XGBoost 论文笔记
Posted 同学少年
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了XGBoost 论文笔记相关的知识,希望对你有一定的参考价值。
1. 树融合模型
假定有一个数据集包含n个样本 ,每个样本有m个特征。树融合模型是利用K个函数(树)来预测最终的结果。
,每个样本有m个特征。树融合模型是利用K个函数(树)来预测最终的结果。
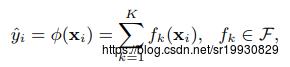

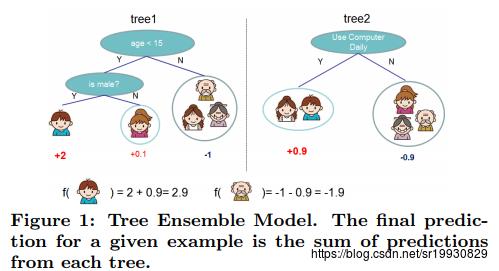
每一个f(x)代表一棵生成的回归树(也称为CART),q代表一棵树的结构,该结构将输入的样本x,映射到该树的叶子结点上去。T代表该树叶子结点的个数, wq(x)表示该树叶子结点上的权重(也是该叶子结点的输出值),wi表示第i个叶子结点的权重。对于给定的一个样本x,它的预测值等于每棵回归树单独的预测值的加和。如下图:
XGBoost就是这样一种融合树模型。它所优化的目标函数如下:

其中 是可微的凸损失函数,评估预测值与真实值的差别。k代表生成的k棵树。
是可微的凸损失函数,评估预测值与真实值的差别。k代表生成的k棵树。 是正则项,作用是减少模型的复杂度,防止过拟合。
是正则项,作用是减少模型的复杂度,防止过拟合。
2 梯度提升
用 表示第i个样本在第t轮迭代时的预测值,如下图,第t轮的优化目标就是最小化如下损失函数,采用的是前向加法模型,每次迭代只考虑当前损失最小。
表示第i个样本在第t轮迭代时的预测值,如下图,第t轮的优化目标就是最小化如下损失函数,采用的是前向加法模型,每次迭代只考虑当前损失最小。
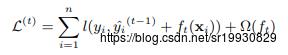
使用二阶近似可以很方便地优化上面那个函数。
考虑二阶泰勒公式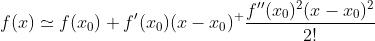
令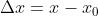 , 有
, 有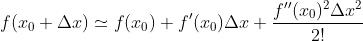
将前一轮的预测函数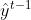 作为
作为 , 当前要学习的
, 当前要学习的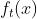 作为
作为 ,则有下列式子:
,则有下列式子:

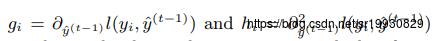 分别是损失函数关于的一阶导和二阶导(这里的变量是函数,是在函数空间进行优化的)。去掉第一项常数,则第t轮的优化目标是最小化下面损失:
分别是损失函数关于的一阶导和二阶导(这里的变量是函数,是在函数空间进行优化的)。去掉第一项常数,则第t轮的优化目标是最小化下面损失:
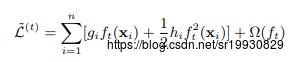
定义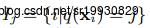 为所有落在叶子结点 j 上的样本xi, 展开,有下面式子:
为所有落在叶子结点 j 上的样本xi, 展开,有下面式子:
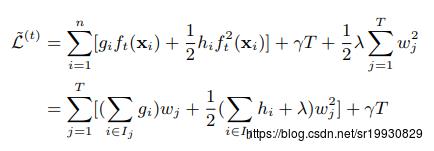
该式子第二步将第一步的两个不同加和统一成一样的格式(叶子结点上样本的总和),是等价的,因为所有样本的个数就等于所有落在叶子结点上的样本个数。这样的话,对于一个固定的树结构,就可以用上面的式子对 wj进行求导,找到最优的wj 使得上面函数取得最小值:
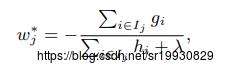
将最优的w代回原式,有:
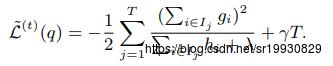
这个公式可以作为对一棵结构确定的树(比如当前树只包含一个节点)的打分。它代表着,在当前结构下对所有样本进行预测,最小损失是多少(求出的w*作为该结构的叶子输出值)。和决策树算法一样,我们不可能枚举出所有的树结构,所以只能依靠启发式来对节点进行分裂,从而找到次优的树。假设当前节点包含的样本集合为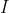 , 我们采用某个特征值的某个切分点将集合划分为
, 我们采用某个特征值的某个切分点将集合划分为

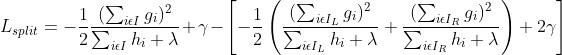
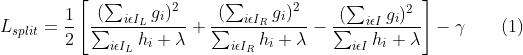
3 防止过拟合
除了上面目标函数的正则项可以防止过拟合,权重缩减和列抽样也可以防止过拟合。权重缩减意思是在每棵树的预测值前面乘以一个权重因子,缩小该预测值。目的是让后面的树有更大的发挥空间(比如某个样本的真实值是3,第一棵树的预测值为2.6,那么以后生成的树所对最终预测值贡献就很小,0.4的发挥空间,利用权重缩减,乘以一个权重,比如0.3,那么第一棵树的预测值为0.3 * 2.6,为后面树留出发挥空间)。列采样,就是每次分裂节点时,从m个总的列特征里面随机选出k个作为候选特征,原理是和随机森林是一样的。
4 划分点选择
4.1 完全贪心算法
和决策树中思想一样,决策树在划分节点的时候,是选择信息增益值最大的划分点(第几个特征的第几个划分值)。XGBoost选择使得上述公式(1) 最大的划分点。算法如下图:
最大的划分点。算法如下图:

先遍历每个特征,然后将该特征的所有取值从小到大排好序,依次对每个可能取值计算score,选择score最大的值作为划分点。
4.2 近似算法
当数据集的特征比较多或者每个特征的可能取值特别多时,上面的完全贪心算法效率低下。XGBoost采用近似的方法,对于每个特征的所有可能取值,不是每个可能取值作为一个候选划分点,而是将这些值从小到大排好序,分装在几个桶里面,桶的边界值作为划分点。而桶的装法是按照权重直方图算法来进行的, 表示每个样本的第k个特征的值和该样本相应的二阶导数值。定义一个rank函数:
表示每个样本的第k个特征的值和该样本相应的二阶导数值。定义一个rank函数:

表示第k个特征值小于边界值z的所有样本点占所有样本点的比例。目标是找到划分点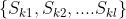 ,满足
,满足
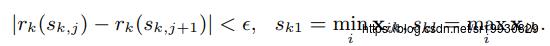
 是近似因子。直觉上看,大约有
是近似因子。直觉上看,大约有  个划分点。由rank函数中可看到样本对应的二阶导数值
个划分点。由rank函数中可看到样本对应的二阶导数值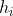 作为了权重值, 是因为第t步要优化的损失函数
作为了权重值, 是因为第t步要优化的损失函数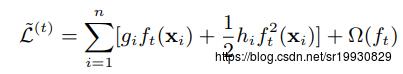 可写成如下形式:
可写成如下形式:
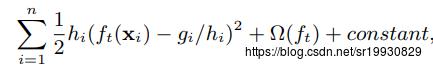
下面说一下具体的候选点选择过程,假设的一组值为(1, 1/12), (2, 1/12), (4, 1/6), (5, 1/3), ( 6, 1/3) 第一个特征值xik是从小到大排好序的,为了好理解,假设 且
且 ,则把这些样本点装到桶的装法为 (1, 1/12), (2, 1/12), (4, 1/6)为一组,权值总和为 1/ 3, (5, 1/3)为另外一组,权值总和为1/ 3,(6, 1/3)为最后一组,权值总和为1/ 3。所相应的划分点为
,则把这些样本点装到桶的装法为 (1, 1/12), (2, 1/12), (4, 1/6)为一组,权值总和为 1/ 3, (5, 1/3)为另外一组,权值总和为1/ 3,(6, 1/3)为最后一组,权值总和为1/ 3。所相应的划分点为 。
。
根据权重直方图图算法得出候选点有两种方式,一种是全局先算出所有候选点,后面节点分裂时都从这些候选点里面选。另一种是局部算候选点,每次分裂时都单独算一遍候选点。通常,全局需要的方法需要更多的候选点,因为每次分裂后不会再去调整候选点,还是从原来的里面选。而局部每次分裂都会调整候选点,比较适合于较深的树。通过比较发现,局部方法的确要求更少的候选点。而如果有足够的候选点的话,全局方法能够达到局部方法的精确度。
5 稀疏处理
数据中可能会有一些稀疏数据(缺失值,大量的0).XGBoost为了更好处理稀疏值,对每个节点设定了一个默认的方向。当对一个节点划分带有缺失值数据时,被分到默认方向的节点上(左节点还是右节点)。算法如下:

该算法先把含有缺失值的数据分到左节点,计算它的score,再分到右节点,计算它的score,选择score最大的那个方向作为节点的默认方向。XGBoost支持用户自定义缺失值。
6 并行化
树学习最耗时的部分是将数据进行排序。XGBoost将数组存储到内存单元,block。每个block的数据以压缩列的形式存储。每一列是按照其特征值排好序的。在训练之前,将所有特征排好序。
对每一列数据的统计是可以并行的,因为候选点的选取可以进行并行化。
以上是关于XGBoost 论文笔记的主要内容,如果未能解决你的问题,请参考以下文章