用 Keras+LSTM+CRF 的实践命名实体识别NER
Posted Python中文社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用 Keras+LSTM+CRF 的实践命名实体识别NER相关的知识,希望对你有一定的参考价值。

文本分词、词性标注和命名实体识别都是自然语言处理领域里面很基础的任务,他们的精度决定了下游任务的精度,其实在这之前我并没有真正意义上接触过命名实体识别这项工作,虽然说读研期间断断续续也参与了这样的项目,但是毕业之后始终觉得一知半解的感觉,最近想重新捡起来,以实践为学习的主要手段来比较系统地对命名实体识别这类任务进行理解、学习和实践应用。
当今的各个应用里面几乎不会说哪个任务会没有深度学习的影子,很多子任务的发展历程都是惊人的相似,最初大部分的研究和应用都是集中在机器学习领域里面,之后随着深度学习模型的发展,也被广泛应用起来了,命名实体识别这样的序列标注任务自然也是不例外的,早就有了基于LSTM+CRF的深度学习实体识别的相关研究了,只不过与我之前的方向不一致,所以一直没有化太多的时间去关注过它,最近正好在学习NER,在之前的相关文章中已经基于机器学习的方法实践了简单的命名实体识别了,这里以深度学习模型为基础来实现NER。
命名实体识别属于序列标注任务,其实更像是分类任务,NER是在一段文本中,将预先定义好的实体类型识别出来。
NER是一种序列标注问题,因此他们的数据标注方式也遵照序列标注问题的方式,主要是BIO和BIOES两种。这里直接介绍BIOES,明白了BIOES,BIO也就掌握了。
先列出来BIOES分别代表什么意思:
B,即Begin,表示开始
I,即Intermediate,表示中间
E,即End,表示结尾
S,即Single,表示单个字符
O,即Other,表示其他,用于标记无关字符
比如对于下面的一句话:
姚明去哈尔滨工业大学体育馆打球了
标注结果为:
姚明 去 哈尔滨工业大学 体育馆 打球 了
B-PER E-PER O B-ORG I-ORG I-ORG I-ORG I-ORG I-ORG E-ORG B-LOC I-LOC E-LOC O O O
简单的温习就到这里了,接下来进入到本文的实践部分,首先是数据集部分,数据集来源于网络获取,简单看下样例数据,如下所示:

train_data部分样例数据如下所示:
当 O
希 O
望 O
工 O
程 O
救 O
助 O
的 O
百 O
万 O
儿 O
童 O
成 O
长 O
起 O
来 O
, O
科 O
教 O
兴 O
国 O
蔚 O
然 O
成 O
风 O
时 O
, O
今 O
天 O
有 O
收 O
藏 O
价 O
值 O
的 O
书 O
你 O
没 O
买 O
, O
明 O
日 O
就 O
叫 O
你 O
悔 O
不 O
当 O
初 O
!O
test_data部分样例数据如下所示:
高 O
举 O
爱 O
国 O
主 O
义 O
和 O
社 O
会 O
主 O
义 O
两 O
面 O
旗 O
帜 O
, O
团 O
结 O
全 O
体 O
成 O
员 O
以 O
及 O
所 O
联 O
系 O
的 O
归 O
侨 O
、 O
侨 O
眷 O
, O
发 O
扬 O
爱 O
国 O
革 O
命 O
的 O
光 O
荣 O
传 O
统 O
, O
为 O
统 O
一 O
祖 O
国 O
、 O
振 O
兴 O
中 B-LOC
华 I-LOC
而 O
努 O
力 O
奋 O
斗 O
;O
简单了解训练集数据和测试集数据结构后就可以进行后面的数据处理,主要的目的就是生成特征数据,核心代码实现如下所示:
with open('test_data.txt',encoding='utf-8') as f:
test_data_list=[one.strip().split('\\t') for one in f.readlines() if one.strip()]
with open('train_data.txt',encoding='utf-8') as f:
train_data_list=[one.strip().split('\\t') for one in f.readlines() if one.strip()]
char_list=[one[0] for one in test_data_list]+[one[0] for one in train_data_list]
label_list=[one[-1] for one in test_data_list]+[one[-1] for one in train_data_list]
print('char_list_length: ', len(char_list))
print('label_list_length: ', len(label_list))
print('char_num: ', len(list(set(char_list))))
print('label_num: ', len(list(set(label_list))))
char_count,label_count=,
#字符频度统计
for one in char_list:
if one in char_count:
char_count[one]+=1
else:
char_count[one]=1
for one in label_list:
if one in label_count:
label_count[one]+=1
else:
label_count[one]=1
#按频度降序排序
sorted_char=sorted(char_count.items(),key=lambda e:e[1],reverse=True)
sorted_label=sorted(label_count.items(),key=lambda e:e[1],reverse=True)
#字符-id映射关系构建
char_map_dict=
label_map_dict=
for i in range(len(sorted_char)):
char_map_dict[sorted_char[i][0]]=i
char_map_dict[str(i)]=sorted_char[i][0]
for i in range(len(sorted_label)):
label_map_dict[sorted_label[i][0]]=i
label_map_dict[str(i)]=sorted_label[i][0]
#结果存储
with open('charMap.json','w') as f:
f.write(json.dumps(char_map_dict))
with open('labelMap.json','w') as f:
f.write(json.dumps(label_map_dict))
代码实现的很清晰,关键的部分也都有对应的注释内容,这里就不多解释了,核心的思想就是将字符或者是标签类别数据映射为对应的index数据,这里我没有对频度设置过滤阈值,有的实现里面会过滤掉只出现了1次的数据,这个可以根据自己的需要进行对应的修改。
charMap数据样例如下所示:
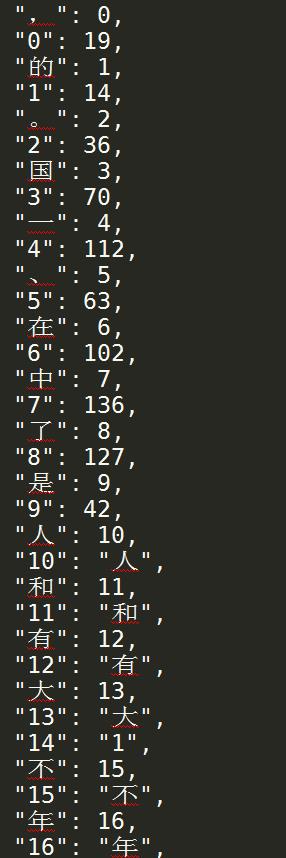
labelMap数据样例如下所示:
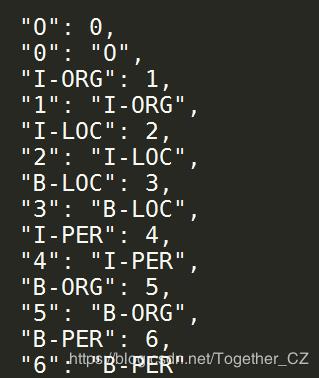
在生成上述映射数据之后,就可以对原始的文本数据进行转化计算,进而生成我们所需要的特征数据了,核心代码实现如下所示:
X_train,y_train,X_test,y_test=[],[],[],[]
#训练数据集
for i in range(len(trainData)):
one_sample=[one.strip().split('\\t') for one in trainData[i]]
char_list=[O[0] for O in one_sample]
label_list=[O[1] for O in one_sample]
char_vec=[char_map_dict[char_list[v]] for v in range(len(char_list))]
label_vec=[label_map_dict[label_list[l]] for l in range(len(label_list))]
X_train.append(char_vec)
y_train.append(label_vec)
#测试数据集
for i in range(len(testData)):
one_sample=[one.strip().split('\\t') for one in testData[i]]
char_list=[O[0] for O in one_sample]
label_list=[O[1] for O in one_sample]
char_vec=[char_map_dict[char_list[v]] for v in range(len(char_list))]
label_vec=[label_map_dict[label_list[l]] for l in range(len(label_list))]
X_test.append(char_vec)
y_test.append(label_vec)
feature=
feature['X_train'],feature['y_train']=X_train,y_train
feature['X_test'],feature['y_test']=X_test,y_test
#结果存储
with open('feature.json','w') as f:
f.write(json.dumps(feature))
到这里我们已经得到了我们所需要的特征数据,且已经划分好了测试集数据和训练集数据。
接下来就可以构建模型了,这里为了简化实现,我采用的是Keras框架,相比于原生态的Tensorflow框架来说,上手门槛更低,核心代码实现如下所示:
#加载数据集
with open('feature.json') as f:
F=json.load(f)
X_train,X_test,y_train,y_test=F['X_train'],F['X_test'],F['y_train'],F['y_test']
#数据对齐操作
X_train = pad_sequences(X_train, maxlen=max_len, value=0)
y_train = pad_sequences(y_train, maxlen=max_len, value=-1)
y_train = np.expand_dims(y_train, 2)
X_test = pad_sequences(X_test, maxlen=max_len, value=0)
y_test = pad_sequences(y_test, maxlen=max_len, value=-1)
y_test = np.expand_dims(y_test, 2)
#模型初始化、训练
if not os.path.exists(saveDir):
os.makedirs(saveDir)
#模型初始化
model = Sequential()
model.add(Embedding(voc_size, 256, mask_zero=True))
model.add(Bidirectional(LSTM(128, return_sequences=True)))
model.add(Dropout(rate=0.5))
model.add(Dense(tag_size))
crf = CRF(tag_size, sparse_target=True)
model.add(crf)
model.summary()
model.compile('adam', loss=crf.loss_function, metrics=[crf.accuracy])
#训练拟合
history=model.fit(X_train,y_train,batch_size=100,epochs=500,validation_data=[X_test,y_test])
model.save(saveDir+'model.h5')
#模型结构可视化
try:
plot_model(model,to_file=saveDir+"model_structure.png",show_shapes=True)
except Exception as e:
print('Exception: ', e)
#结果可视化
plt.clf()
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epochs')
plt.legend(['train','test'], loc='upper left')
plt.savefig(saveDir+'train_validation_acc.png')
plt.clf()
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epochs')
plt.legend(['train', 'test'], loc='upper left')
plt.savefig(saveDir+'train_validation_loss.png')
scores=model.evaluate(X_test,y_test,verbose=0)
print("Accuracy: %.2f%%" % (scores[1]*100))
model_json=model.to_json()
with open(saveDir+'structure.json','w') as f:
f.write(model_json)
model.save_weights(saveDir+'weight.h5')
print('===Finish====')
训练完成后,结构目录文件结构如下所示:
模型结构图如下所示:
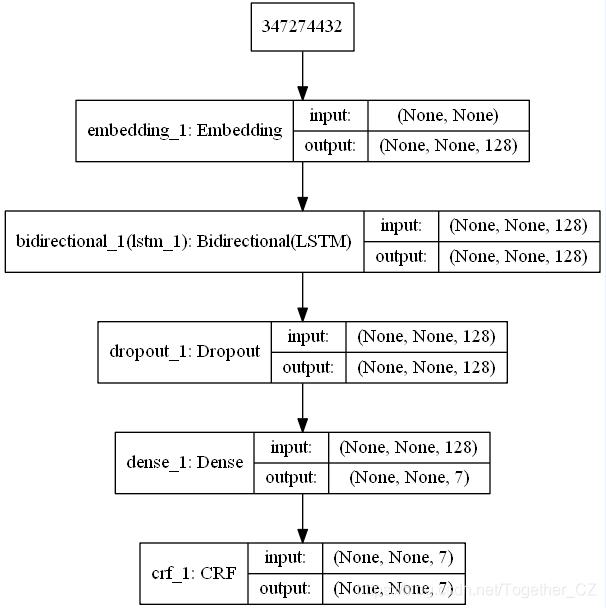
训练过程中准确度曲线如下所示:
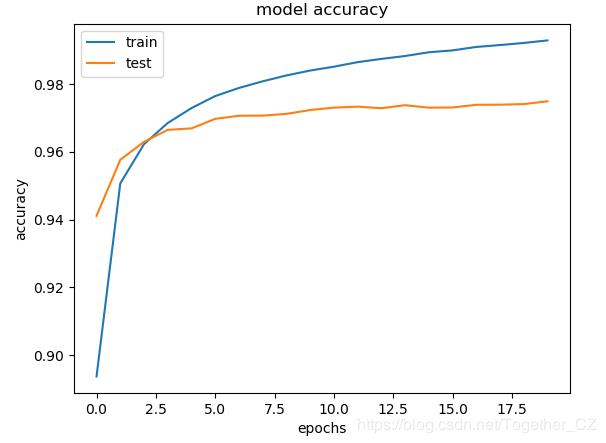
训练过程中损失值曲线如下所示:

由于训练计算资源占用比较大,且时间比较长,我这里只是简单地设置了20次的迭代计算,这个可以根据自己的实际情况设置更高的或者是更低的迭代次数来实现不同的需求。
简单的预测实例如下所示:


到这里,本文的实践就结束了,后面有时间继续深入研究,希望对您有所帮助,祝您工作顺利,学有所成!
作者:沂水寒城,CSDN博客专家,个人研究方向:机器学习、深度学习、NLP、CV
Blog: http://yishuihancheng.blog.csdn.net
赞 赏 作 者

Python中文社区作为一个去中心化的全球技术社区,以成为全球20万Python中文开发者的精神部落为愿景,目前覆盖各大主流媒体和协作平台,与阿里、腾讯、百度、微软、亚马逊、开源中国、CSDN等业界知名公司和技术社区建立了广泛的联系,拥有来自十多个国家和地区数万名登记会员,会员来自以工信部、清华大学、北京大学、北京邮电大学、中国人民银行、中科院、中金、华为、BAT、谷歌、微软等为代表的政府机关、科研单位、金融机构以及海内外知名公司,全平台近20万开发者关注。
长按扫码添加“Python小助手” 进入 P Y 交 流 群
▼点击成为社区会员 喜欢就点个在看吧
以上是关于用 Keras+LSTM+CRF 的实践命名实体识别NER的主要内容,如果未能解决你的问题,请参考以下文章
快递单信息抽取基于ERNIE1.0至ErnieGram + CRF预训练模型