[spark]spark资源分配
Posted 胖胖学编程
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[spark]spark资源分配相关的知识,希望对你有一定的参考价值。
一、常用方法
1、查看集群有多少资源
hadoop2:9870

2、查看每个节点的线程数和内存大小
1)查看单个节点的总线程数

2)查看每个节点的内存大小

应该是32G
3)查看队列的内存占比(常用的是hive队列)
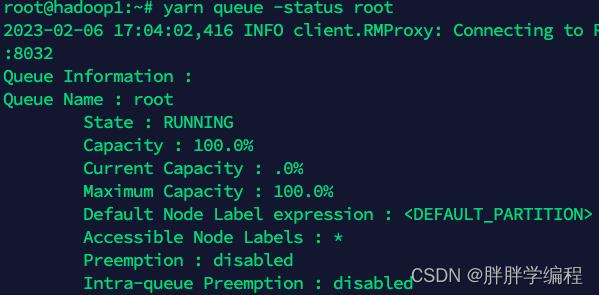
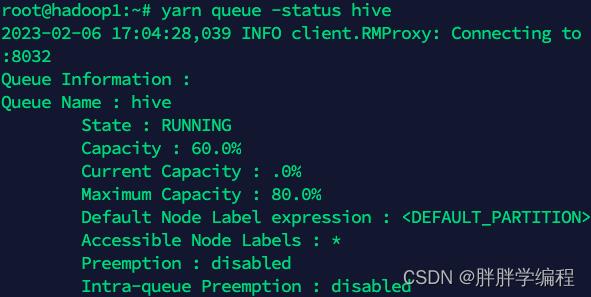
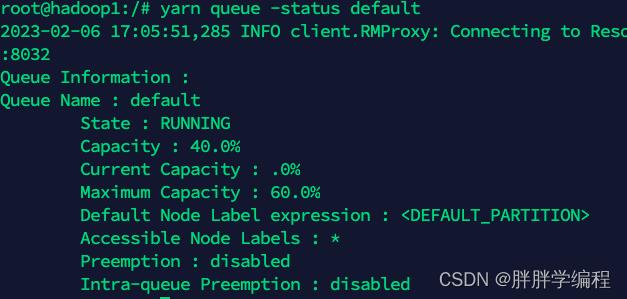
3、设置executor个数 每个executor的CPU个数 每个CPU的内存大小
注:这个集群4个节点,每个节点8个线程,每个节点内存为32G
1、确定executor的cpu核数
每个节点的cpu设置为4(一般为3-6)比较合适
2、确定每个节点executor数量
executor nums=该节点可用的总线程数/每个executor的cpu数=6/4=1
3、 确定没个executor内存数量
如果使用hive队列的话,占总集群的内存最大占比为60%-80%即19G-25G即最大使用25G内存,
每个executor内存数=该节点可用的总内存数/该节点executor数=16G/1=19G(这里因为executor num实在太小,所以随便选了16)
这里可以看出来,内存数/线程数=16/4=4
内存数与线程数不是严格按照1:2,或者1:4,这个需要看一下每个节点的可用资源,具体情况具体计算。
但是一般cpu:内存=1:2-1:4,阿里云封装的时候1CU = 1cpu+4G内存, 即1:4,该值是比较合理的。
4、其他人共享这个队列时
如果和其他人共享这个队列,那么num-executors*executor-cores不要超过队列总cpu cores的1/3-1/2比较合适。(1*4即4个节点共4个executor)*4=16,总cpu为32线程 8/16=1/2
二、问了两个同学,但是我感觉他们也不知道具体怎么计算
1、京东
executor要么1:2要么1:4
2cpu 4g或2cpu 8g
我感觉这中的是不是也得分是io密集的还是cpu密集(就是比较吃cpu)的
如果是io的话,就内存多点,如果是cpu的话,那就cpu密集
如果数据量大的话,就多给executor个数
2、百度
1、日常小任务
executor nums 50
executor cores 4
executor memory 4G
2、较大统计任务
executor nums 200
executor cores 4
executor memory 4G
3、复杂逻辑&大shuffle计算任务
xecutor nums 300
executor cores 4
executor memory 6G以上是关于[spark]spark资源分配的主要内容,如果未能解决你的问题,请参考以下文章