文本分类之朴素贝叶斯算法
Posted 耶瞳
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了文本分类之朴素贝叶斯算法相关的知识,希望对你有一定的参考价值。
数据集如下,有两个特征共250条数据。数据集暂不提供下载。
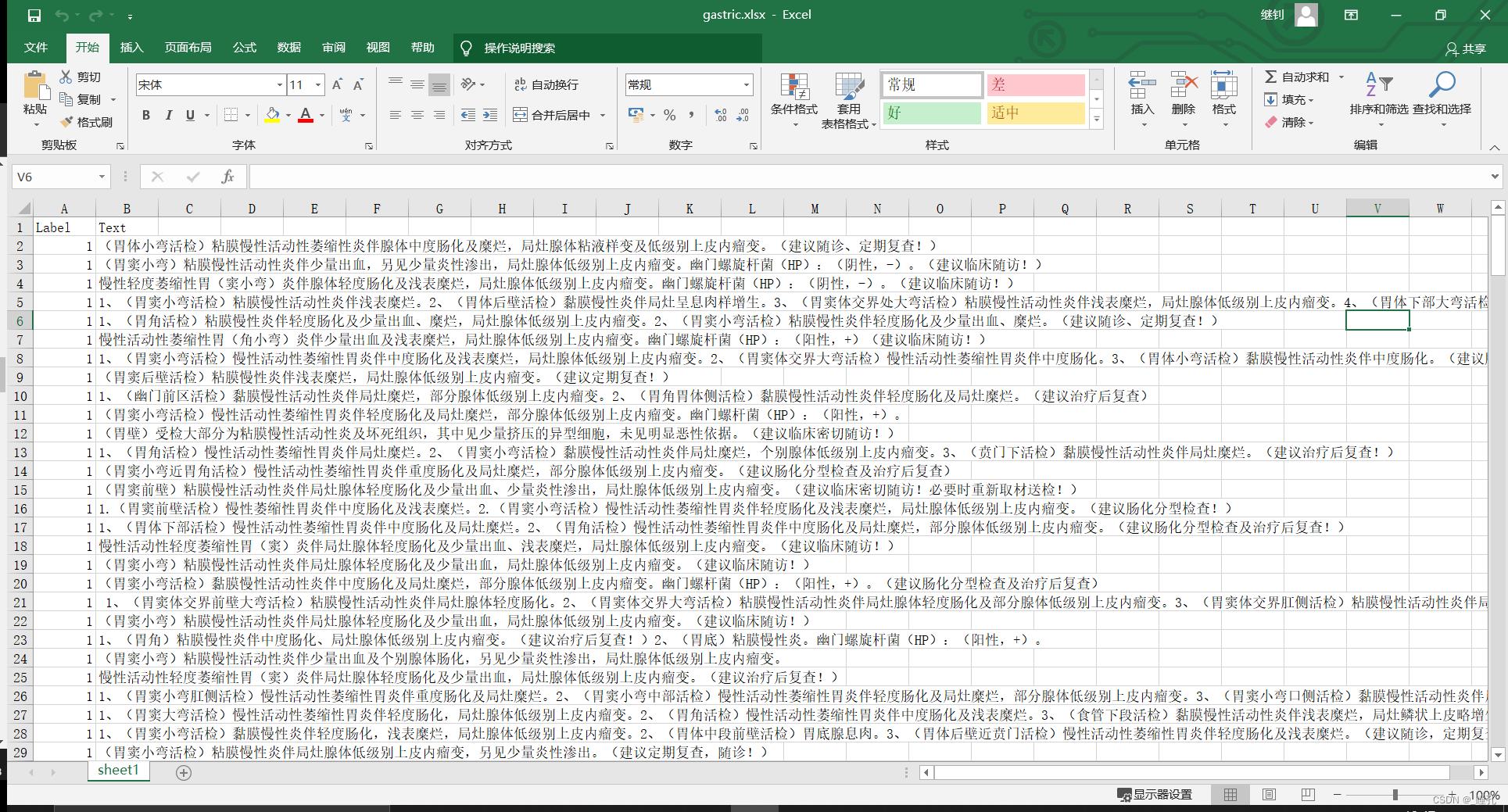
代码如下,人工智能小白,大佬轻喷。
import pandas as pd
import jieba.analyse
import random
# 数据预处理
data = pd.read_excel('gastric.xlsx')
dataMap =
dataSum = ""
labelFrequency = # 统计标签频率
for i in range(len(data.index.values)):
dataSum += data.loc[i].values[1]
if data.loc[i].values[0] in dataMap:
dataMap[data.loc[i].values[0]] += data.loc[i].values[1]
labelFrequency[data.loc[i].values[0]] += 1
else:
dataMap[data.loc[i].values[0]] = data.loc[i].values[1]
labelFrequency[data.loc[i].values[0]] = 1
# 计算标签频率
dataLen = len(data.index.values)
for i in labelFrequency.keys():
labelFrequency[i] /= dataLen
# 选取关键词
KWArray = jieba.analyse.extract_tags(dataSum)
KWSum = 0
for i in KWArray:
KWSum += dataSum.count(i)
# 统计词频率
KWFrequency =
for (k, v) in dataMap.items():
KWFrequency[k] =
for i in KWArray:
count = v.count(i)
if count == 0:
KWSum += 1
KWFrequency[k][i] = 1 / KWSum # 拉普拉斯平滑
else:
KWFrequency[k][i] = count / KWSum
# 构建朴素贝叶斯模型
def naiveBayes(test):
resArr = []
for ti in test:
# 统计词频
testKW =
for kwValue in KWArray:
kCount = ti.count(kwValue)
if kCount != 0:
testKW[kwValue] = kCount
# 计算概率
maxFreq = 0
maxLabel = 0
for (label, freq) in KWFrequency.items():
tFreq = labelFrequency[label]
for (tk, tq) in testKW.items():
tFreq *= pow(freq[tk], tq)
if tFreq > maxFreq:
maxFreq = tFreq
maxLabel = label
resArr.append(maxLabel)
return resArr
# 构建测试数据
testArray = []
testLabelArray = []
for i in range(len(data.index.values)):
if random.random() < 0.2:
testLabelArray.append(data.loc[i].values[0])
testArray.append(data.loc[i].values[1])
# 计算准确率
resArr = naiveBayes(testArray)
trueNum = 0
for i in range(len(testArray)):
if resArr[i] == testLabelArray[i]:
trueNum += 1
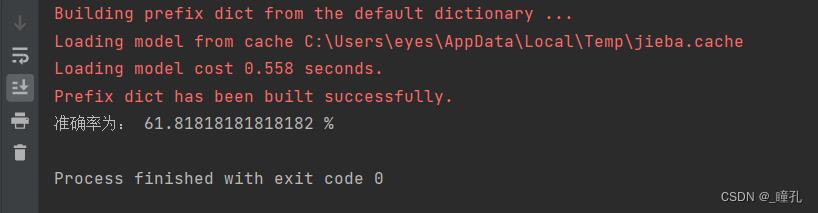
print("准确率为:", 100 * trueNum / len(testArray), "%")
如果有兴趣了解更多相关内容,欢迎来我的个人网站看看:瞳孔空间
以上是关于文本分类之朴素贝叶斯算法的主要内容,如果未能解决你的问题,请参考以下文章