Faster RCNN交替训练法详解
Posted mazinkaiser1991
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Faster RCNN交替训练法详解相关的知识,希望对你有一定的参考价值。
对Faster RCNN的详解类文章实在是数都数不过来,这些详解类的文章大多是从网络结构角度出发,对于Faster RCNN的训练流程介绍的比较少。从我个人的经历来看,感觉单纯的理解网络结构对Faster RCNN理解的还不够透彻,尤其是生成有效anchor这一块。因此本文从Faster RCNN的训练流程这个角度出发,对Faster RCNN进行详解,重点对anchor相关的操作进行细致分支。
本文采用的训练流程不是基于某个实现,而是基于原论文中3.2小节中给出的“4-Step Alternating Training”(四步交替训练流程)。
“4-Step Alternating Training”,四步交替训练流程如下:
-
训练RPN
RPN的详细训练方法在3.1.3节有详细介绍:从每幅图片中生成训练所需的每组mini-batch数据。每组mini-batch包括若干的正样本与负样本,考虑到正负样本平衡的问题,每组mini-batch不是使用所有的样本,而是随机采集256个样本构成一组mini-batch,正样本与负样本数量尽量保持1:1,如果达不到的话,也即正样本数量不足128的话,就使用负样本补齐。对于损失函数在此不做分析。
至此RPN的训练方法已经非常清楚了,接下来就是搞清楚什么是正负样本。在本文中正负样本被称为anchor,对于正负anchor的定义在文章的3.1.2节,正anchor的定义包括两种情况:与groundtruth的IoU最大的anchor,与任何groundtruth的IoU大于0.7anchor。以上两种情况都被作为正anchor,其实只有第二种情况基本已经足够,但为了保证不会出现一幅图片一个正anchor都没有的情况,所以又添加了第一种情况。负样本是指与groundtruth的IoU的小于0.3的。IoU大于0.3小于0.7的,或者不是正样本的感觉就不参与训练。
但是问题又来了,这个anchor不是在最后一层feature map上滑窗获得的吗,怎么和groundtruth算IoU?其实理解这个问题需要理解一个关键概念“ROI Projection”,这个概念不是我自己造的,是在SPPnet这篇文章的最后附录里提到的一个概念:

有兴趣可以仔细的研读这一段。给大家总结一下,Feature map与原图的坐标可以相互转化,转化公式如下,定义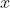 ,
,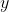 为原图上的点,
为原图上的点, ,
, 为该图经过卷积与池化操作后得到的feature map:
为该图经过卷积与池化操作后得到的feature map:
Feature map To origin image

其中S是经过卷积与池化操作后得到的缩放倍数。由这里还有一个重要前提,这个公式成立的前提是做卷积操作时需要对图做kernel size/2向下取整的padding操作。之所以要做这样一步,是为了经过卷积操作后原图大小保持不变,而经过池化操作后原图大小变为原来的1/4,经过几次池化,就变为原图大小的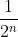 。
。
至此已经分析完了,一个anchor与原图上一个点的对应关系,这还不够,仅靠一个anchor还无法学习不同尺度的物体特征,因此本文中一个anchor对的是原图上9个不同大小的采样框。具体来说就是3种不同的大小与3种不同的长宽比,原文中给出的三种不同大小是128*128,256*256,512*512,三种不同的长宽比是1:1,1:2和2:1。
以128*128大小举个例子,1:1大小非常好理解,就是128*128大小的采样框,以这个大小为滑窗在原图上滑动,在每个滑动位置查看是否有groundtruth为正样本,或者是负样本。好了滑窗大小我们已经有了,滑窗位置我们就可以根据上面的公式算出在原图上的位置。比如对于feature map上的(0,0)点,其在原图上的坐标还是(0,0),滑窗就是应该是(-64,-64,64,64)以上四个值分别为(left_top_x,left_top_y,right_buttom_x,right_buttom_y)。这个计算方法对不对?可以通过作者给出的实现的示例进行验证(从我看到的一些资料上看,有一个generate_anchor.py可以生成(0,0)点处的anchor,我没有跑这个程序,直接把结果贴出来):
[[ -84. -40. 99. 55.]
[-176. -88. 191. 103.]
[-360. -184. 375. 199.]
[ -56. -56. 71. 71.]
[-120. -120. 135. 135.]
[-248. -248. 263. 263.]
[ -36. -80. 51. 95.]
[ -80. -168. 95. 183.]
[-168. -344. 183. 359.]]通过对比可以发现,第四行的结果就是大小为128*128,长宽比为1:1,中心点坐标为(0,0)处的采样框。
通过以上过程就可以大约生成共20000个采样框,此处以文中给出的例子为例,原图大小为1000*600,经过4次卷积与池化操作后,生成的feature map大小约为60*40(1000/16=62.5,600/16=37.5),每个feature map像素对应有9个anchor,所以共有约60*40*9,共20000个采样框,去除掉出图的采样框还剩约6000个。
至此所有的采样框已经生成完毕,从6000个anchor中随机采样选出256个候选框用于训练RPN网络,至此RPN网络的训练流程就分析完了。其实Faster RCNN的核心内容至此已经分析的差不多了。
总结一下:训练RPN送入网络的是256个候选框,groundtruth是与之配对的boundingbox,对于负样本就没有boundingbox就没有回归框任务,只有分类任务。我们可以发现为了选择候选框,一共进行了3次选择:
1)首先是生成了大约20000个候选框。
2)去除掉其中与边缘相交的,选择其中大约6000个。
3)最后在6000个中选择其中256个用于训练。
特别注意:训练RPN的过程是没有“generate proposal”的过程的,也就是不会有NMS的过程。以何为证:stage1_rpn_train.pt文件中就没有“ProposalLayer”层。先说stage1_rpn_train.pt文件,这个文件是FasterRCNN原版实现中交替训练法的prototext文件,“ProposalLayer”层的定义位于“proposal_layer.py”文件中,其功能是根据RPN生成的候选框应用NMS算法进行过滤,生成最终的候选框。“generate proposal”其实是在RPN训练之后,Fast RCNN训练之前,其结果全部写到硬盘中。
-
训练Fast RCNN
此时使用RPN产生的候选框互相之间交叠会比较大,也即冗余非常多,所以要对RPN产生的候选框执行进一步执行NMS操作,这正是“ProposalLayer”层的作用。
ProposalLayer的作用不仅限于应用NMS,在应用NMS前首先对RPN的结果进行过滤。首先对大约20000个anchor的回归框结果进行过滤,过滤的标准是proposal的height与width均需要大于RPN_MIN_SIZE。
然后应用NMS。NMS的排序标准是分类的分数(此处是正负候选框的分数),NMS阈值是0.7,经过这一步操作后大约还剩2000个候选框,选择其中top-N个框训练Fast RCNN网络。
其中有两个重要的参数:RPN_PRE_NMS_TOP_N、RPN_POST_NMS_TOP_N又分为train、test,train的值分别为12000,2000,也即在训练Fast RCNN过程中,使用已经训练好的RPN网络生成proposal,在对框进行过滤后、应用NMS前保留其分数最高的前12000个框,应用NMS后保留正类样本的2000个框。test的值分别为6000,300。应用方式相同。
有了NMS的结果,就可以用于替代原来Fast RCNN中使用的Selective Search算法生成候选。这一步不再训练RPN而是利用RPN产生region proposal,将region proposal送入Fast RCNN进行训练。此时Fast RCNN与RPN还不共享卷积层参数,是两个完全独立的网络。
-
finetune RPN
为了finetune RPN首先,使用Fast RCNN的参数初始化RPN,同时保持RPN与Fast RCNN共享的参数保持不变,仅finetune RPN自己的层,通过以上操作,RPN就与Fast RCNN共享卷积层参数。
-
finetune Fast RCNN
保持共享的卷积层参数保持不变,仅finetune Fast-RCNN自己的层。
以上是关于Faster RCNN交替训练法详解的主要内容,如果未能解决你的问题,请参考以下文章