数据库规范化,数据库范式,和规范化实例
Posted Xurtle
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据库规范化,数据库范式,和规范化实例相关的知识,希望对你有一定的参考价值。
文章目录
什么是数据库规范化
维基百科的定义如下:
数据库规范化,又称数据库或资料库的正规化、标准化,是数据库设计中的一系列原理和技术,以减少数据库中数据冗余,增进数据的一致性。
数据库范式是埃德加·科德设计出来的。在1970年代初,他定义了第一范式(First normal form)、第二范式(Second normal form),和**第三范式(Third normal form)**的概念。数据库范式可以理解成一系列的规范或者规则,为了实现数据库规范化的目标,我们需要按照这些范式的规则来优化数据库。
关于这些范式的规则我会在文章后续部分说明。
现在数据库设计最多满足第三范式,普遍认为范式过高,虽然具有对数据关系更好的约束性,但也导致数据关系表增加而令数据库IO更易繁忙,原来交由数据库处理的关系约束现更多在数据库使用程序中完成。
因此,本文数据库的优化实例只做到第三范式。
术语
为了更准确,简洁地定义各个范式的规则,我们需要知道一些术语的含义。对于有些术语来说,我不打算写出它标准化的定义,这是因为标准化定义十分晦涩。对于这样的术语,俺直接给出相应的例子,理解它代表的是什么东西就行。
- 关系(relation):数据库中的「表」
- 元组(tuple):数据库表中的「行」
- 属性(attribute ):数据库表中的「列」
- 超键(superkey):数据库关系中能够唯一标示元组(即,行)的属性集合。超键例子
- 候选键(candidate key):不含有多余属性的超键。也就是说,这个超键属性集合的任何一个真子集(proper subset),都不能唯一标示元组。候选键有时也被称为主键(primary key)。一个表中的候选键可能不唯一
- 主属性(prime attributes):候选键中包含的属性
- 非主属性(non-prime attribute):任何一个候选键都没有包含的属性
下面俺给出一个关于上面部分术语的例子。这个例子来源于 yangyang17
假如有以下学生和教师两个表:
Student(student_no, student_name, student_age, student_sex, student_credit, teacher_no)
Teacher(teacher_no, teacher_name, teacher_salary)
超键:Student表中可根据学生编号(student_no),或身份证号(student_credit),或(学生编号,姓名)(student_no,student_name),或(学生编号,身份证号)(student_no,student_credit)等来唯一确定是哪一个学生,因此这些组合都可以作为此表的超键
候选键:候选键属于超键,且是最小的超键,即如果去掉超键组合中任意一个属性就不再是超键了。Student表中候选键为学生编号(student_no),身份证号(student_credit)
主键:主键是候选键中的一个,可人为决定,通常会选择编号来作为表的主键。
数据库的3个范式介绍
在这个小节,俺会用具体的例子来说明每个范式所包含的规则。
第一范式
第一范式的定义:
First normal form (1NF) is a property of a relation in a relational database. A relation is in first normal form if and only if the domain of each attribute contains only atomic (indivisible) values, and the value of each attribute contains only a single value from that domain.
第一范式必须符合下面3个标准:
- Eliminate repeating groups in individual tables
- Create a separate table for each set of related data
- Identify each set of related data with a primary key
下表是一个不符合第一范式的 例子,Telephone Number 列并不是原子的,它可以继续拆分下去。
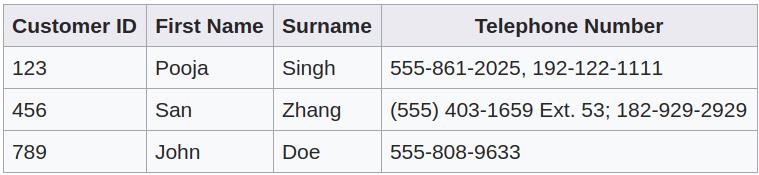
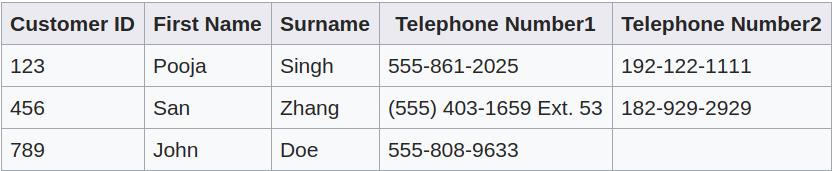
解决上面问题的一个直观方法是多引入一列,如下图所示。但是,这种方法仍然有3个问题。第一、下表仍然包含 “repeating group”,即包含概念上相似的属性,电话号。第二、这样做会引入没有意义的顺序。比如,为什么 555-861-2025 放到 Telephone Number1 列,而不是放到 Telephone Number2 列呢?第三、当一个客户再多一个号码时,会修改表结构,增加一列。
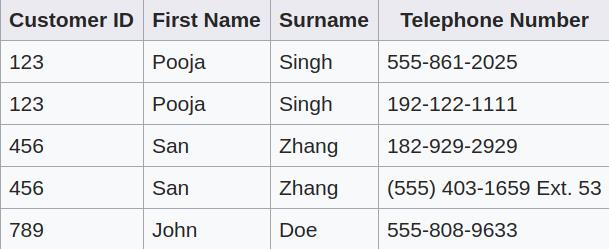
下面的表结构可以解决上面的问题。由于第一范式要求能唯一地标识出一个元组,而现在 Customer ID 重复了,所以我们需要 Telephone Number 与 Customer ID 的组合才能标识出一个元组。
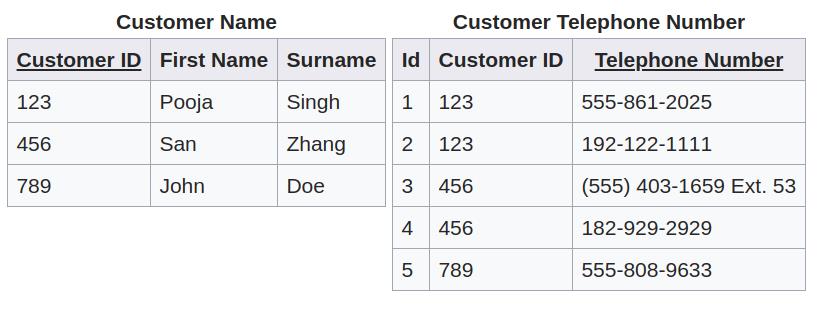
另一种设计方案如下所示,它是使用两张表。
第二范式
第二范式必须满足下面2个条件:
- be in first normal form (1NF)
- not have any non-prime attribute that is dependent on any proper subset of any candidate key of the relation
第2个条件翻译过来的含义为:任何一个非主属性不能依赖于候选键属性集合的真子集属性。
下表的每个值都是单一值,所以它符合第一正规化。但它不符合第二范式。这是因为,一个元件 ID 和供应商 ID 合在一起组成一个主键,但供应商的名称和住址却只和供应商 ID 有关(部分依赖)。
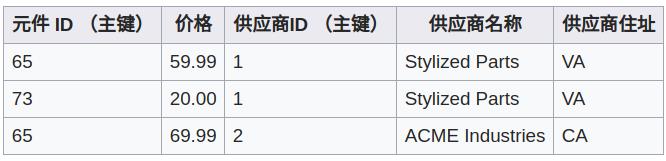
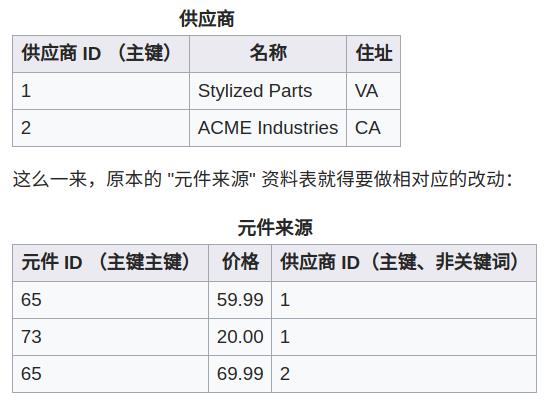
把上表的结构改成下面的结构,就符合第二范式了。
第三范式
第三范式必须满足下面2个条件:
- 符合第二范式
- all the attributes in a table are determined only by the candidate keys of that relation and not by any non-prime attributes
也就是说,符合第三范式的表结构不应该包含 transitive dependency. 即,非主属性之间不能有依赖关系。比如下表的结构就包含 transitive dependency,因为非主属性 Author 决定了另一个非主属性 Author Nationality.
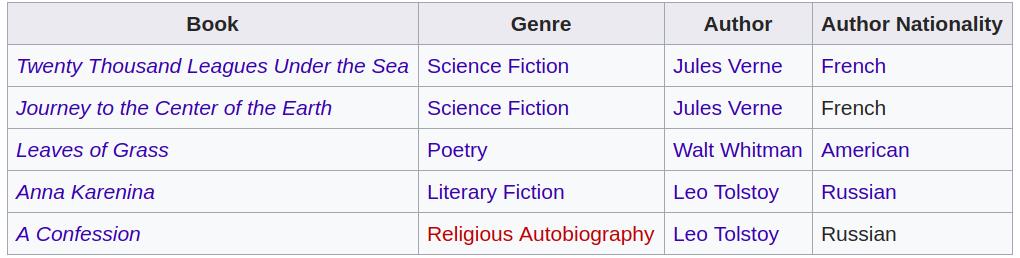
根据数据库范式优化数据库结构
在这个小节中,俺会给出一个数据库表的初始结构,它不符合数据库范式。我会一步一步地改进它,直到让它满足数据库的第三范式。下表是一个不符合范式的初始结构:

满足第一范式
初始表中的 Subject 列并不是原子的,一种方式是将其拆分成3个列。如下所示:

如果用上面的方式,当某本书增加一个 subject 时,就需要更改表结构,增加一列。因此,用下面的方式修改表,使其符合第一范式会更好一些。
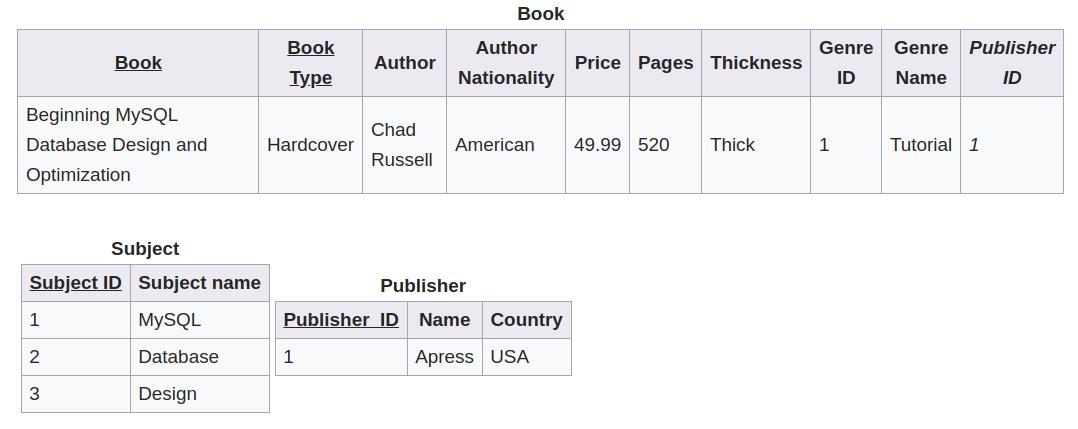
拆分成上面的结构以后,我们需要把 Subject 表与 Book 表连接起来。由于一本书可能对应多个 subject,而一个 subject 也可能对就多本书,这是一个典型的 多对多 关系。因此我们需要新建一张关联表:
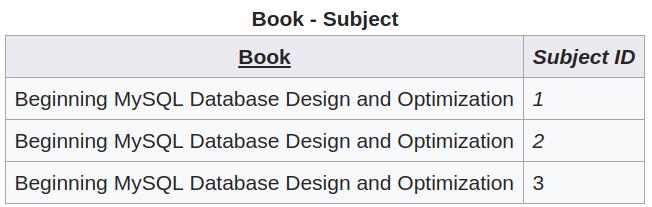
满足第二范式
从下表可以看出,Book 和 Book Type 是一个候选键。但是,只有一个 price 属性是由这2个主属性共同影响的(这是合理的,因为同样一本书,电子版与精装的价格肯定是不同的)。其它的属性都是只由 Book 这个主属性影响的。因此,这不符合第二范式。
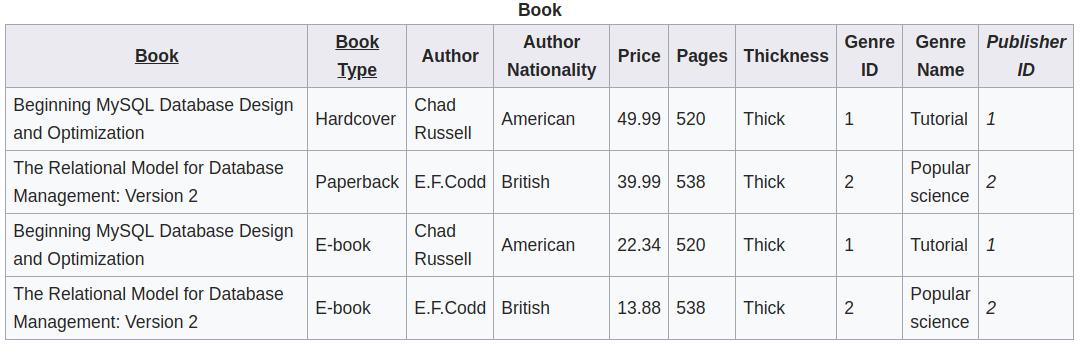
按照下面的方式修改以后,就符合第二范式了。
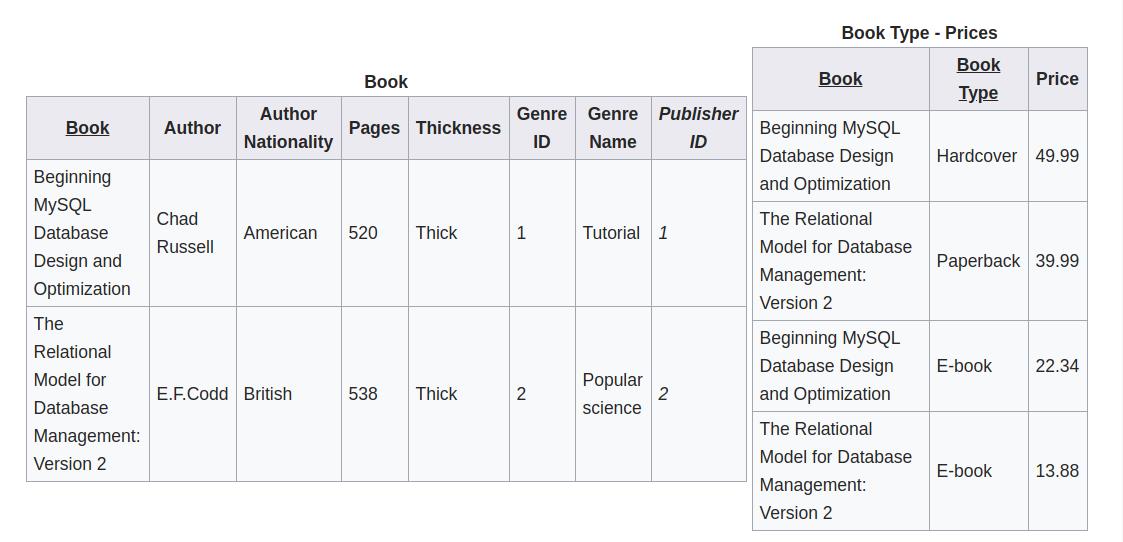
满足第三范式
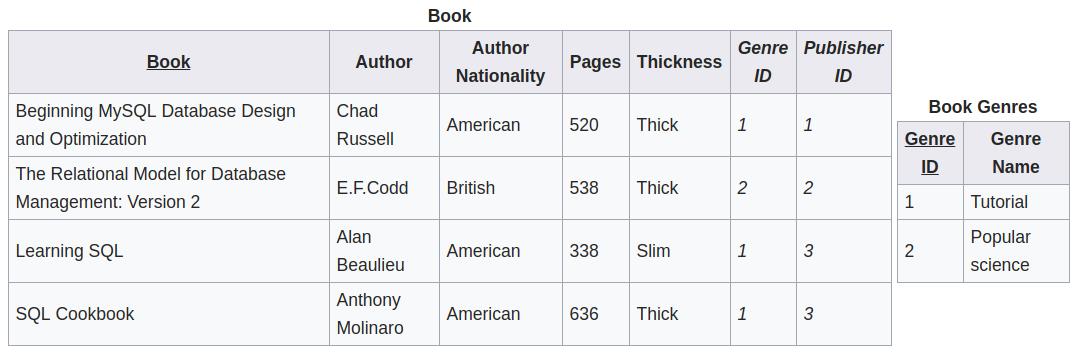
由于下表中的非主属性 Genre ID 决定了另一个非主属性 Genre Name,即存在 transitive dependency,所以它并不符合第三范式。
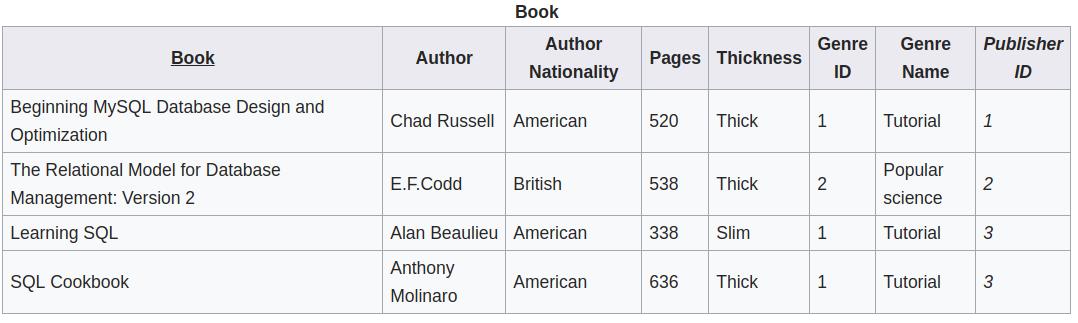
改成下面的结构以后,就符合第三范式了。至此,我们从一个不符合任何范式的初始表结构,一步一步地改成了现在这个结构。
参考链接
以上是关于数据库规范化,数据库范式,和规范化实例的主要内容,如果未能解决你的问题,请参考以下文章