HBase 安装snappy压缩软件以及相关编码配置
前言
在使用HBase过程中因为数据存储冗余、备份数等相关问题占用过多的磁盘空间,以及在入库过程中为了增加吞吐量所以会采用相关的压缩算法来压缩数据,降低存储空间和在入库过程中通过数据压缩提高吞吐量。
HBase-2.1.5
Hadoop-2.7.7
一、HBase安装Snappy压缩软件
snappy-1.1.3下载地址:
wget wget https://github.com/google/snappy/releases/download/1.1.3/snappy-1.1.3.tar.gz
sudo yum -y install gcc-c++ libstdc++-devel
#下面是通过命令直接安装,
sudo yum -y install snappy snappy-devel
$ wget wget https://github.com/google/snappy/releases/download/1.1.3/snappy-1.1.3.tar.gz
$ sudo yum install gcc-c++ libstdc++-devel #安装需要编译snappy的软件
$ tar -zxvf /home/zfll/soft/snappy-1.1.2.tar.gz
$ cd snappy-1.1.3
#安装完成之后重新进行./configure 然后 make
$ ./configure
$ make
$ sudo make install
hbase使用
snappy进行对数据压缩需要再Linux安装snaapy,安装完成之后需要对相关配置文件进行修改,snappy安装完成之后一般是在/usr/local/lib中生成snappy的依赖包
hadoop-2.7.7:因为使用的是当前版本,当前版本中实际上是整合了snappy依赖包的,所以不需要去重新编译一个带有snappy的版本
$ $HADOOP_HOME/bin/hadoop checknative -a
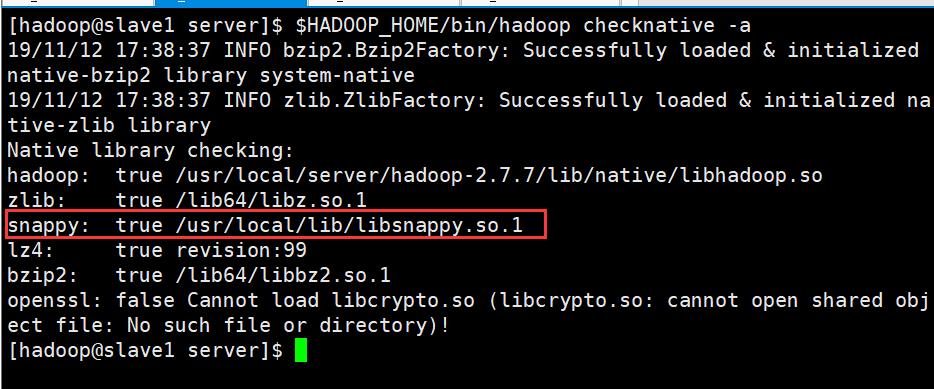
检查当前安装的hadoop版本是否带有snappy
如上图数据中是带有了相关的压缩程序依赖包的
在hadoop安装目录的hadoop/lib/native文件夹下存在如下内容:

如上内容为在使用snappy压缩的是时候需要依赖的包,在当前版本中已经编译好了,不需要再自己编译版本
安装完成之后,在HBase中使用,使用的时候需要进行相关配置
将依赖复制到HBase目录
将$HADOOP_HOME/lib/native目录下的所有文件复制到$HBase/lib/native/linux-amd64-64目录中,目录不存在则新建
$ mkdir -p $HBASE_HOME/lib/native/linux-amd64-64
$ cp $HADOOP_HOME/lib/native $HBASE_HOME/lib/native/linux-amd64-64
注:上述操作在集群中所有节点都需要进行操作,使得各个节点上的snappy程序在解压缩的时候能够找到依赖
hbase/conf/hbase-site.xml
<property>
<name>hbase.regionserver.codecs</name>
<value>snappy</value>
</property>
在上述文件中添加如上配置
hbase/conf/hbase-env.sh
export HBASE_LIBRARY_PATH=$HBASE_LIBRARY_PATH:$HBASE_HOME/lib/native/linux-amd64-64/:/usr/local/lib
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$HADOOP_HOME/lib/native/:/usr/local/lib
完成上述配置之后需要跟新hbase-env.sh环境变量,每个节点都更新避免问题,然后关闭HBase重新启动HBase
$ source $HBASE/conf/hbase-env.sh
$ ./$HBase_HOME/bin stop-hbase.sh
$ ./$HBASE_HOME/lib start-hbase.sh
验证是否能够使用
完成上述安装和配置之后需要进行验证
$ hbase shell
$ > CREATE \'snappyTest\',{NAME=>\'info\',COMPRESESSION=>\'snappy\'}
通过上述命令进行创建一个使用压缩算法snappy的表,看是否能够创建成功,可以再通过一些数据读写操作进行验证
major_compact
参考:
<https://segmentfault.com/a/1190000013211406>