java-raft框架之atomix进行分布式管理
Posted 水中加点糖
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了java-raft框架之atomix进行分布式管理相关的知识,希望对你有一定的参考价值。
共识算法
在一个分布式的系统中,管理各个节点的一致性(共识)一直是个很有难度的问题。
在近几十年的发展中,于1990年诞生的Paxos算法是其中最为经典的代表,并一统江湖数几十载。
如著名的zookeeper、chubby都是基于Paxos算法的经典应用。
不过Paxos算法的复杂度和难以理解性,也吸引了一些大佬想让它变得更加简单。
为此,以简单和易理解为目标的Raft算法便于2014年横空出世。
其Raft论文地址为:https://web.stanford.edu/~ouster/cgi-bin/papers/raft-atc14
为了快速了解,也通过结合https://raft.github.io/中的动画演示快速了解。
尽管Raft算法的发布时间较短,不过它的具体落地方面可谓是百花齐放,如K8S中的etcd就是使用raft算法实现的代表应用。
atomix框架
atomix是一个基于raft算法,使用java语言进行实现的一个分布式框架,可以运用在各种分布式场景中。
更多关于atomix的相关介绍,可以在对应的github中找到:https://github.com/atomix/atomix-archive
需要注意的是:基于java的atomix现已停止维护,这里仅用作学习目的,在分布式系统中体验一下。
本文选用的atomix版本为最新的3.1.12版本。https://github.com/atomix/atomix-archive/releases/tag/atomix-3.1.12
所对应的maven依赖为:
<atomix.version>3.1.12</atomix.version>
<dependency>
<groupId>io.atomix</groupId>
<artifactId>atomix</artifactId>
<version>$atomix.version</version>
</dependency>
<dependency>
<groupId>io.atomix</groupId>
<artifactId>atomix-raft</artifactId>
<version>$atomix.version</version>
</dependency>
下面以在分布式系统中的常见场景,来快速掌握下atomix的用法
数据存储
使用atomix进行数据存储与查询
package io.github.puhaiyang;
import io.atomix.cluster.ClusterMembershipService;
import io.atomix.cluster.Member;
import io.atomix.cluster.discovery.BootstrapDiscoveryProvider;
import io.atomix.core.Atomix;
import io.atomix.core.election.AsyncLeaderElector;
import io.atomix.core.map.AsyncAtomicMap;
import io.atomix.primitive.Recovery;
import io.atomix.protocols.raft.MultiRaftProtocol;
import io.atomix.protocols.raft.partition.RaftPartitionGroup;
import io.atomix.utils.time.Versioned;
import java.io.File;
import java.time.Duration;
import java.util.Collections;
import java.util.List;
import java.util.Set;
import java.util.concurrent.CompletableFuture;
public class ClusterTest
private static String LOCAL_DATA_DIR = "db/partitions/";
private static String groupName = "raft";
private static Integer MAX_RETRIES = 5;
public static void main(String[] args) throws Exception
Atomix atomix = buildAtomix();
//atomix启动并加入集群
atomix.start().join();
//创建atomixMap
AsyncAtomicMap<Object, Object> asyncAtomicMap = atomix.atomicMapBuilder("myCfgName")
.withProtocol(MultiRaftProtocol.builder(groupName)
.withRecoveryStrategy(Recovery.RECOVER)
.withMaxRetries(MAX_RETRIES)
.build())
.withReadOnly(false)
.build()
.async();
//进行数据存储
asyncAtomicMap.put("myBlog", "https://puhaiyang.blog.csdn.net");
//进行查询
CompletableFuture<Versioned<Object>> myBlog = asyncAtomicMap.get("myBlog");
Versioned<Object> objectVersioned = myBlog.get();
System.out.printf("value:%s version:%s%n", objectVersioned.value(), objectVersioned.version());
private static Atomix buildAtomix()
List<String> raftMembers = Collections.singletonList("node1");
//创建atomix
return Atomix.builder(ClusterTest.class.getClassLoader())
.withClusterId("my-cluster")
.withMemberId("node1")
.withHost("127.0.0.1")
.withPort(6789)
.withMembershipProvider(BootstrapDiscoveryProvider.builder().build())
.withManagementGroup(RaftPartitionGroup.builder("system")
.withNumPartitions(1)
.withDataDirectory(new File(LOCAL_DATA_DIR, "system"))
.withMembers(raftMembers)
.build())
.addPartitionGroup(RaftPartitionGroup.builder(groupName)
.withNumPartitions(raftMembers.size())
.withDataDirectory(new File(LOCAL_DATA_DIR, "data"))
.withMembers(raftMembers)
.build())
.build();
输出结果为:
value:https://puhaiyang.blog.csdn.net version:4
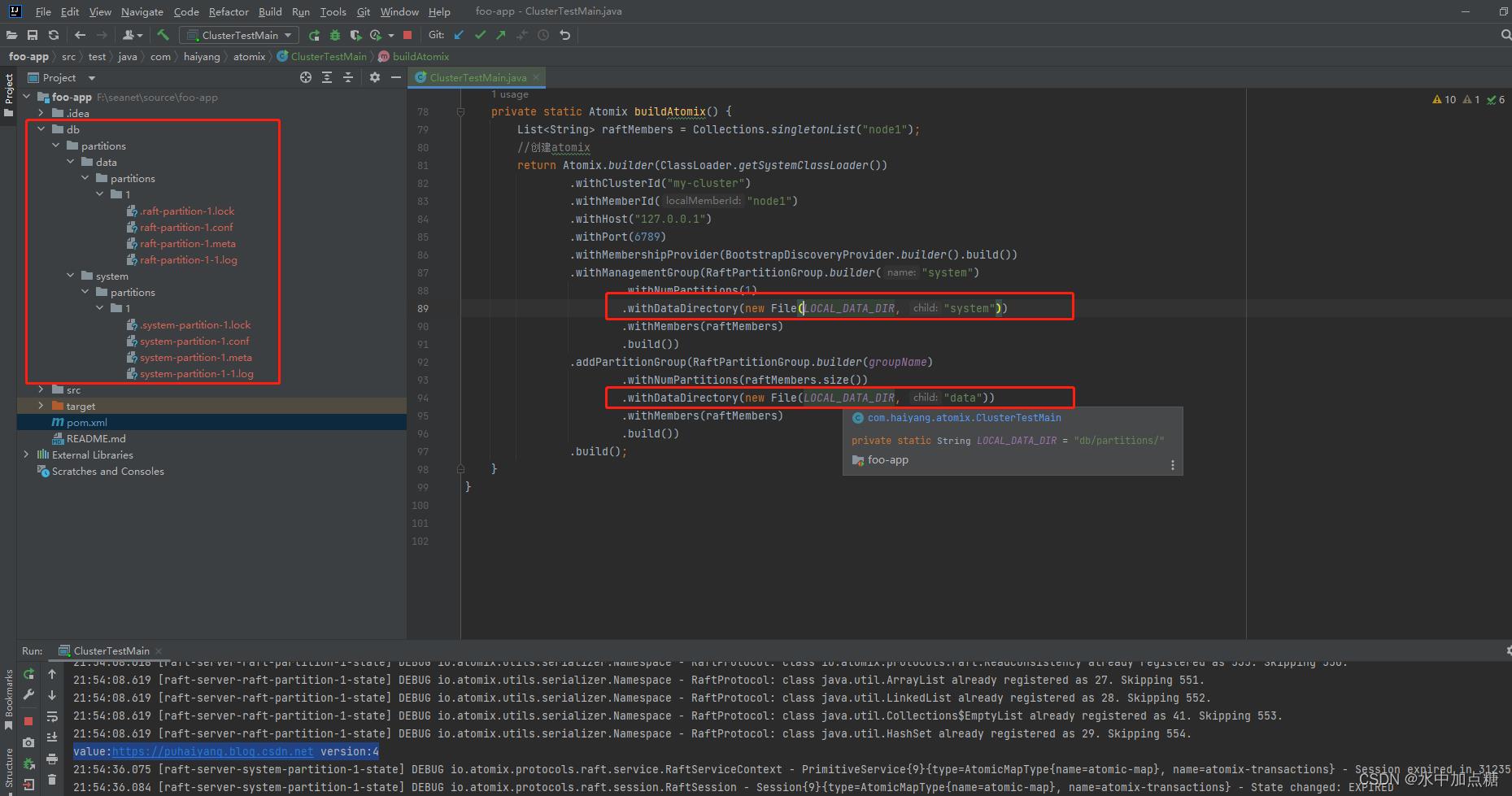
运行成功后,会在程序根目录下生成对应的数据文件。
如上面代码中指定的文件路径为:db/partitions/data和db/partitions/system,则会将数据持久化到上面的目录中
leader选举
除了上面的map存储外,leader选举也是分布式系统中经常用到:
AsyncLeaderElector leaderElector = atomix.leaderElectorBuilder("leader")
.withProtocol(MultiRaftProtocol.builder(groupName)
.withRecoveryStrategy(Recovery.RECOVER)
.withMaxRetries(MAX_RETRIES)
.withMaxTimeout(Duration.ofMillis(15000L))
.build())
.withReadOnly(false)
.build()
.async();
//获取出当前节点
Member localMember = atomix.getMembershipService().getLocalMember();
System.out.println("localMember:" + localMember.toString());
String topic = "this is a topic";
//根据某一topic选举出leader,返回的是选举为leader的节点
Leadership leadership = (Leadership) leaderElector.run(topic, localMember.toString()).get();
System.out.println("==========" + leadership);
//get leadership
Leadership topicLeadership = (Leadership) leaderElector.getLeadership(topic).get();
System.out.println("------------>" + topicLeadership);
//输出所有的topic对应的leader
Map topicLeadershipMaps = (Map) leaderElector.getLeaderships().get();
System.out.println("++++++++++++" + topicLeadershipMaps.toString());
输出结果为:
localMember:Memberid=node1, address=127.0.0.1:6789, host=127.0.0.1, properties=
==========Leadershipleader=Leaderid=Memberid=node1, address=127.0.0.1:6789, host=127.0.0.1, properties=, term=1, termStartTime=1675088739669, candidates=[Memberid=node1, address=127.0.0.1:6789, host=127.0.0.1, properties=]
------------>Leadershipleader=Leaderid=Memberid=node1, address=127.0.0.1:6789, host=127.0.0.1, properties=, term=1, termStartTime=1675088739669, candidates=[Memberid=node1, address=127.0.0.1:6789, host=127.0.0.1, properties=]
++++++++++++this is a topic=Leadershipleader=Leaderid=Memberid=node1, address=127.0.0.1:6789, host=127.0.0.1, properties=, term=1, termStartTime=1675088739669, candidates=[Memberid=node1, address=127.0.0.1:6789, host=127.0.0.1, properties=]
总结
atomix的api远不止本例中的两个,还有其他很多的api。
如分布式锁、分布式事务、分布式自增id、分布式队列、分布式信息号等,这些在atomix中都有实现,详细可见atomix的类方法:
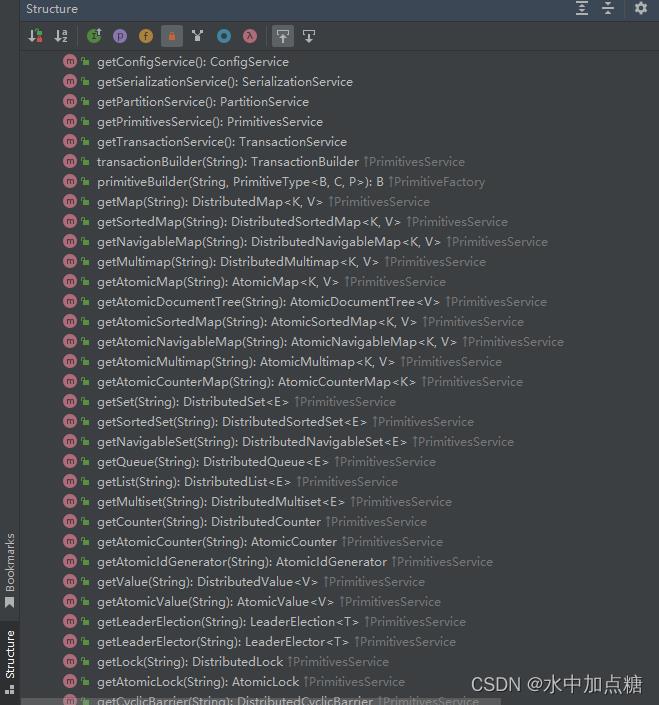
也正如当前所说,当前基于JAVA实现的atomix已经停止维护了。
如果要在生产环境中使用atomix,可以移步atomix的官网,获取在k8s环境下的新版atomix的使用方式,依然很强大。
参考链接
https://baymaxhuang.github.io/2017/06/14/Kryo序列化及其在ONOS中的应用/
以上是关于java-raft框架之atomix进行分布式管理的主要内容,如果未能解决你的问题,请参考以下文章