文献阅读:Finetuned Language Models Are Zero-Shot Learners
Posted Espresso Macchiato
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了文献阅读:Finetuned Language Models Are Zero-Shot Learners相关的知识,希望对你有一定的参考价值。
1. 文章简介
这篇文章是上年两月份的Google发表的一个工作,提出了他们所谓的Flan模型,算是大模型当中目前比较著名的变体之一了,后面又引申出了Flan-T5,反正都是一个系列的。
上年挺早的时候就听说过这个工作了,然后后面也是在各类报告还有博客推广当中都看到过Flan的大名,也算是相当有名的一个工作了,但是因为是大模型,在实际工作中感觉也不太能用的到,因此虽然很早就知道这个工作,但是其实也一直没有去真正去看过这篇文献,直到现在稍微有点空闲了才回过头来拜读了一下这个原文。
不过,坦率地说,多少有点失望了,因为文中其实没啥特别新的东西,结论也是非常平凡的一个结论,基本可以用一句话来概括:
- 大规模语言模型在经过了标注数据的Finetune之后可以达到更好的效果,且在Finetune中从未见过的任务当中也能够获得更好地效果表达。
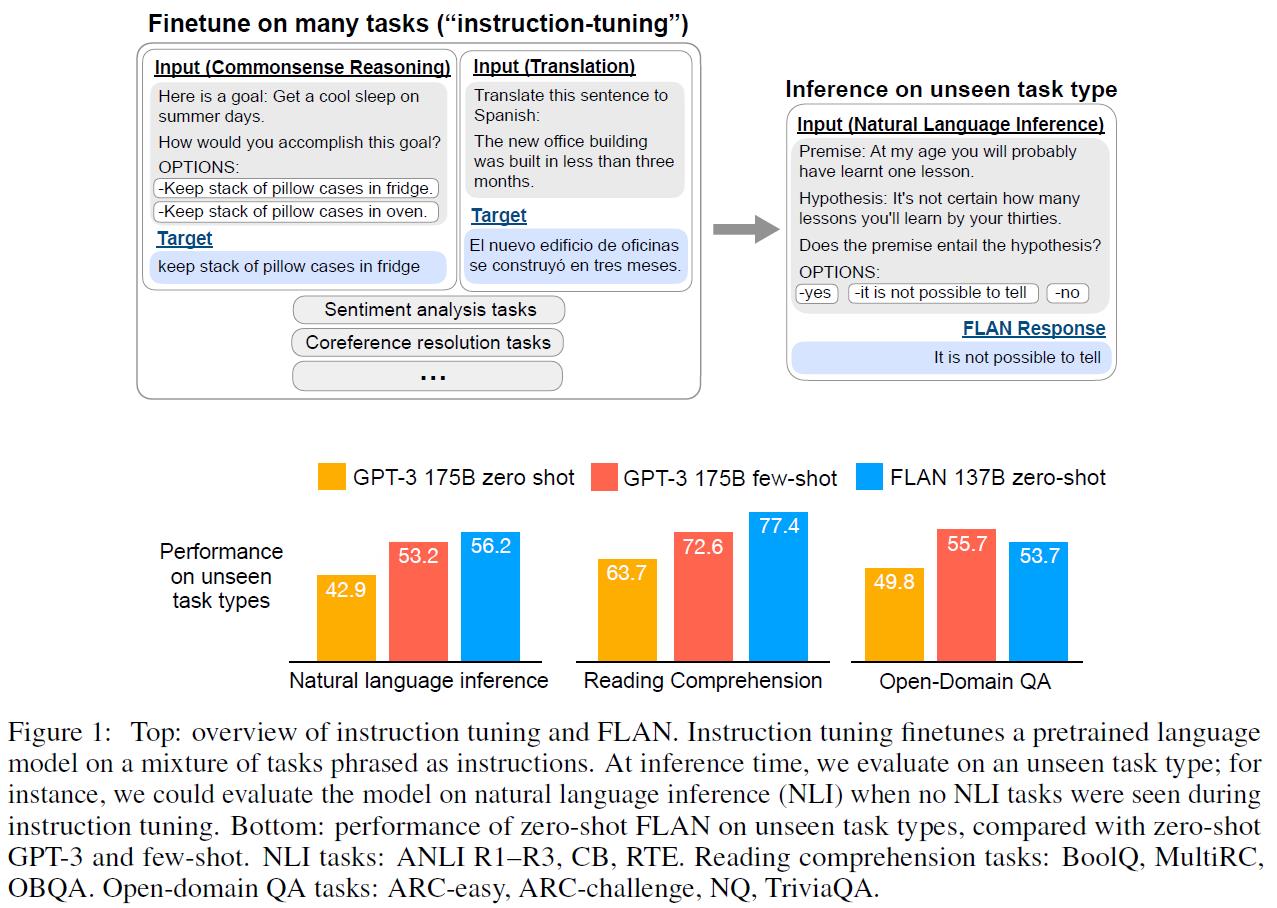
这个结论还是挺平凡的,不过真心一般人玩不起来就是了,不得不说,有钱真好啊……
2. 方法介绍
下面,我们来具体看一下文中的方法,也就是文中提出的FLAN模型。
FLAN模型是Finetuned Language Net的缩写,顾名思义,其实就是对Language模型进行了一下Finetune,不过FLAN的finetune方式是Instruction Tuning,也就是说,他事实上是通过在其它类型的标注数据上面进行finetune,然后在没有见过的类型任务当中进行测试。
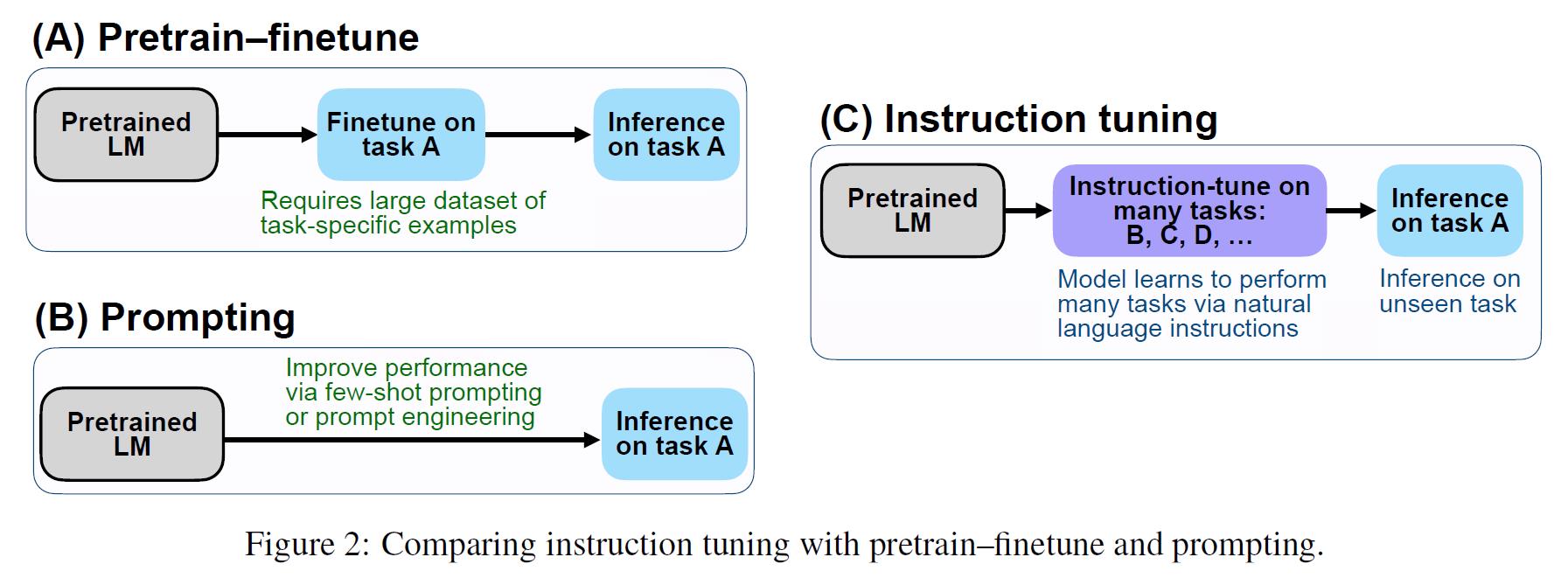
这部分其实整体上都感觉没啥有意思的,从实验到结论都挺平凡的,不过文中进行了一些消解实验,这里面还是有一些比较有意思的结论的。
3. 实验
1. 数据集整理
首先,我们来看一下文中使用的数据集整理如下:
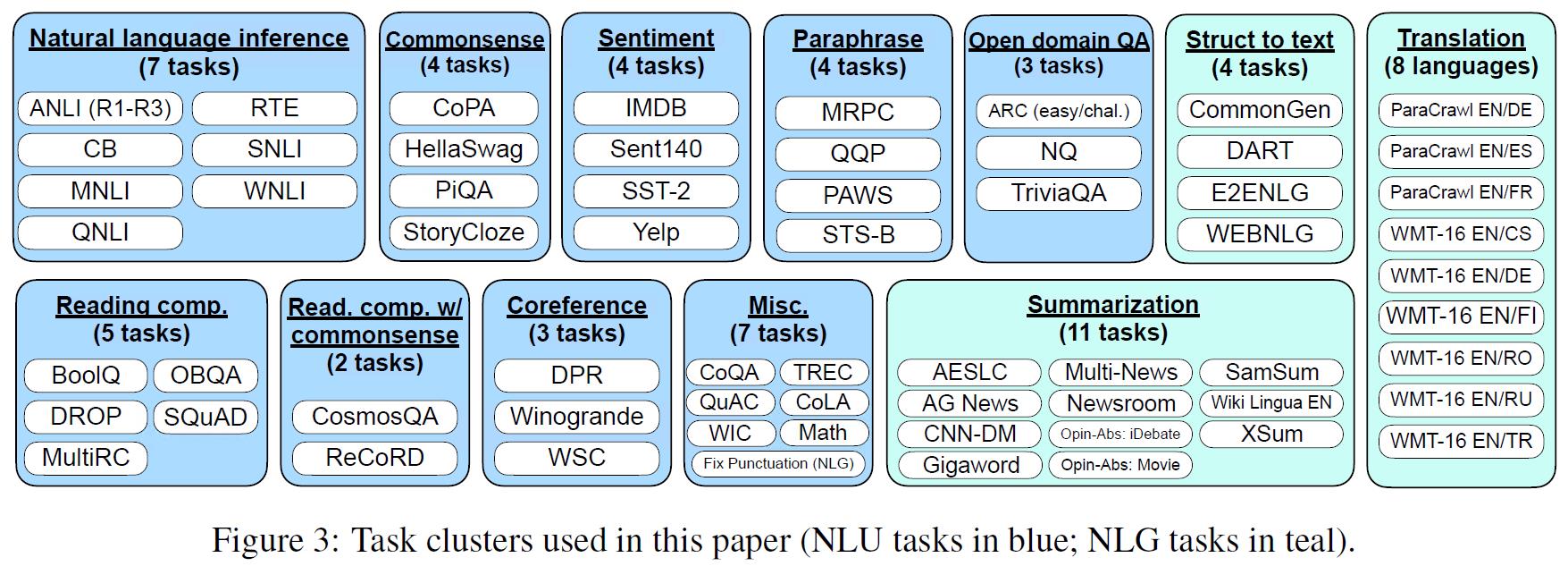
包含了12个大的任务中的62个子数据集。
文中对于每一个任务,都会使用其他任务的数据聚合成一个数据集进行finetune,然后用这个任务中的数据集进行测试。
而有关数据的具体构造方式,文中是通过prompt的方式将标注数据整合成训练文本的,具体如下:
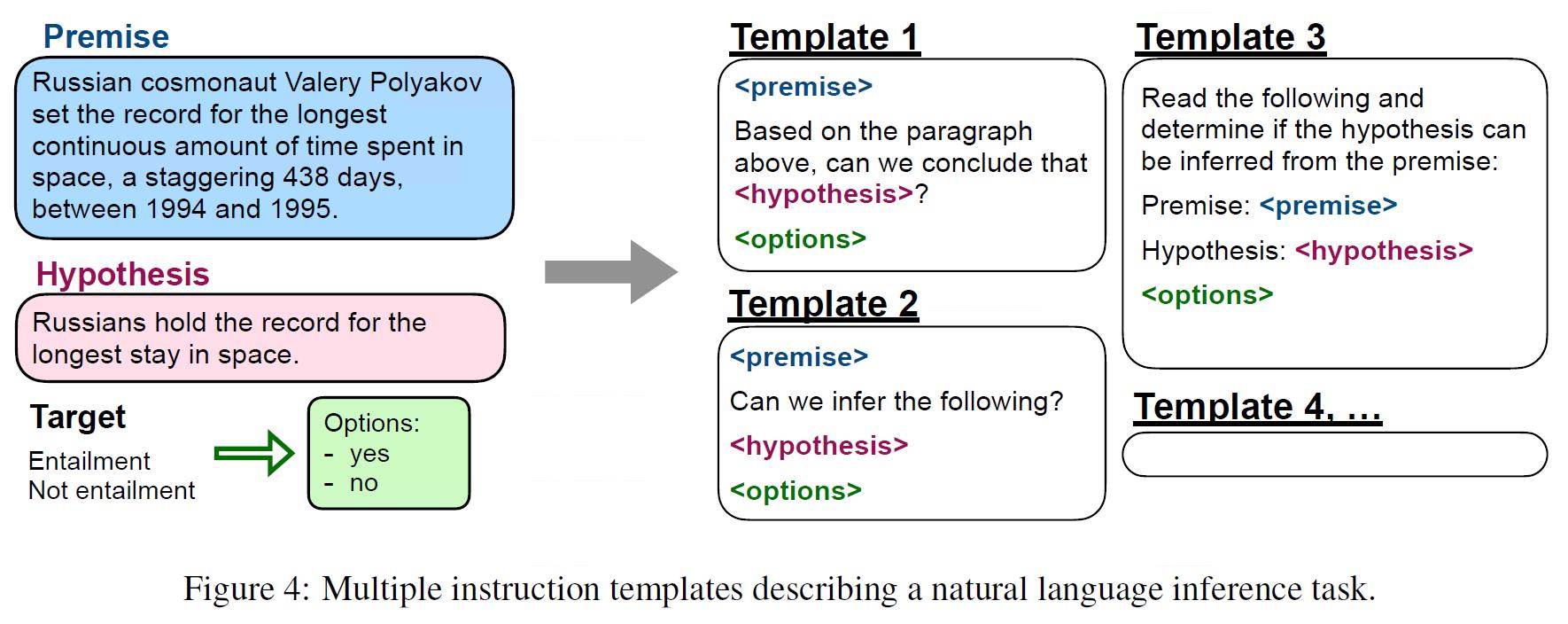
2. 基础实验
文中将FLAN模型在各类任务当中都进行了考察,具体结果如下:
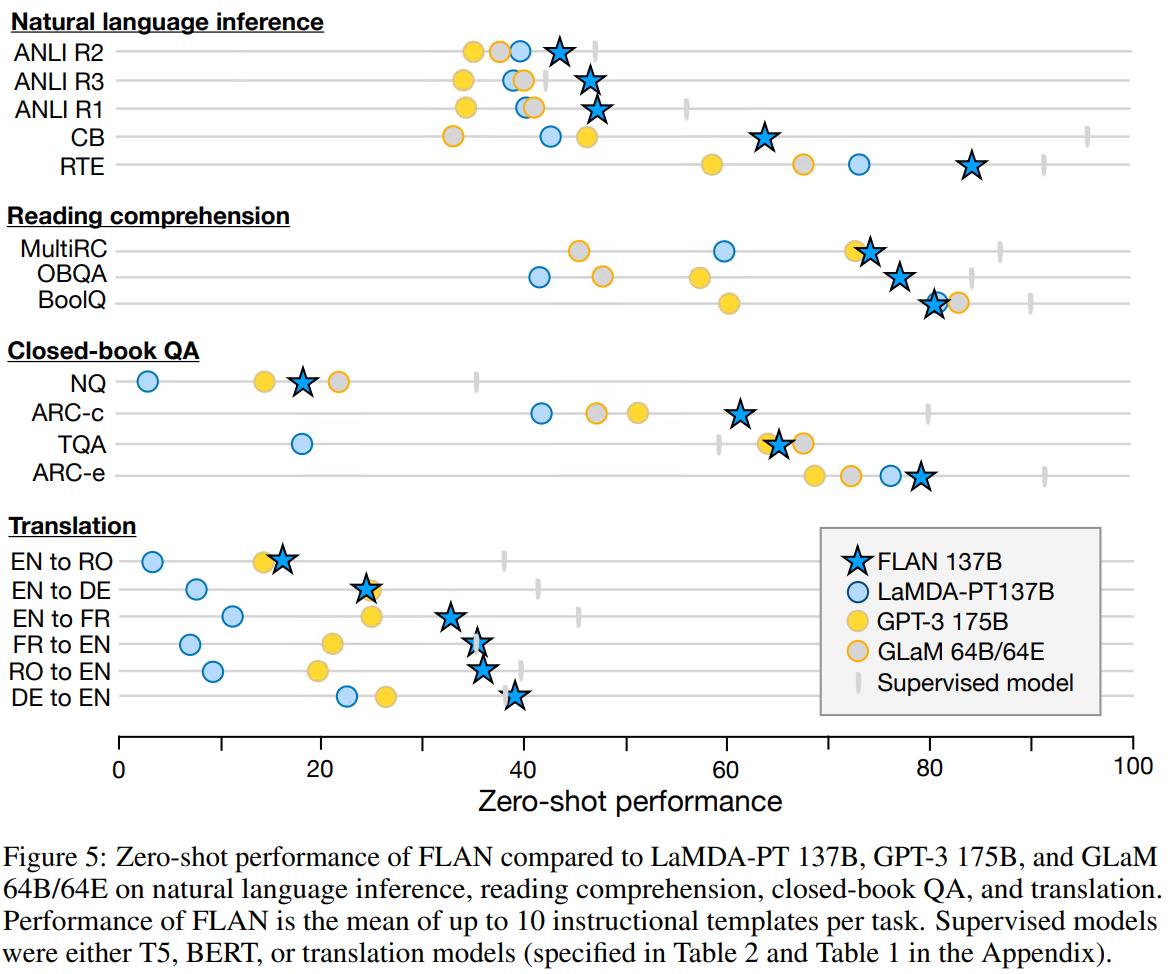
可以看到:
- FLAN在绝大多数任务当中都取得了不错的表现。
3. 消解实验
下面,我们整理一下文中给出的一些消解实验。
1. finetune任务数量
首先,文中考察了一下Tuning的任务数目对最终的模型效果的影响,得到的结果如下:
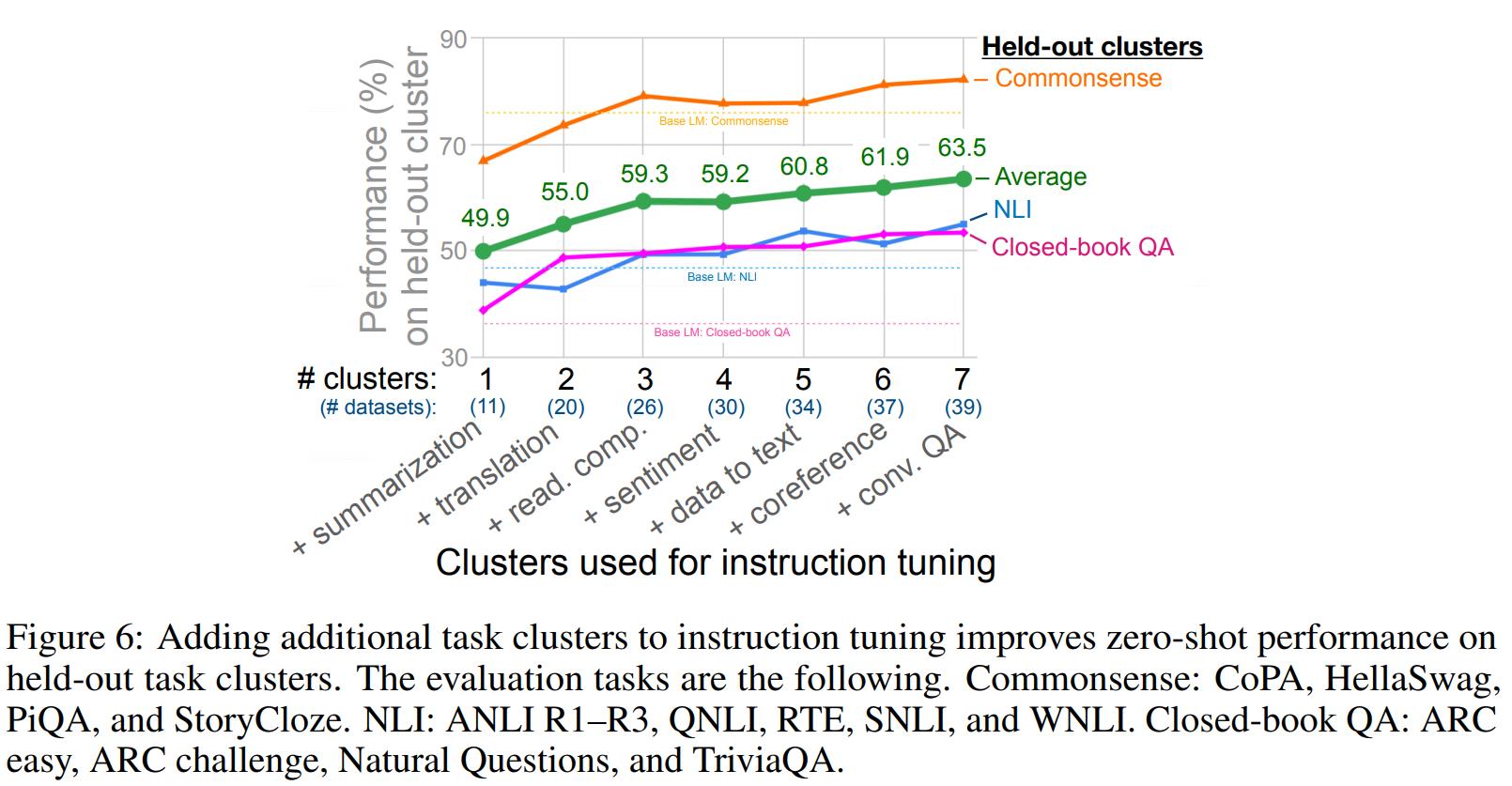
可以看到:
- Tuning过程中使用的数据类型越多,模型最终的泛化表现就越好。
2. 模型size
然后,文中还考查了FLAN在不同size模型基础上的表现,得到结果如下:
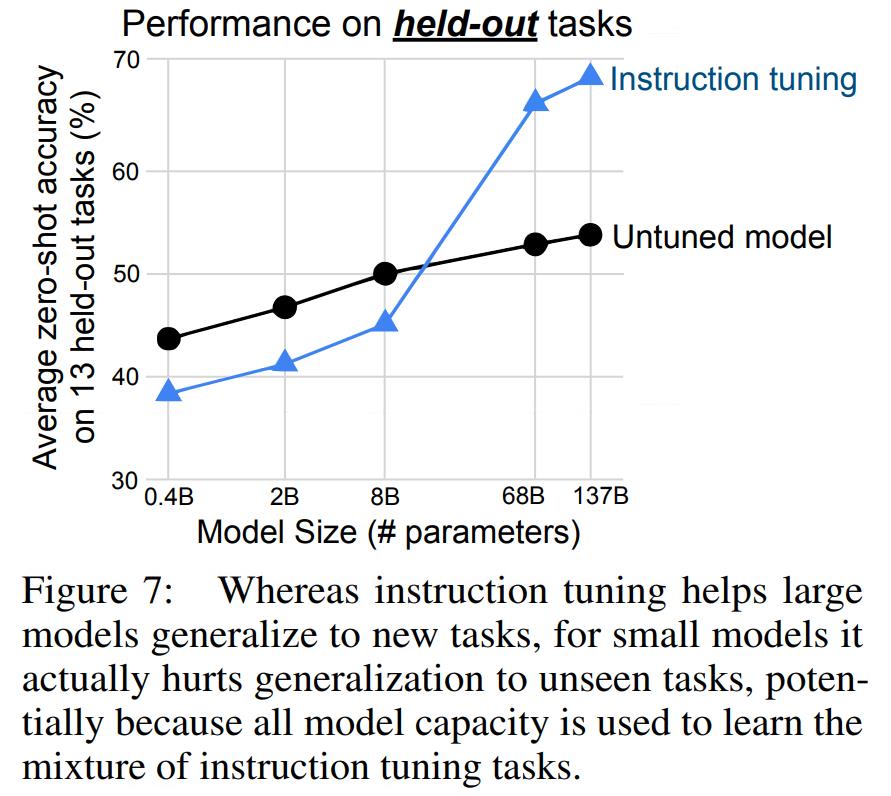
这是一个比较有意思的结果,或者说是一个多少有一点反直觉的结果,可以看到:
- FLAN在小模型的效果上反而劣于不经过finetune的模型,只有在模型size足够大的情况下,FLAN才会表现出较好的效果。
这部分的原因很可能是由于在小模型上finetune可能会导致模型针对任务过拟合,弱化了模型的整体泛化性能。
3. Instruct Tuning
然后,文中还考察了一下不同的训练数据构造方式对于模型效果的影响:

可以看到:
- Instruction Tuning的方式可以获得更好的模型效果,说明自然语言化的文本对于模型在finetune时的理解还是有帮助的。
4. Few-Shot
另外,在原版的GPT3当中,我们知道Few-Shot的方式可以提升模型的表达效果,因此,这里文中还考察了一下Few-Shot方法在FLAN模型当中是否依然有效。
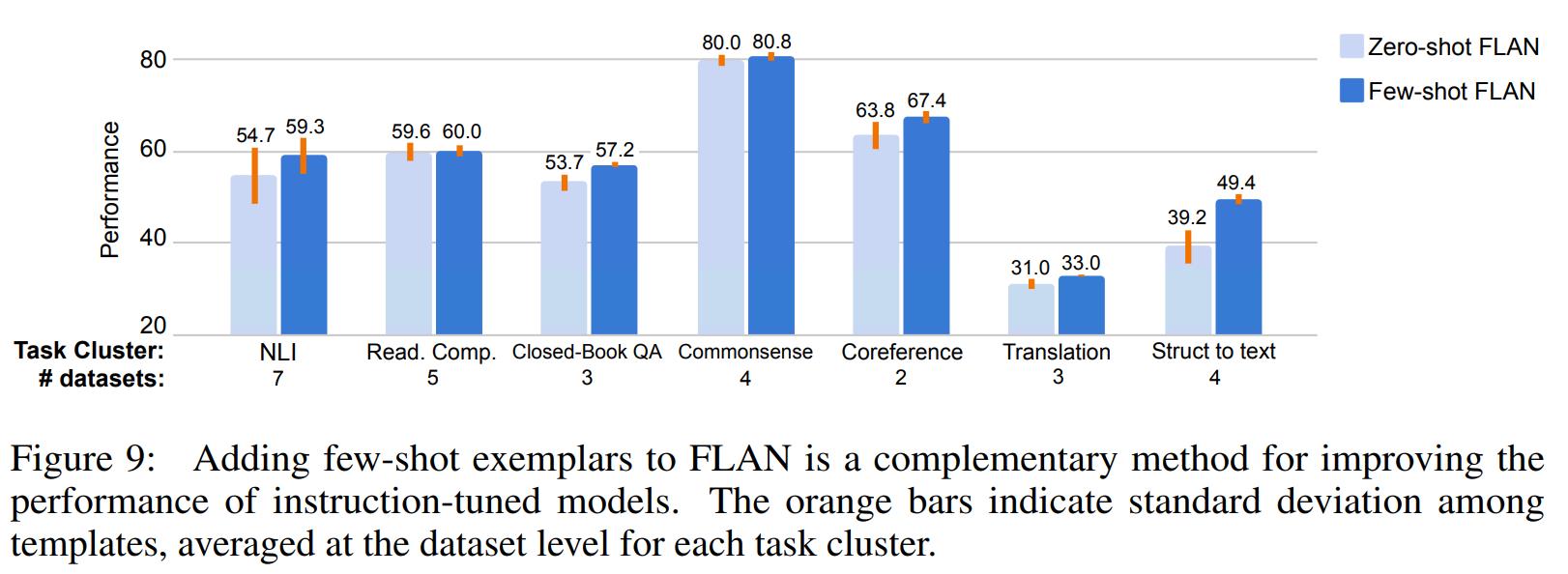
可以看到:
- Few-Shot的方式在FLAN模型当中依然可以提升模型的表达效果。
5. Prompt Tuning
同样的,现有的实验已经证明,soft prompt效果是由于Instruction Prompt的,因此,文中也考察了一下soft prompt是否也适用于FLAN模型。
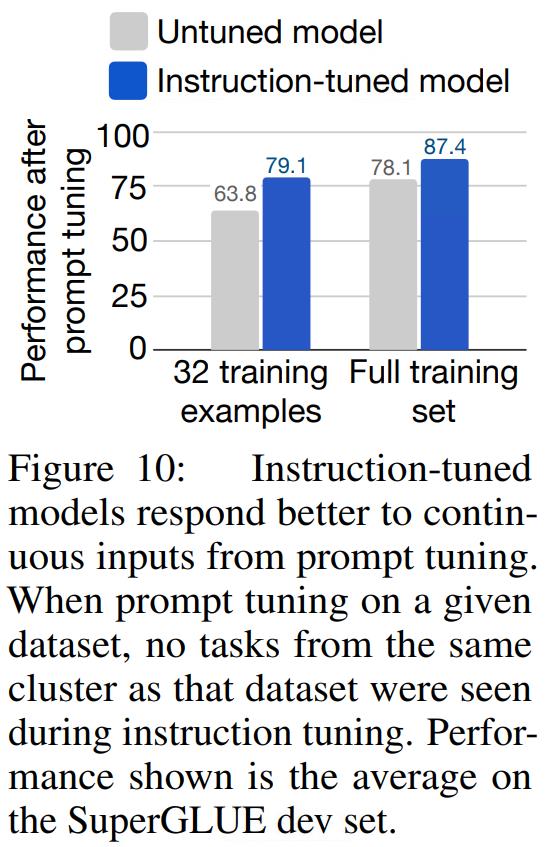
从上图可以看到:
- Soft-Prompt Tuning的方式同样适用于FLAN模型。
4. 结论
综上,我们可以看到:
- 对于大规模语言模型,Finetune依然可以有效的提升模型的效果,即使不是同类型任务的标注数据,依然可以有效地提升模型的效果,且Prompt以及Few-Shot等方法依然可以适用。
以上是关于文献阅读:Finetuned Language Models Are Zero-Shot Learners的主要内容,如果未能解决你的问题,请参考以下文章