关于决策树可视化各项展示数据的解读(泰坦尼克号预测生还案例Titanic)
Posted Joy丶EASon
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关于决策树可视化各项展示数据的解读(泰坦尼克号预测生还案例Titanic)相关的知识,希望对你有一定的参考价值。
本人是业余的编程爱好者,非职业程序员,如有解读错误的地方,欢迎大牛评论指正。
我写这个的动力是:我一晚上花了大量的时间在网上找了各种关于决策树可视化的图中sex=male<0.5或sex=female<0.5代表什么含义;value值哪个代表“遇难”,哪个数字代表“生还”;为什么有的图显示class自己的却没有这些问题的解答,我没有找到一篇文章对此有很清晰全面的解答。但是我就是想搞懂这个,因为可以直接根据图像来获得判断条件与结果的相关性信息!故此花了很多时间进行研究得出了以下结论,希望对大家有帮助。

先说结论:
1、sex=male <= 0.5或 sex=female <= 0.5代表什么含义?
“sex=male” 、 “sex=female” 都是字典特征抽取后的特征值名称。特征抽取后,原先的“sex”特征经one-hot变成了“sex=male” 、 “sex=female”两个特征。
原特征 sex 是 “male” 的,在one-hot后的 “sex=male” 的值为1 ,在one-hot后的 “sex=female” 的值为0 。原特征 sex 是 female 的 反之。
sex=female <= 0.5 是判断条件。是用特征抽取后 “sex=female”字段的值(0或1)做判断。
以上图为例。所有的女人(female)的 “sex=female” 值 都为1,经过 sex=female <= 0.5 条件判断,故都属于false结果。
2、value值哪个代表“遇难”,哪个数字代表“生还”?
value最高的那个值,对应着class显示的分类。以上图为例。最顶的方框中 value = [608,373] 608 > 373 ,class = “死” , 所以608这个值代表遇难人数。
3、为什么有的图显示class自己的却没有?
在可视化输出.dot文件时缺少传递class_names的值。
修改下这行代码就把目标值名称传过来了。
from sklearn.tree import export_graphviz
export_graphviz(
decision_tree = estimator, # estimator 训练后的决策树预估器
out_file = None, # .dot文件输出路径
feature_names = a.get_feature_names() # a = DictVectorizer() 实例化的DictVectorizer
class_names = estimator.classes_ # estimator 训练后的决策树预估器
)各项展示数据的解读
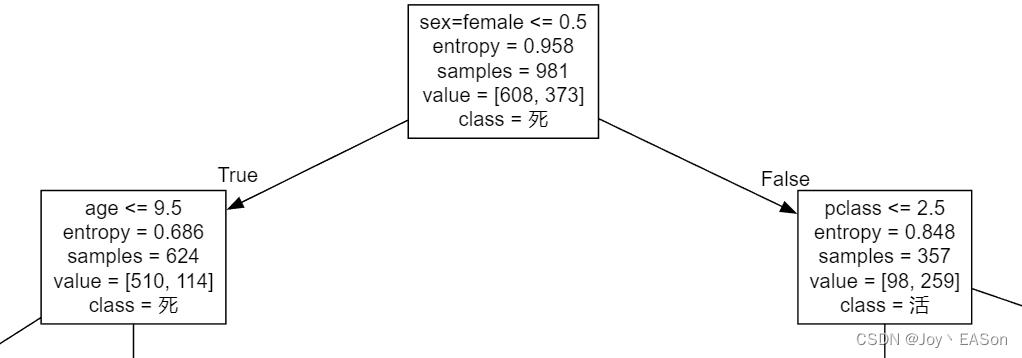
1、“sex=female” 经one-hot后的特征值。1 代表 sex=female ,0代表sex!=female。
2、entropy = 0.958 :信息熵增,数字越大越无序。
3、samples = 981 :样本总数共981个
4、value = [608,373] :目标值共两类,属于第一类的数量为608个,属于第二类的数量为373个
5、class = 死 :value 值最高的分类的名称。
结论推理过程
结论一:sex=male <= 0.5或 sex=female <= 0.5代表什么含义?
证明“sex=male”、“sex=female”是原先的“sex”特征经one-hot特征抽取后拆分的。
import pandas as pd
from sklearn.feature_extraction import DictVectorizer
from sklearn.model_selection import train_test_split
data = pd.read_excel(titanic.xls)
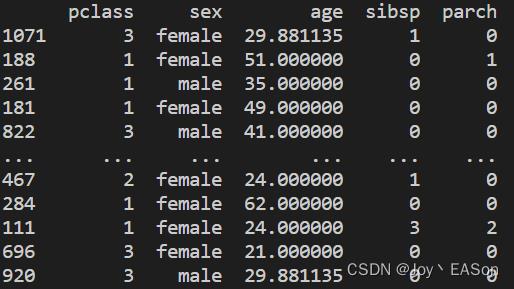
feature_data = data[["pclass", "sex", "age", "sibsp", "parch"]] # 特征值使用这些
target_data = data["survived"] # 目标值字段 这个字段原先的值是0和1,为了清晰理解,我将数据源文件的0改为了“死”,1改为了“活”
train_feature, test_feature, train_target, test_target = train_test_split(feature_data, target_data,train_size= 0.75, random_state= 2012) # 划分训练集和测试集
print(train_feature) # 看下特征训练集
train_feature = train_feature.to_dict(orient = "records") # 转化为字典格式
test_feature = test_feature.to_dict(orient = "records")
a = DictVectorizer() # 实例化字典特征抽取
train_feature = a.fit_transform(train_feature)
test_feature = a.transform(test_feature)
print(a.get_feature_names()) # 看下特征抽取后的特征名称
print(train_feature.toarray()) # 看下特征抽取后的特征值print(train_feature) 结果如下
print(a.get_feature_names())
print(train_feature.toarray()) 结果如下
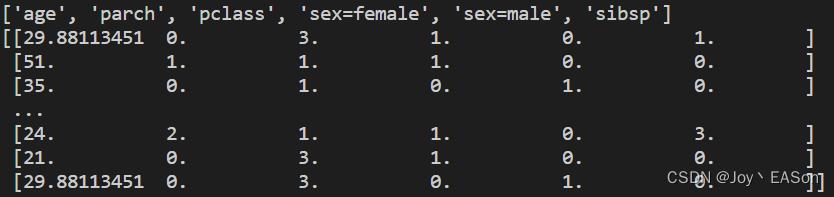
可以看到 sex 特征提取后 变为了 “sex=male”、“sex=female” 两个特征。
sex 属于 female 的第1、2行和倒数第2、3行,在“sex=female”中都是1,在“sex=male”中都是0。
sex 属于 male 的第3行和倒数第1行,在“sex=female”中都是0,在“sex=male”中都是1。
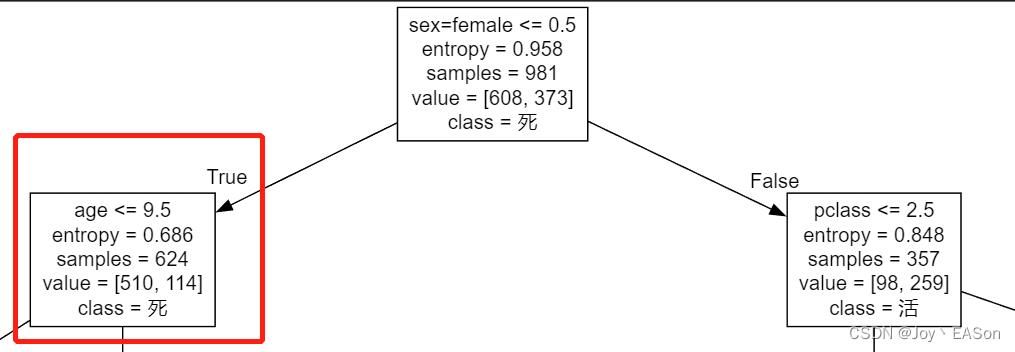
如果上述结论正确,那么sex=female <= 0.5 为True 的样本总数624个都是男人male(“sex=female”的值为0)。
a = train_feature.toarray()[...,-2] # 对训练特征集做切片,取出sex=male这一列,是一个一维数组。
print(a)
print(a.cumsum()) # 对一维数组做加和,因为男人的sex=male的值为1,所以返回的数组最后一个值是总数。print(a)结果

看下前三个值跟后三个值与这张图的sex=male的值是对应上的。
print(a.cumsum()) 结果
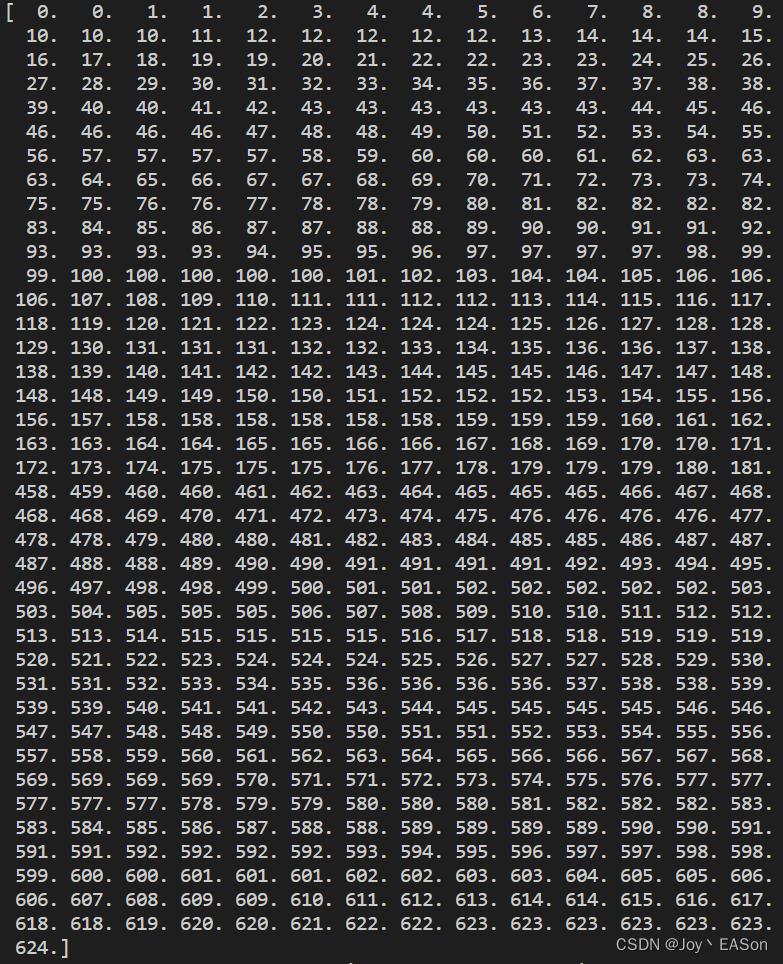
总数是624,跟可视化sex=female <= 0.5 为True 的样本总数624 是能够对应的。故认为结论正确。
结论二: value值哪个代表“遇难”,哪个数字代表“生还”?
证明划分后的训练集样本总数981里是不是有608个“死”,373个“活”就行了。value第一个数字高class就显示“死”,第二个数字高class就显示活。
print(train_target)
print(train_target[train_target == "死"])
print(train_target[train_target == "活"])结果:
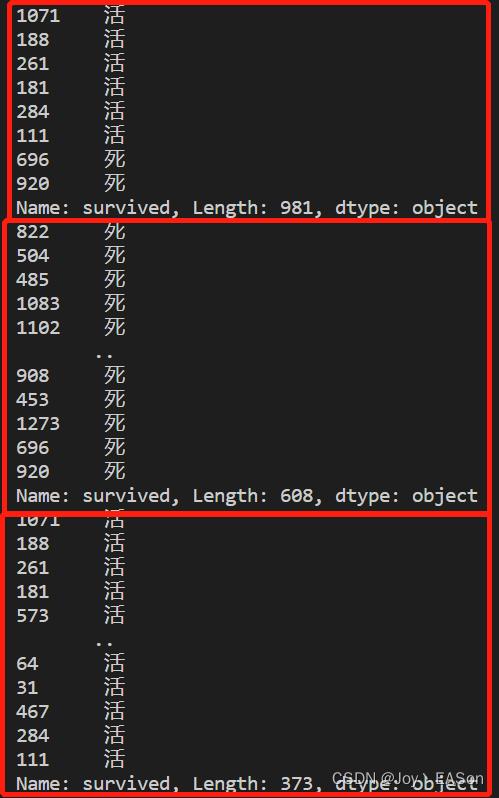
Length:981与训练集样本总数981是一致的。
survivied = "死" 的 Length:608 ;survivied = "活" 的 Length:373,与value是一致的。故证明。
创作不易,转载请注明出处,谢谢!
以上是关于关于决策树可视化各项展示数据的解读(泰坦尼克号预测生还案例Titanic)的主要内容,如果未能解决你的问题,请参考以下文章