高,因为需要进行大量的计算以建立主题模型
MultipartiteRank
paper:Unsupervised Keyphrase Extraction with Multipartite Graphs
MultipartiteRank是一种基于多元关系的关键词提取算法。在TopicRank的基础上,在多部分图结构中对主题信息进行编码,并将关键词候选词和主题表示在一个图中,并利用它们之间的相互加强关系来提取关键词。
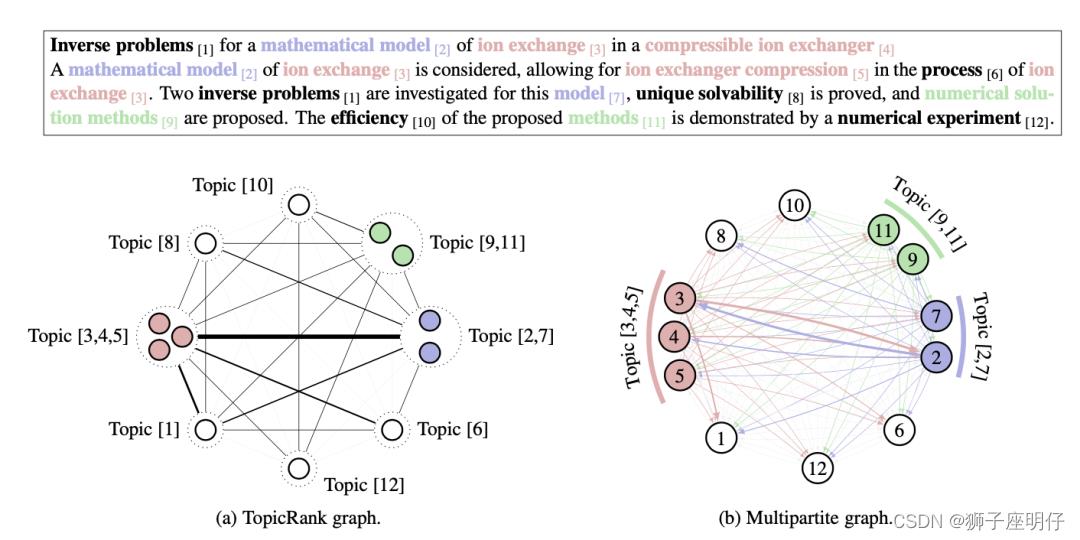
小结
- 优点:可以考虑多种关系,如语义关系和词语位置,从而更好地提取关键词
- 缺点:需要大量的计算,因此效率不高
PositionRank
paper:PositionRank: An Unsupervised Approach to Keyphrase Extraction from Scholarly Documents
PositionRank也是一种基于图结构的算法,与TextRank类似,是基于PageRank的图关系计算词的得分,根据词的位置和词频来计算每个词的权重值。算法主要两个部分组成:
- 图的构建:类似TextRank,根据POS选择关键词构建图的节点,节点的边根据窗口size共现次数来计算两个词的边的权重分值。
- Position-Biased PageRank,会根据每个词位置的倒数计算权重,若一个词出现在文档多个位置,则分值相加。核心思想是:越在一个文档靠前的位置,权重越大,同时频率出现越高,权重也越大。假设一个词在文档的位置时第2,第5,第10,则权重分值为:1/2+1/5+1/10=0.8,再归一化。
该方法在迭代计算词权重的过程中融入了位置信息,融入方式有两种,一种是融入了该词出现的所有位置,另外一种是融入了该词出现的第一个位置。第一种融入方式效果好些。
实验结果:PositionRank优于目前一些主流的图方法和统计方法。
小结
- 优点:可以考虑文档中词语的位置,因此可以更好地提取出文档中重要的关键词
- 缺点:效率不高,因为需要考虑多个文档和词语的位置。
KeyBERT
paper:Keyword Extraction with BERT
是一种基于 Transformer 模型的关键词提取算法,利用了预训练的语言模型的能力来提取关键词。使用BERT的embedding表示层和简单余弦相似性来查找文档中与文档本身最相似的子短语。做法是:
- 使用Sentence-BERT计算文档的embedding表示;
- 对文档中的Ngram短语计算其embedding表示;
- 使用余弦相似度来查找与文档最相似的单词/短语;
- 最相似的topK个单词可以被识别为最能描述整个文档的单词,即关键短语。
实验结果:准确率最高,速度最慢。
小结
- 优点:可以考虑多种语言特征,如语义关系和词语位置,因此效果较好
- 缺点:效率较低,因为需要大量的计算以生成关键词
Reference
关键词提取(keyword extraction)技术
https://github.com/MaartenGr/KeyBERT
PositionRank等四种花式变体的算法思想与开源实现
以上是关于中文关键词提取算法的主要内容,如果未能解决你的问题,请参考以下文章