from flask import Flask, current_app app = Flask(__name__) a = current_app d = current_app.config[‘DEBUG‘]
首先从这段代码看起,代码运行的结果就是
RuntimeError: Working outside of application context.
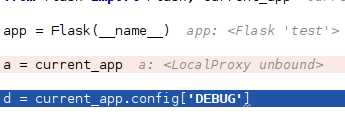
此时本地代理未绑定,不是我们想要的核心flask对象。代码报错。


current_app = LocalProxy(_find_app) request = LocalProxy(partial(_lookup_req_object, ‘request‘)) session = LocalProxy(partial(_lookup_req_object, ‘session‘)) g = LocalProxy(partial(_lookup_app_object, ‘g‘))
如何理解上下文
flask分为应用上下文(对Flask核心对象封装并提供方法)与请求上下文对象(对Request对象请求封装)两种。
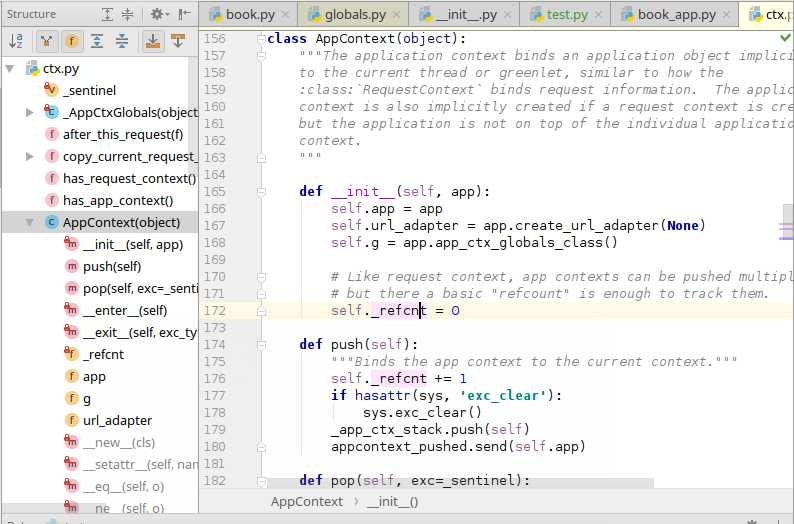
在flask源码的ctx下可以找到flask的AppContext与RequestContext。
class AppContext(object): """The application context binds an application object implicitly to the current thread or greenlet, similar to how the :class:`RequestContext` binds request information. The application context is also implicitly created if a request context is created but the application is not on top of the individual application context. """ def __init__(self, app): self.app = app # flask核心对象app self.url_adapter = app.create_url_adapter(None) self.g = app.app_ctx_globals_class() # Like request context, app contexts can be pushed multiple times # but there a basic "refcount" is enough to track them. self._refcnt = 0 def push(self): """Binds the app context to the current context.""" self._refcnt += 1 if hasattr(sys, ‘exc_clear‘): sys.exc_clear() _app_ctx_stack.push(self) appcontext_pushed.send(self.app) def pop(self, exc=_sentinel): """Pops the app context.""" try: self._refcnt -= 1 if self._refcnt <= 0: if exc is _sentinel: exc = sys.exc_info()[1] self.app.do_teardown_appcontext(exc) finally: rv = _app_ctx_stack.pop() assert rv is self, ‘Popped wrong app context. (%r instead of %r)‘ % (rv, self) appcontext_popped.send(self.app) def __enter__(self): self.push() return self def __exit__(self, exc_type, exc_value, tb): self.pop(exc_value) if BROKEN_PYPY_CTXMGR_EXIT and exc_type is not None: reraise(exc_type, exc_value, tb)
上下文对象包含了flask(封装路由,配置信息等等)等对象的同时,还包含了一些其他的对象,并提供方法供外部使用。我们使用flask与request对象并不意味着我们就要直接import导入,而是使用上下文调用。而在flask中我们,那怎么使用上下文呢?
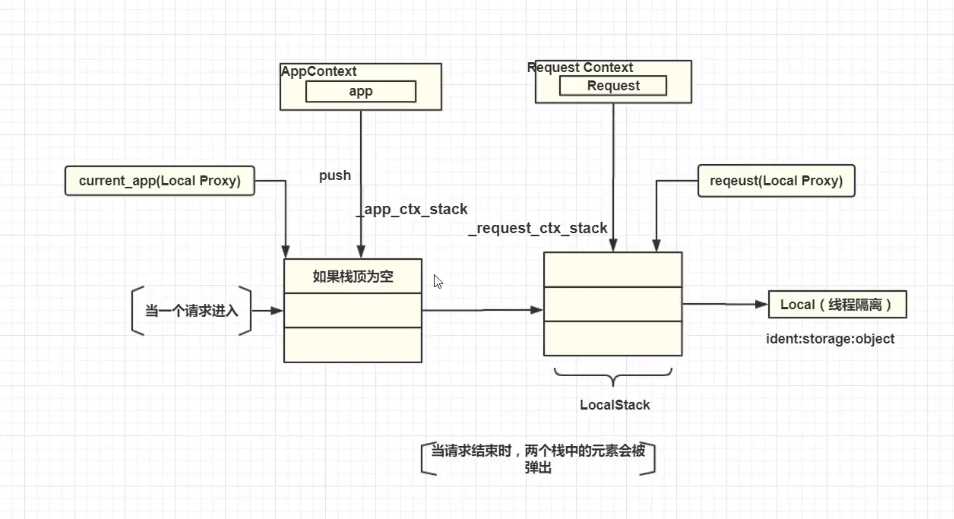
上图就是flask运行的核心机制,从请求进入flask开始。
第一步,接收到一个request请求。生成一个request context请求上下文(封装本次请求信息)。准备将上下文推入栈中。
第二步,在request入栈之前先去检查app_ctx_stack的栈顶,如果栈顶为空或者不是当前对象,那么将app上下文推入_app_ctx_stack栈。
第三步,并将上下文推入(上下文的push方法)LocalStack栈中(实例化为_request_ctx_stack)。
# context locals _request_ctx_stack = LocalStack() _app_ctx_stack = LocalStack()
request和current_app永远都是指向这两个栈顶的元素,操作他就是操作栈顶元素。
现在我们就可以解释开始的问题了,我们使用current_app时,没有请求进来,也没有request上下文生成入栈的过程,那么app上下文也就不会入栈,current_app拿到的栈顶上下文为空。所以结果是unbound。
current_app = LocalProxy(_find_app) def _find_app(): top = _app_ctx_stack.top if top is None: raise RuntimeError(_app_ctx_err_msg) return top.app # 返回给current_app就是一个app核心对象
request返回的也不是上下文对象,而是Request对象。
def _lookup_req_object(name): top = _request_ctx_stack.top if top is None: raise RuntimeError(_request_ctx_err_msg) return getattr(top, name) request = LocalProxy(partial(_lookup_req_object, ‘request‘))传入字符串就是request,partial就是执行_lookup_req_object
第四步,当请求结束,两个栈的元素会被弹出(pop)。
with app.app_context(): a = current_app d = current_app.config[‘DEBUG‘]
上下文里做了什么?
def __enter__(self): self.push() return self def __exit__(self, exc_type, exc_value, tb): self.pop(exc_value) if BROKEN_PYPY_CTXMGR_EXIT and exc_type is not None: reraise(exc_type, exc_value, tb)
with语句就是为了实现对资源管理。(连接数据库,sql,释放资源,当sql出了问题时释放资源就尤其的重要。)
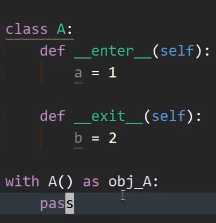
这里的A()是上下文管理器,as后面一定不是上下文管理器。而是enter方法返回的值。我们对实现上下文协议对象使用with,实现上下文协议的就是上下文管理器。上下文管理器必须有enter和exit。上下文表达式必须返回一个上下文管理器。
我们初始化是如何找到数据库连接的信息的,setdefault进行了防御性编程。
def init_app(self, app): """This callback can be used to initialize an application for the use with this database setup. Never use a database in the context of an application not initialized that way or connections will leak. """ if ( ‘SQLALCHEMY_DATABASE_URI‘ not in app.config and ‘SQLALCHEMY_BINDS‘ not in app.config ): warnings.warn( ‘Neither SQLALCHEMY_DATABASE_URI nor SQLALCHEMY_BINDS is set. ‘ ‘Defaulting SQLALCHEMY_DATABASE_URI to "sqlite:///:memory:".‘ ) app.config.setdefault(‘SQLALCHEMY_DATABASE_URI‘, ‘sqlite:///:memory:‘) app.config.setdefault(‘SQLALCHEMY_BINDS‘, None) app.config.setdefault(‘SQLALCHEMY_NATIVE_UNICODE‘, None) app.config.setdefault(‘SQLALCHEMY_ECHO‘, False) app.config.setdefault(‘SQLALCHEMY_RECORD_QUERIES‘, None) app.config.setdefault(‘SQLALCHEMY_POOL_SIZE‘, None) app.config.setdefault(‘SQLALCHEMY_POOL_TIMEOUT‘, None) app.config.setdefault(‘SQLALCHEMY_POOL_RECYCLE‘, None) app.config.setdefault(‘SQLALCHEMY_MAX_OVERFLOW‘, None) app.config.setdefault(‘SQLALCHEMY_COMMIT_ON_TEARDOWN‘, False) track_modifications = app.config.setdefault( ‘SQLALCHEMY_TRACK_MODIFICATIONS‘, None )
db.init_app(app)
db.create_all()
SQLAlchemy在实例化的时候没有将核心app绑定到db(SQLAlchemy的实例化对象),所以直接creat_all()并不能将db关联到核心app上。那么我们怎么完成db与app的绑定呢?
def create_all(self, bind=‘__all__‘, app=None):# self就是我们的db """Creates all tables. .. versionchanged:: 0.12 Parameters were added """ self._execute_for_all_tables(app, bind, ‘create_all‘)# 这里面将db与app绑定
def get_app(self, reference_app=None): """Helper method that implements the logic to look up an application.""" if reference_app is not None: return reference_app if current_app: return current_app._get_current_object() if self.app is not None: return self.app raise RuntimeError( ‘No application found. Either work inside a view function or push‘ ‘ an application context. See‘ ‘ http://flask-sqlalchemy.pocoo.org/contexts/.‘ )
第一种,将核心app传给create_all()作为参数,reference_app会得到hexinapp返回完成绑定。
db.init_app(app)
db.create_all(app=app)
def get_engine(self, app=None, bind=None): """Returns a specific engine.""" app = self.get_app(app) state = get_state(app) with self._engine_lock: connector = state.connectors.get(bind) if connector is None: connector = self.make_connector(app, bind) state.connectors[bind] = connector return connector.get_engine()
第二种,将上下文推入栈,current_app得到值后绑定。
with app.app_context():
db.create_all()
第三种,在实例化db的时候加入app。在这里我们采取其他方式。
class SQLAlchemy(object): """This class is used to control the SQLAlchemy integration to one or more Flask applications. Depending on how you initialize the object it is usable right away or will attach as needed to a Flask application. There are two usage modes which work very similarly. One is binding the instance to a very specific Flask application:: app = Flask(__name__) db = SQLAlchemy(app) The second possibility is to create the object once and configure the application later to support it:: db = SQLAlchemy() def create_app(): app = Flask(__name__) db.init_app(app) return app The difference between the two is that in the first case methods like :meth:`create_all` and :meth:`drop_all` will work all the time but in the second case a :meth:`flask.Flask.app_context` has to exist. By default Flask-SQLAlchemy will apply some backend-specific settings to improve your experience with them. As of SQLAlchemy 0.6 SQLAlchemy will probe the library for native unicode support. If it detects unicode it will let the library handle that, otherwise do that itself. Sometimes this detection can fail in which case you might want to set ``use_native_unicode`` (or the ``SQLALCHEMY_NATIVE_UNICODE`` configuration key) to ``False``. Note that the configuration key overrides the value you pass to the constructor. This class also provides access to all the SQLAlchemy functions and classes from the :mod:`sqlalchemy` and :mod:`sqlalchemy.orm` modules. So you can declare models like this:: class User(db.Model): username = db.Column(db.String(80), unique=True) pw_hash = db.Column(db.String(80)) You can still use :mod:`sqlalchemy` and :mod:`sqlalchemy.orm` directly, but note that Flask-SQLAlchemy customizations are available only through an instance of this :class:`SQLAlchemy` class. Query classes default to :class:`BaseQuery` for `db.Query`, `db.Model.query_class`, and the default query_class for `db.relationship` and `db.backref`. If you use these interfaces through :mod:`sqlalchemy` and :mod:`sqlalchemy.orm` directly, the default query class will be that of :mod:`sqlalchemy`. .. admonition:: Check types carefully Don‘t perform type or `isinstance` checks against `db.Table`, which emulates `Table` behavior but is not a class. `db.Table` exposes the `Table` interface, but is a function which allows omission of metadata. The ``session_options`` parameter, if provided, is a dict of parameters to be passed to the session constructor. See :class:`~sqlalchemy.orm.session.Session` for the standard options. .. versionadded:: 0.10 The `session_options` parameter was added. .. versionadded:: 0.16 `scopefunc` is now accepted on `session_options`. It allows specifying a custom function which will define the SQLAlchemy session‘s scoping. .. versionadded:: 2.1 The `metadata` parameter was added. This allows for setting custom naming conventions among other, non-trivial things. .. versionadded:: 3.0 The `query_class` parameter was added, to allow customisation of the query class, in place of the default of :class:`BaseQuery`. The `model_class` parameter was added, which allows a custom model class to be used in place of :class:`Model`. .. versionchanged:: 3.0 Utilise the same query class across `session`, `Model.query` and `Query`. """ #: Default query class used by :attr:`Model.query` and other queries. #: Customize this by passing ``query_class`` to :func:`SQLAlchemy`. #: Defaults to :class:`BaseQuery`. Query = None def __init__(self, app=None, use_native_unicode=True, session_options=None, metadata=None, query_class=BaseQuery, model_class=Model): self.use_native_unicode = use_native_unicode self.Query = query_class self.session = self.create_scoped_session(session_options) self.Model = self.make_declarative_base(model_class, metadata) self._engine_lock = Lock() self.app = app _include_sqlalchemy(self, query_class) if app is not None: self.init_app(app)
在实例化时是有app传进来的,但是在这个模块下,我们需要再导入app核心对象。在这样的业务环境下不推荐使用,但是我们可以这样操作:
db.init_app(app) db.app = app db.create_all()