基于OpenCV的视频处理 - 人脸检测
Posted 羁旅少年
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于OpenCV的视频处理 - 人脸检测相关的知识,希望对你有一定的参考价值。
一个不知名大学生,江湖人称菜狗
original author: jacky Li
Email : 3435673055@qq.comTime of completion:2023.2.7
Last edited: 2023.2.7导读
本文将使用Python、OpenCV对人脸进行检测,防止痴呆后忘了Quiet。

目录
基于OpenCV的视频处理 - 人脸检测

目前可依靠模块化方式实现图像处理管道,检测一堆图像文件中的人脸,并将其与漂亮的结构化JSON摘要文件一起保存在单独的文件夹中。
让我们对视频流也可以进行同样的操作。为此,我们将构建以下管道:
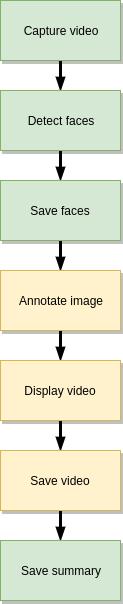
首先,我们需要捕获视频流。该管线任务将从视频文件或网络摄像头(逐帧)生成一系列图像。接下来,我们将检测每个帧上的脸部并将其保存。接下来的三个块是可选的,它们的目标是创建带有注释的输出视频,例如在检测到的人脸周围的框。我们可以显示带注释的视频并将其保存。最后一个任务将收集有关检测到的面部的信息,并保存带有面部的框坐标和置信度的JSON摘要文件。
如果尚未设置jagin / image-processing-pipeline存储库以查看源代码并运行一些示例,则可以立即执行以下操作:
$ git clone git://github.com/jagin/image-processing-pipeline.git
$ cd image-processing-pipeline
$ git checkout 7df1963247caa01b503980fe152138b88df6c526
$ conda env create -f environment.yml
$ conda activate pipeline如果已经克隆了存储库并设置了环境,请使用以下命令对其进行更新:
$ git pull
$ git checkout 7df1963247caa01b503980fe152138b88df6c526
$ conda env update -f environment.yml拍摄影片
使用OpenCV捕获视频非常简单。我们需要创建一个VideoCapture对象,其中参数是设备索引(指定哪个摄像机的数字)或视频文件的名称。然后,我们可以逐帧捕获视频流。
我们可以使用以下CaptureVideo扩展类来实现捕获视频任务Pipeline:
import cv2
from pipeline.pipeline import Pipeline
class CaptureVideo(Pipeline):
def __init__(self, src=0):
self.cap = cv2.VideoCapture(src)
if not self.cap.isOpened():
raise IOError(f"Cannot open video src")
self.fps = int(self.cap.get(cv2.CAP_PROP_FPS))
self.frame_count = int(self.cap.get(cv2.CAP_PROP_FRAME_COUNT))
super(CaptureVideo, self).__init__()
def generator(self):
image_idx = 0
while self.has_next():
ret, image = self.cap.read()
if not ret:
# no frames has been grabbed
break
data =
"image_id": f"image_idx:05d",
"image": image,
if self.filter(data):
image_idx += 1
yield self.map(data)
def cleanup(self):
# Closes video file or capturing device
self.cap.release()使用__init__我们创建VideoCapture对象(第6行)并提取视频流的属性,例如每秒帧数和帧数。我们将需要它们显示进度条并正确保存视频。图像帧将在具有字典结构的generator函数(第30行)中产生:
data =
"image_id": f"image_idx:05d",
"image": image,
当然,数据中也包括图像的序列号和帧的二进制数据。
检测人脸
我们准备检测面部。这次,我们将使用OpenCV的深度神经网络模块,而不是我在上一个故事中所承诺的Haar级联。我们将要使用的模型更加准确,并且还为我们提供了置信度得分。

从版本3.3开始,OpenCV支持许多深度学习框架,例如Caffe,TensorFlow和PyTorch,从而使我们能够加载模型,预处理输入图像并进行推理以获得输出分类。
有一位优秀的博客文章中阿德里安·罗斯布鲁克(Adrian Rosebrock)解释如何使用OpenCV和深度学习实现人脸检测。我们将在FaceDetector类中使用部分代码:
import cv2
import numpy as np
class FaceDetector:
def __init__(self, prototxt, model, confidence=0.5):
self.confidence = confidence
self.net = cv2.dnn.readNetFromCaffe(prototxt, model)
def detect(self, images):
# convert images into blob
blob = self.preprocess(images)
# pass the blob through the network and obtain the detections and predictions
self.net.setInput(blob)
detections = self.net.forward()
# Prepare storage for faces for every image in the batch
faces = dict(zip(range(len(images)), [[] for _ in range(len(images))]))
# loop over the detections
for i in range(0, detections.shape[2]):
# extract the confidence (i.e., probability) associated with the prediction
confidence = detections[0, 0, i, 2]
# filter out weak detections by ensuring the `confidence` is
# greater than the minimum confidence
if confidence < self.confidence:
continue
# grab the image index
image_idx = int(detections[0, 0, i, 0])
# grab the image dimensions
(h, w) = images[image_idx].shape[:2]
# compute the (x, y)-coordinates of the bounding box for the object
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
# Add result
faces[image_idx].append((box, confidence))
return faces
def preprocess(self, images):
return cv2.dnn.blobFromImages(images, 1.0, (300, 300), (104.0, 177.0, 123.0))
我们尝试模块化并分离管道构建块,这种方法将为我们提供易于管理的代码,并使测试更容易编写:
import os
import cv2
from pipeline.libs.face_detector import FaceDetector
import tests.config as config
class TestFaceDetector:
def test_face_detector(self):
prototxt = os.path.join(config.MODELS_FACE_DETECTOR_DIR, "deploy.prototxt.txt")
model = os.path.join(config.MODELS_FACE_DETECTOR_DIR, "res10_300x300_ssd_iter_140000.caffemodel")
detector = FaceDetector(prototxt, model)
test_image = cv2.imread(os.path.join(config.ASSETS_IMAGES_DIR, "friends", "friends_01.jpg"))
faces = detector.detect([test_image])
assert len(faces) == 1
assert len(faces[0]) # Should recognize some faces from friends_01.jpg使用管道架构,可以很容易地CascadeDetectFaces从上一篇文章换成更准确的深度学习人脸检测器模型。让我们FaceDetector在新的DetectFaces管道步骤中使用:
from pipeline.pipeline import Pipeline
from pipeline.libs.face_detector import FaceDetector
class DetectFaces(Pipeline):
def __init__(self, prototxt, model, batch_size=1, confidence=0.5):
self.detector = FaceDetector(prototxt, model, confidence=confidence)
self.batch_size = batch_size
super(DetectFaces, self).__init__()
def generator(self):
batch = []
stop = False
while self.has_next() and not stop:
try:
# Buffer the pipeline stream
data = next(self.source)
batch.append(data)
except StopIteration:
stop = True
# Check if there is anything in batch.
# Process it if the size match batch_size or there is the end of the input stream.
if len(batch) and (len(batch) == self.batch_size or stop):
# Prepare images batch
images = [data["image"] for data in batch]
# Detect faces on all images at once
faces = self.detector.detect(images)
# Extract the faces and attache them to the proper image
for image_idx, image_faces in faces.items():
batch[image_idx]["faces"] = image_faces
# Yield all the data from buffer
for data in batch:
if self.filter(data):
yield self.map(data)
batch = []我们对图像流(第15–20行)进行缓冲,直到到达batch_size(第24行)为止,然后在所有缓冲的图像上(第28行)检测面部,收集面部坐标和置信度(第31–32行),然后重新生成图像(第35-37行)。
当我们使用GPU(图形处理单元)时,我们的武器库中同时运行着数千个处理内核,这些内核专门用于矩阵运算。批量执行推理总是更快,一次向深度学习模型展示的图像多于一张一张。
保存面孔和摘要
SaveFaces并SaveSummary产生输出结果。在SaveFaces类,使用map功能,遍历所有检测到的面部,从图像裁剪他们并保存到输出目录。
SaveSummary类的任务是收集有关已识别面部的所有元数据,并将它们保存为结构良好的JSON文件,该map函数用于缓冲元数据。接下来,我们使用额外的write功能扩展我们的类,我们将需要在管道的末尾触发以将JSON文件与摘要一起保存。脸部图像针对每一帧存储在单独的目录中。

视频输出
为了观察流水线的结果,很高兴可以显示带有带注释的面孔的视频。关于AnnotateImage(pipeline/annotate_image.py)/DisplayVideo(pipeline/display_video.py)的全部内容。

运行中的管道
在process_video_pipeline.py文件中我们可以看到,整个管道的定义如下:
pipeline = (capture_video |
detect_faces |
save_faces |
annotate_image |
display_video |
save_video |
save_summary)上面有很多解释,但是视频和图像胜于雄辩。让我们来看一下触发命令的管道:
python process_video_pipeline.py -i assets/videos/faces.mp4 -p -d -ov faces.avi,M,];
-p将显示进度条,
-d显示带有批注面孔的视频结果,
-ov faces.avi并将视频结果保存到output文件夹。
视频最终的呈现效果如下:

正如我们在示例视频中看到的那样,并不是所有脸孔都能被识别。我们可以降低设置参数的深度学习模型的置信度confidence 0.2(默认值为0.5)。降低置信度阈值会增加假阳性的发生(在图像中没有脸的位置出现脸)。
DetectFaces类的批量处理大小:
$ python process_video_pipeline.py -i assets/videos/faces.mp4 -p
--batch-size 1
100%|███████████████████████████| 577/577 [00:11<00:00, 52.26it/s]
[INFO] Saving summary to output/summary.json...
$ python process_video_pipeline.py -i assets/videos/faces.mp4 -p
--batch-size 4
100%|███████████████████████████| 577/577 [00:09<00:00, 64.66it/s]
[INFO] Saving summary to output/summary.json...
$ python process_video_pipeline.py -i assets/videos/faces.mp4 -p
--batch-size 8
100%|███████████████████████████| 577/577 [00:10<00:00, 56.04it/s]
[INFO] Saving summary to output/summary.json...在我们的硬件上(2.20GHz的Core R7-5800H CPU和NVIDIA RTX 3060 RTX),我门每秒获得52.26帧的图像--batch-size 1,但是对于--batch-size 4我们来说,速度却提高到了每秒64.66帧。
作者有言
如果需要代码,请私聊博主,博主看见回。
如果感觉博主讲的对您有用,请点个关注支持一下吧,将会对此类问题持续更新……
以上是关于基于OpenCV的视频处理 - 人脸检测的主要内容,如果未能解决你的问题,请参考以下文章