Mysql查询将查询的结果进行更新
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Mysql查询将查询的结果进行更新相关的知识,希望对你有一定的参考价值。
用sql语句将 两条sql语句查出来的数据 进行更新update set 表 set 字段 in 第一条sql语句(351条数据) where id in (第二条sql语句(351条数据)) -------这种格式执行不成功,请教大家 这条更新语句 该咋写呢

有时候我们会不小心对一个大表进行了 update,比如说写错了 where 条件......
此时,如果 kill 掉 update 线程,那回滚 undo log 需要不少时间。如果放置不管,也不知道 update 会持续多久。
那我们能知道 update 的进度么?
实验
我们先创建一个测试数据库:

快速创建一些数据:

连续执行同样的 SQL 数次,就可以快速构造千万级别的数据:

查看一下总的行数:

我们来释放一个大的 update:

然后另起一个 session,观察 performance_schema 中的信息:
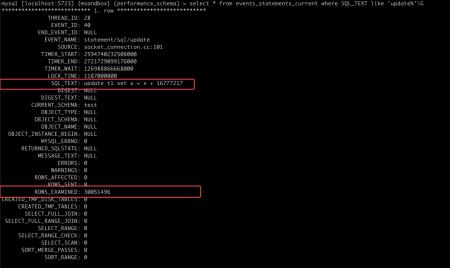
可以看到,performance_schema 会列出当前 SQL 从引擎获取的行数。
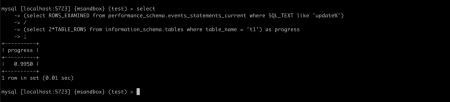
等 SQL 结束后,我们看一下 update 从引擎总共获取了多少行:
可以看到该 update 从引擎总共获取的行数是表大小的两倍,那我们可以估算:update 的进度 = (rows_examined) / (2 * 表行数)
💡小贴士
information_schema.tables 中,提供了对表行数的估算,比起使用 select count(1) 的成本低很多,几乎可以忽略不计。
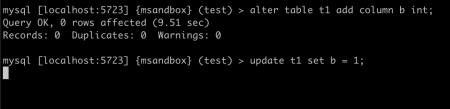
那么是不是所有的 update,从引擎中获取的行数都会是表大小的两倍呢?这个还是要分情况讨论的,上面的 SQL 更新了主键,如果只更新内容而不更新主键呢?我们来试验一下:
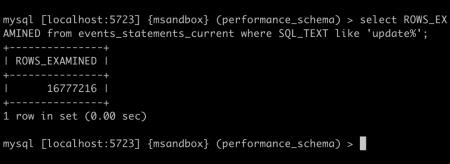
等待 update 结束,查看 row_examined,发现其刚好是表大小:
那我们怎么准确的这个倍数呢?
一种方法是靠经验:update 语句的 where 中会扫描多少行,是否修改主键,是否修改唯一键,以这些条件来估算系数。
另一种方法就是在同样结构的较小的表上试验一下,获取倍数。
这样,我们就能准确估算一个大型 update 的进度了。
参考技术A update a set aa = '1' where ab = ( select ab from b);测试过了 可以通过
但是这个语句只有在 b表中只有一条记录的时候是准确的
如果b表中有多条记录 那你得在子查询中查询指定的某一个 ab 列的值 才是准确的!追问
我用了存储过程,你这种只适合简单的更新,还有 你后面ab如果是多个值怎么办?
update a set aa = '1' where ab in ( select ab from b);
你后面等于号必须改成IN
以上是关于Mysql查询将查询的结果进行更新的主要内容,如果未能解决你的问题,请参考以下文章