Android Dex文件格式
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Android Dex文件格式相关的知识,希望对你有一定的参考价值。
第三块: 数据区
索引区中的最终数据偏移以及文件头中描述的map_off偏移都指向数据区, 还包括了即将要解析的class_def_item, 这个结构非常重要,下面就开始解析
class_def_item:
这个结构由dex文件头中的classDefsSize和classDefsOff所指向, 描述Dex文件中所有类定义信息, 每一个DexClassDef中包含一个DexClassData的结构(classDataOff),
每一个DexClassData中包含了一个Class的数据, Class数据中包含了所有的方法, 方法中包含了该方法中的所有指令
//Direct-mapped "class_def_item". struct DexClassDef { u4 classIdx; //类的类型, DexTypeId中的索引下标 u4 accessFlags; //访问标志 u4 superclassIdx; //父类类型, DexTypeId中的索引下标 u4 interfacesOff; //接口偏移, 指向DexTypeList的结构 u4 sourceFileIdx; //源文件名, DexStringId中的索引下标 u4 annotationsOff; //注解偏移, 指向DexAnnotationsDirectoryItem的结构 u4 classDataOff; //类数据偏移, 指向DexClassData的结构 u4 staticValuesOff; //类静态数据偏移, 指向DexEncodedArray的结构 }; struct DexClassData { DexClassDataHeader header; //指定字段与方法的个数 DexField* staticFields; //静态字段 DexField* instanceFields; //实例字段 DexMethod* directMethods; //直接方法 DexMethod* virtualMethods; //虚方法 }; struct DexClassDataHeader { uleb128 staticFieldsSize; //静态字段个数 uleb128 instanceFieldsSize; //实例字段个数 uleb128 directMethodsSize; //直接方法个数 uleb128 virtualMethodsSize; //虚方法个数 }; struct DexMethod { uleb128 methodIdx; //指向DexMethodId的索引 uleb128 accessFlags; //访问标志 uleb128 codeOff; //指向DexCode结构的偏移 }; struct DexCode { u2 registersSize; 使用的寄存器个数 u2 insSize; 参数个数 u2 outsSize; 调用其他方法时使用的寄存器个数 u2 triesSize; Try/Catch个数 u4 debugInfoOff; 指向调试信息的偏移 u4 insnsSize; 指令集个数, 以2字节为单位 u2 insns[1]; 指令集 //followed by optional u2 padding //followed by try_item[triesSize] //followed by uleb128 handlersSize //followed by catch_handler_item[handlersSize] };
class_def_item:

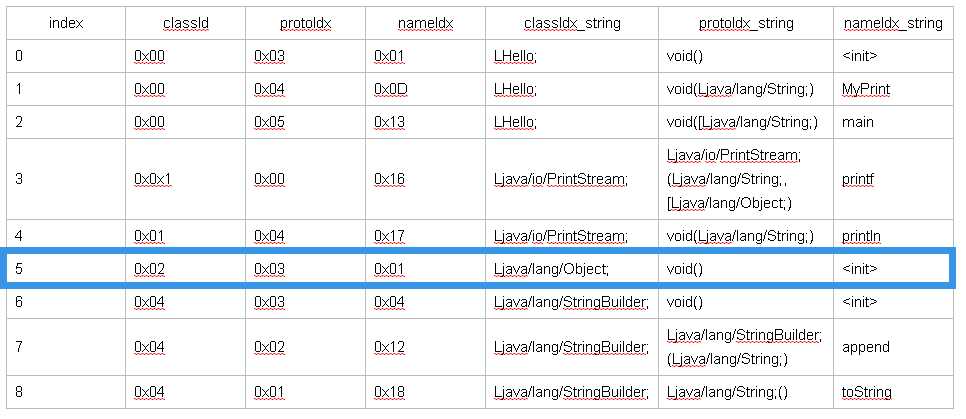
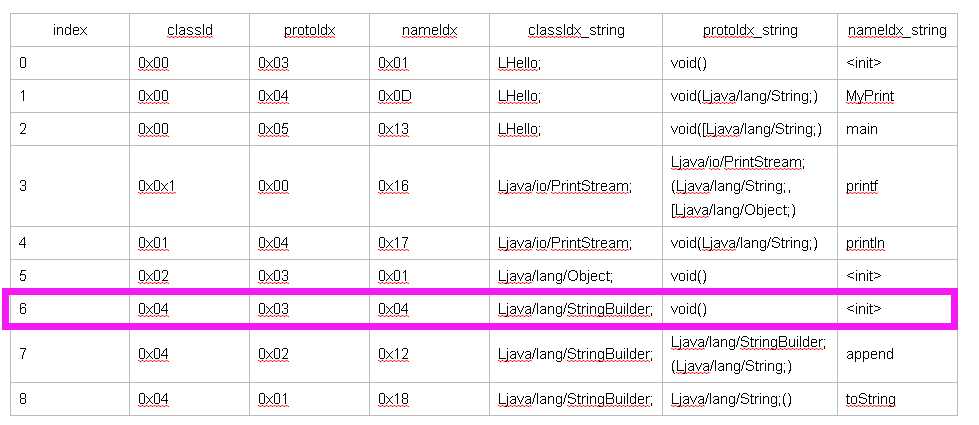
| index | classIdx | accessFlags | superclassIdx | interfacesOff | sourceFileIdx | annotationsOff | classDataOff | staticValuesOff |
| 0 | 0x00 | 0x01 | 0x02 | 0x00 | 0x03 | 0x00 | 0x388 | 0x00 |
| 0_string | LHello; | public | Ljava/lang/Object; | no interfaces | Hello.java | no annotations |

DexClassData的定义在源码的DexClass.h中, 在DexClass.h中的u4类型是uleb128类型, 在DexFile.h中的u4类型是unsigned int
所以这里DexClassDataHeader中的u4其实都是uleb128类型
在程序中,一般使用32位比特位来表示一个整型的数值。不过,一般能够使用到的整数值都不会太大,使用32比特位来表示就有点太浪费了。对于普通计算机来说,这没什么问题,毕竟存储空间那么大。但是,对于移动设备来说,存储空间和内存空间都非常宝贵,不能浪费,能省就省。
每个leb128由1~5字节组成, 所有字节组合在一起表示一个32位的数据, 每个字节只有7位有效, 如果第1个字节的最高位为1, 表示leb128需要使用到第2个字节, 如果第2个字节的最高位为1, 表示需要使用到第3个字节, 以此类推直到最后的字节最高位为0, 当然, leb128最多只会使用到5个字节, 如果读取5个字节后下一个字节最高位仍为1, 则表示该dex无效

这张图表示了,只使用两个字节进行编码的情况。可以看到,第一个字节的最高位为1,代表还要用到接着的下一个字节。并且,第一个字节存放的是整型值的最低7位。而第二个字节的最高位为0,代表编码到此结束,剩下的7个比特位存放了整型值的高7位数据。
例如uleb128编码的数据: c0 83 92 25
拆分为二进制
11000000 10000011 10010010 00100101
读取第1个字节0xc0(11000000), 其最高位为1, 表示需要继续读取第2个字节 (余下的7位: 1000000)
读取第2个字节0x83(10000011), 其最高位为1, 表示需要继续读取第3个字节 (余下的7位: 0000011)
读取第3个字节0x92(10010010), 其最高位为1, 表示需要继续读取第4个字节 (余下的7位: 0010010)
读取第4个字节0x25(00100101), 其最高位为0, 表示读取结束 (余下的7位: 0100101)
读取结束后, 按照读取的字节顺序将剩余的7位数据从右向左依次拼接起来即可:

最终拼得二进制数据: 0100101001001000000111000000
将其转换为十六进制数据: 0x4A481C0 即可得到当前uleb128编码的数据所表示的最终32位数据
在dalvik的源码中也有对uleb128数据读取的代码:
DEX_INLINE int readUnsignedLeb128(const u1** pStream) { const u1* ptr = *pStream; int result = *(ptr++); if (result > 0x7f) { int cur = *(ptr++); result = (result & 0x7f) | ((cur & 0x7f) << 7); if (cur > 0x7f) { cur = *(ptr++); result |= (cur & 0x7f) << 14; if (cur > 0x7f) { cur = *(ptr++); result |= (cur & 0x7f) << 21; if (cur > 0x7f) { cur = *(ptr++); result |= cur << 28; } } } } *pStream = ptr; return result; }
| index | staticFieldsSize | instanceFieldsSize | directMethodsSize | virtualMethodsSize |
| 0 | 0 | 0 | 3 | 0 |
DexMethod:

| index | methodIdx | accessFlags | codeOff |
| 0 | 0x0 | 0x10001 | 0x1B0 |
| 0_string | void LHello;-><init>() | public|constructor | |
| 1 | 0x01 | 0x09 | 0x1C8 |
| 1_string | void LHello;->MyPrint(Ljava/lang/String;) | public|static | |
| 2 | 0x01(看010Editor解析此处也是0x01) | 0x09 | 0x210 |
| 2_string | 但是字符串描述也是下表为0x02的信息 | public|static |
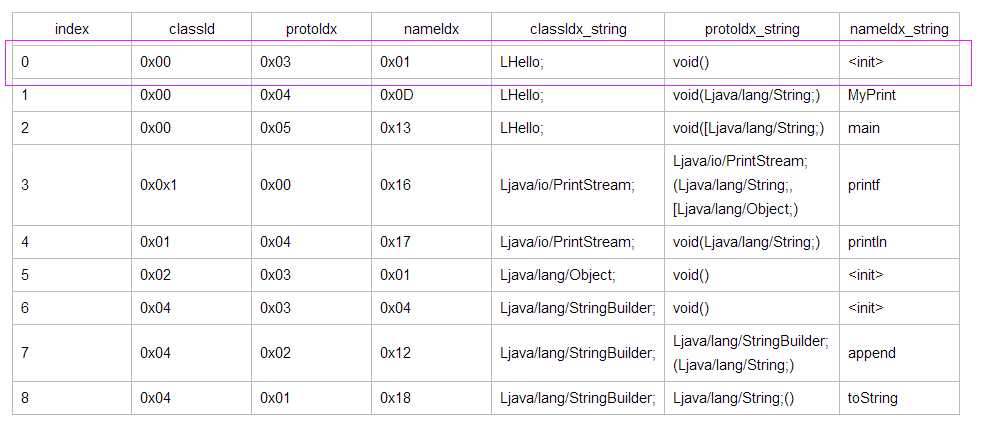
DexMethod表中下标1中成员methonIdx所指向的Method信息:
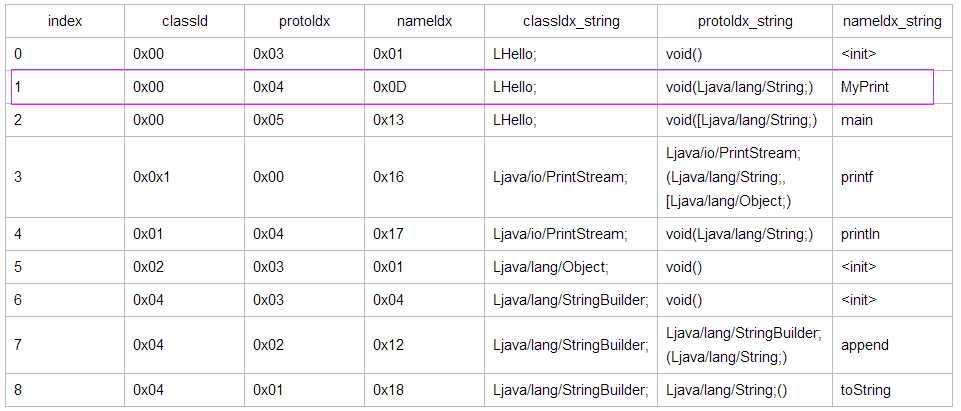
DexMethod中的codeOff指向的是DexCode的结构,描述了方法更详细的信息以及方法中指令的内容, 在这个结构中会涉及到Dalvik指令格式的解析
可以先了解一下Dalvik指令格式: http://www.cnblogs.com/dacainiao/p/6035298.html
| DexMethod_index | registersSize | insSize | outsSize | triesSize | debugInfoOff | insnsSize | insns |
| 0 | 0x01 | 0x01 | 0x01 | 0x00 | 0x372 | 0x04 | 0x70, 0x10, 0x05, 0x00, 0x00, 0x00, 0x0E, 0x00 |
| 1 | 0x04 | 0x01 | 0x03 | 0x00 | 0x377 | 0x1C | 0x62, 0x00, 0x00, 0x00, 0x22, 0x01, 0x04, 0x00, 0x70, 0x10, 0x06, 0x00, 0x01, 0x00, 0x6E, 0x20, 0x07, 0x00, 0x31, 0x00, 0x0C, 0x01, 0x1A, 0x02, 0x00, 0x00, 0x6E, 0x20, 0x07, 0x00, 0x21, 0x00, 0x0C, 0x01, 0x6E, 0x10, 0x08, 0x00, 0x01, 0x00, 0x0C, 0x01, 0x12, 0x02, 0x23, 0x22, 0x07, 0x00, 0x6E, 0x30, 0x03, 0x00, 0x10, 0x02, 0x0E, 0x00 |
| 2 | 0x03 | 0x01 | 0x02 | 0x00 | 0x380 | 0x0D | 0x1A, 0x00, 0x14, 0x00, 0x71, 0x10, 0x01, 0x00, 0x00, 0x00, 0x62, 0x00, 0x00, 0x00, 0x1A, 0x01, 0x02, 0x00, 0x6E, 0x20, 0x04, 0x00, 0x10, 0x00, 0x0E, 0x00 |
第一个方法 DexMethod_index: 0, void LHello;-><init>()
其指令集为: 0x70, 0x10, 0x05, 0x00, 0x00, 0x00, 0x0E, 0x00
根据Dalvik指令格式介绍, 每16位的字采用空格分隔开来, 每个字母表示四位, 每条指令的参数从指令第一部分开始,op位于低8位,高8位可以是一个8位的 参数,也可以是两个4位的参数,还可以为空,如果指令超过16位,则后面部分 依次作为参数
所以上述指令格式可以划分为: 0x70, 0x10 | 0x05, 0x00 | 0x00, 0x00 | 0x0E, 0x00
指令集格式采用小尾方式, 第一部分的低8位是 0x70 (op)
拿到op位后,查看Dalvik的官方文档, 在dalvik\\docs目录下 dalvik-bytecode.html 和 instruction-formats.html
查看dalvik-bytecode.html 对于0x70的定义

可以看到0x70表示为 invoke-direct, 而指令的格式编码为35c
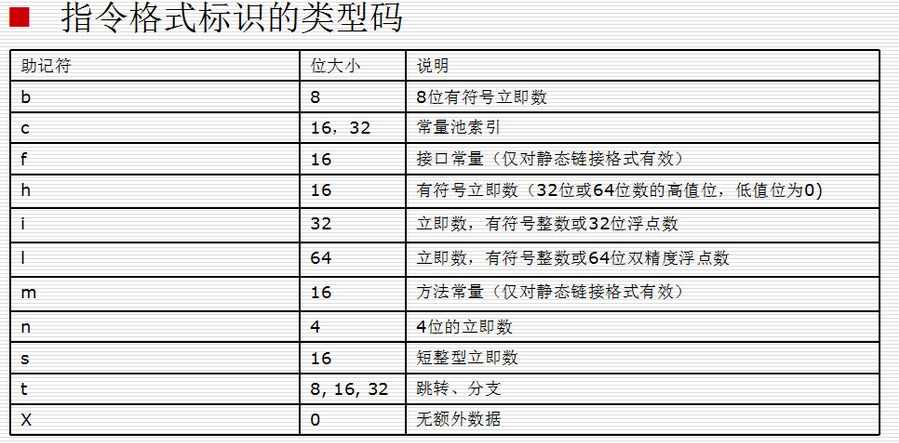
单独使用位标识还无法确定一条指令,必须通过指令格式标识来指定指令的格式编码。 它的约定如下:指令格式标识大多由三个字符组成,前两个是数字,最后一个是字母第一个数字是表示指令有多少个16位的字组成第二个数字是表示指令最多使用寄存器的个数。特殊标记“r”标识使用一定范围内的寄存器第三个字母为类型码,表示指令用到的额外数据的类型
所以当前的指令格式编码为35c表示
该条指令占用了3个16位
该条指令最多使用5个寄存器
该条指令有常量池索引
既然占用了3个16位,所以先将该条指令的3个16位拷贝过来
0x70, 0x10 | 0x05, 0x00 | 0x00, 0x00
查看instruction-formats.html对于类型码35c的定义

由于每个字母占用4位, 所以按照类型码35c的格式编码解析当前指令为
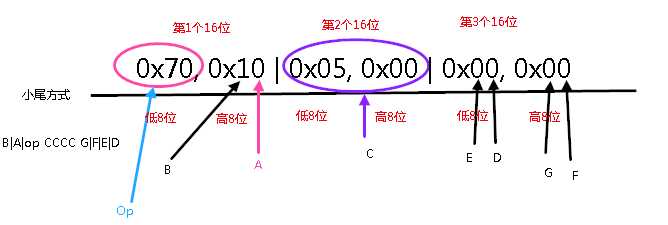
由于D = 0, 所以 {vD) == {v0}

C = 5, 在dalvik-bytecode.html 中对于0x70定义处有提到, C是方法列表的下标,占16位
所以[email protected] == void Ljava/lang/Object-->init()
最终该条指令解析为:
invoke-direct {v0}, Ljava/lang/Object-><init>V
然后继续解析剩下的指令: 0x0E, 0x00
还是一样的方法:
0x0E为低8位,所以为op位,查看dalvik-bytecode.html 关于0x0E的定义

指令的格式编码为10x, 表示
该条指令占用了1个16位
该条指令最多使用0个寄存器
该条指令无额外数据
最终该条指令解析为:
return-void
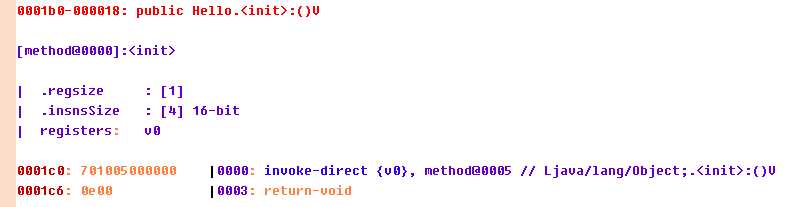
所以,第一个方法,DexMethod_index: 0, void LHello;-><init>(),的方法实现为:
invoke-direct {v0}, Ljava/lang/Object-><init>V
return-void
对照反编译工具的结果:
第二个方法 DexMethod_index: 1, void LHello;->MyPrint(Ljava/lang/String;)
其指令集为: 0x62, 0x00, 0x00, 0x00, 0x22, 0x01, 0x04, 0x00, 0x70, 0x10, 0x06, 0x00, 0x01, 0x00, 0x6E, 0x20, 0x07, 0x00, 0x31, 0x00, 0x0C, 0x01, 0x1A, 0x02, 0x00, 0x00, 0x6E, 0x20, 0x07, 0x00, 0x21, 0x00, 0x0C, 0x01, 0x6E, 0x10, 0x08, 0x00, 0x01, 0x00, 0x0C, 0x01, 0x12, 0x02, 0x23, 0x22, 0x07, 0x00, 0x6E, 0x30, 0x03, 0x00, 0x10, 0x02, 0x0E, 0x00
这里就不再赘述了, 都是按照上面的方法来解析的
0x62为op,62: sget-object 格式编码为 21c
2个16位(0x62, 0x00, 0x00, 0x00),最多1个寄存器, 常量表索引

a = 0, b = 0, B: static field reference index (16 bits)
b是field中的下标

最终解释为:
sget-object v0, Ljava/lang/System;.out:Ljava/io/PrintStream;
紧接着0x22为op, 22: new-instance vAA, [email protected], 格式编码为 21c
2个16位(0x22, 0x01, 0x04, 0x00),最多1个寄存器, 常量表索引

a = 1, b = 4
A: destination register (8 bits)
B: type index
最终解释为:
new-instance v1, Ljava/lang/StringBuilder;
紧接着0x70为op, 70: invoke-direct 格式编码为 35c
3个16位(0x70, 0x10, 0x06, 0x00, 0x01, 0x00), 最多5个寄存器,常量池索引

b = 1, a = 0, c = 6, f = 0, g = 0, e = 0, d =1
C: method index (16 bits)
[B=1] op {vD}, [email protected]
最终解析为:
invoke-direct {v1}, Ljava/lang/StringBuilder-><init>V
紧接着0x6E为op, 6e: invoke-virtual 格式编码为 35c
3个16位(0x6E, 0x20, 0x07, 0x00, 0x31, 0x00), 最多5个寄存器,常量池索引

b = 2, a = 0, c = 7, g = 0, f = 0, e = 3, d = 1
[B=2] op {vD, vE}, [email protected]
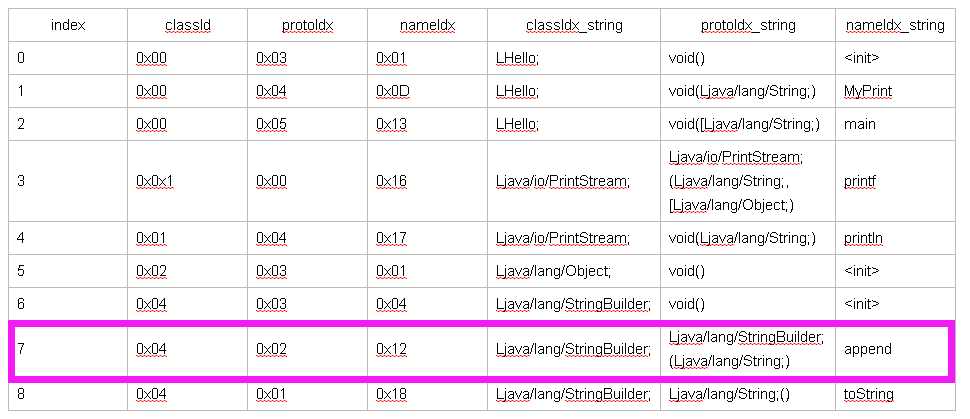
最终解析为:
invoke-virtual {v1, v3} Ljava/lang/StringBuilder->append( Ljava/lang/String;)Ljava/lang/StringBuilder
紧接着0c为op, 0c: move-result-object vAA 格式编码为11x
1个16位(0x0C, 0x01), 最多1个寄存器, 无额外数据

b = 0, a = 1
如果参数采用“+X”的方式表示,表明它是一个相对指令的地址偏移
最终解析为:
move-result-object v1
紧接着1a为op, 1a: const-string vAA, [email protected] 格式编码为21c
2个16位(0x1A, 0x02, 0x00, 0x00),最多1个寄存器,常量池索引
a = 2, b = 0
A: destination register (8 bits)
B: string index
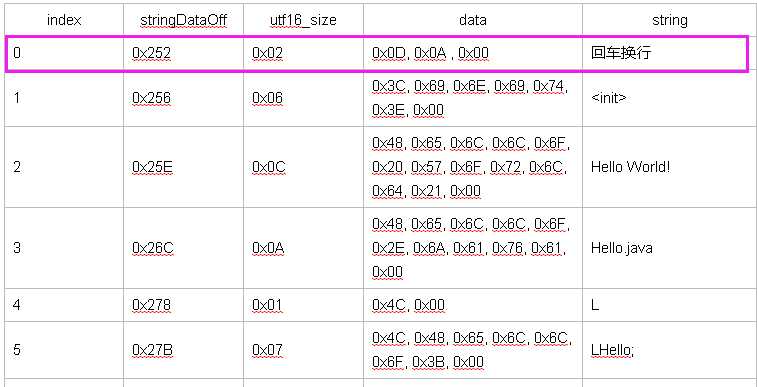
最终解析为:
const-string v2, "\\r\\n"
紧接着0x6E为op, 6e: invoke-virtual 格式编码为 35c
3个16位(0x6E, 0x20, 0x07, 0x00, 0x21, 0x00), 最多5个寄存器,常量池索引

b = 2, a = 0, c = 7, g = 0, f = 0, e = 2, d = 1
[B=2] op {vD, vE}, [email protected]
最终解析为:
invoke-virtual {v1, v2} Ljava/lang/StringBuilder->append( Ljava/lang/String;)Ljava/lang/StringBuilder
Dalvik指令解析方法大致就是这样,后面以此类推就可以,就不再继续解析了,解析这玩意太累。。。。
解析完dex之后我们有很多事都可以做了1、我们可以检测一个apk中是否包含了指定系统的api(当然这些api没有被混淆),同样也可以检测这个apk是否包含了广告,以前我们可以通过解析androidManifest.xml文件中的service,activity,receiver,meta等信息来判断,因为现在的广告sdk都需要添加这些东西,如果我们可以解析dex的话,那么我们可以得到他的所有字符串内容,就是string_ids池,这样就可以判断调用了哪些api。那么就可以判断这个apk的一些行为了,当然这里还有一个问题,假如dex加密了我们就蛋疼了。好吧,那就牵涉出第二件事了。2、我们在之前说过如何对apk进行加固,其实就是加密apk/dex文件内容,那么这时候我们必须要了解dex的文件结构信息,因为我们先加密dex,然后在动态加载dex进行解密即可3、我们可以更好的逆向工作,其实说到这里,我们看看apktool源码也知道,他内部的反编译原理就是这些,只是他会将指令翻译成smail代码,这个网上是有相对应的jar包api的,所以我们知道了dex的数据结构,那么原理肯定就知道了,同样还有一个dex2jar工具原理也是类似的4、 .....等等等等
Android Dex文件格式学习笔记pdf版下载:
链接: http://pan.baidu.com/s/1eR745Rs
密码: qqqk
参考资料:
<<Android软件安全与逆向分析>>
<<第1卷 Dalvik虚拟机结构剖析>>
<<实例分析dex>>
dalvik-bytecode
instruction-formats
以上是关于Android Dex文件格式的主要内容,如果未能解决你的问题,请参考以下文章