计算机视觉中的深度学习11: 神经网络的训练2
Posted SuPhoebe
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了计算机视觉中的深度学习11: 神经网络的训练2相关的知识,希望对你有一定的参考价值。
Slides:百度云 提取码: gs3n
接着第10讲继续
总览
- 单次设置
- 激活函数
- 数据预处理
- 权重初始化
- 正则化
- 动态训练
- 学习率规划
- large-batch 训练;
- 超参数优化
- 训练后
- 模型融合
- 迁移学习
今天将介绍第二点和第三点。
学习率规划
我们有多种梯度下降的方式:SGD, SGD+Momentum, Adagrad, RMSProp, Adam
对于这些梯度下降的方式,学习率都是一个超参数。我们要怎么选取一个合适的学习率呢?
对于任何的方式,初始情况下,我们都应该选择较大的学习率,随着训练轮数的增加而逐渐减少。
下降方式:固定轮数
每隔几轮,按照一定比例下降。
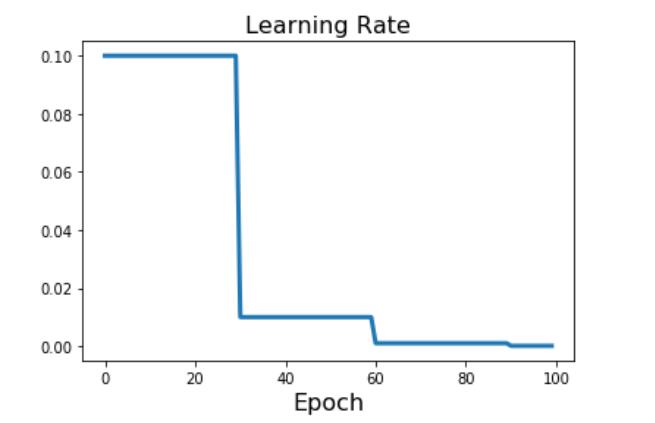
上图是每30轮,将学习率乘以0.1
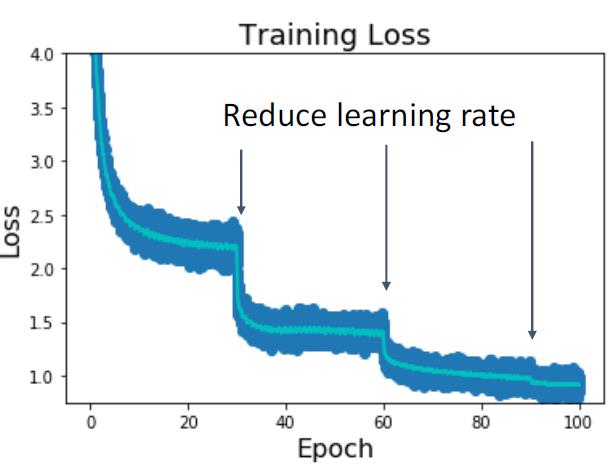
下降方式:Loss不变
有很多人可能会这样选择
一开始选择很大的learning rate 然后训练很长时间。这个很长时间指的是,当Loss不再变化之后(或者变化平
缓之后)。再进行learning rate的改变。
下降方式:cos
学习率
α t = 1 2 α 0 ( 1 + c o s ( t π / T ) ) \\alpha_t = 1\\over 2\\alpha_0(1+cos(t\\pi/T)) αt=21α0(1+cos(tπ/T))
别看引入了不少变量,但是并没有增加新的超参数。一个是初始的学习率,一个是T

下降方式:线性
α t = α 0 ( 1 − t / T ) \\alpha_t = \\alpha_0(1-t/T) αt=α0(1−t/T)
这在自然语言处理的NN中经常被用到

下降方式:除根方
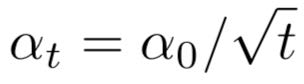
缺点:learning rate下降太快了;导致在高Learning rate的时间非常短

下降方式:不改变
α t = α 0 \\alpha_t=\\alpha_0 αt=α0
自适应learning rate有众多好处,但是也因为其复杂性,容易出现问题
也许更简单的方式也能获得不错的结果。
同时,对于训练结果的准确性而言,几种方式都没有太多的区别。只可能有几个百分点的改善。当你的模型被优化到极致的情况下,除了优化learning rate没有任何其他的方法的时候,可以尝试进行改善。
从没有因为采用了constant的方式而导致模型不能运行不能收敛的情况。
提前停止 Early Stopping
当验证集的准确性降低时,停止训练
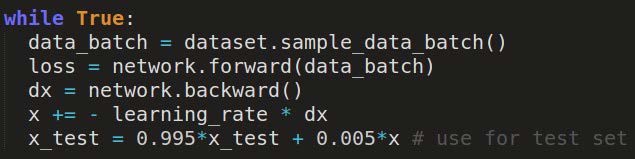
或长时间训练,但始终保留在验证集上效果最好的模型snapshot。
这永远是个值得采用的方式。

超参数选择
网格搜索 vs 随机搜索
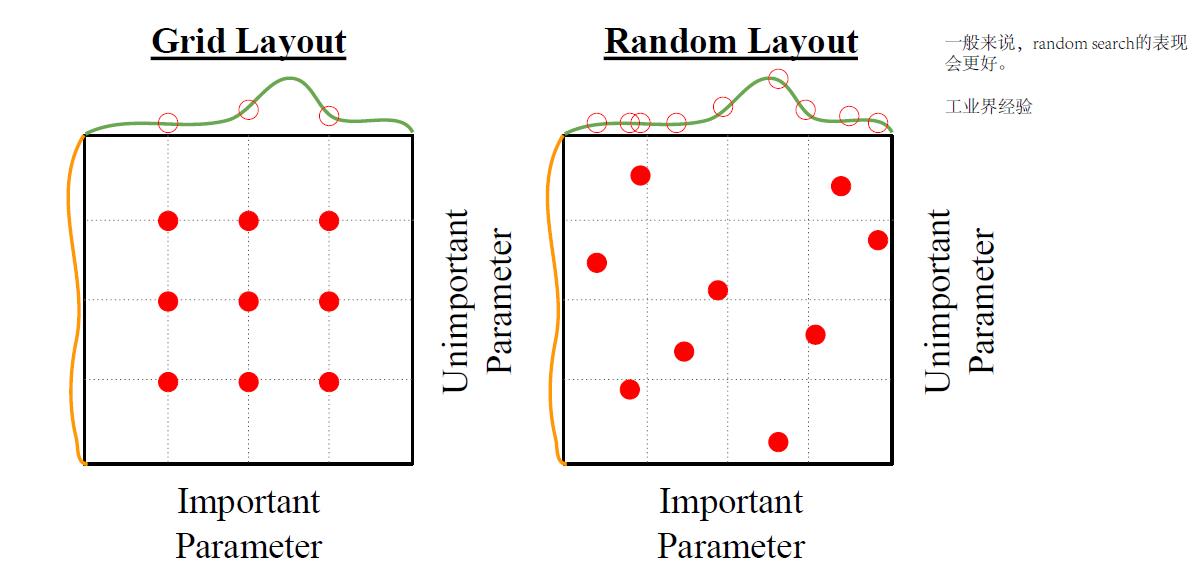
请务必选择随机搜索,在效果上远比网格搜索快得多。这在我待过的多个公司的试验中都有相似的结论(我不太懂他们有没有发论文)
步骤1:检查初始Loss
通过数学模型(基于你的Loss函数),计算出理论上的Loss函数的大小。
比如, softmax 对应C个类别 log©
步骤2:在小数据集上overfit
找出能够让你最快overfit的参数(关闭regularization)
试着在一个比较小的数据集上获得100%的训练准确率(因为数据集非常小,所以能够在很短时间内收敛,并达到100%正确),试一些NN结构,学习率,权重初始化等等(采用之前的随机选取的方式)。
- Loss不下降?LR太小了,权重初始化太差了
- Loss变成了INF?LR太大了,权重初始化太差了
步骤3:选择一个能让Loss下降的LR
在前面的结构下,用全数据集,找到一个LR可以让Loss在100轮左右的训练中迅速下降。
值得一试的是,1e-1, 1e-2, 1e-3, 1e-4
步骤4:网格搜索
在你的2,3步得到一定参数的情况下,在他们周围进行一定的试探。这些组合是非常非常少的,而且为通常这样
选择会使得你的参数大都可用,不会因为选择奇怪的参数而导致模型非常糟糕。
这样能让你在周围试探出一些可能更好的参数。
步骤5:进行长时间的训练
选出一些你觉得不错的超参数的组合,进行更长时间的训练,10到20轮的全数据训练。
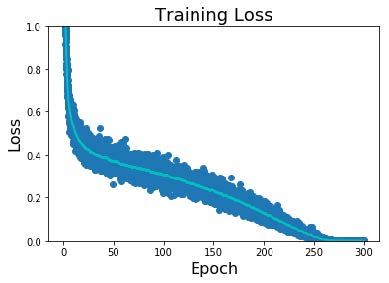
步骤6:观察学习曲线
Loss曲线可能很嘈杂,请使用散点图并绘制移动平均线以更好地查看趋势
一些经验:
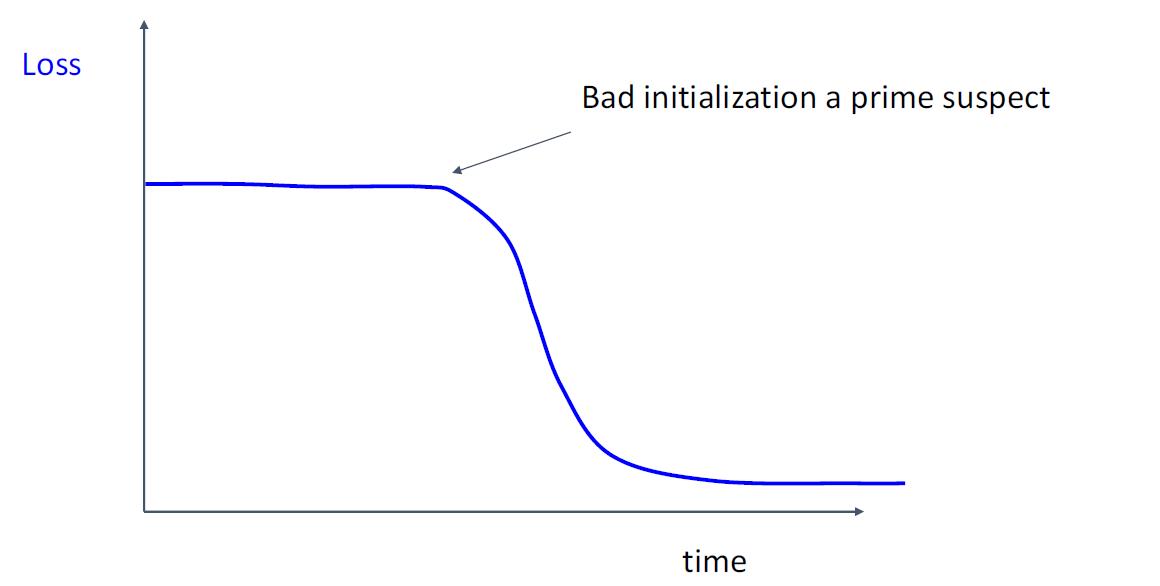


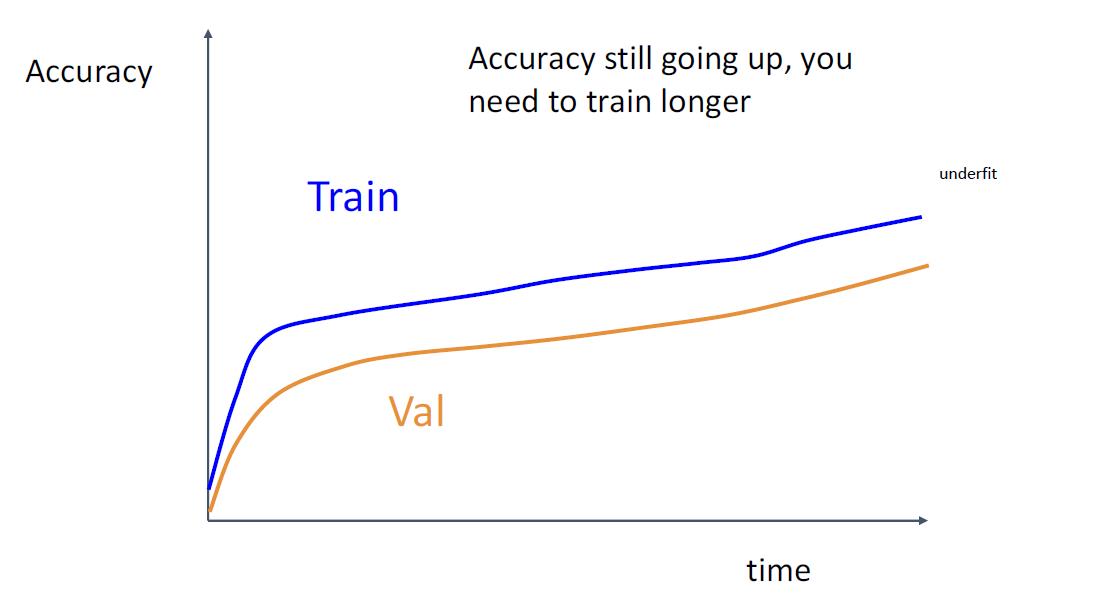
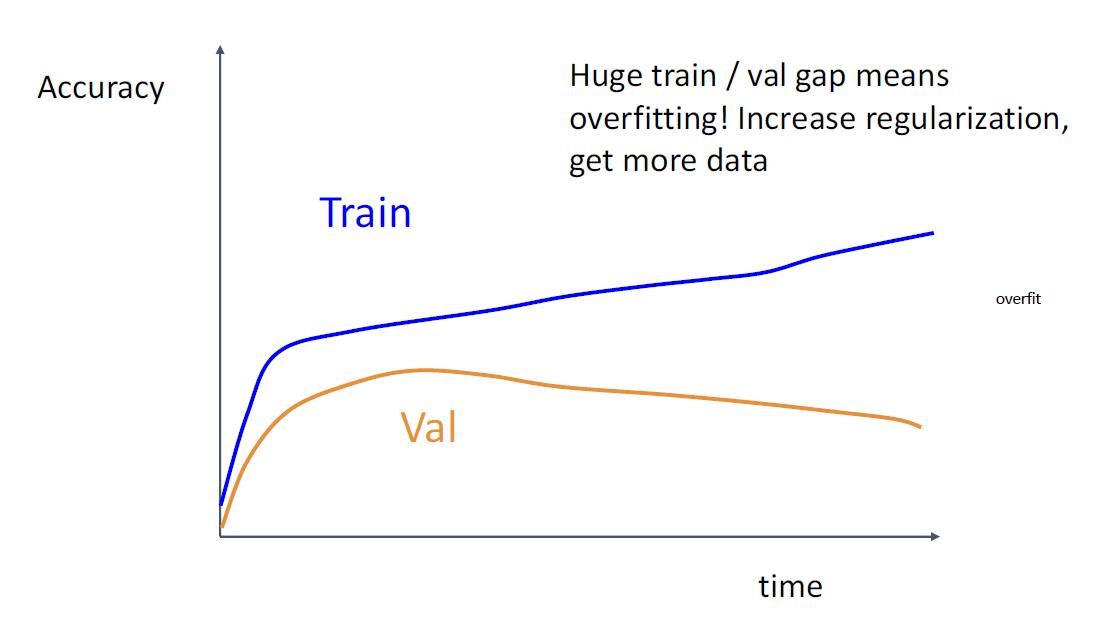
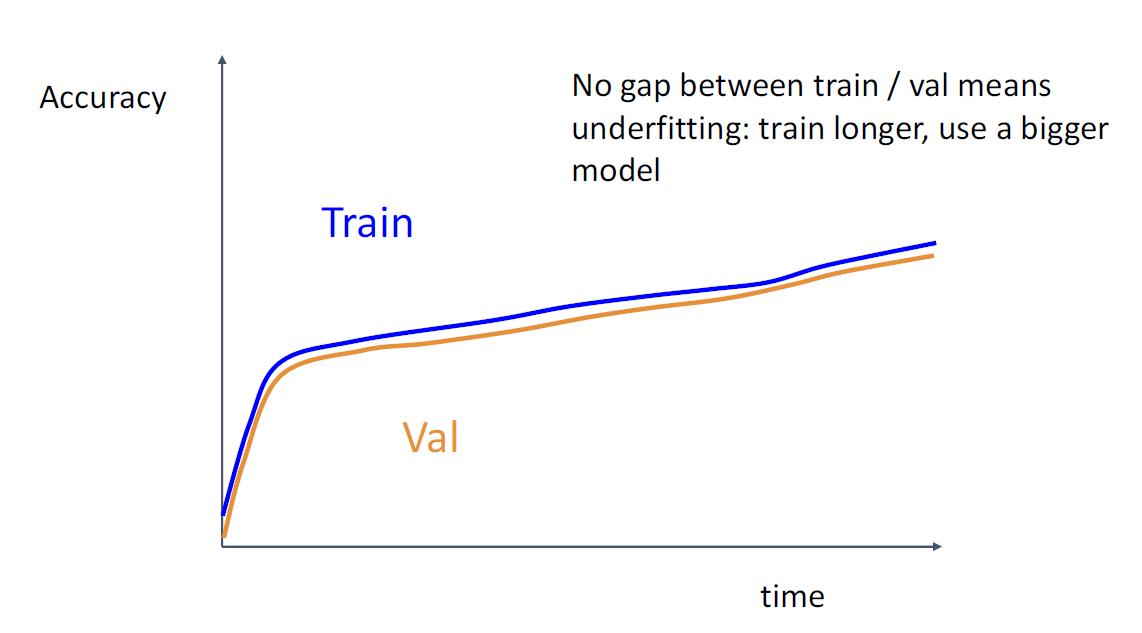
步骤7: 从步骤5开始
模型叠加
- 训练多个模型
- 预测的时候使用他们的平均值
- 一般会有2%的额外提升
小技巧
- 不去训练多个单独的模型,而是保存一个模型在训练中的多个snapshot
- 训练一个模型,但是用Polyak averaging的方式去保留真正的参数
迁移学习
迁移学习就是就是把已学训练好的模型参数迁移到新的模型来帮助新模型训练。考虑到大部分数据或任务是存在相关性的,所以通过迁移学习我们可以将已经学到的模型参数(也可理解为模型学到的知识)通过某种方式来分享给新模型从而加快并优化模型的学习效率不用像大多数网络那样从零学习(starting from scratch,tabula rasa)。
这是另一个区域的学习了,在这就不详细展开了,有兴趣的朋友可以自己去搜一下资料。
分布式训练
基于分布式系统的训练。
不再是ML范畴的,而是属于infra的范畴了。
以上是关于计算机视觉中的深度学习11: 神经网络的训练2的主要内容,如果未能解决你的问题,请参考以下文章