HashMap为啥不安全?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HashMap为啥不安全?相关的知识,希望对你有一定的参考价值。
原因:
JDK1.7 中,由于多线程对HashMap进行扩容,调用了HashMap#transfer(),具体原因:某个线程执行过程中,被挂起,其他线程已经完成数据迁移,等CPU资源释放后被挂起的线程重新执行之前的逻辑,数据已经被改变,造成死循环、数据丢失。
JDK1.8 中,由于多线程对HashMap进行put操作,调用了HashMap#putVal(),具体原因:假设两个线程A、B都在进行put操作,并且hash函数计算出的插入下标是相同的,当线程A执行完第六行代码后由于时间片耗尽导致被挂起,而线程B得到时间片后在该下标处插入了元素,完成了正常的插入,然后线程A获得时间片,由于之前已经进行了hash碰撞的判断,所有此时不会再进行判断,而是直接进行插入,这就导致了线程B插入的数据被线程A覆盖了,从而线程不安全。
改善:
数据丢失、死循环已经在在JDK1.8中已经得到了很好的解决,如果你去阅读1.8的源码会发现找不到HashMap#transfer(),因为JDK1.8直接在HashMap#resize()中完成了数据迁移。
2、HashMap线程不安全的体现:
JDK1.7 HashMap线程不安全体现在:死循环、数据丢失
JDK1.8 HashMap线程不安全体现在:数据覆盖
二、HashMap线程不安全、死循环、数据丢失、数据覆盖的原因
1、JDK1.7 扩容引发的线程不安全
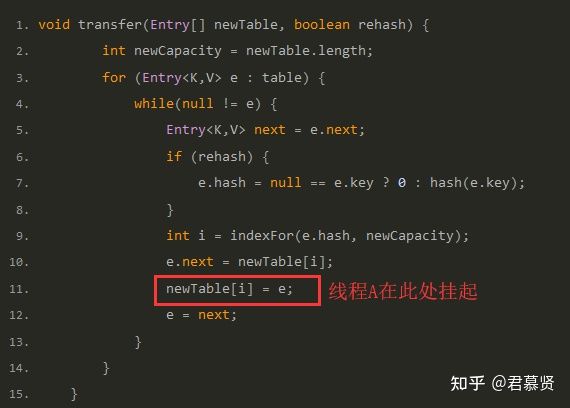
HashMap的线程不安全主要是发生在扩容函数中,其中调用了JDK1.7 HshMap#transfer():
void transfer(Entry[] newTable, boolean rehash)int newCapacity = newTable.length;
for (Entry<K,V> e : table)
while(null != e)
Entry<K,V> next = e.next;
if (rehash)
e.hash = null == e.key ? 0 : hash(e.key);
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
复制代码
这段代码是HashMap的扩容操作,重新定位每个桶的下标,并采用头插法将元素迁移到新数组中。头插法会将链表的顺序翻转,这也是形成死循环的关键点。理解了头插法后再继续往下看是如何造成死循环以及数据丢失的。
2、扩容造成死循环和数据丢失
假设现在有两个线程A、B同时对下面这个HashMap进行扩容操作:
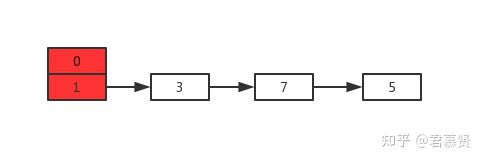
正常扩容后的结果是下面这样的:
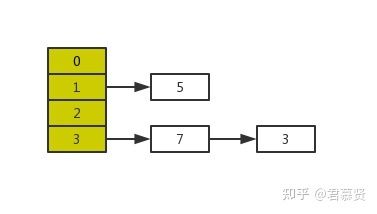
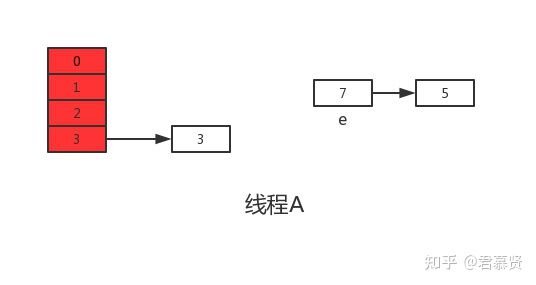
但是当线程A执行到上面transfer函数的第11行代码时,CPU时间片耗尽,线程A被挂起。即如下图中位置所示:
此时线程A中:e=3、next=7、e.next=null
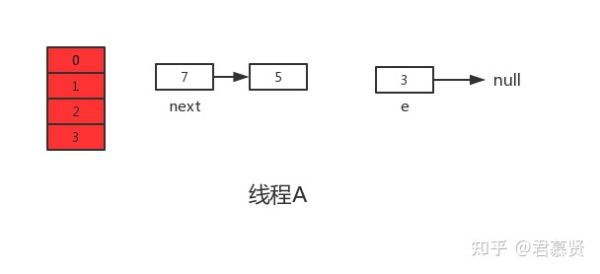
当线程A的时间片耗尽后,CPU开始执行线程B,并在线程B中成功的完成了数据迁移
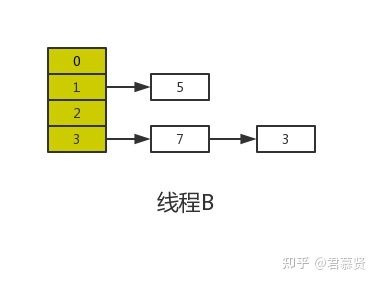
重点来了,根据Java内存模式可知,线程B执行完数据迁移后,此时主内存中newTable和table都是最新的,也就是说:7.next=3、3.next=null。
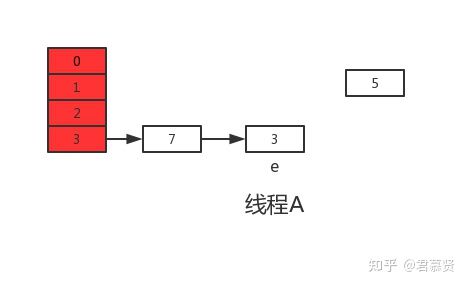
随后线程A获得CPU时间片继续执行newTable[i] = e,将3放入新数组对应的位置,执行完此轮循环后线程A的情况如下:
接着继续执行下一轮循环,此时e=7,从主内存中读取e.next时发现主内存中7.next=3,此时next=3,并将7采用头插法的方式放入新数组中,并继续执行完此轮循环,结果如下:
此时没任何问题。
上轮next=3,e=3,执行下一次循环可以发现,3.next=null,所以此轮循环将会是最后一轮循环。
接下来当执行完e.next=newTable[i]即3.next=7后,3和7之间就相互连接了,当执行完newTable[i]=e后,3被头插法重新插入到链表中,执行结果如下图所示:
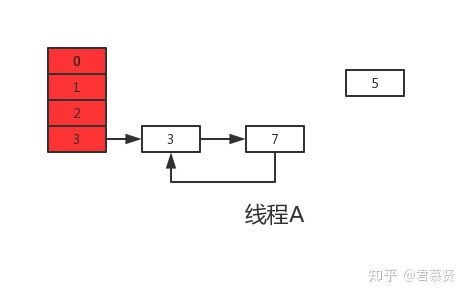
上面说了此时e.next=null即next=null,当执行完e=null后,将不会进行下一轮循环。到此线程A、B的扩容操作完成,很明显当线程A执行完后,HashMap中出现了环形结构,当在以后对该HashMap进行操作时会出现死循环。
并且从上图可以发现,元素5在扩容期间被莫名的丢失了,这就发生了数据丢失的问题。
3、JDK1.8中的线程不安全
上面的扩容造成的数据丢失、死循环已经在在JDK1.8中已经得到了很好的解决,如果你去阅读1.8的源码会发现找不到HashMap#transfer(),因为JDK1.8直接在HashMap#resize()中完成了数据迁移。
为什么说 JDK1.8会出现数据覆盖的情况? 我们来看一下下面这段JDK1.8中的put操作代码:
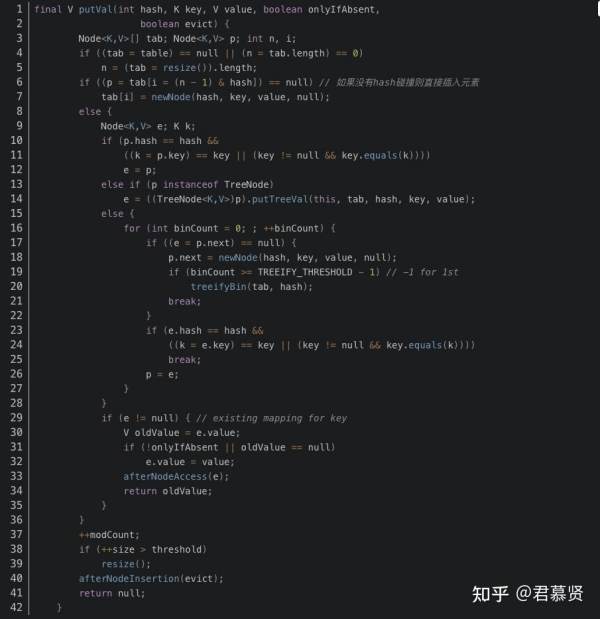
其中第六行代码是判断是否出现hash碰撞,假设两个线程A、B都在进行put操作,并且hash函数计算出的插入下标是相同的,当线程A执行完第六行代码后由于时间片耗尽导致被挂起,而线程B得到时间片后在该下标处插入了元素,完成了正常的插入,然后线程A获得时间片,由于之前已经进行了hash碰撞的判断,所有此时不会再进行判断,而是直接进行插入,这就导致了线程B插入的数据被线程A覆盖了,从而线程不安全。
除此之前,还有就是代码的第38行处有个++size,我们这样想,还是线程A、B,这两个线程同时进行put操作时,假设当前HashMap的zise大小为10,当线程A执行到第38行代码时,从主内存中获得size的值为10后准备进行+1操作,但是由于时间片耗尽只好让出CPU,线程B快乐的拿到CPU还是从主内存中拿到size的值10进行+1操作,完成了put操作并将size=11写回主内存,然后线程A再次拿到CPU并继续执行(此时size的值仍为10),当执行完put操作后,还是将size=11写回内存,此时,线程A、B都执行了一次put操作,但是size的值只增加了1,所有说还是由于数据覆盖又导致了线程不安全。
三、如何使HashMap在多线程情况下进行线程安全操作?
使用 Collections.synchronizedMap(map),包装成同步Map,原理就是在HashMap的所有方法上synchronized。
例如:Collections.SynchronizedMap#get()
public V get(Object key)synchronized (mutex)
return m.get(key);
复制代码
四、总结
1、HashMap线程不安全原因:
原因:
JDK1.7 中,由于多线程对HashMap进行扩容,调用了HashMap#transfer(),具体原因:某个线程执行过程中,被挂起,其他线程已经完成数据迁移,等CPU资源释放后被挂起的线程重新执行之前的逻辑,数据已经被改变,造成死循环、数据丢失。
JDK1.8 中,由于多线程对HashMap进行put操作,调用了HashMap#putVal(),具体原因:假设两个线程A、B都在进行put操作,并且hash函数计算出的插入下标是相同的,当线程A执行完第六行代码后由于时间片耗尽导致被挂起,而线程B得到时间片后在该下标处插入了元素,完成了正常的插入,然后线程A获得时间片,由于之前已经进行了hash碰撞的判断,所有此时不会再进行判断,而是直接进行插入,这就导致了线程B插入的数据被线程A覆盖了,从而线程不安全。
改善:
数据丢失、死循环已经在在JDK1.8中已经得到了很好的解决,如果你去阅读1.8的源码会发现找不到HashMap#transfer(),因为JDK1.8直接在HashMap#resize()中完成了数据迁移。
2、HashMap线程不安全的体现:
JDK1.7 HashMap线程不安全体现在:死循环、数据丢失
JDK1.8 HashMap线程不安全体现在:数据覆盖
2. 参考技术B Map概述 我们都知道HashMap是线程不安全的,但是HashMap的使用频率在所有map中确实属于比较高的。因为它可以满足我们大多数的场景了。 Map类继承图 复制代码 Map是一个接口,我们常用的实现类...
2.HashMap的实现 java7和java8在实现HashMap上有所区别,当然java8的效率要更好一些,主要是java8的HashMap在java7的基础上增加了红黑树这种数据结构,使得在桶里面查找数据的...
以上是关于HashMap为啥不安全?的主要内容,如果未能解决你的问题,请参考以下文章
[笔记]为啥hashmap查询速度快? 如何理解hashmap的散列?