Android6.0系统启动流程分析一:init进程
Posted 阳光玻璃杯
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Android6.0系统启动流程分析一:init进程相关的知识,希望对你有一定的参考价值。
到了android6.0,Init进程使用c++来写了,不过没有关系,它和c写的init没有太大的区别。
Init进程的入口代码是:system\\core\\init\\init.cpp
main函数:
int main(int argc, char** argv) {
if (!strcmp(basename(argv[0]), "ueventd")) {
return ueventd_main(argc, argv);
}
if (!strcmp(basename(argv[0]), "watchdogd")) {
return watchdogd_main(argc, argv);
}
// Clear the umask.
umask(0);
add_environment("PATH", _PATH_DEFPATH);
bool is_first_stage = (argc == 1) || (strcmp(argv[1], "--second-stage") != 0);
// Get the basic filesystem setup we need put together in the initramdisk
// on / and then we'll let the rc file figure out the rest.
if (is_first_stage) {
mount("tmpfs", "/dev", "tmpfs", MS_NOSUID, "mode=0755");
mkdir("/dev/pts", 0755);
mkdir("/dev/socket", 0755);
mount("devpts", "/dev/pts", "devpts", 0, NULL);
mount("proc", "/proc", "proc", 0, NULL);
mount("sysfs", "/sys", "sysfs", 0, NULL);
}
// We must have some place other than / to create the device nodes for
// kmsg and null, otherwise we won't be able to remount / read-only
// later on. Now that tmpfs is mounted on /dev, we can actually talk
// to the outside world.
open_devnull_stdio();
klog_init();
klog_set_level(KLOG_NOTICE_LEVEL);
NOTICE("init%s started!\\n", is_first_stage ? "" : " second stage");
if (!is_first_stage) {
// Indicate that booting is in progress to background fw loaders, etc.
close(open("/dev/.booting", O_WRONLY | O_CREAT | O_CLOEXEC, 0000));
property_init();
// If arguments are passed both on the command line and in DT,
// properties set in DT always have priority over the command-line ones.
process_kernel_dt();
process_kernel_cmdline();
// Propogate the kernel variables to internal variables
// used by init as well as the current required properties.
export_kernel_boot_props();
}
// Set up SELinux, including loading the SELinux policy if we're in the kernel domain.
selinux_initialize(is_first_stage);
// If we're in the kernel domain, re-exec init to transition to the init domain now
// that the SELinux policy has been loaded.
if (is_first_stage) {
if (restorecon("/init") == -1) {
ERROR("restorecon failed: %s\\n", strerror(errno));
security_failure();
}
char* path = argv[0];
char* args[] = { path, const_cast<char*>("--second-stage"), nullptr };
if (execv(path, args) == -1) {
ERROR("execv(\\"%s\\") failed: %s\\n", path, strerror(errno));
security_failure();
}
}
// These directories were necessarily created before initial policy load
// and therefore need their security context restored to the proper value.
// This must happen before /dev is populated by ueventd.
INFO("Running restorecon...\\n");
restorecon("/dev");
restorecon("/dev/socket");
restorecon("/dev/__properties__");
restorecon_recursive("/sys");
epoll_fd = epoll_create1(EPOLL_CLOEXEC);
if (epoll_fd == -1) {
ERROR("epoll_create1 failed: %s\\n", strerror(errno));
exit(1);
}
signal_handler_init();
property_load_boot_defaults();
start_property_service();
init_parse_config_file("/init.rc");
action_for_each_trigger("early-init", action_add_queue_tail);
// Queue an action that waits for coldboot done so we know ueventd has set up all of /dev...
queue_builtin_action(wait_for_coldboot_done_action, "wait_for_coldboot_done");
// ... so that we can start queuing up actions that require stuff from /dev.
queue_builtin_action(mix_hwrng_into_linux_rng_action, "mix_hwrng_into_linux_rng");
queue_builtin_action(keychord_init_action, "keychord_init");
queue_builtin_action(console_init_action, "console_init");
// Trigger all the boot actions to get us started.
action_for_each_trigger("init", action_add_queue_tail);
// Repeat mix_hwrng_into_linux_rng in case /dev/hw_random or /dev/random
// wasn't ready immediately after wait_for_coldboot_done
queue_builtin_action(mix_hwrng_into_linux_rng_action, "mix_hwrng_into_linux_rng");
// Don't mount filesystems or start core system services in charger mode.
char bootmode[PROP_VALUE_MAX];
if (property_get("ro.bootmode", bootmode) > 0 && strcmp(bootmode, "charger") == 0) {
action_for_each_trigger("charger", action_add_queue_tail);
} else {
action_for_each_trigger("late-init", action_add_queue_tail);
}
// Run all property triggers based on current state of the properties.
queue_builtin_action(queue_property_triggers_action, "queue_property_triggers");
while (true) {
if (!waiting_for_exec) {
execute_one_command();
restart_processes();
}
int timeout = -1;
if (process_needs_restart) {
timeout = (process_needs_restart - gettime()) * 1000;
if (timeout < 0)
timeout = 0;
}
if (!action_queue_empty() || cur_action) {
timeout = 0;
}
bootchart_sample(&timeout);
epoll_event ev;
int nr = TEMP_FAILURE_RETRY(epoll_wait(epoll_fd, &ev, 1, timeout));
if (nr == -1) {
ERROR("epoll_wait failed: %s\\n", strerror(errno));
} else if (nr == 1) {
((void (*)()) ev.data.ptr)();
}
}
return 0;
}
1.这个函数是否往下执行取决于传入的参数,如果第0个参数的basename为ueventd,则执行ueventd_main(argc, argv);如果basename为watchdogd_main,则执行watchdogd_main(argc, argv);只有basename不为这二者时,才会继续往下执行。
2.如果argv[1]不为”–second-stage”或者只有一个参数的话,那么is_first_stage就为true,就会创建/dev/pts和”/dev/socket”两个设备文件节点,并挂载一个文件系统。可以看出来init进程分两个阶段,不同的阶段有不同的行为。具体的内涵鄙人还没搞明白。
3.启动属性服务。创建一个socket,并在之后的死循环中监听这个socket返回的文件描述符。
3.解析init.rc。这个过程也是我最感兴趣的,也是最重要的复杂的。
4.对各个阶段的action排序。
5.进入死循环。
6.第一次进入死循环后,action_queue里面有很多时间,因此需要不断调用execute_one_command来执行命令。此时,action_queue_empty为假,timeout 为0,init线程不会在epoll_wait方法中休眠,因为设置的timeout=0哦,这一点曾一度困扰了我。
7.所有的命令执行完后,init进程进入休眠,监听property_set_fd和signal_read_fd两个文件描述符,一点他们有事件过来,立刻被唤醒,进而做事件处理。
init.rc梳理
在我们分析init.rc的解析过程之前,我们还需要先对init.rc有个基本的认识。
先看一张我根据理解绘制的图:
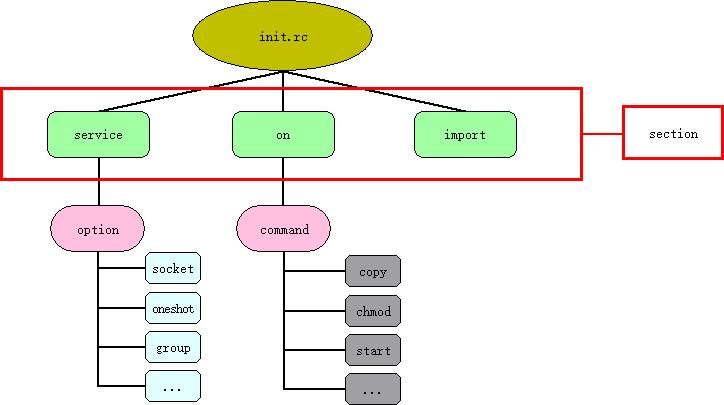
从图来看,init.rc主要有section组成,section由on,import,section三个关键字标示。其中on标示的section叫做action。
import就不用说了,和c语言中的include功能有点类似。
service格式如下
service <name> <pathname> [ <argument> ]*
<option>
<option>
... action后面会跟一个触发器,然后另起一行开始放置命令(command),格式如下:
on <trigger>
<command>
<command>
<command> 跟在service后面的是option,跟在action后面的是command.command都会对应一个处理函数,定义在keywords.h中:
...
KEYWORD(loglevel, COMMAND, 1, do_loglevel)
KEYWORD(mkdir, COMMAND, 1, do_mkdir)
KEYWORD(mount_all, COMMAND, 1, do_mount_all)
KEYWORD(mount, COMMAND, 3, do_mount)
...命名也是很有规则的。比如mkdir,对应的函数就是do_mkdir。我们看看do_mkdir做了什么:
int do_mkdir(int nargs, char **args)
{
mode_t mode = 0755;
int ret;
/* mkdir <path> [mode] [owner] [group] */
if (nargs >= 3) {
mode = strtoul(args[2], 0, 8);
}
ret = make_dir(args[1], mode);
/* chmod in case the directory already exists */
if (ret == -1 && errno == EEXIST) {
ret = fchmodat(AT_FDCWD, args[1], mode, AT_SYMLINK_NOFOLLOW);
}
if (ret == -1) {
return -errno;
}
if (nargs >= 4) {
uid_t uid = decode_uid(args[3]);
gid_t gid = -1;
if (nargs == 5) {
gid = decode_uid(args[4]);
}
if (lchown(args[1], uid, gid) == -1) {
return -errno;
}
/* chown may have cleared S_ISUID and S_ISGID, chmod again */
if (mode & (S_ISUID | S_ISGID)) {
ret = fchmodat(AT_FDCWD, args[1], mode, AT_SYMLINK_NOFOLLOW);
if (ret == -1) {
return -errno;
}
}
}
return e4crypt_set_directory_policy(args[1]);
}
其实就是调用了make_dir并做了一些权限等方面的操作。所以,跟在action后面的命令并不能随随便便乱加,而是要确保这个命令被定义了,不然就会出错。
init.rc的解析过程(以import为例)
因为init.rc的第一行代码就是Import语句。万事开头难,只要我们理清了第一行的解析过程,后面行的解析分析起来就不怎么费劲了。所以下面我们主要看看init.rc中第一行的解析过程。
init.tc的解析函数为:init_parse_config_file
int init_parse_config_file(const char* path) {
INFO("Parsing %s...\\n", path);
Timer t;
std::string data;
if (!read_file(path, &data)) {
return -1;
}
data.push_back('\\n'); // TODO: fix parse_config.
parse_config(path, data);
dump_parser_state();
// MStar Android Patch Begin
INFO("(Parsing %s took %.2fs.)\\n", path, t.duration());
// MStar Android Patch End
return 0;
}这个函数把/init.rc中的内容读出来,并让data这个string类型的变量指向它。
把读出来的data传递给parse_config函数做真正的解析工作。parse_config函数如下:
static void parse_config(const char *fn, const std::string& data)
{
char *args[UEVENTD_PARSER_MAXARGS];
int nargs = 0;
parse_state state;
state.filename = fn;
state.line = 1;
state.ptr = strdup(data.c_str()); // TODO: fix this code!
state.nexttoken = 0;
state.parse_line = parse_line_no_op;
for (;;) {
int token = next_token(&state);
switch (token) {
case T_EOF:
parse_line(&state, args, nargs);
return;
case T_NEWLINE:
if (nargs) {
parse_line(&state, args, nargs);
nargs = 0;
}
state.line++;
break;
case T_TEXT:
if (nargs < UEVENTD_PARSER_MAXARGS) {
args[nargs++] = state.text;
}
break;
}
}
}我看到这个函数的时候,我想起了xml解析方法之一的pull解析,感觉挺像的。每次循环都会找到一个token,token就是一个特定的符号,然后根据这个toke做不同的处理。这里使用到了parse_state结构,启动以如下:
struct parse_state
{
char *ptr;
char *text;
int line;
int nexttoken;
void *context;
void (*parse_line)(struct parse_state *state, int nargs, char **args);
const char *filename;
void *priv;
};这个就够中:ptr执行init.rc字符流的,text后面会用到,用来保存参数,line当然就是行数了,nexttoken保存下一个token,filename保存init.rc的文件描述符,filename当然是/init.rc了.parse_line是一个函数指针。context暂时没明白…state.priv 指向Import的一个文件链表。
我们打开Init.rc看看,从头分析它的解析过程。
import /init.environ.rc
import /init.usb.rc
import /init.${ro.hardware}.rc
import /init.${ro.zygote}.rc
import /init.trace.rc
...init.rc前面几行都是import语句,我们看看一开始的解析流程。
这个时候,parse_satate的状态为:
state.filename = fn;
state.line = 1;
state.ptr = strdup(data.c_str()); // TODO: fix this code!
state.nexttoken = 0;
state.parse_line = parse_line_no_op;
list_init(&import_list);
state.priv = &import_list;step 1.第一次循环
然后进入死循环,第一次调用next_token函数:
int next_token(struct parse_state *state)
{
char *x = state->ptr;
char *s;
if (state->nexttoken) {
int t = state->nexttoken;
state->nexttoken = 0;
return t;
}
for (;;) {
switch (*x) {
case 0:
state->ptr = x;
return T_EOF;
case '\\n':
x++;
state->ptr = x;
return T_NEWLINE;
case ' ':
case '\\t':
case '\\r':
x++;
continue;
case '#':
while (*x && (*x != '\\n')) x++;
if (*x == '\\n') {
state->ptr = x+1;
return T_NEWLINE;
} else {
state->ptr = x;
return T_EOF;
}
default:
goto text;
}
}
textdone:
state->ptr = x;
*s = 0;
return T_TEXT;
text:
state->text = s = x;
textresume:
for (;;) {
switch (*x) {
case 0:
goto textdone;
case ' ':
case '\\t':
case '\\r':
x++;
goto textdone;
case '\\n':
state->nexttoken = T_NEWLINE;
x++;
goto textdone;
case '"':
x++;
for (;;) {
switch (*x) {
case 0:
/* unterminated quoted thing */
state->ptr = x;
return T_EOF;
case '"':
x++;
goto textresume;
default:
*s++ = *x++;
}
}
break;
case '\\\\':
x++;
switch (*x) {
case 0:
goto textdone;
case 'n':
*s++ = '\\n';
break;
case 'r':
*s++ = '\\r';
break;
case 't':
*s++ = '\\t';
break;
case '\\\\':
*s++ = '\\\\';
break;
case '\\r':
/* \\ <cr> <lf> -> line continuation */
if (x[1] != '\\n') {
x++;
continue;
}
case '\\n':
/* \\ <lf> -> line continuation */
state->line++;
x++;
/* eat any extra whitespace */
while((*x == ' ') || (*x == '\\t')) x++;
continue;
default:
/* unknown escape -- just copy */
*s++ = *x++;
}
continue;
default:
*s++ = *x++;
}
}
return T_EOF;
}
这时候,init.rc中的第一个符号应该是i(impor,省去空格),所以next_token直接进入到text:标签执行,执行的结果是state->text = s = ‘i’;然后继续执行textresume:标签后面的内容:
标签后面的for死循环中,发现第一个字符是i,于是执行default分支:*s++ = *x++;这样直到import的t被检测完以后,在下一次循环变得到一个空格,于是执行x++,并goto textdone.。textdown执行完后函数返回,返回后,state->ptr 指向’/’符号 。*s = 0;意味着state.text就是字符串“import”,因为0就是字符串结束符了。注意返回值为T_TEXT。这个时候执行parse_config函数中的case T_TEXT:分支。
case T_TEXT:
if (nargs < INIT_PARSER_MAXARGS) {
args[nargs++] = state.text;
}这个时候,nargs为0,state.text位import,于是args数组的第0项就存了”import”字符串了。然后nargs++,也就是等于1了。然后进入下次循环。
step 2.第二次循环
第二次循环再次调用next_token函数,这次state->ptr=’\\’,这我们分析过了。因此next_token函数不断执行defaulty分支,最终state.text = “/init.environ.rc”,返回类型还是T_TEXT。于是和之前一样,args[1]=”/init.environ.rc”,nargs=2。
step 3.第三次循环
这个时候一行结束,parse_config函数进入case T_NEWLINE:分支。
这个分支中,首先执行lookup_keyword函数,从名字来看是查找关键字。肯定就是import了,它肯定是关键字。不信请看代码:
static int lookup_keyword(const char *s)
{
switch (*s++) {
case 'b':
if (!strcmp(s, "ootchart_init")) return K_bootchart_init;
break;
case 'c':
if (!strcmp(s, "opy")) return K_copy;
if (!strcmp(s, "lass")) return K_class;
if (!strcmp(s, "lass_start")) return K_class_start;
if (!strcmp(s, "lass_stop")) return K_class_stop;
if (!strcmp(s, "lass_reset")) return K_class_reset;
if (!strcmp(s, "onsole")) return K_console;
if (!strcmp(s, "hown")) return K_chown;
if (!strcmp(s, "hmod")) return K_chmod;
if (!strcmp(s, "ritical")) return K_critical;
break;
case 'd':
if (!strcmp(s, "isabled")) return K_disabled;
if (!strcmp(s, "omainname")) return K_domainname;
break;
case 'e':
if (!strcmp(s, "nable")) return K_enable;
if (!strcmp(s, "xec")) return K_exec;
if (!strcmp(s, "xport")) return K_export;
break;
case 'g':
if (!strcmp(s, "roup")) return K_group;
break;
case 'h':
if (!strcmp(s, "ostname")) return K_hostname;
break;
case 'i':
if (!strcmp(s, "oprio")) return K_ioprio;
if (!strcmp(s, "fup")) return K_ifup;
if (!strcmp(s, "nsmod")) return K_insmod;
if (!strcmp(s, "mport")) return K_import;
if (!strcmp(s, "nstallkey")) return K_installkey;
break;
case 'k':
if (!strcmp(s, "eycodes")) return K_keycodes;
break;
case 'l':
if (!strcmp(s, "oglevel")) return K_loglevel;
if (!strcmp(s, "oad_persist_props")) return K_load_persist_props;
if (!strcmp(s, "oad_all_props")) return K_load_all_props;
break;
case 'm':
if (!strcmp(s, "kdir")) return K_mkdir;
if (!strcmp(s, "ount_all")) return K_mount_all;
if (!strcmp(s, "ount")) return K_mount;
break;
case 'o':
if (!strcmp(s, "n")) return K_on;
if (!strcmp(s, "neshot")) return K_oneshot;
if (!strcmp(s, "nrestart")) return K_onrestart;
break;
case 'p':
if (!strcmp(s, "owerctl")) return K_powerctl;
break;
case 'r':
if (!strcmp(s, "estart")) return K_restart;
if (!strcmp(s, "estorecon")) return K_restorecon;
if (!strcmp(s, "estorecon_recursive")) return K_restorecon_recursive;
if (!strcmp(s, "mdir")) return K_rmdir;
if (!strcmp(s, "m")) return K_rm;
break;
case 's':
if (!strcmp(s, "eclabel")) return K_seclabel;
if (!strcmp(s, "ervice")) return K_service;
if (!strcmp(s, "etenv")) return K_setenv;
if (!strcmp(s, "etprop")) return K_setprop;
if (!strcmp(s, "etrlimit")) return K_setrlimit;
if (!strcmp(s, "ocket")) return K_socket;
if (!strcmp(s, "tart")) return K_start;
if (!strcmp(s, "top")) return K_stop;
if (!strcmp(s, "wapon_all")) return K_swapon_all;
if (!strcmp(s, "ymlink")) return K_symlink;
if (!strcmp(s, "ysclktz")) return K_sysclktz;
break;
case 't':
if (!strcmp(s, "rigger")) return K_trigger;
break;
case 'u':
if (!strcmp(s, "ser")) return K_user;
break;
case 'v':
if (!strcmp(s, "erity_load_state")) return K_verity_load_state;
if (!strcmp(s, "erity_update_state")) return K_verity_update_state;
break;
case 'w':
if (!strcmp(s, "rite")) return K_write;
if (!strcmp(s, "ritepid")) return K_writepid;
if (!strcmp(s, "ait")) return K_wait;
break;
}
return K_UNKNOWN;
}
调用这个函数的时候,我们传入的参数args[0]=”import”.显而易见该函数返回K_import。它是一个整数。返回以后使用kw_is函数看他是不是一个Section。当然是一个section了,import也是一个section。不信看代码:
#define kw_is(kw, type) (keyword_info[kw].flags & (type))keyword_info定义在system/core/init/keywords.h中:
...
KEYWORD(group, OPTION, 0, 0)
KEYWORD(hostname, COMMAND, 1, do_hostname)
KEYWORD(ifup, COMMAND, 1, do_ifup)
KEYWORD(import, SECTION, 1, 0)
...截取含有import的一部分代码,后面SECTION已经表明它是个Section了。KEYWORD自后一个参数是这个关键字对应的处理函数。比如这其中的hostname。如果你在init.rc中使用hostname 关键字,那么最终会调用do_hostname函数来处理。
既然import是一个section。那么parce_config就会调用state.parse_line函数,这里是一个函数指针,其实调用的是parse_line_no_op,不记得回去看下state的初始就知道了。
static void parse_line_no_op(struct parse_state*, int, char**) {
}这个函数是空的。接下来调用parse_new_section函数:
static void parse_new_section(struct parse_state *state, int kw,
int nargs, char **args)
{
printf("[ %s %s ]\\n", args[0],
nargs > 1 ? args[1] : "");
switch(kw) {
case K_service:
state->context = parse_service(state, nargs, args);
if (state->context) {
state->parse_line = parse_line_service;
return;
}
break;
case K_on:
state->context = parse_action(state, nargs, args);
if (state->context) {
state->parse_line = parse_line_action;
return;
}
break;
case K_import:
parse_import(state, nargs, args);
break;
}
state->parse_line = parse_line_no_op;
}
我们当然是执行case K_import:分支了,想都不用想。所以接下来执行parse_import方法:
static void parse_import(struct parse_state *state, int nargs, char **args)
{
struct listnode *import_list = (listnode*) state->priv;
char conf_file[PATH_MAX];
int ret;
if (nargs != 2) {
ERROR("single argument needed for import\\n");
return;
}
ret = expand_props(conf_file, args[1], sizeof(conf_file));
if (ret) {
ERROR("error while handling import on line '%d' in '%s'\\n",
state->line, state->filename);
return;
}
struct import* import = (struct import*) calloc(1, sizeof(struct import));
import->filename = strdup(conf_file);
list_add_tail(import_list, &import->list);
INFO("Added '%s' to import list\\n", import->filename);
}
这个函数首先使用expand_props方法对args[1]也就是“/init.environ.rc”做进一步处理。这个函数如下:
int expand_props(char *dst, const char *src, int dst_size)
{
char *dst_ptr = dst;
const char *src_ptr = src;
int ret = 0;
int left = dst_size - 1;
if (!src || !dst || dst_size == 0)
return -1;
/* - variables can either be $x.y or ${x.y}, in case they are only part
* of the string.
* - will accept $$ as a literal $.
* - no nested property expansion, i.e. ${foo.${bar}} is not supported,
* bad things will happen
*/
while (*src_ptr && left > 0) {
char *c;
char prop[PROP_NAME_MAX + 1];
char prop_val[PROP_VALUE_MAX];
int prop_len = 0;
int prop_val_len;
c = strchr(src_ptr, '$');
if (!c) {
while (left-- > 0 && *src_ptr)
*(dst_ptr++) = *(src_ptr++);
break;
}
...可以看出,这个函数的作用是拓展args[1].这里不需要拓展,因为我们的args[1]=”/init.environ.rc”没有$符号,所以直接就跳出循环了。这里应该是对那些有包含变量的字符串,把变量的内容展开。
然后构建了一个import结构体。import中的filename项赋值为”/init.environ.rc”.并把它加入到import_list链表中。
import定义如下:
struct import {
struct listnode list;
const char *filename;
};这样,第一行就分析完了,从而我们也彻底明白了怎么解析一个import 的section。
只要能看懂一个,其他的就简单了。因为,他们都是类似的。
service的解析与启动
service的解析
和import解析过程类似,遇到service关键字后,service关键字和后面的参数会保存在args[]数组中。然后通过对args[0]提取关键字,发现args[0]=”service”,于是开始执行parse_new_section函数。此时这个函数必然会进入 case K_service:分支执行:
case K_service:
state->context = parse_service(state, nargs, args);
if (state->context) {
state->parse_line = parse_line_service;
return;
}
break;这里做了两件事情非常重要,一件是调用parse_service解析service这个section。另一件事情是给state->parse_line赋值为parse_line_service。也就是service 关键字所在的行后面的那些options行都是使用parse_line_service函数来解析的。我们从parse_service看起:
static void *parse_service(struct parse_state *state, int nargs, char **args)
{
if (nargs < 3) {
parse_error(state, "services must have a name and a program\\n");
return 0;
}
if (!valid_name(args[1])) {
parse_error(state, "invalid service name '%s'\\n", args[1]);
return 0;
}
service* svc = (service*) service_find_by_name(args[1]);
if (svc) {
parse_error(state, "ignored duplicate definition of service '%s'\\n", args[1]);
return 0;
}
nargs -= 2;
svc = (service*) calloc(1, sizeof(*svc) + sizeof(char*) * nargs);
if (!svc) {
parse_error(state, "out of memory\\n");
return 0;
}
svc->name = strdup(args[1]);
svc->classname = "default";
memcpy(svc->args, args + 2, sizeof(char*) * nargs);
trigger* cur_trigger = (trigger*) calloc(1, sizeof(*cur_trigger));
svc->args[nargs] = 0;
svc->nargs = nargs;
list_init(&svc->onrestart.triggers);
cur_trigger->name = "onrestart";
list_add_tail(&svc->onrestart.triggers, &cur_trigger->nlist);
list_init(&svc->onrestart.commands);
list_add_tail(&service_list, &svc->slist);
return svc;
}可以看到和import做的事情差不多。import解析的最后,会创建一个import结构体,并把它添加到import_list双向链表中。service解析从这里看,也是构建一个service结构体,然后把service结构体添加到service_list链表中。
我们看下service结构体:
struct service {
void NotifyStateChange(const char* new_state);
/* list of all services */
struct listnode slist;
char *name;
const char *classname;
unsigned flags;
pid_t pid;
time_t time_started; /* time of last start */
time_t time_crashed; /* first crash within inspection window */
int nr_crashed; /* number of times crashed within window */
uid_t uid;
gid_t gid;
gid_t supp_gids[NR_SVC_SUPP_GIDS];
size_t nr_supp_gids;
const char* seclabel;
struct socketinfo *sockets;
struct svcenvinfo *envvars;
struct action onrestart; /* Actions to execute on restart. */
std::vector<std::string>* writepid_files_;
/* keycodes for triggering this service via /dev/keychord */
int *keycodes;
int nkeycodes;
int keychord_id;
ioschedClass ioprio_class;
int ioprio_pri;
int nargs;
/* "MUST BE AT THE END OF THE STRUCT" */
char *args[1];
}; /* socketinfo 用来保存socket option的相关信息。
classname 给service定义一个类名,如果多个service使用相同的类型,可以方便进行批量操作。
nargs 保存参数的个数。
很多字段不理解,没关系,我们看看parse_service函数给service做了那些初始化:
1. svc->name = strdup(args[1]);名字就是service 关键字后面的第一个参数
2. svc->classname = “default”; 类别名是default
3. memcpy(svc->args, args + 2, sizeof(char*) * nargs); svc->args[nargs] = 0;
把所有参数保存在args数组中,并把最有一个成员只为0。
4. svc->nargs = nargs; nargs保存参数个数
5. trigger* cur_trigger = (trigger*) calloc(1, sizeof(*cur_trigger));
list_init(&svc->onrestart.triggers);
cur_trigger->name = “onrestart”;
list_add_tail(&svc->onrestart.triggers, &cur_trigger->nlist);
构建一个触发器,并把它添加到service中的onrestart.triger列表中。
因此,我们可以知道么一个service都会有一个onrestart的action,这个action有一个触发器。这个action用来重启service。
解析完service后,就会解析service后面的option了,这个时候会调用parse_line_service。
static void parse_line_service(struct parse_state *state, int nargs, char **args)
{
struct service *svc = (service*) state->context;
struct command *cmd;
int i, kw, kw_nargs;
if (nargs == 0) {
return;
}
svc->ioprio_class = IoSchedClass_NONE;
kw = lookup_keyword(args[0]);
switch (kw) {
case K_class:
if (nargs != 2) {
pars以上是关于Android6.0系统启动流程分析一:init进程的主要内容,如果未能解决你的问题,请参考以下文章