MYSQL优化
Posted scanner小霸王
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MYSQL优化相关的知识,希望对你有一定的参考价值。
客户端发送请求,例如:select,服务端做了哪些操作
mysql服务端逻辑分层有三层:连接层、服务层、引擎层
三层的作用如下:

引擎
InnoDB和MyISAM主要的区别
InnoDB:事务优先(适合高并发,行锁:每条数据都要锁,所以性能就降低了)
MyISAM:性能优先(表锁)
-- 查找存在的引擎
show ENGINES;
-- 当前默认的
show VARIABLES like '%storage_engine%';
sql优化
编写和解析的过程

优化sql,主要就是优化索引:
索引:数据结构(树:B树(默认),hash树…)
索引弊端:
1)索引很大,可以存在内存和硬盘(通常较为硬盘)
2)并非索引情况均使用:a.少量数据 b,频繁更新的字段, c.很少使用的字段不适合添加索引
3)索引会降低增删改的效率;(因为增删改的时候需要维护索引的数据)
优势:
1)提高查询的效率(客户端连接服务端是使用io
的,所以采用索引降低了IO的使用率)
2.降低CPU使用率(…order by age desc,因为B树索引 本身就是 一个排好序的结构,因此在排序的时候,可以直接使用)
B+树
数据一般都是全部存放在叶节点,所以b+树查询任意的数据次数:n次
索引
分类:
1)单值索引:单列,一个表可以多个单值索引
2)唯一索引:不能重复, id
3)复合索引
创建索引:
主键索引:单列,不能为null,唯一索引可以为null

SQL性能优化


1)id相同,自上而下执行,id越大越优先查询
2)select_type

SELECT b.book_name,b.isbn,b.price
from book b
where b.isbn =
(SELECT bs.isbn from book_stock bs where bs.FaccountID=
(SELECT a.accountId from account a WHERE a.username='Jerry')
)
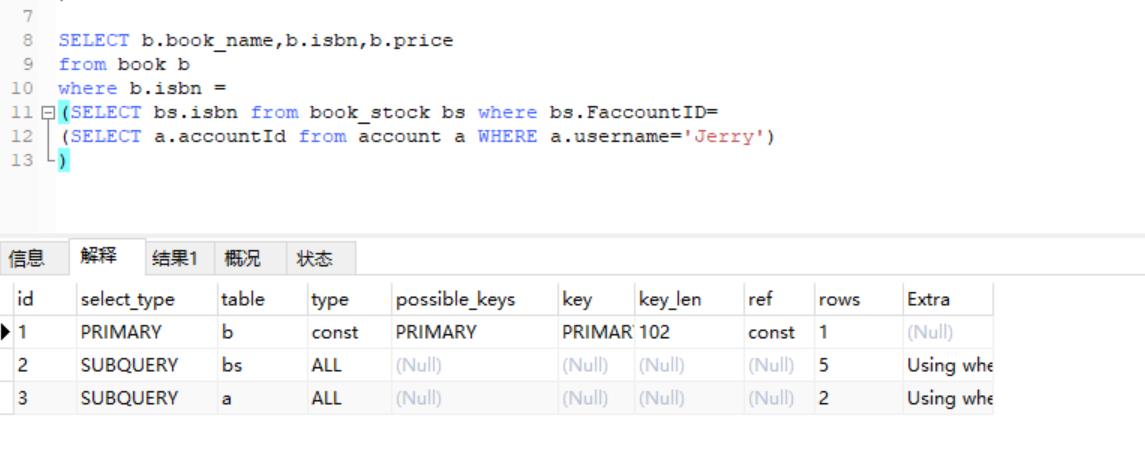
PRIMARY:表示主查询,这里 id=1为主查询,即最外层
SUBQUERY:包含在子查询sql中子查询(非最外层)
**derived:**衍生查询(使用到了临时表)
**union result :**那些表存在联合查询
ii)from子查询只有一张表

ii)在from子查询中,如果table1 union table2 ,则table1就是derived

3).type(约往左越高)
system>const>eq_ref>ref>range>index>all
其中:system,const只是理想;
对type优化的前提是有索引
system:只有一条数据的系统表,或衍生表只有一条数据的主查询
const:仅仅能查到一条数据的SQL,用于主键或者唯一索引
eq_ref:唯一性索引,对于每个索引键的查询,返回匹配唯一行数据(有且只有一个)
ref:非唯一性索引,返回匹配所有行(0,多)
range:检索范围的行,between,in >、 >= ,<.<= ,
但是 in有时候会导致索引失效,失效就是all
index:查询全部索引的数据
all:查询全部表中的数据

4)possible_keys:可能用到的索引
5)key:实际用到的索引
6)key_len:索引的长度;经常用于判断符合索引是否被完全使用(a,b,c)
在utf-8:1个字符占3个字节,所以 name char(20)对应的key_len为60,name is not null;
如果name 字段可以为null,对应的key_len为61,其中一个字节用来标识可以为null

使用name1时候,会先用name
mysql用1个字节表示null,用两个字节表示可变长度varchar
utf-8:1个字符3个字节
gbk:1个字符2个字节
latin:1个字符1个字节

7)ref:注意和type的ref区分


8)rows:被索引优化查询的个数
9)Extra:
ii)using filesort:表示性能消耗大,需要额外的一次排序,一般出现在order by

对于单索引,如果排序和查找是同一个字段,则不会出现using filesort;反之,则会。
避免:where 哪些字段就order by 哪些字段
对于复合索引:不能跨列(最佳左前缀)

ii)using temporary:性能损耗大,用到了临时表,一般出现在group by

ii)using index:性能提升:索引覆盖,只从索引获取数据

ii)using where (需要回表)
ii)impossible where: a1不可能既为x也为y

sql优化例子

第一条sql为推荐写法,第二条sql虽然和索引的顺序不一致,但是经过sql优化器之后,和第一条一样的效果;

符合索引的时候,a1,a2使用索引
a3跳过了,a4跨列了,索引无效,回表查询,这也是为啥Extra也一部分是using where,一部分是using index

where 和order by 拼接起来的复合索引的顺序不会跨列,则不会出现using filesort
总结:
ii)如果(a,b,c,d)复合索引 和使用的顺序全部一致,则符合索引全部生效;
如果(a,b,c,d)复合索引 和使用的顺序部分一致,则符合索引部分生效;
ii)where 和order by 拼起来不要跨列使用
单表案例分析
分析下列代码
SELECT isbn
from book b
where b.book_name in('book01','book02')
and b.price=200
order by book_name
执行结果:

问题:
type =all extra =Using where; Using filesort
解决:
1)加索引:
alter table book add index index_book(isbn,book_name,price);
type = index

2)根据索引的解析顺序,应该先where ,oder by,select,调整索引的顺序
alter table book add index index_book(book_name,price,isbn);
得到了优化,少了using filesort

3)再次优化(之前是index级别):
因为in可能会索引失效,以之前的顺序,in失效,后面几个也会跟着失效,所以调整一下顺序,type提升为ref
SELECT isbn
from book b
where b.price=200
and b.book_name in('book01','book02')
order by book_name
这里出现using where 的原因是in 使索引失效,去原表找数据

小结:a.索引不能跨列使用(最佳左前缀,)
b.索引需要逐步优化,
c.将含in的范围放在后面
双表优化案例
select *
from book b
LEFT OUTER JOIN book_stock bs
on b.isbn = bs.isbn
索引往哪张表加:
–小表驱动大表
–索引加在经常使用的字段上**(加在左边上)**
where 小表.x 10 = 大表.y 300;
当编写where 小表.x 10 = 大表.y 300;数据量小的表放左边
1)没加索引的时候
using join buffer :说明sql写的太差,mysql加了链接缓存

2)加上索引
alter table book add index index_book(id_bs);
alter table book_stock add index index_book_stock(FaccountID);

小结:

如果一定要用like '%x%'进行模糊查询,一定要用索引覆盖,select tname


其他的一些优化方法:
1)exist和in

2)order by 优化
select name ,age from …order by id;

sql排除—慢查询日志
mysql提供一种日志记录,用于记录mysql响应时间超过阈值的sql(默认10秒,long_query_time);
慢查询日志默认是关闭的
开启慢查询日志
设置慢查询阈值:

查询超过阈值的sql

锁机制
解决因资源共享 而造成的并发问题
示例:

分类:
操作类型:
**a.读锁(共享锁):**对同一个数据(衣服),多个读操作可以同时进行,互不干扰
**b.写锁(互斥锁):**如果当前写操作没有完毕(买衣服的一系列操作),则无法进行其他的读、写操作
操作范围:
a.表锁
一次性对一张表整体加锁,如:MyISAM存储引擎使用表锁,开销小、加锁快、无死锁;但锁的范围大,容易发生所冲突、并发度低
b.行锁:
一次性对一条数据进行加锁。如InnoDb存储引擎使用行锁,开销大,加锁慢容易发生死锁;锁的范围较小,不易发生锁冲突,并发度高(很小概率发生高并发问题(脏读,不可重复读、幻读等问题))
c.页锁:
锁的语法
增加锁:
locak table 表1 read/write,表2 read/write,…
查看锁的表:
show open tables;
加读锁:
当前会话当中,如果对book表加了读锁,则只能对A表进行读取操作、无法对A表进行其他操作,也无法对其他表进行操作(包括读操作);

另外一个会话可以对A表进行读取操作,当是对A表进行写操作时候,将进入等待,直到上一个会话释放锁;而在另外一个会话当中,不影响对其他表的读写操作

释放锁:
只有当前会话释放锁之后,
UNLOCK tables;
另外一个会话才会执行
以上是关于MYSQL优化的主要内容,如果未能解决你的问题,请参考以下文章