斯坦福大学公开课机器学习: advice for applying machine learning | deciding what to try next(revisited)(针对高偏差高方差问
Posted 橙子牛奶糖
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了斯坦福大学公开课机器学习: advice for applying machine learning | deciding what to try next(revisited)(针对高偏差高方差问相关的知识,希望对你有一定的参考价值。
针对高偏差、高方差问题的解决方法:
1、解决高方差问题的方案:增大训练样本量、缩小特征量、增大lambda值
2、解决高偏差问题的方案:增大特征量、增加多项式特征(比如x1*x2,x1的平方等等)、减少lambda值

隐藏层数的选择对于拟合效果的影响:
隐藏层数过少,神经网络简单,参数少,容易出现欠拟合;
隐藏层数过多,神经网络复杂,参数多,容易出现过拟合,同时计算量也庞大。
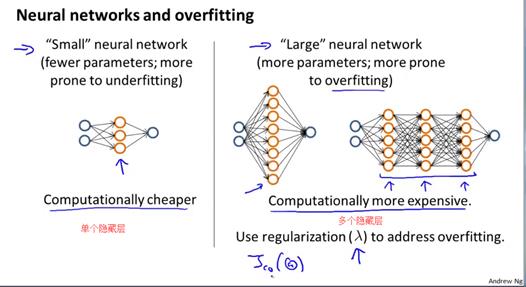
事实上,如果经常应用神经网络,特别是大型神经网络的话,会发现越大型的网络性能越好,如果发生了过拟合,可以使用正则化的方法来修正过拟合。使用一个大型的神经网络,并使用正则化来修正过拟合问题,通常比使用一个小型的神经网络效果更好。
最后,我们需要确定隐藏层的层数。默认的情况是使用一个隐藏层是比较合理的选择,但是如果你想要选择一个最合适的隐藏层层数,你也可以试试把数据分割为训练集、验证集和测试集,然后试试使用一个隐藏层的神经网络来训练模型。然后试试两个、三个隐藏层,以此类推。然后看看哪个神经网络在交叉验证集上表现得最理想。也就是说你得到了三个神经网络模型,分别有一个、两个、三个隐藏层。然后你对每一个模型,都用交叉验证集数据进行测试,算出三种情况下的交叉验证集误差Jcv,然后选出你认为最好的神经网络结构。
以上是关于斯坦福大学公开课机器学习: advice for applying machine learning | deciding what to try next(revisited)(针对高偏差高方差问的主要内容,如果未能解决你的问题,请参考以下文章