JackHttp -- 浅谈编码加密(对称加密,非对称加密,Hash算法)
Posted JackWaiting
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JackHttp -- 浅谈编码加密(对称加密,非对称加密,Hash算法)相关的知识,希望对你有一定的参考价值。
如果你还不清楚 JackHttp 是什么,请戳这里!!!
JackHttp 是一个网络框架系列,为什么还要分享编码和加密呢?主要有如下几个原因:
- HTTP 在网络传输过程中是明文的。
- HTTP 在网络传输过程中内容有可能被中间商篡改的。
- 浏览器,服务器都要求 HTTP 2.0 基于 HTTPS,而 HTTPS 使用到对称加密,非对称加密,Hash 算法。
- 编码和加密在我们 URL 文字编码、HTTPS 连接,TCP 连接中都经常使用。
带着这 4 个原因,开始我们今天的内容。
编码
很遗憾,说起来你可能不信,编码的定义从计算机发展至今,还没有一个完整的官方定义,(如果你有找到,请一定要告知我,感谢!)
但借助一些相对权威的机构定义及自己对编码的理解,浅谈一些编码相关的知识。
什么是编码?
编码是任意一种数据从一种形式或格式转换为另一种形式或格式,并且支持转换回来的过程。
Base64
好像很熟悉,但具体让我们说说 Base64 是啥?可能又说不上来,那么我问几个问题,大家思考下。
- Base64 是编码吗?
- Base64 是加密吗?(平时应该听过 Base64 加密这种说法吧)
- Base64 转换后的数据会变的更加安全吗?
- 使用 Base64 能提高效率吗?
- 为什么使用 Base64 ,Base64 的使用场景有哪些?
希望读者可以简单思考后,再阅读下文。
什么是 Base64?
将二进制数据转换成由 64 个字符组成的字符串编码算法。
具体由以下 64 个字符组成。

包含 “大写的 A -> Z 26 个字母 , 小写的 a -> z 26 个字母, 阿拉伯数字 0 -> 9 10个数字,运算符 + /” 共 64 个可见字符 。
了解到这里你可能会比较奇怪,为什么一定要用 64 个字符呢?
Base128 ,Base256 , Base32 不行吗?
ok,那么我们来弄明白 Base64 的编码原理,以上问题都将得到答案。
Base64 编码原理
例如我们需要对字符串 “Jack” 进行 Base64 编码,步骤如下:
-
将 "Jack " 拆分成 "J "、"a "、"c "、"k " 4 个字符,并获取到每个字符的 ASCII 码值。
通过 ASCII 码对照表 我们可以获取到 "J "、"a "、"c "、“k " 的 ASCII 码值对应为"74”、"97 "、“99”、"107 "。 -
Base64 是对二进制数据进行转换,所以我们需要将 ASCII 码值转换成对应的二进制数据,“01001010”、"01100001 "、“01100011”、“01101011”。
-
对二进制数据进行读取,为了确保转换后的任意数据都能用 64 个字符表表示出来,我们对二进制数据进行排列组合,如下图:

组合后会发现,64 个字母的字母表,最多可对应 26,也就是 Base64 一次转换读取最多只能读取 6 Bit,否则就有可能造成部分转换后的字符无法正常显示,出现乱码,转换后数据如下图:

解释: 一个英文字母占一个字节,一个字节占 8 Bit。
-
将转换后获得的二进制数据转换成 Base64 字符表中的“十进制索引”,然后对应 Base64 字符表索引取出索引值,以此获取最终转换后的数据。
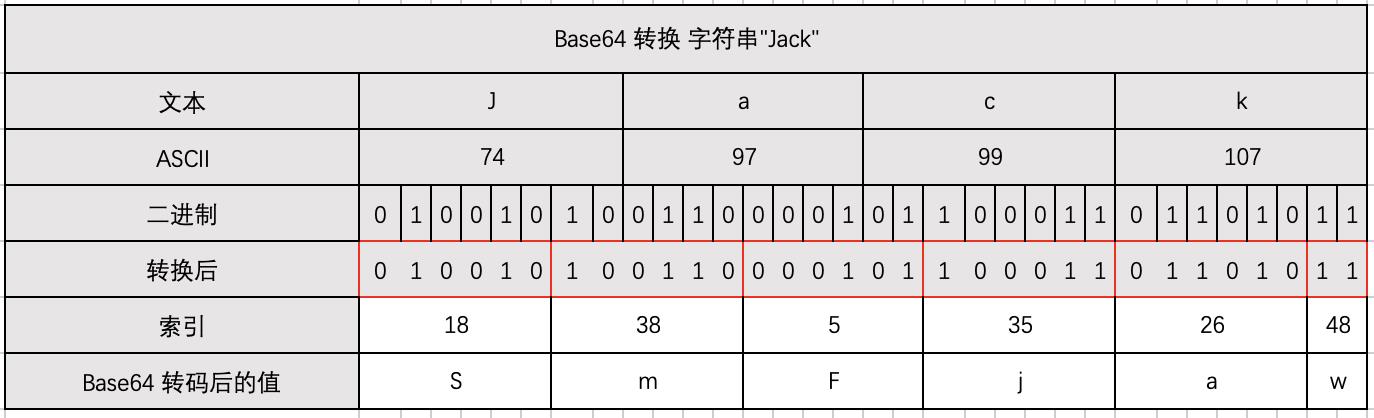
注意:最后 1 位 Bit 数据读取如果如果长度< 6 ,则补 0 ,例子中最后的 “11”,转成十进制前的数据补码后的值为"110000 "。
以上就是Base64 最核心的转码原理,OK,说的好像是那么回事,验证下,看下结果是不是对的。
public static void main(String[] args)
String encoderStr = "Jack";
BASE64Encoder encoder = new BASE64Encoder();
System.out.println("Jack Base64 转换后的结果:" +
encoder.encode(encoderStr.getBytes()));
输出的结果
Jack Base64 转换后的结果:SmFjaw==
结果确实跟我们推导出来的一样,但是输出的结果后面还跟着2个 " = = " 是什么意思呢?
其实他仅仅是一个位数补齐标记,是为了方便后面做解码的时候使用的,我们观察上面的转码过程发现,编码前每 3 个字节的 3* 8 = 24Bit 解码后刚好 24 / 6 = 4 个字节。
Base64 转码前每 3 个字节转码后会变成 4 个字节,而 4个字节是 Base64 编码的最小单元,也就是说我们任何一个数据进行 Base64 编码后都是 4 的倍数,而我们本例中对应字符表解码出来的数据是“SmFjaw”只有 6 个字节,怎么办? Base64 就想到用 “= =” 进行补齐,解码时以 4 个字节为最小单元进行解码,明白了吧?
Base64 解码原理
完全的逆向,通过字符表获取 “SmFjaw==” 索引再转换成 6 Bit 的二进制数据,然后在逆向转成 8 Bit 二进制数据,最后通过 ASCII 码值得到转换前的 “Jack” 。
Base64 问题解答
弄明白了原理,我们再来回答之前提出的问题。
-
为什么一定要用 64 个字符呢?Base128 ,Base256 , Base32 不行吗?为什么定义 Base64?
-
-
按照 Base64 的原理,如果一次读取 8 Bit,那么转换后的数据,不就不会改变原数据的长度了吗?为什么不用 Base256?
因为 ASCII 的基础码是用 7 Bit 组成的,最多只有 128 个字符, 而要读取 8 Bit 至少需要 256 个可见字符才能完全表示,从文本转成 ASCII 码值数量都不够,这显然行不通。拓展:有人想到过用颜色来代表不同的 Base64 算法,把 Base64 分成不同的 4 组颜色,听上去确实可行,但其实并没有什么意义,对解码效率不会有任何提升。
-
而不使用 Base128 的原因也大同小异,在 ASCII 字符集中虽然有 128 个字符,但并不是所有的字符都是可见的,例如 “NUT”,“SOH” 等,如果用 128 个字符在转换后也就会出现我们所看到的乱码。
-
那么为什么不用 Base32 呢?
效率嘛,能读取 6 Bit ,为什么还要去读取 5 Bit 甚至更少呢,这不浪费效率和带宽嘛。
-
这也是为什么会定义出 Base64 的核心原因。
-
Base64 是编码吗?
-
很明显是的,他可以使数据从一种格式变为另一种格式且可以解码回原始数据。
Base64 是加密吗?(平时应该听过 Base64 加密这种说法吧)
-
讲完加密我在回答你,请关注文末。
Base64 转换后的数据会变的更加安全吗?
-
搞懂了原理,应该清楚了吧? 整个编码和解码的流程都是公开可见且很容易推敲,怎么会更安全呢?安全个锤子。
使用 Base64 能提高效率吗?
-
Base64 编码每个最小单元都会把 3 个字节转换成 4 个字节,文本大小增加 33%,更高效?假设我们现在有一个 2.4M 的图片,服务器对其 Base64 编码后再传输,会编码成一个 3.2M 的文本。
Are you kiding me? 大小增加了 800K,你跟我说更高效了?这得多浪费带宽,因此你们公司的后台开发人员不到万不得已的情况下,还在使用 Base64 对图片进行编码传输,你可以开始怼他了,开个玩笑。
那么 Base64 的使用场景有哪些呢?
-
再电子邮件刚开始发展的时候,只能传输英文,但随着时代的发展,电子邮件需要支持更多国家的语言以及传输图片,甚至是视频文件,而当时的服务器、网关并不支持传输图片和视频,怎么办?Base64 就诞生了。
因此 Base64 他的应用场景主要有以下几点:- 我们所开发的系统并不支持大文件传输,例如:图片、视频。系统在没有更好选择的情况下,需要对其进行 Base64 编码转换成文本,再进行网络传输。
- 对小的文件或文本数据进行 Base64 编码,以达到不同端的兼容性。小文本的编码性能损失可以降到最低。
ok,之所以这么详细的介绍 Base64 编码,是因为大部分常见的编码原理基本和 Base64 一致,只是不同的编码其的核心算法会有些改变,你搞懂了 Base64 的原理,弄清楚什么是编码,在反过推敲其它的编码原理,将可以举一反三,so easy!
最后我在罗列一下我们常见的编码还有哪些:
| 编码 | 说明 | 算法 |
|---|---|---|
| URL Encoding | 将 URL 中保留的字符使用“%”进行编码 | 核心算法跟 Base64 一致 |
| 压缩和解压缩 | 把数据换一种形式来存储,以达到减小存储内存的目的 | DEFLATE(gzip、zip)、JEPG、MP3、MP4 |
| 媒体数据的编码 | 把二进制图片数据转换成 JPG、PNG的格式 | JPG、PNG |
| 字符集编码 | 计算机要准确的处理各种字符集文字,就需要进行字符编码,以便计算机能够识别和存储各种文字 | ASCII、ISO-8859-1、Unicode、UTF-8、UTF-16、GBK、GB2312、GB18030 |
什么是加密?
加密是以某种特殊的算法改变原有的数据,使我们无法理解其明文的含义,并通过秘钥可以还原到原始数据的过程。
加密的诞生
加密算法的前十今生,如要要开始追溯,得从古代战争–古典密码学说起。
在古代战争中,情报作为战事中最大的要素,决定着一场战争的胜负。
在大型战争中,由于部队较多,指挥无法直接对每支部队下达命令,所以常常需要信使来传递重要的军事情报。
可是,你要知道,依靠信使来传递军情并不安全:一旦信使被敌军抓获,重要的军事情报就完全被敌方知悉了。
届时,借用三国曹操的一句话“尔等无需反抗,下马受死”。
在这样的背景下,就诞生了人类历史上第一种加密算法 – 凯撒密码,他使用的是一种
位移式加密,就像这样:
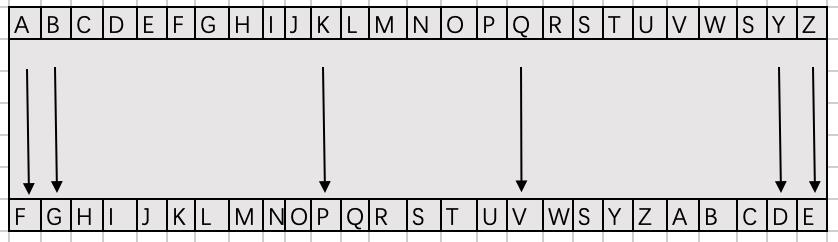
把每个字母向后移动 5 位,然后在交给信使。军队拿到后在移回来 5 位,得到真实的数据。
还是拿三国举例:
现在曹操发送军令攻打 “Jin Gong Jingzhou” 转码后的数据给到信使就变成了 “OTS LTSL ONSLEMTZ” 。即使信使被抓了,也看不懂吧?在这个故事中,解密的秘钥就是“将字母位移 5 位”。
但随着时间的发展,敌人慢慢的也会破解这段不懂的秘钥,因此再今后的发展过程中,加密的算法变的越来越复杂,破解加密的算法也同步再发展壮大,也就是道高一尺,魔高一尺。
直到有一天,计算机的出现,彻底打破了加密算法的平衡,在计算机的强大的计算面前,之前定义的算法都将灰飞烟灭。于是,更高级的加密算法应运而生。
现代密码学的时代开启,基于当时的使用场景和需求,首先诞生的现代密码学是对称加密算法。
对称加密
对称加密核心原理:
使用秘钥和加密算法对数据进行转换,得到加密后的看不懂的密文数据,使用秘钥和解密算法对密文进行逆向转换,得到原始数据。

经典的对称加密算法有 2 种:
DES(Data Encryption Standard): 数据加密标准,速度较快。
AES(Advanced Encryption Standard): 高级加密标准,是当今的加密算法标准,速度快,安全级别高。
他们的底层原理基本是一样的,AES 的诞生主要是因为 DES 的秘钥太短,很容易被暴利破解。(暴利破解指的是用枚举法一个一个秘钥的尝试)
因此 DES 发展至今基本被弃用了,大部分的对称加密,目前都使用 AES 。
但随着时间和计算机的发展,AES 也会有被弃用的那一天,取而代之的将是更加安全的加密标准。
AES 算法基础原理
AES 算法原理是基于排列和置换运算。排列是对数据重新进行安排,置换是将一个数据单元替换为另一个。同时 AES 还会使用几种不同的方法来执行排列和置换运算,提高破解难度。
(它可以使用 128、192 和 256 位不同的密钥长度分组加密和解密数据。)
对称加密的弊端
-
虽然对称加密的算法公开、计算量小、加密速度快、加密效率高。但我们发现由于通信双方用到的是同一个密钥,如果其中一方的密钥遭泄露,那么整个通信就会被破解。
-
每个用户与其他用户使用对称加密算法时,都需要使用仅限双方知道的唯一密钥,随着每个用户通信对象的增加,用户所拥有的密钥数量会越来越大,因此密钥管理成为用户的负担。
-
对称加密无法用于签名与签名验证。
在这种弊端下于是衍生出非对称加密。
非对称加密
非对称加密与对称加密最大的区别是,非对称加密拥有两把钥匙,一把公钥,一把私钥。
非对称加密核心原理:
使用公钥和加密算法对数据进行转换,得到加密后的看不懂的密文数据,使用私钥和相同的加密算法对密文进行逆向转换,得到原始数据。

非对称加密的优势?
- 我们来想想,现在我们团队开发了一个平台,会有很多客户跟我们服务器进行通信,考虑到数据安全,如果使用对称加密,我们就需要给每一个用户发送一个私钥,通信时,在取出对应的私钥解密获取原数据,对吧?这将没有任何问题,但假设我们的用户达到了 1 个亿,我们是不是需要维护1 亿个私钥?而且用户的私钥由于XX原因,泄漏了,导致我们之前通信的数据被修改,造成损失,责任怎么算?公说公有理婆说婆有理,是不是这样?但如果我们使用非对称加密,我们可以把私钥握在手里,公钥发给任何人, 1 亿个用户都可以用我们同一个公钥对数据进行加密,私钥只有我们团队有,因此我们通信只要出了问题,责任就很清楚,是我们团队泄漏的私钥,并且我们只需要维护 1 个私钥,是不是减轻的很多负担,对吧?只要我们的私钥不被泄漏,加密算法足够安全,这个加密流程是很难被破解的。
签名与签名验证
由于非对称加密优势,人们想到了另外一个场景,就是签名和认证,用私钥和加密算法对数据进行签名,然后把公钥公开的大家,去对我的原始数据进行签名认证。
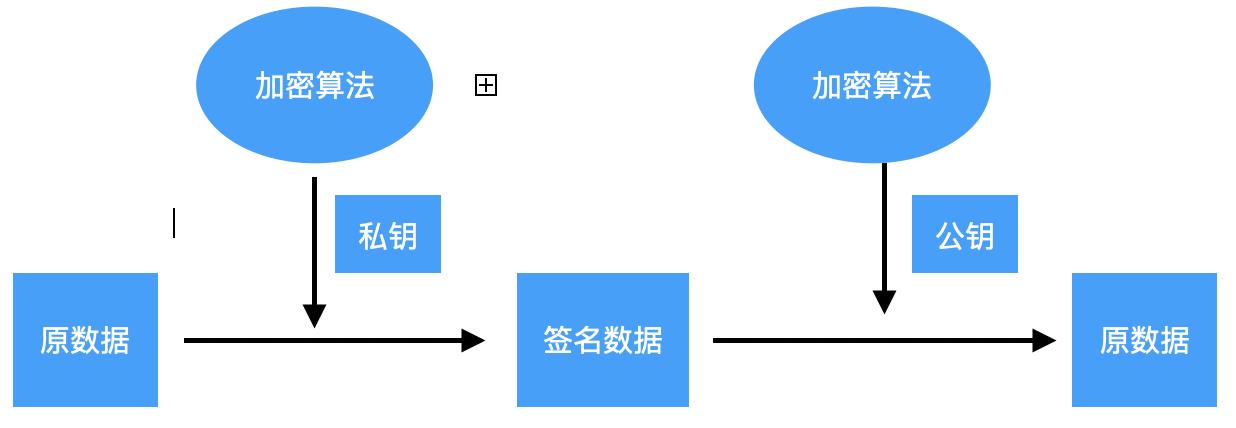
签名和认证在我们的开发过程中非常普片,例如:
- 在安全层 SSL/TLS 连接过程中(后面文章会讲到)。
- 我们安装包在发布时需要签名, APK 安装时会对签名进行验证。
- 在我们实际开发中会结合(加密+签名)来加密数据并解密后验证数据的真实性,是否被篡改。
经典的非对称加密算法有 3 种:
- RSA:由美国麻省理工学院三位学者 Rivest、Shamir 及 Adleman 研发的密码系统,是一个支持变长密钥的公共密钥算法,需要加密的文件块的长度也是可变的。
- DSA(Digital Signature Algorithm):数字签名算法,是一种标准的 DSS(数字签名标准,此算法只用于签名,比较专一)。
- ECC(Elliptic Curves Cryptography):椭圆曲线密码编码学,常用于比特币数据加密使用。
非对称加密算法的弊端
加密算法及其复杂,安全性依赖算法与密钥,而且加密和解密效率很低。一个词概括:安全低效。
Hash 算法
定义:
把任意长度的数据,通过散列算法,变换成固定长度的数据(通常情况下很小)。
注意: Hash 算法是不可逆的,所以 Hash 算法既不是编码,也不属于加密算法,注意啦!
什么意思呢,我们在上班的时候,公司会给我们申请一个唯一的工号吧?(我们认为工号是不会被注销的)有的公司还会录指纹打卡对吧?那么申请工号这个过程就能算作是一个 Hash 算法,他把我们整个人的体貌、行为特征抽象到这个工号上了,这个工号所做的所有操作,都能证明是你的做的。
经典的算法也是 2 种
- MD5(Message Digest Algorithm 5):是 RSA 算法同一个团队研发的,一种单向散列算法。
- SHA(Secure Hash Algorithm):可以对任意长度的数据运算生成一个 160 位的数值。
Hash算法有什么作用呢?
1. 数据完整性验证
-
举例:我们现在写了一部很经典的小说,大小 2G 左右,在网站上公开提供用户下载,过了一段时间发现用户经常下载到盗版并且有时候下载出来的小说文本可能会丢包,少一些章节,怎么办?
-
验证数据完整性嘛?刚你不是讲了签名吗?ok,我们使用签名应该怎么做?
- 在某平台提供小说源文件下载地址。
- 对小说源文件通过私钥进行签名,然后把签名文件、公钥、加密算法放在下载地址下方,提供用户进行源文件验证,如果和原数据一致,说明是正版的。
- 用户下载小说源文件。
- 用户下载签名文件,并获取公钥、加密算法对签名文件进行解密,得到源文件看是否和源文件一致。
看似好像没有什么问题(如果你发现了那更好了),但是,,,凡事都还有个但是,这个源文件可是有 2G 左右,这会导致它的签名的文件也会有 2G 左右,甚至更大。What? 你不是在逗我吧,让我下载一个 2G的文件验证源文件?另外一个问题,你让我用户怎么确认源文件小说是不是盗版,一个章节一个章节的核对吗? 这时候 Hash 算法的价值就体验出来了,我们如何优化刚才的步骤呢?
- 在某平台提供小说源文件下载地址。
- 对小说源文件进行 MD5/SHA1 算法得到一个固定的摘要值(这个值非常小,大概只有20B 左右)然后在通过私钥对摘要值进行签名,此时的签名文件就非常小了,再把签名文件、公钥、加密算法放在下载地址旁提供给用户下载,最后在写一个 README 告知源文件使用的是什么 Hash 算法(MD5/SHA1)。
- 用户下载小说源文件。
- 用户下载 MD5/SHA1 后的签名文件,获取公开的公钥、加密算法对签名文件进行解密,得到之前签名的那个摘要值,根据 README 中告知 Hash 算法,对源数据进行此 Hash 算法也得到一个 摘要值,如果这个值跟刚才解密得到的值是一样的,说明源文件是正版并且不可能被串改,因为源文件只要有任何一点点改动,得到的 Hash 摘要值都会有很明显的变化,称之为雪崩效应。
注意:这个例子的过程非常重要,如果你没看懂,希望你可以多看几遍,这对你理解对称加密、非对称加密、 Hash 算法非常有帮助,这个逻辑是也是 SSL/TLS 证书认证的核心。
2. 快速查找,提高效率(hashCode(),HashMap)
这也是 Hash 算法非常重要的一个作用了,搞明白这个作用前,我们可以来了解下 HashCode()。
-
为什么每次我们重写 equals() 时,一定要重写 hashCode() 呢?
-
首先我们要有一个概念,hashCode() 也是 Hash 算法的一种,他获取的是我们当前这个对象的摘要值(也可以理解成是特征值),他是用来对身份判定的,并且很轻量,以此达到快速识别的目的。
快速识别的核心逻辑总结是下面这2句话:
hashCode() 相同的对象,其 equals() 可能相同,hashCode() 不同的对象,equals() 肯定不同。
基于这个核心逻辑,当我们在做查找的时候,可以先用轻量的摘要值对数据进行一次过滤,因为 equals() 是非常耗时的(会拿这个对象的属性值,方法等逐一比较。),这样就不用每次都去比较 equals() 是不是相等的,以此达到提高效率的作用。
而如果我们不重写 hashCode() 的话,会发生什么呢? 数据碰撞。
当我们不重写 hashCode() 时,会默认调用 Object 的 hashCode() 方法,如果此时我们在通过 HashMap/HashSet 等 put 数据时,就会出现这样一个现象,本来这个对象的 hashCode() 是不相等的,结果由于我们没有重写, 导致发生数据碰撞,结果后进入的数据会替换掉重复的那么 hashCode() 对应的 value 值,查找的时候也是这个原理。
3. 隐私保密
比较有代表性的就是对密码、登录授权信息进行 MD5/SHA1 加密,加密前,大部分服务器开发人员还会对你的实际数据做一些本地的加密算法后,再进行 MD5/SHA1 加密存储。
如果我们直接在数据库明文存我们的密码等敏感信息,数据库一旦被盗,那将是毁灭性的。而我们对密码等敏感数据做 MD5/SHA1 后,存储到数据库的数据是不可逆的,坏人就算拿到你的数据库也不会对用户隐私造成损失。如果本地加密后,再进行 MD5/SHA1 那就更安全了,你就算暴利破解(这里的暴利破解指的是枚举所有的可能去做 MD5/SHA1 算法,看得到的数据是否和数据库一致,以此来破解你的密码),但是如果服务器做了一次本地的加密后,你就算破解了 MD5/SHA1 这层,得到的也是服务器本地加密后的那个数据,再不知道本地服务器加密算法的情况下,坏人拿到这个数据也毫无意义。
Base64 是不是加密
终于说完了,读完本文,我们清楚了什么是编码,什么是加密。回答本文最后一个问题 “Base64 是不是加密?” 前,我们对比下编码、加密异同点
相同点:
- 编码的过程都是一个可逆的过程,既从 A -> B,并且可以从 B -> A
不同点:
- 编码过程不需要秘钥,而加密过程必须需要秘钥解密。
- 编码过程注重转换,而加密过程注重安全和性能。
因此 Base64 不属于加密,因为加密是需要秘钥的。
以上是关于JackHttp -- 浅谈编码加密(对称加密,非对称加密,Hash算法)的主要内容,如果未能解决你的问题,请参考以下文章