CMDB3 完善采集端代码(ssh方案的多线程采集), 异常处理, 服务端目录结构的设计(django的app), API数据分析比对入库
Posted 战斗小人
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CMDB3 完善采集端代码(ssh方案的多线程采集), 异常处理, 服务端目录结构的设计(django的app), API数据分析比对入库相关的知识,希望对你有一定的参考价值。
完善一下采集端代码
-
线程和进程,协程的区别 (90% 问到)
-
提高并发的话,使用多线程
-
python2 多进程有 多线程没有
-
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor p = ThreadPoolExecutor(10) def test(i): time.sleep(1) print(i) for i in range(100): p.submit(test, i)
- 异常处理
> 增加代码的健壮性,增强代码的容错能力
import traceback def test(): try: int(\'dsadsa\') except Exception as e: print(traceback.format_exc()) # 打印系统报错原文 print(\'hello\') test()
-
api : 负责接收数据, 并且对比入库的
-
backend: 前端数据的展示
-
设计表的大原则,建立模型类的根据是:根据客户端传过来的数据类型来去建立对应的表模型类,包括这些模型类中的字段,一定是根据客户端传过来的字段来去定
业务线或者产品线的概念?
腾讯公司有三条业务线或产品线:微信,QQ, 王者荣耀
但是小公司的话,因为没钱,服务少,一条业务线跑在多台服务器上,一台服务器上也可以跑多个业务。此时关系就是多对多关系
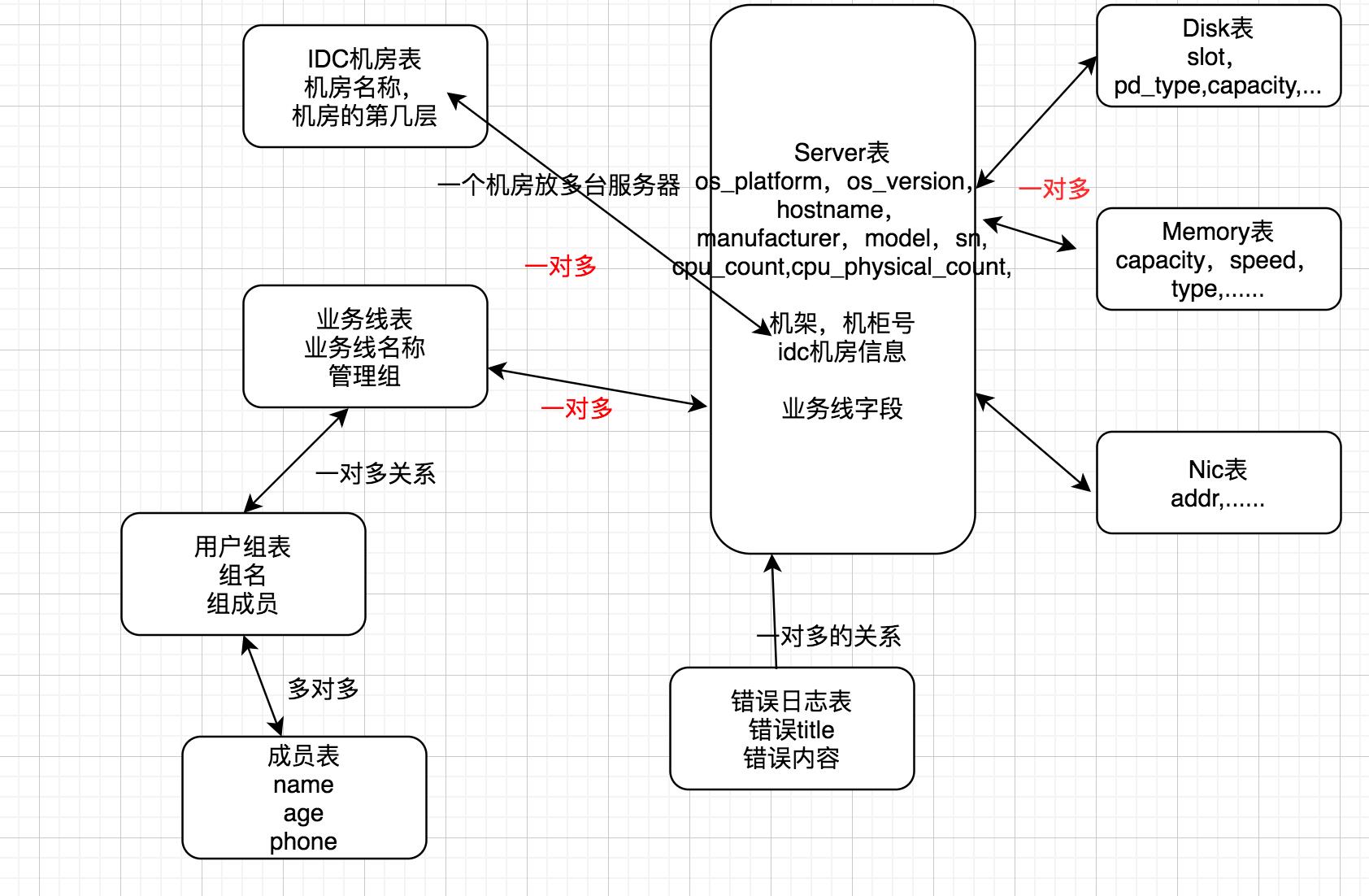
Api/views.py
import json from django.shortcuts import render,HttpResponse # Create your views here. from repository import models def asset(request): if request.method == \'POST\': info = json.loads(request.body) # print(info) ### 判断此台服务器是否已经录入到数据库中了 hostname = info[\'basic\'][\'data\'][\'hostname\'] ### c1.com server_obj = models.Server.objects.filter(hostname=hostname).first() ###obj if not server_obj: return HttpResponse(\'资产未录入!\') #### 分析磁盘数据为例 status = info[\'disk\'][\'status\'] if status != 10000: models.ErrorLog.objects.create(title=\'错误信息\', content=info[\'disk\'][\'data\'], server_obj=server_obj) return HttpResponse(\'采集出错!\') new_disk_info = info[\'disk\'][\'data\'] old_disk_info = models.Disk.objects.filter(server_obj=server_obj).all() # [ # (slot=0, pd_type=\'sas\', capacity=256G, ...), # (slot=1, pd_type=\'sat\', capacity=278G, ...) # ..... # ] new_slot = set(new_disk_info.keys()) old_slot = [] for obj in old_disk_info: old_slot.append(obj.slot) old_slot = set(old_slot) print(new_slot) print(old_slot) ## 增加的是哪一些槽位的值: add_slot = new_slot.difference(old_slot) # 取差集 if add_slot: for slot in add_slot: ### {\'slot\': \'3\', \'pd_type\': \'SATA\', \'capacity\': \'476.939\', \'model\': \'S1AXNSAF912433K Samsung SSD 840 PRO Series DXM06B0Q\'}, add_disk_info = new_disk_info[slot] add_disk_info[\'server_obj\'] = server_obj ## 可以增加的变更 {2,3,4,5} 数据记录到变更日志表中 models.Disk.objects.create(**add_disk_info) ## 删除槽位数据 del_slot = old_slot.difference(new_slot) if del_slot: models.Disk.objects.filter(server_obj=server_obj,slot__in=del_slot).delete() ## 将删除的槽位数据记录到变更日志表中 # 比较数据是否变动 up_slot = new_slot.intersection(old_slot) # 取交集 if up_slot: for slot in up_slot: ## {\'slot\': \'0\', \'pd_type\': \'SATA\', \'capacity\': \'279.396\', \'model\': \'SEAGATE ST300MM0006 LS08S0K2B5NV\'} new_disk_row = new_disk_info[slot] ## obj(slot:0, pd_type:sas, capacity:234,...) old_slot_row = models.Disk.objects.filter(slot=slot,server_obj=server_obj).first() for k,new_v in new_disk_row.items(): \'\'\' k: slot, pd_type, capacity, model... new_v: 0, SATA, 279 , ... \'\'\' old_v = getattr(old_slot_row,k) if new_v != old_v: ## 记录变更日志 setattr(old_slot_row,k,new_v) old_slot_row.save() return HttpResponse(\'ok\') else: ### 主机名提前录入到数据库中 ### 连接数据库,从数据库中获取主机名 return [\'c1.com\',\'c2.com\',\'c3.com\']
以上是关于CMDB3 完善采集端代码(ssh方案的多线程采集), 异常处理, 服务端目录结构的设计(django的app), API数据分析比对入库的主要内容,如果未能解决你的问题,请参考以下文章