python动态渲染页面爬取Selenium的具体使用
Posted zhi_neng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python动态渲染页面爬取Selenium的具体使用相关的知识,希望对你有一定的参考价值。
Selenium是一个自动化测试工具,利用它可以驱动浏览器执行特定的动作,如点击、下拉等操作,同时还可以获取浏览器当前呈现的页面的源代码,做到可见即可爬。对于一些javascript动态渲染的页面来说,此种抓取方式非常有效。本文就让我们一起来学习一下它的强大之处吧。
1.准备工作
我们用Chrome为例来学习Selenium的用法。在开始之前,请确保已经正确安装了Chrome浏览器并配置好了ChromeDriver。另外还需要正确安装Python的Selenium库,详细的安装教程大家可以看我之前写的文章。
《Python3请求库Selenium的安装教程》《Python3安装教程之ChromeDriver的安装》
2.基本使用方法
准备工作做好之后,我们来大体看一下Selenium有一些怎样的功能。示例如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
browser = webdriver.Chrome()
try:
browser.get('https://www.baidu.com')
input = browser.find_element_by_id('kw')
input.send_keys('Python')
input.send_keys(Keys.ENTER)
wait = WebDriverWait(browser,1000)
wait.until(EC.presence_of_all_elements_located((By.ID,'content_left')))
print(browser.current_url)
print(browser.get_cookies())
print(browser.page_source)
finally:
browser.close()运行代码之后发现,会自动弹出一个Chrome浏览器。浏览器首先会跳转到百度,然后在搜索框中输入Python,接着跳转到搜索结果页。搜索结果页加载出来后,控制台会输出当前的URL、当前的Cookies和网页源代码。代码过长此处省略。可以看到,我们得到了当前的URL、Cookies和源代码都是浏览器中的真实内容。
所以说,使用Selenium来驱动浏览器加载网页的话,就可以直接拿到JavaScript渲染的结果了,不用担心使用的是什么加密系统。下面我们来详细的了解一下Selenium的具体用法。
3.声明浏览器对象
Selenium支持非常多的浏览器,如Chrome、Firefox、Edge等,还有android、BlackBerry等手机端的浏览器。另外,也支持无界面浏览器PhantomJS。此外,我们可以使用如下的方式初始化:
from selenium import webdriver
browser = webdriver.Chrome()
browser = webdriver.Firefox()
browser = webdriver.Edge()
browser = webdriver.PhantomJS()
browser = webdriver.Safari()
这样就完成了浏览器对象的初始化并将其赋值为browser对象。接下来,我们要做的就是调用browser对象,让其执行各个动作以模拟浏览器操作。
4.访问页面
我们可以用get()方法来请求网页,参数传入链接URL即可。比如,这里用get()方法访问淘宝,然后打印出源代码,代码如下:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
print(browser.page_source)
browser.close()
运行后发现,弹出了Chrome浏览器并且自动访问了淘宝网,然后控制台输出了淘宝页面的源代码,随后浏览器关闭。
通过这几行简单的代码,我们可以实现浏览器的驱动并获取网页源码,非常便捷。
5.查找节点
Selenium可以驱动浏览器完成各种操作,比如填充表单、模拟点击等。比如,我们想要完成向某个输入框输入文字的操作,总需要知道这个输入框在哪里吧?而Selenium提供了一系列查找节点的方法,我们可以用这些方法来获取想要的节点,以便下一步执行一些动作或者提取信息。
1)单个节点
比如,想要从淘宝页面中提取搜索框这个节点,首先要观察它的源代码,如下图
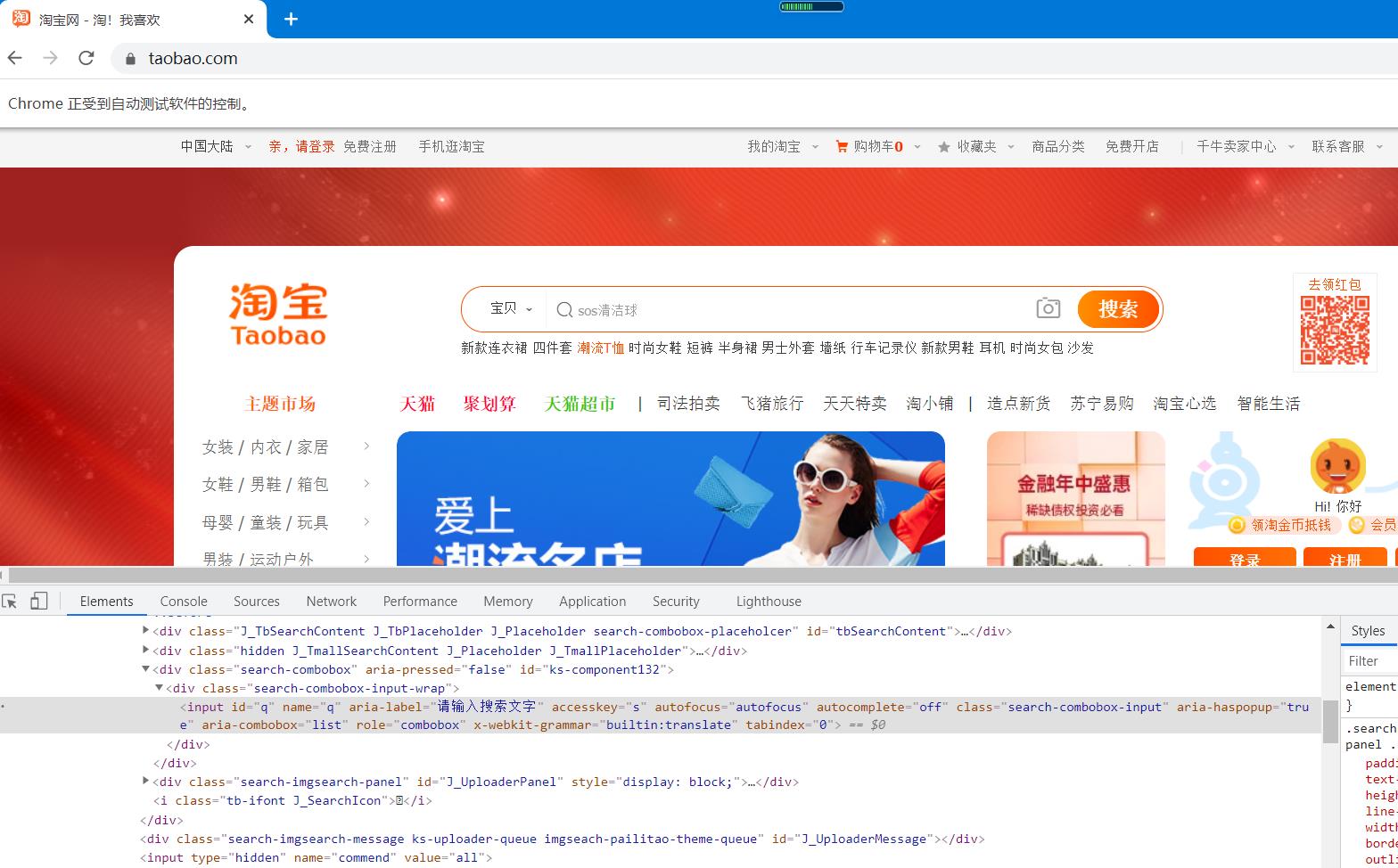
我们可以发现,它的id是q,name也是q。此外,还有许多其他属性,我们此时就可以用多种方式获取它了。比如,find_element_by_name()是根据name值获取,find_element_by_id()是根据id获取。我们用代码实现一下:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
input_first = browser.find_element_by_id('q')
input_second = browser.find_element_by_css_selector('#q')
input_third = browser.find_element_by_name('q')
input_four = browser.find_element_by_xpath('//*[@id="q"]')
print(input_first,input_second,input_third,input_four)
browser.close()
这里我们使用了4种方式获取输入框,分别是ID、CSS、Name、和Xpath获取,它们返回的结果完全一致。运行结果如下:
<selenium.webdriver.remote.webelement.WebElement (session="06810131574f7cd748062c7a7cd73bd3", element="4934e890-fc43-43bb-b966-c1d4783bf737")> <selenium.webdriver.remote.webelement.WebElement (session="06810131574f7cd748062c7a7cd73bd3", element="4934e890-fc43-43bb-b966-c1d4783bf737")> <selenium.webdriver.remote.webelement.WebElement (session="06810131574f7cd748062c7a7cd73bd3", element="4934e890-fc43-43bb-b966-c1d4783bf737")> <selenium.webdriver.remote.webelement.WebElement (session="06810131574f7cd748062c7a7cd73bd3", element="4934e890-fc43-43bb-b966-c1d4783bf737")>
可以看到,这4个节点都是WebElement类型,是完全一致的。
下面列出所有获得单个节点的方法:
find_element_by_id(按 ID 在此元素的子元素中查找元素)
find_element_by_name(按名称查找此元素的子元素中的元素)
find_element_by_xpath(通过 xpath 查找元素)
find_element_by_link_text(通过可见链接文本在此元素的子元素中查找元素)
find_element_by_partial_link_text(通过部分可见的链接文本在此元素的子元素中查找元素)
find_element_by_tag_name(按标签名称在此元素的子元素中查找元素)
find_element_by_class_name(按类名在此元素的子元素中查找元素)
find_element_by_css_selector(通过 CSS 选择器在此元素的子元素中查找元素)
另外,Selenium还提供了通用方法find_element(),它需要传入两个参数:查找方式By和值。实际上,它就是find_element_by_id()这种方法的通用函数版本,比如find_element_by_id(id)就等价于find_element(By.ID,id),二者得到的结果完全一致。我们用代码实现一下:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
input_first = browser.find_element(By.ID,'q')
print(input_first)
browser.close()实际上这种查找方式的功能和上面列举的查找函数完全一致,不过参数更加灵活。
2)多个节点
如果查找的目标在网页中只有一个,那么完全可以用find_element()方法。但是如果有多个节点,再使用的话,就只能得到一个节点。如果要查找所有满足条件的节点,需要用find_elements()这样的方法。注意,在这个方法的名称中,element多了一个s,注意区分。
比如,要查找淘宝左侧导航条的所有条目,如下图所示:

我们可以这样实现:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
lis = browser.find_elements_by_css_selector('.service-bd li')
print(lis)
browser.close()运行结果如下:
[<selenium.webdriver.remote.webelement.WebElement (session="812e28ac68075bba6ce7620921db0b6a", element="50480941-6ee6-4845-b105-3f45ae49863a")>, <selenium.webdriver.remote.webelement.WebElement (session="812e28ac68075bba6ce7620921db0b6a", element="3fcc24e2-cd4f-431f-8609-82f446886be0")>, <selenium.webdriver.remote.webelement.WebElement (session="812e28ac68075bba6ce7620921db0b6a", element="23e8d69c-6e3f-410c-a1b7-3c874b47d270")>, ...,<selenium.webdriver.remote.webelement.WebElement (session="812e28ac68075bba6ce7620921db0b6a", element="028dc6af-fd47-4df2-a18e-59bc26dc0fce")>]
这里我简化了运行结果,中间部分省略。
可以看到,得到的内容变成了列表类型,列表中的每个节点都是WebElement类型。
也就是说,如果我们用find_element()方法,只能获取匹配的第一个节点,结果是WebElement类型。如果用find_elements(),则结果是列表类型,列表中的每一节点是WebElement类型。
这里列出所有获取多个节点的方法:
find_elements_by_id
find_elements_by_name
find_elements_by_xpath
find_elements_by_link_text
find_elements_by_partial_link_text
find_elements_by_tag_name
find_elements_by_class_name
find_elements_by_css_selector
当然,我们也可以直接用find_elements()方法来选择,这时可以这样写:
lis = browser.find_elements(By.CSS_SELECTOR,'.service-bd li')
结果是完全一样的。
6.节点交叉
Selenium可以驱动浏览器来执行一些操作,也就是说可以让浏览器模拟执行一些动作。比较常见的用法有:输入文字时用send_keys()方法,清空文字时用clear()方法,点击按钮的时用click()方法。具体的示例如下:
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
input = browser.find_element_by_css_selector('#q')
input.send_keys('iPhone')
time.sleep(1)
input.clear()
input.send_keys('iPad')
button = browser.find_element_by_class_name('btn-search')
button.click()这里首先驱动浏览器打开淘宝,然后用find_element_by_id()方法获取输入框,然后用send_keys()方法输入iPhone文字,等待一秒后用clear()方法清空输入框,再此调用send_keys()方法输入iPad文字,之后再用find_element_by_class_name()方法获取搜索按钮,最后调用click()方法完成搜索动作。
通过上面的方法,我们就完成了一些常见节点的动作操作,更多的操作可以参见官方文档的交互动作介绍:
http://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.remote.webelement
以上是关于python动态渲染页面爬取Selenium的具体使用的主要内容,如果未能解决你的问题,请参考以下文章