Knowledge-Augmented Language Model and its Application to Unsupervised Named-Entity Recognition(Face
Posted JetHu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Knowledge-Augmented Language Model and its Application to Unsupervised Named-Entity Recognition(Face相关的知识,希望对你有一定的参考价值。
Knowledge-Augmented Language Model and its Application to Unsupervised Named-Entity Recognition(Facebook AI 2019) 文献综述
1.摘要:
传统的语言模型无法为文本中的实体名称进行有效建模,主要是因为这些命名实体不会在文本中频繁出现。近期研究发现相同的实体类型(如人名、地名)其上下文之间具有一定共性,同时训练语言模型时可以借助外部知识图谱。本文主要研究继续探索利用知识图谱来强化语言模型的训练,训练目标是优化语言模型的困惑度,模型全称Knowledge-Augmented Language Model(KALM)。在这个过程并不依赖其他如命名实体识别工具。为了提升语言模型的效果,本模型在训练过程中学习到实体类型信息,然后模型能以完全无监督的方式进行命名实体识别。在NER任务中,本模型获得了与监督学习方法双向LSTM+CRF模型接近的效果。本文通过预测学习方法在大量无标签的朴素文本中建模命名实体识别任务是可行的。本文是第一篇利用无监督进行NER神经网络模型。
2. KALM模型
KALM模型采用传统的RNN语言模型(实际使用的是LSTM,再进行无监督NER时为了看见下文使用了双向LSTM)。在语言模型任务中KALM预测的词来源于一个词表 (普通词的词表);但同时它可以预测具体某一个实体类型的词。每一种实体类型都具有一个单独的词表{ },该词表通过知识图谱搜集得到。如,人名词表(刘德华、张学友、周杰伦 …) 地名词表(南宁、徐州、四川)。KALM通过上下文能学到各种实体类型的共性。
2.1 RNN 语言模型
语言模型的目标即是根据指定的前t个词 预测下一个词。下一个词的概率可表示为
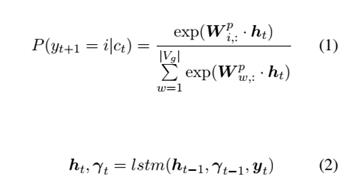
其中 分别是隐藏状态、记忆状态、输入向量。 是投射矩阵,将隐藏状态投射到词表空间 。
2.2知识增强语言模型KALM
KALM在LSTM语言模型的普通词表 基础上增加了实体类型词表{ }。其中实体类型词表是从某个知识图谱中抽取出的。对一个词,KALM通过一个实体类型特征矩阵 (通过学习得到)计算该词的属于指定类型的概率。模型同时能够根据已知上文信息预测下一个词所具有的实体类型信息。最终下一个词的概率分布由实体类型概率分布和词在指定实体类型下的概率一起得出。具体的,令 表示词i的实体类型,分解公式(1)得到:
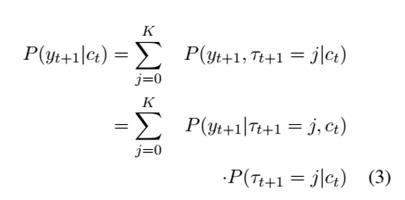
其中 是实体类型 下词的概率分布。
本文保留一个特征矩阵 来根据当前状态计算下一个词的实体类型概率 如公式(5)所示,同时本文采用一个额外的投射矩阵来将 投射到更低维度。
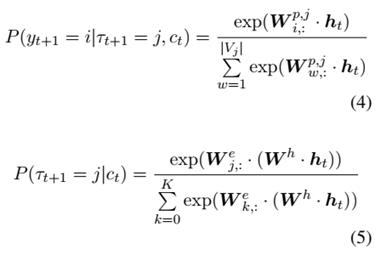
模型的整体结构如图(a)所示:
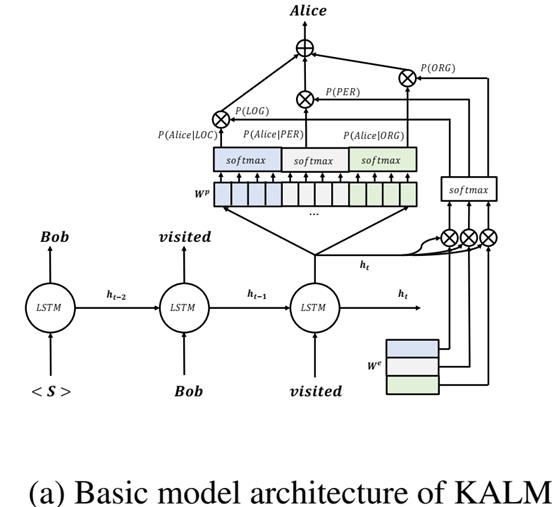
2.3将类型表示作为输入特征加入
在图(a)的基础模型中,每个词的输入只包含了该词的自身的向量。本文对模型输入部分通过引入根据前文获得的类型向量来改进模型效果;最后将类型向量和下一个要输入的词对应向量 进行拼接即可:
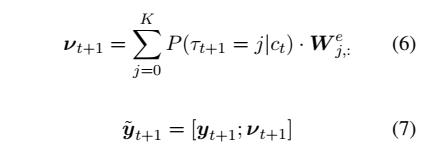
将类型信息作为输入加入有两个作用(1)在前馈计算中已经预测的实体类型有助于提升模型建模上下文的准确性 (2)在反向传播过程中能使模型在接下来的词语中更准确的学到潜藏实体类型信息。加入后的模型结构如图(b)所示。
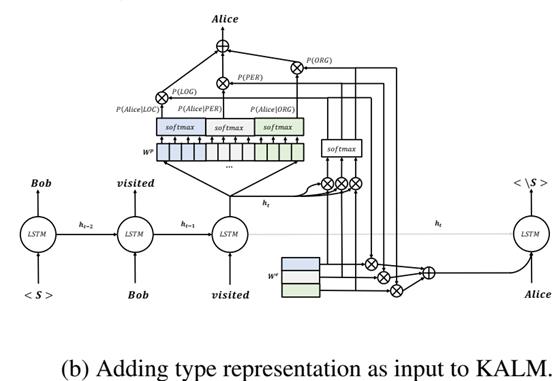
3.KALM进行无监督NER
尽管KALM学到的是实体类型信息是隐藏的,但是根据公式(5)我们可以在测试阶段预测一个指定词是实体词还是普通词。下一个词的实体类型概率 计算得到后,只需要选择概率最大的实体类型作为第t+1个词的实体类型。但是对于NER任务而言,模型是可以看到下文和第t+1个词的,因此为了进行无监督NER,需要对KALM模型做如下调整。
3.1引入双向LSTM,隐藏状态 由左右两边的隐状态拼接而成。
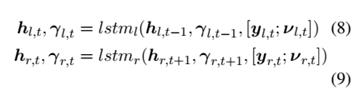
3.2当前词信息
即使使用双向的上下文也并不足以预测当前词的实体类型。本文提出我们可以从已有的知识图谱中计算指定词属于某一个实体类型的先验概率 ,然后可以分别从解码和编码两个方向来优化模型。
(1)Decoding with type prior解码过程中直接将先验实体类型概率与预测实体概率融合
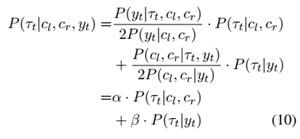
(2)Training with type priors训练过程中使用一个损失函数来缩小预测的实体类型概率分布与实体类型的先验概率 的差距。
4.评测数据集及效果测试(本文还对语言模型的效果进行了评测,但是这部分并不关心,只描述NER的相关评测)
4.1评测数据集
(1)NER任务使用数据集CoNLL 2003(四中实体类型人名、地名、机构名、各种类型MISC),知识图谱采用WikiText-2,本文统计了CoNLL 2003中出现在知识图谱中的实体数量以及该数据集本身句子数和token数量:
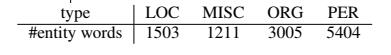
CoNLL 2003中在知识图谱中的实体数量
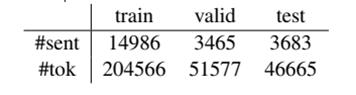
CoNLL 2003 句子数、Token数量
4.2效果测试
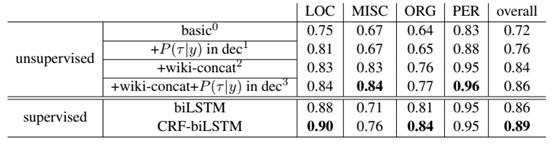
本文选择的基线模型是采用BILSTM和CRF-BILSTM的有监督模型,无监督模型中basic0是双向的KALM模型使用COLL 2003训练集的效果, 是加入了Decoding with type prior和Training with type priors后使用COLL 2003训练集的效果。 是在训练时使用COLL 2003训练集外增加了WikiText-2的文本数据。 为同时使用编码、解码两种策略的效果并增加WikiText-2的文本数据的效果。
5.总结
结合知识图谱中的实体信息去训练语言模型然后再去无监督的NER任务,这个思路非常具有创意,但是研读论文后结合论文的实际效果和使用的策略,本论文实际效果并不能让人满意。
(1)这种方式让我想到的是开放关系抽取中利用知识图谱中的三元组构造远程监督训练集。虽然本文的方法并没有直接将知识图谱中实体及实体类型信息直接用于标注文本数据,而是在训练语言模型的过程中间接使用;其本质是利用了知识图谱中的实体与实体类型信息进行弱监督训练。
(2)从后续实验结果看,basic0的f值0.72比CRF+biLSTM相差17个点,这说明本文提出的完全无监督其效果还是很差。把实体及实体类型在知识图谱中的先验信息加入后的结果直接比basic0提升4个点(我认为加入这个约束跟监督学习已经很接近了),后面增加了训练数据还是比CRF-biLSTM低3个点。
(3)COLL 2003主要是采用了人名、地名、机构名等类别,这是标准的NER任务,本文的方法进行NER比有监督的方法差是可以理解的。外部知识图谱的意义在于其他类型的实体(公司名、产品名)也可以通过这种方法进行NER模型训练,理论上来讲只要效果能达到一定程度,那么也是一种有价值的方法;但是本文并未给出在其他类型实体上识别的效果,所以让人质疑其真实场景的效果。
{
}
以上是关于Knowledge-Augmented Language Model and its Application to Unsupervised Named-Entity Recognition(Face的主要内容,如果未能解决你的问题,请参考以下文章