hadoop/hive-生产错误记录
Posted 假如我有一口缸
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop/hive-生产错误记录相关的知识,希望对你有一定的参考价值。
hadoop/hive-生产错误记录
reduce端出现 java.lang.OutOfMemoryError: Direct buffer memory
描述
MR数据量级大,reduce端Direct buffer memory:
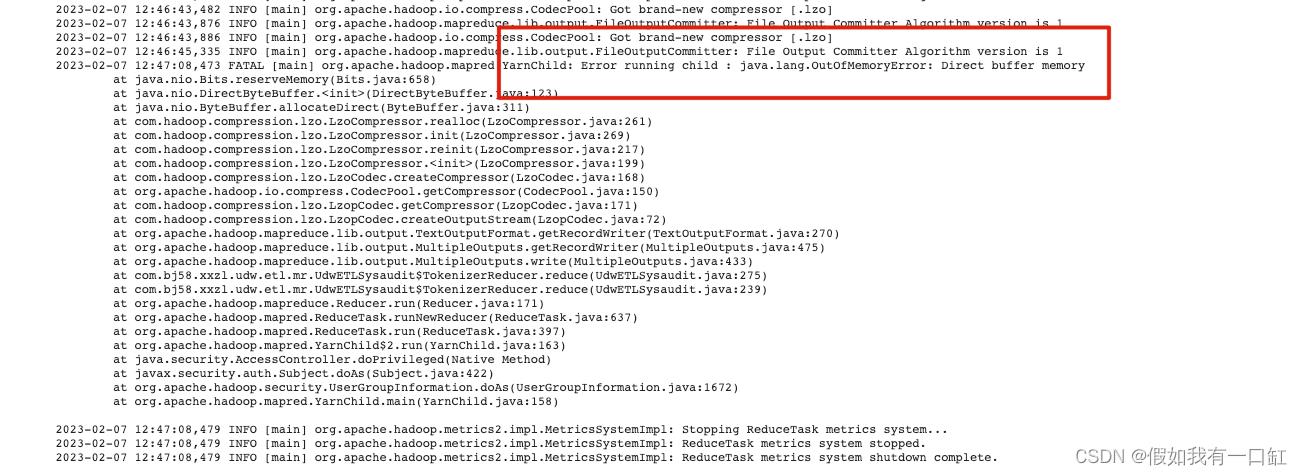
这种情况最好找到configration对应参数,并提高。
解决
在MR任务的yarn UI->Configuration中,搜索 direct 相关的参数:
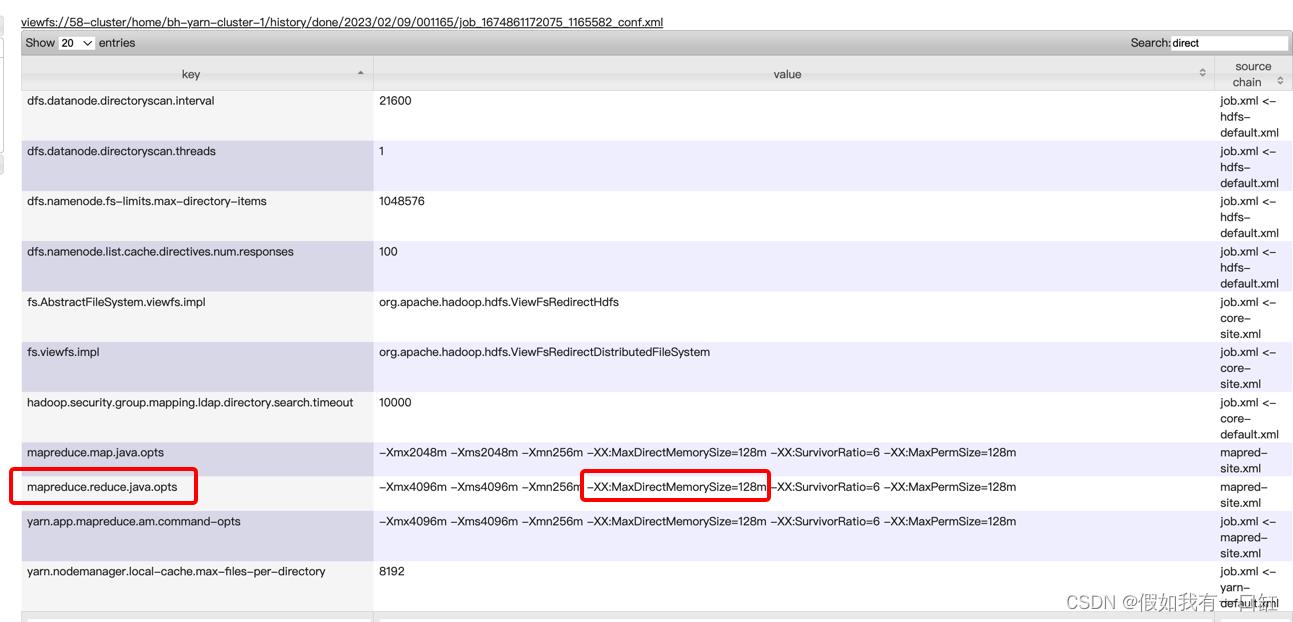
发现使用mapreduce.reduce.java.opts参数来控制reduce端的Direct Memory。
所以在MR main方法中修改mapreduce.reduce.java.opts,把 -XX:MaxDirectMemorySize的值增大到640m:
conf.set("mapreduce.reduce.java.opts",
"-Xmx4096m -Xms4096m -Xmn256m -XX:MaxDirectMemorySize=640m -XX:SurvivorRatio=6 -XX:MaxPermSize=128m -XX:ParallelGCThreads=10");
任务运行成功。
以上是关于hadoop/hive-生产错误记录的主要内容,如果未能解决你的问题,请参考以下文章