机器学习(监督学习)基础,强推!!!
Posted ascto
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习(监督学习)基础,强推!!!相关的知识,希望对你有一定的参考价值。
机器学习
在没有明确设置的情况下,使计算机具有学习能力的研究领域。
计算机程序从经验E中学习解决某一任务T进行某一性能度量P,通过P测定在T上的表现因经验E而提高。如跳棋游戏:E就是计算机与自己下几万次棋,T就是玩跳棋,P就是赢的概率。
机器学习:
- 有监督:我们会教计算机做某件事情
- 无监督:我们让计算机自己学习
监督学习
给算法一个数据集,其中包含了正确答案。回归问题(预测(连续多值))、分类问题(0、1or0、1、2、3…so on)
线性回归
不同符号的含义:


代价函数(平方误差函数):

计算例子

两个参数的代价函数

利用等高线图(等高图像)表示两个参数的代价函数。
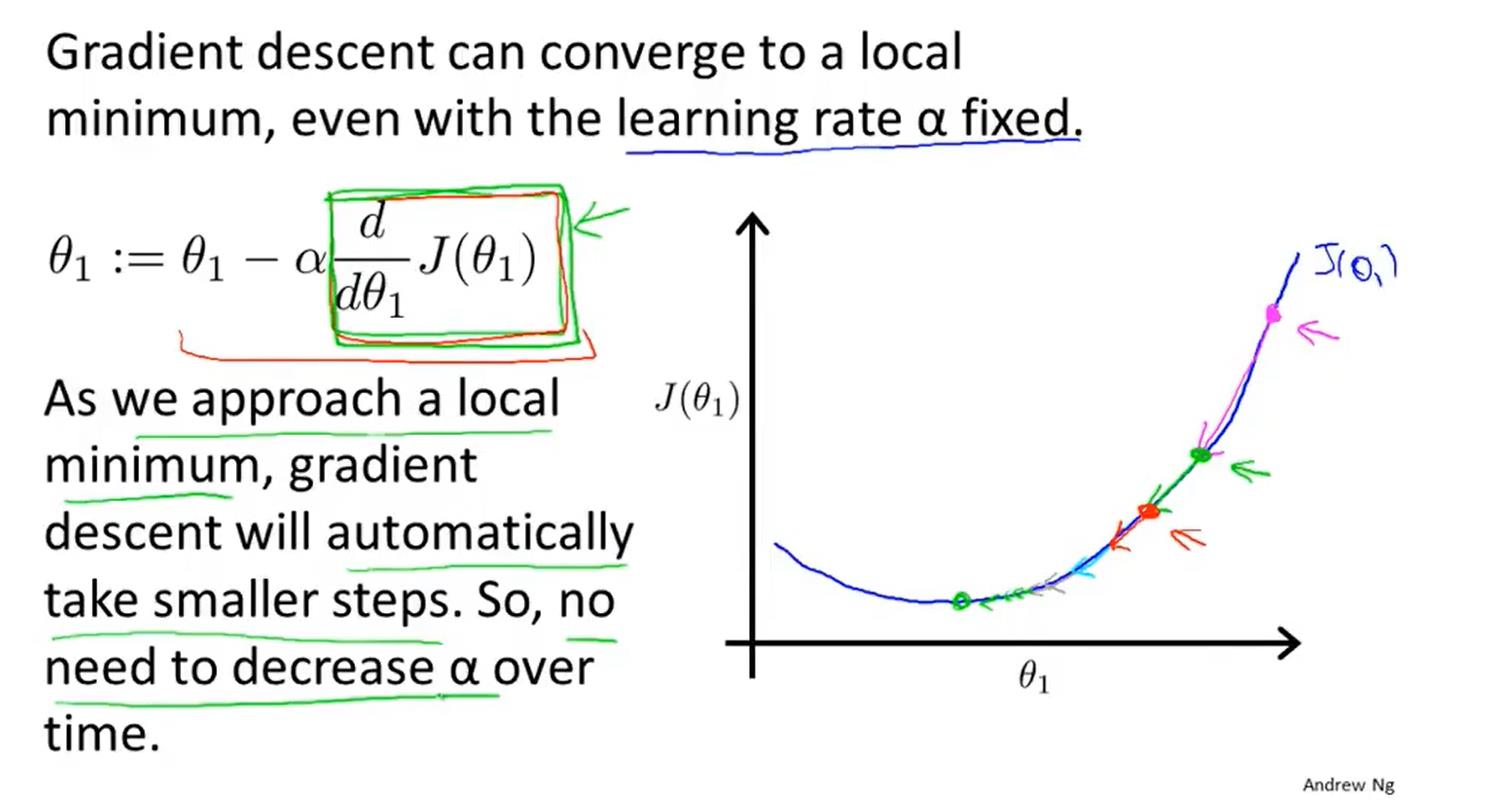
梯度下降算法(最小化)

α(学习速率)表示梯度下降时,我们迈出多大的步子。α大表明下降迅速。
例子:

梯度下降算法的α其实不需要改变,因为算法中的斜率会自动改变,直到逼近局部最优解。


多元线性回归

多元线性回归的特征缩放方法
不同的特征都在相似的一个区间(范围)里面,使用特征缩放方法可以使梯度下降法更快的收敛。

均值归一化

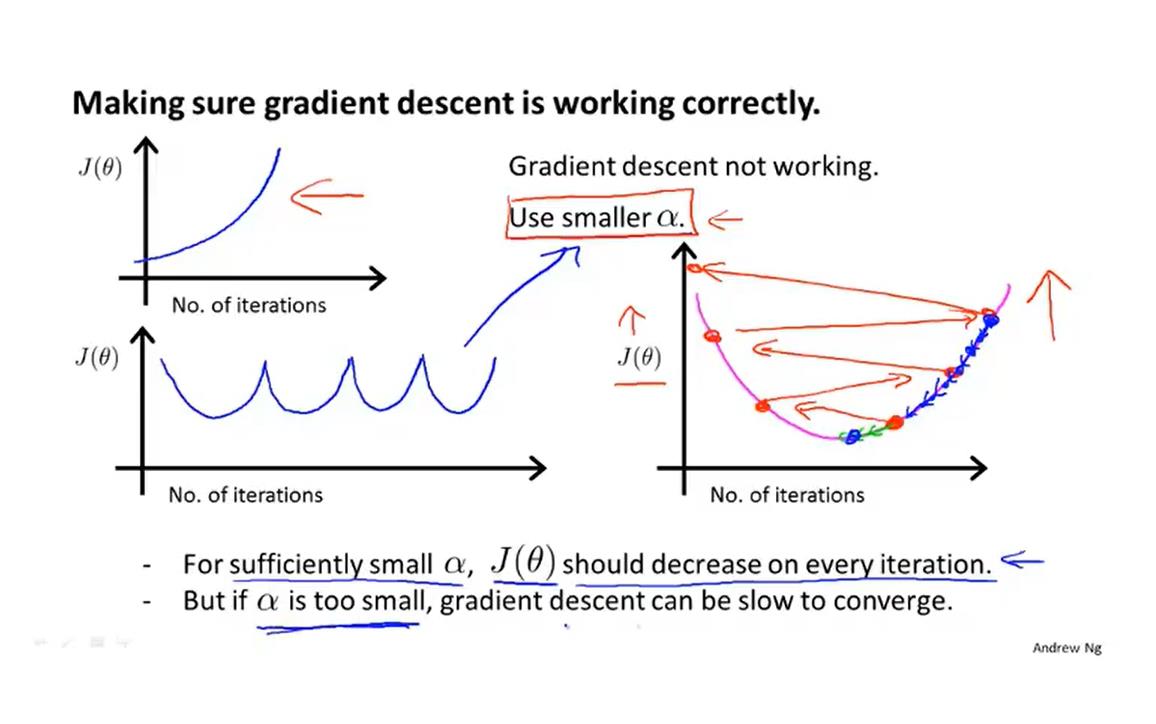
讨论一下学习率α

多元线性回归的方法

正规方程(区别于迭代方法的直接解法)
提供了一种求seita的解析解法,可以一次性求解seita的最优值。

当特征变量比较少的时候可以选择正规方程,特征变量比较多的话(矩阵计算复杂,效率低)还是建议用梯度下降算法。
分类问题
线性回归不再适用
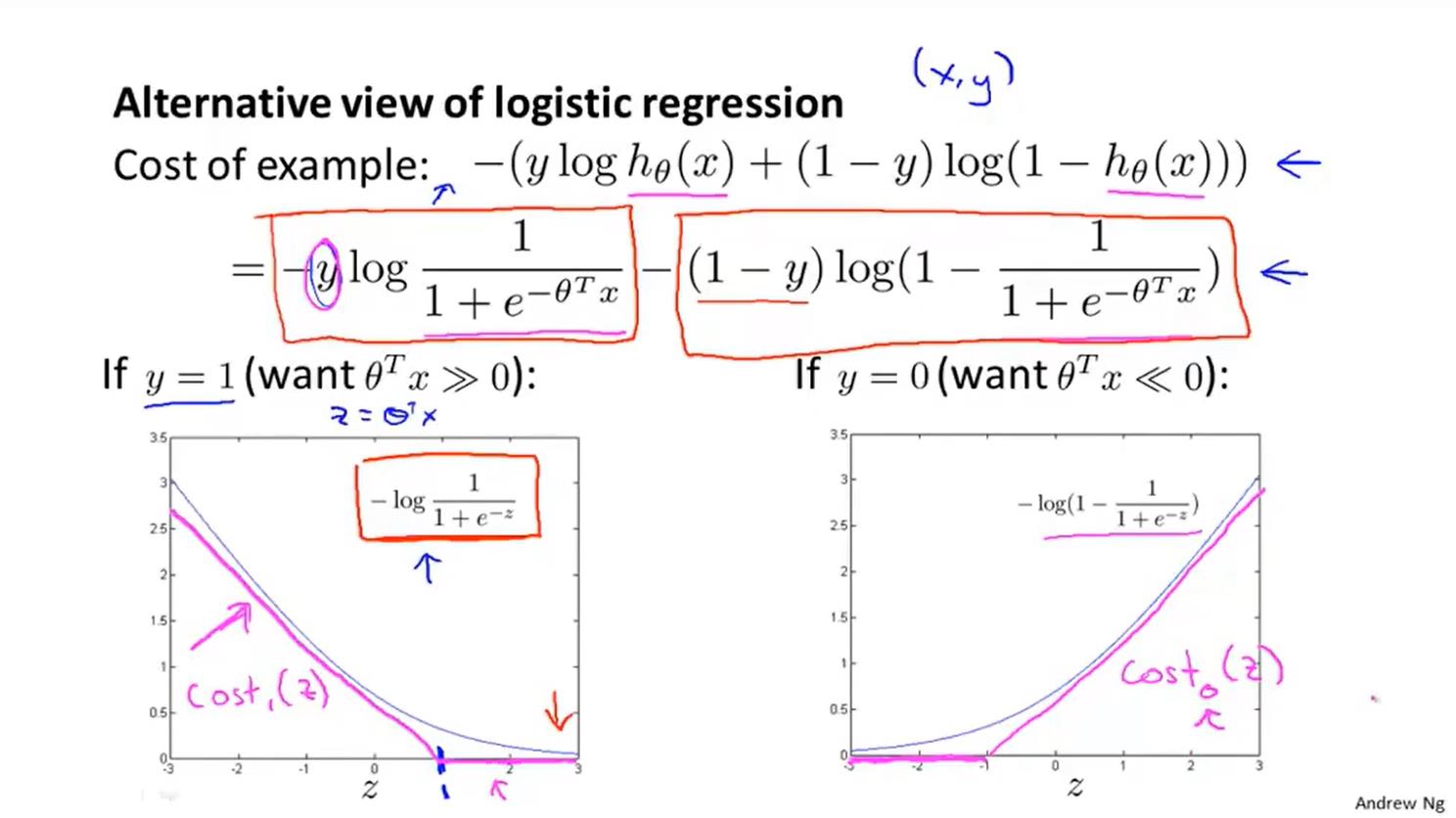
logistic回归算法(分类算法)

决策界限


如何拟合seita?
优化目标(代价函数)




也是用梯度下降算法,只不过h(x)发生了改变

高级的代价函数求法:


多元分类(一对多)

进行训练样本。
当输入一个x之后,选择对应h(X)最高的那个即为最有可能的结果(类型1、2、3)。
过拟合问题
当特征数量过多,但是训练量很少的时候可能会出现过拟合的现象。

注:第一个是欠拟合

解决方案:
1.较少特征量,但是这种方案并不好。
2.正则化。
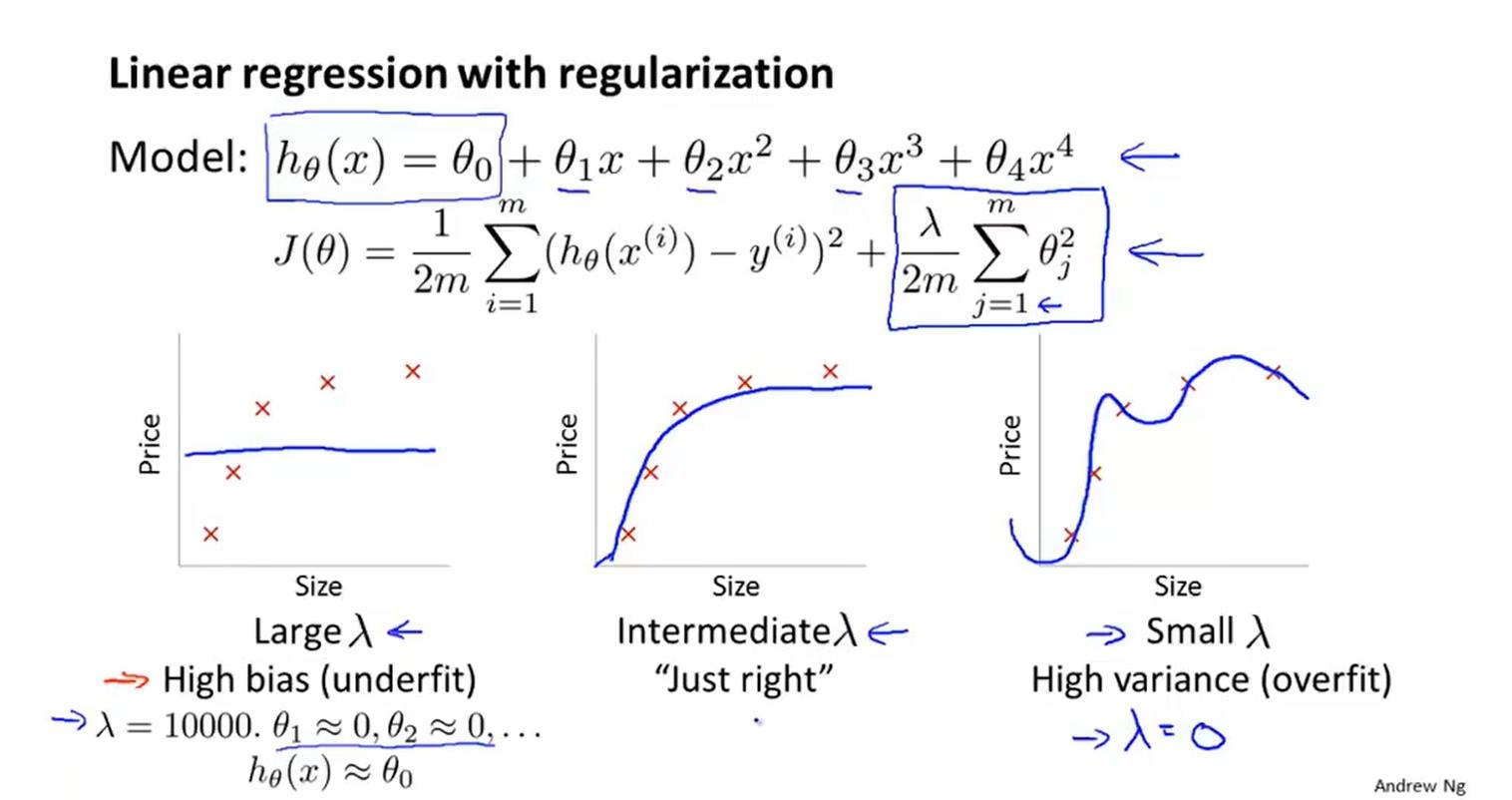
正则化
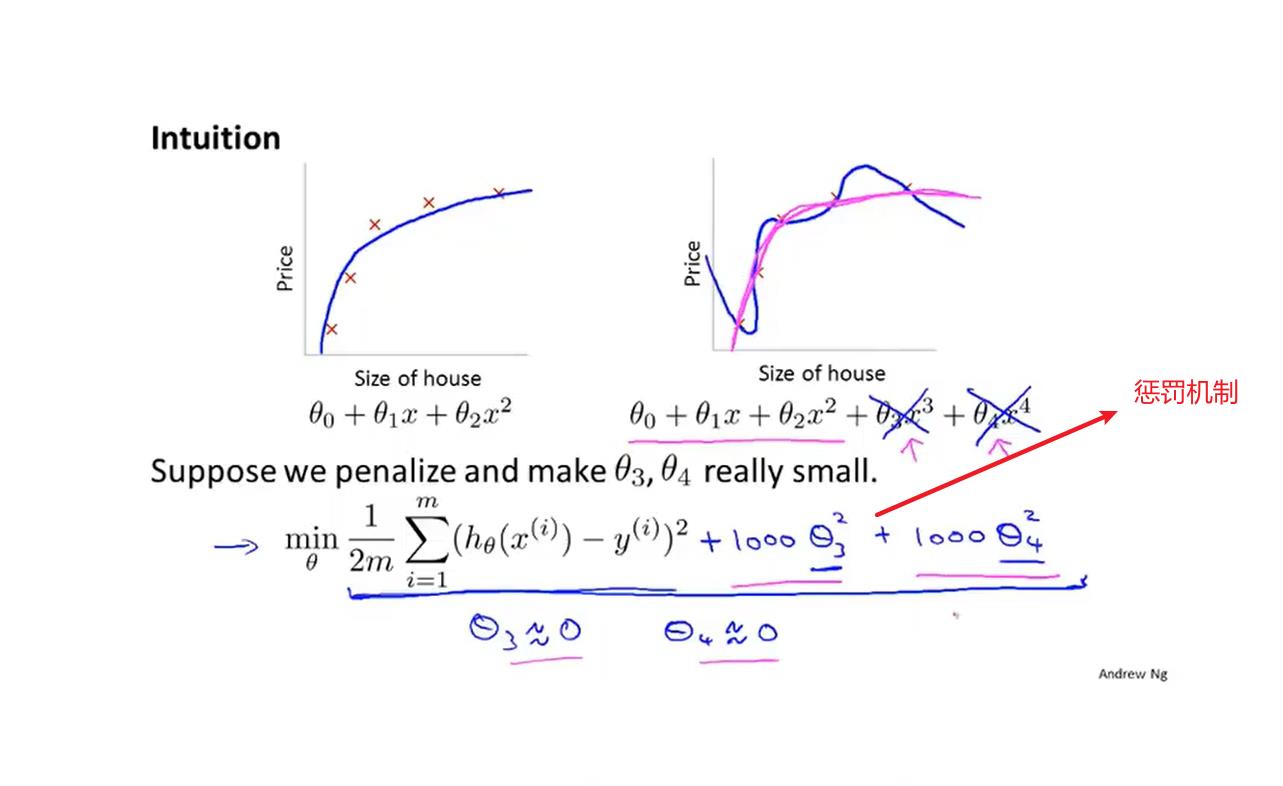


ps:lambda用于动态平衡正则项和前面项的关系。保证不会出现过拟合和欠拟合。如果lambda太大的话就会导致seita太小了,以至于接近0,这样拟合的代价函数就是一个seita0的常函数—>欠拟合。
线性回归的正则化

正规方程的正则化

logistic回归的正则化

神经网络
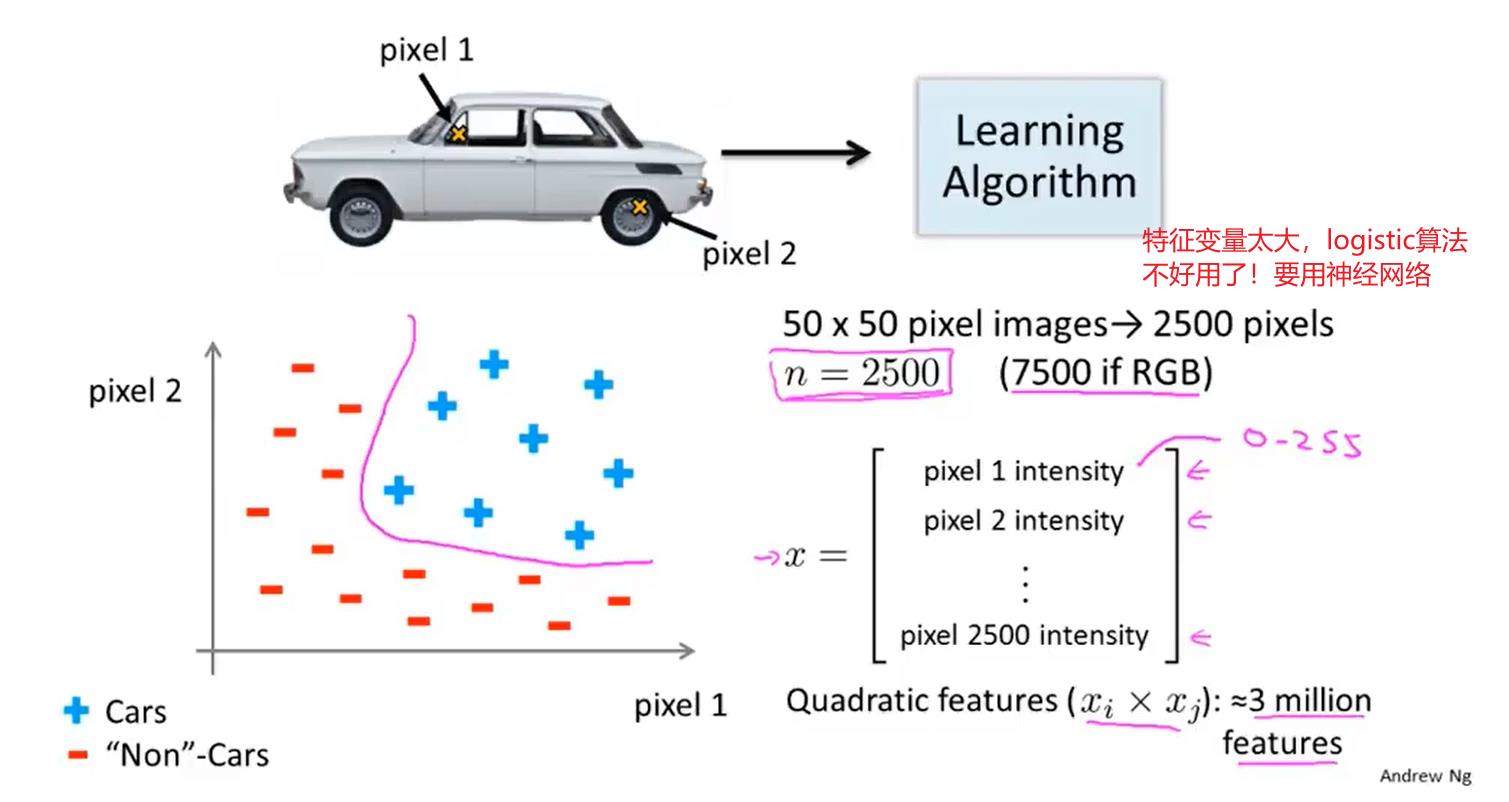
神经元/激活函数
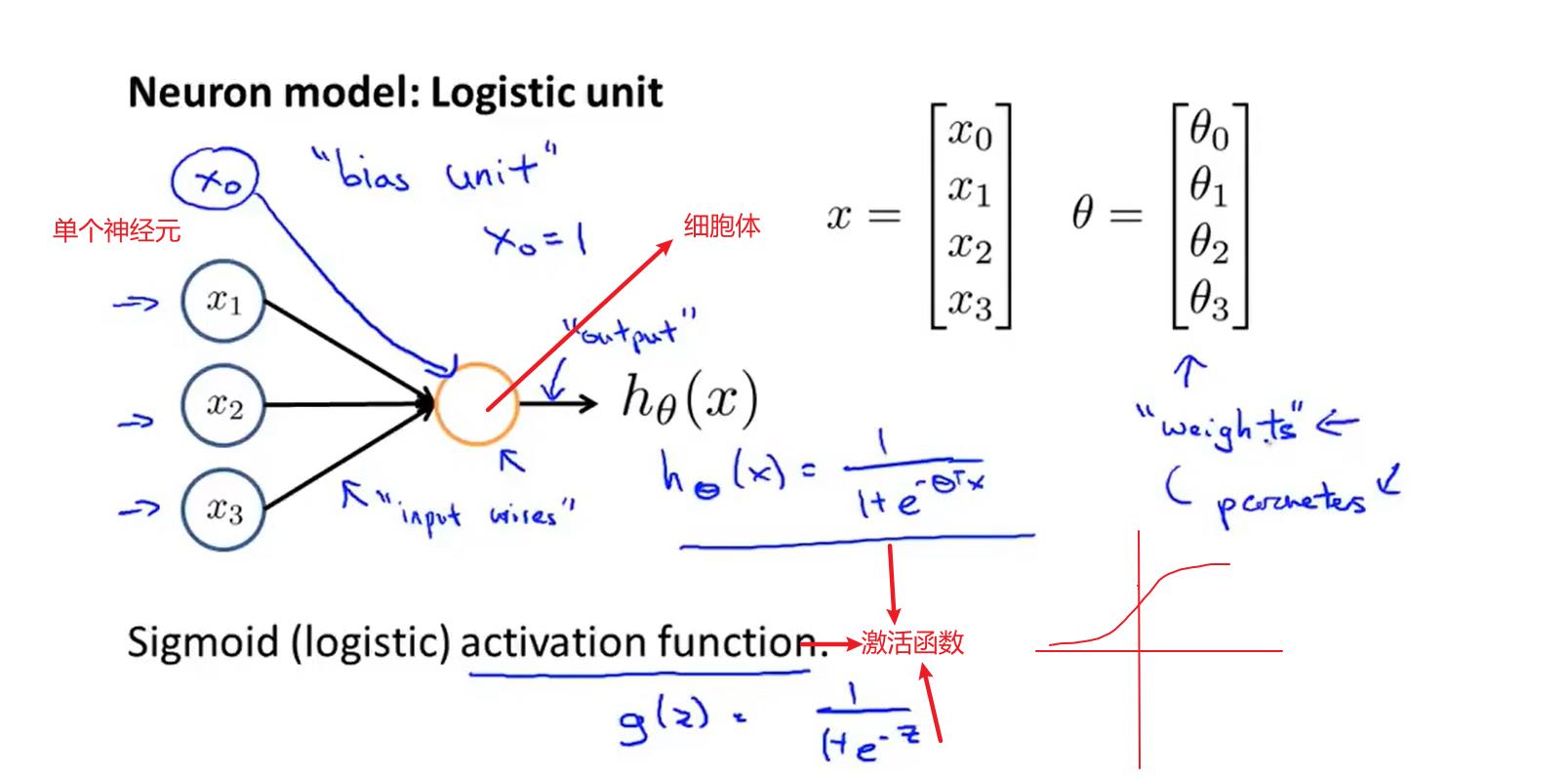
神经网络:一组神经元
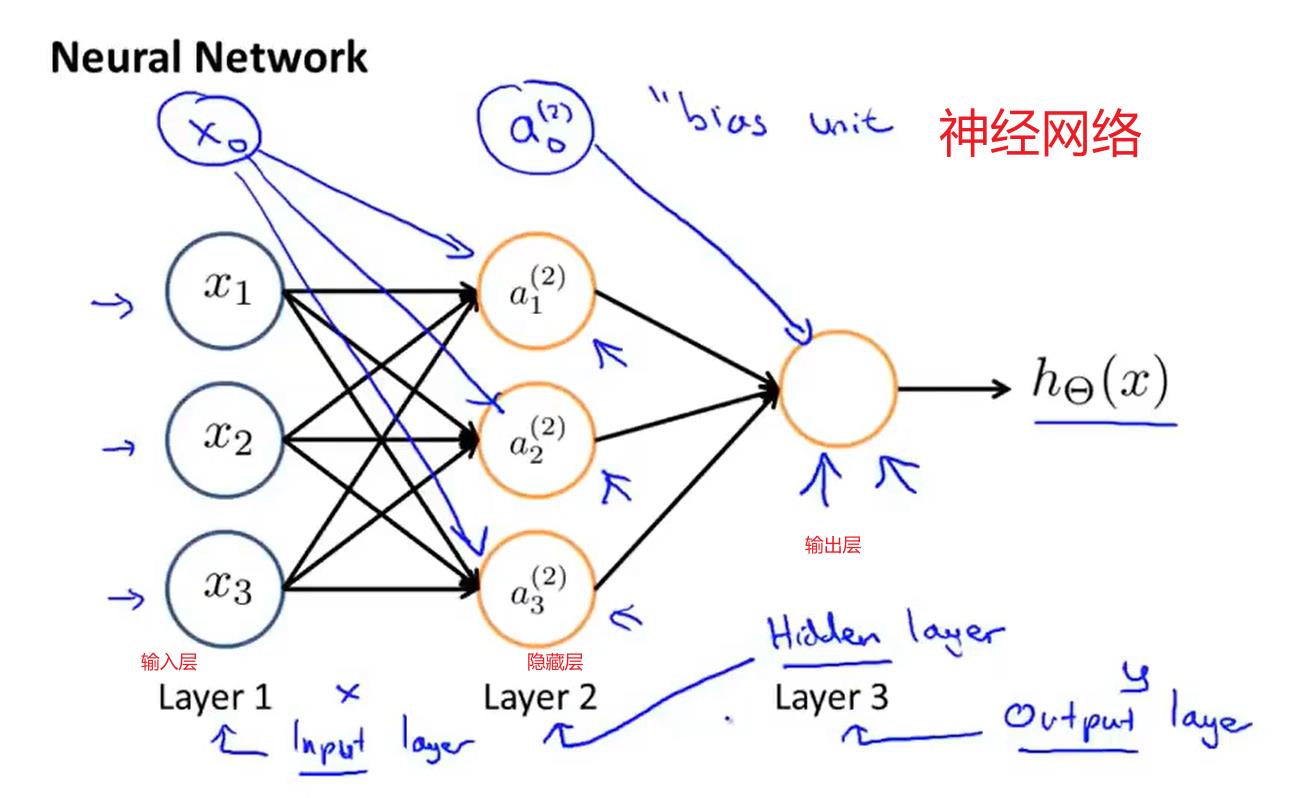
模型展示1:
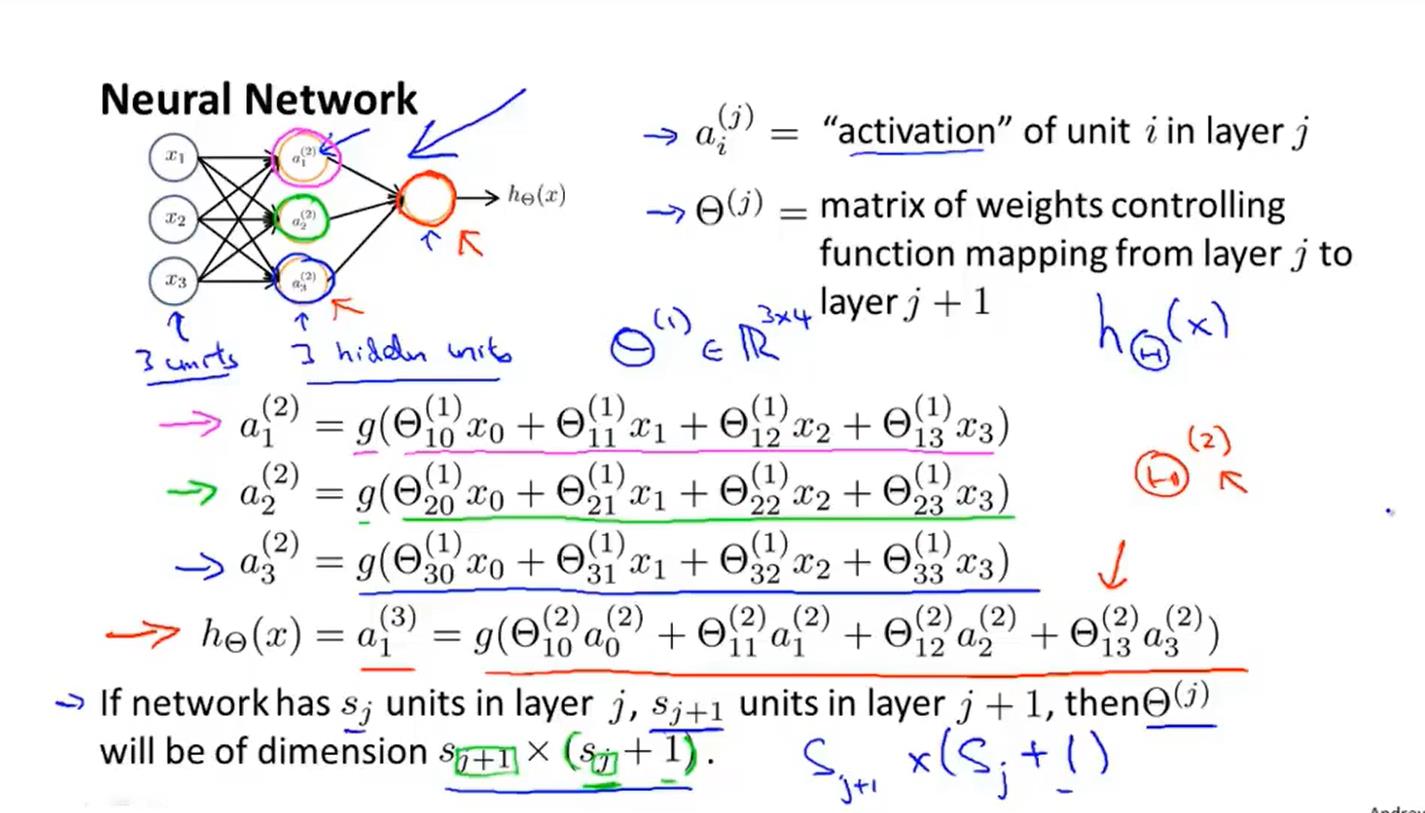
(没有用输入特征x1、x2、x3进行逻辑回归训练,而是自己训练逻辑回归的输入a1、a2、a3)

向前传播

利用神经网络学习多元分类
代价函数:

反向传播算法(BP算法)
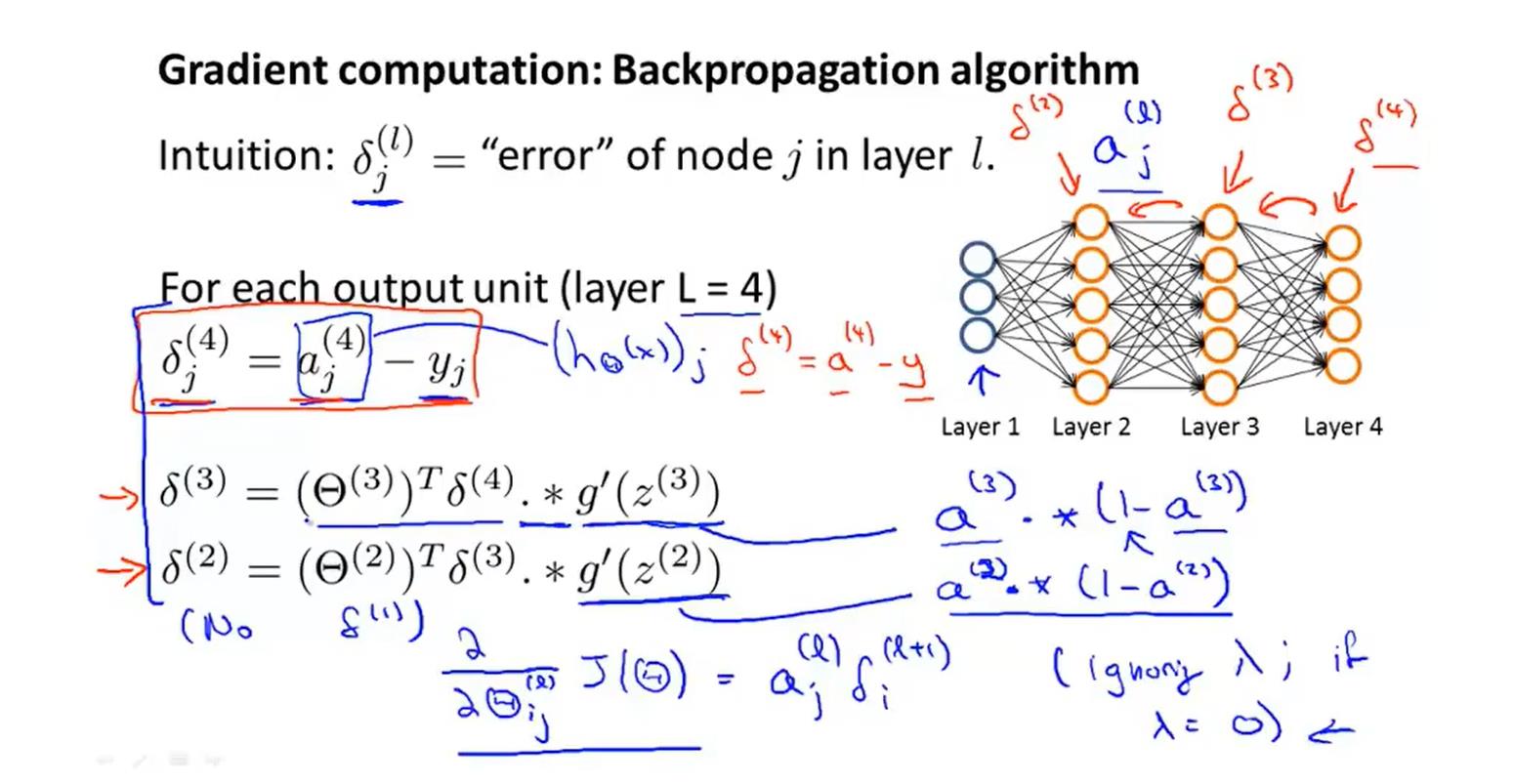
先利用正向传播计算出a(j)(4),然后在利用反向传播(类似回溯)

梯度检验

随机初始化
如果一开始设置的初始值都是0,会导致a1=a2,那么隐藏层那么多隐藏单元就没意义了。

每一个隐藏层应该具有相同的隐藏单元数量
训练神经网络:
- 构建神经网络,随机初始化权重(一般初始化的权重很小)
- 向前传播算法
- 计算出代价函数
- 反向传播算法(找到梯度下降的方向)
- 梯度检查
- 利用梯度下降算法或者其他高级优化算法,找到min
优化,评估,诊断
策略:
- 增加样本容量(适用于过拟合)
- 更少/更多的特征变量(更少适用于过拟合,更多适用于欠拟合)
- 提高多项式的次幂(适用于欠拟合)
4. 增加/减少lambda(增加适用于过拟合,减少适用于欠拟合)
如何选择有效的策略?
机器学习诊断:可以通过运行测试来了解学习算法的工作原理,并获得如何最好地提高其性能的指导。
评估假设:

测试集:将训练集得到的seita放到这里,利用x、方程去验证y,得到误差。
缺点:测试集又充当评价模型的标准,不公平,不准确。需要再次分类
更好的评估假设:

训练集训练模型,验证集选择模型,测试集评估泛化误差
偏差较大:欠拟合,方差较大:过拟合。

正则化与偏差和方差的关系?
如何用?


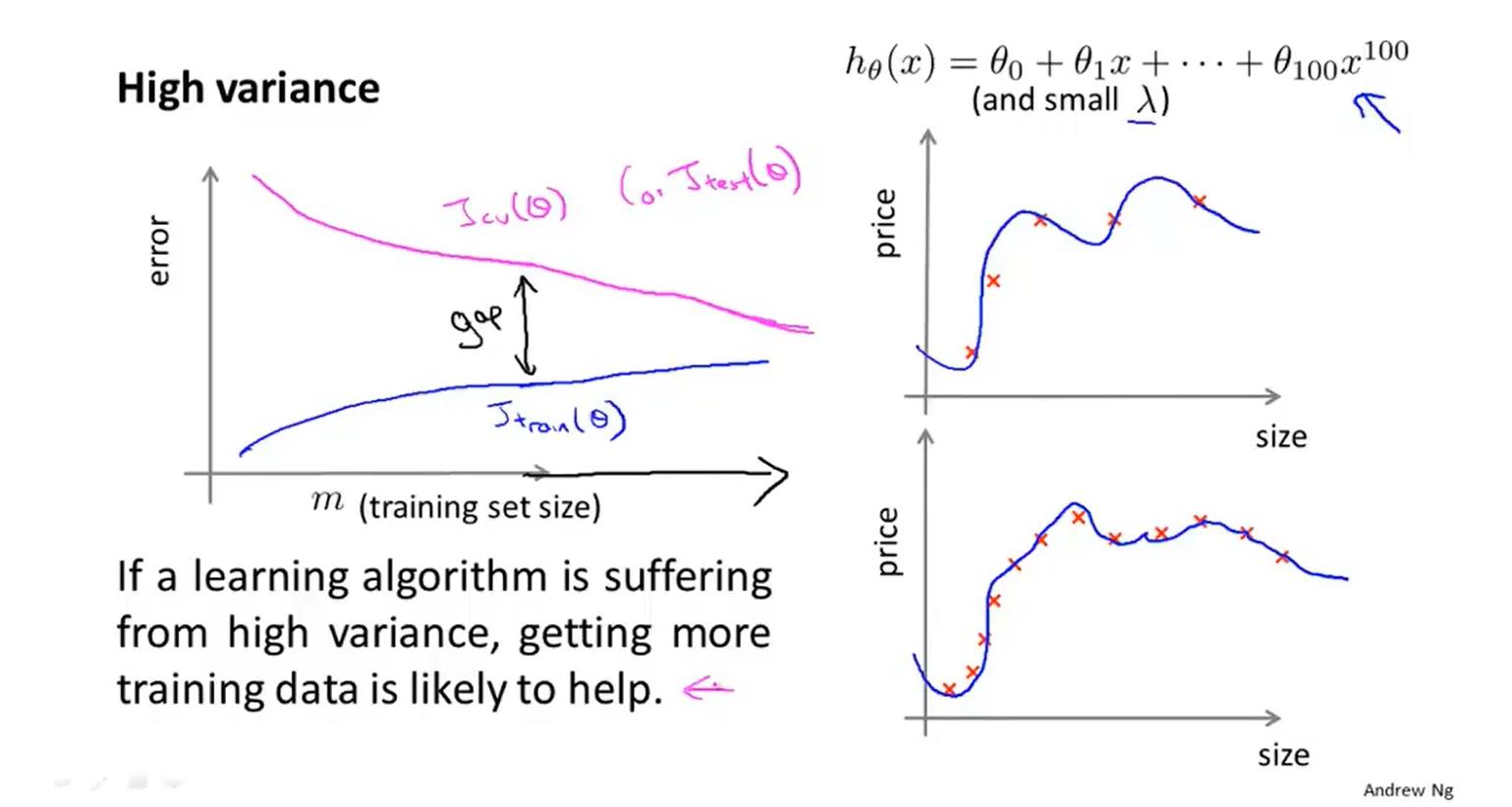
当训练量不同时,训练误差和验证误差的曲线变化:

如果一个学习算法就有高偏差,随着我们增加训练样本,交叉验证误差不会下降了,所以如果学习算法正处于高偏差情况,那么选用更多的训练集数据是无用功

当出于过拟合情况下时,如果增大训练量会使验证集误差变小,训练集误差变大
误差分析
偏斜类简单理解就是在训练模型时由于正样本和负样本之间的严重不平衡,导致模型最后检测全部都是1或者全部都是0。假设正样本的y值为1,当正样本远远多于负样本的时候,训练好的模型就会一直输出1,这会给我们判断模型优劣带来一定的障碍,比如模型输出1的概率是99.8%,输出0的概率是0.2%,这里我们就会认为模型的精度很好,误差很小。但是其实这种结果是由于数据集的不平衡导致的。
利用:查准率和召回率解决偏斜类问题

不同的边界设置对查准率和召回率的影响
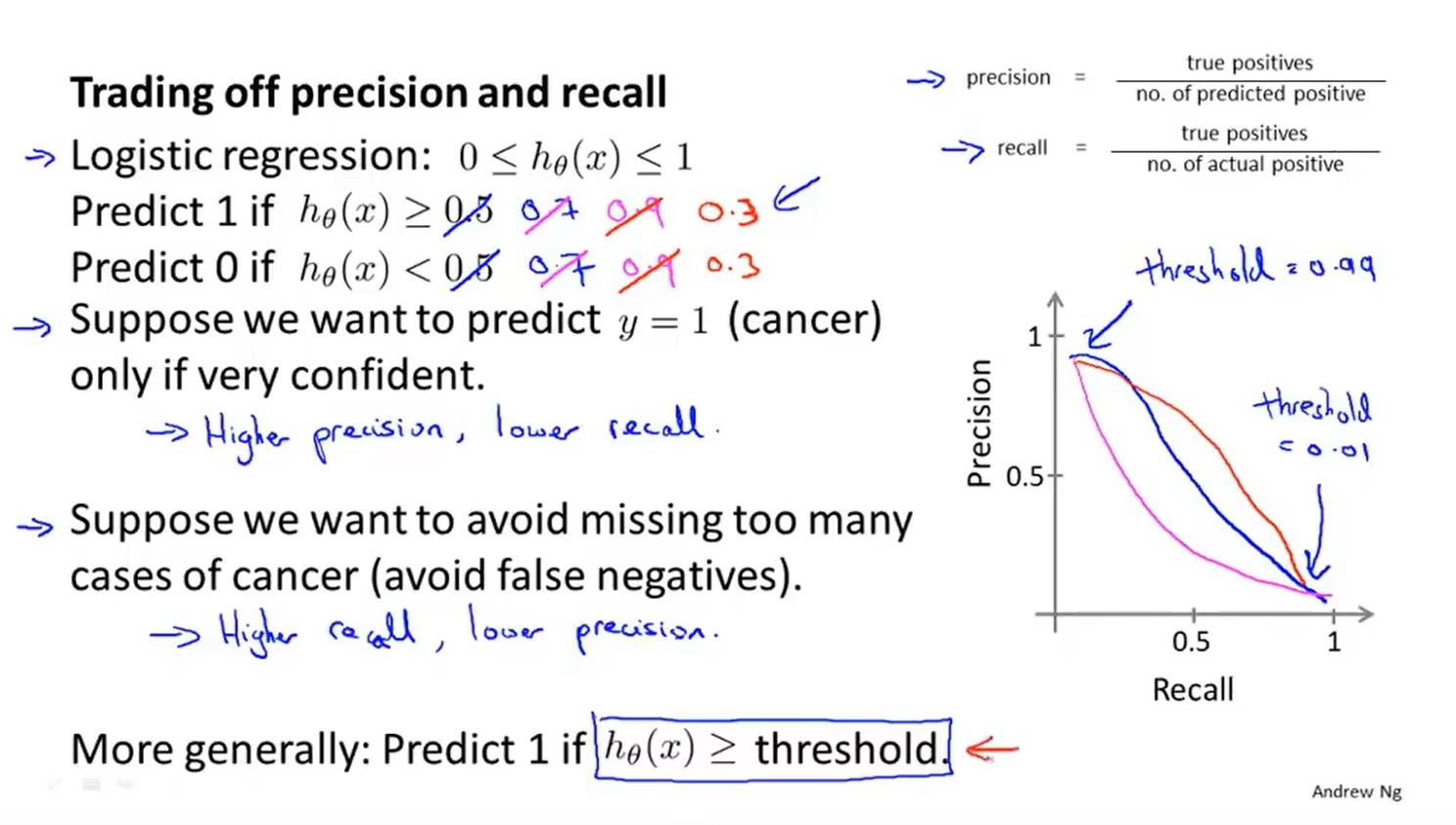
当查准率或者召回率都很小的时候,或者为0的时候,FScore也会很低。只有当两者都很高的时候,才会使FScore分数很高。

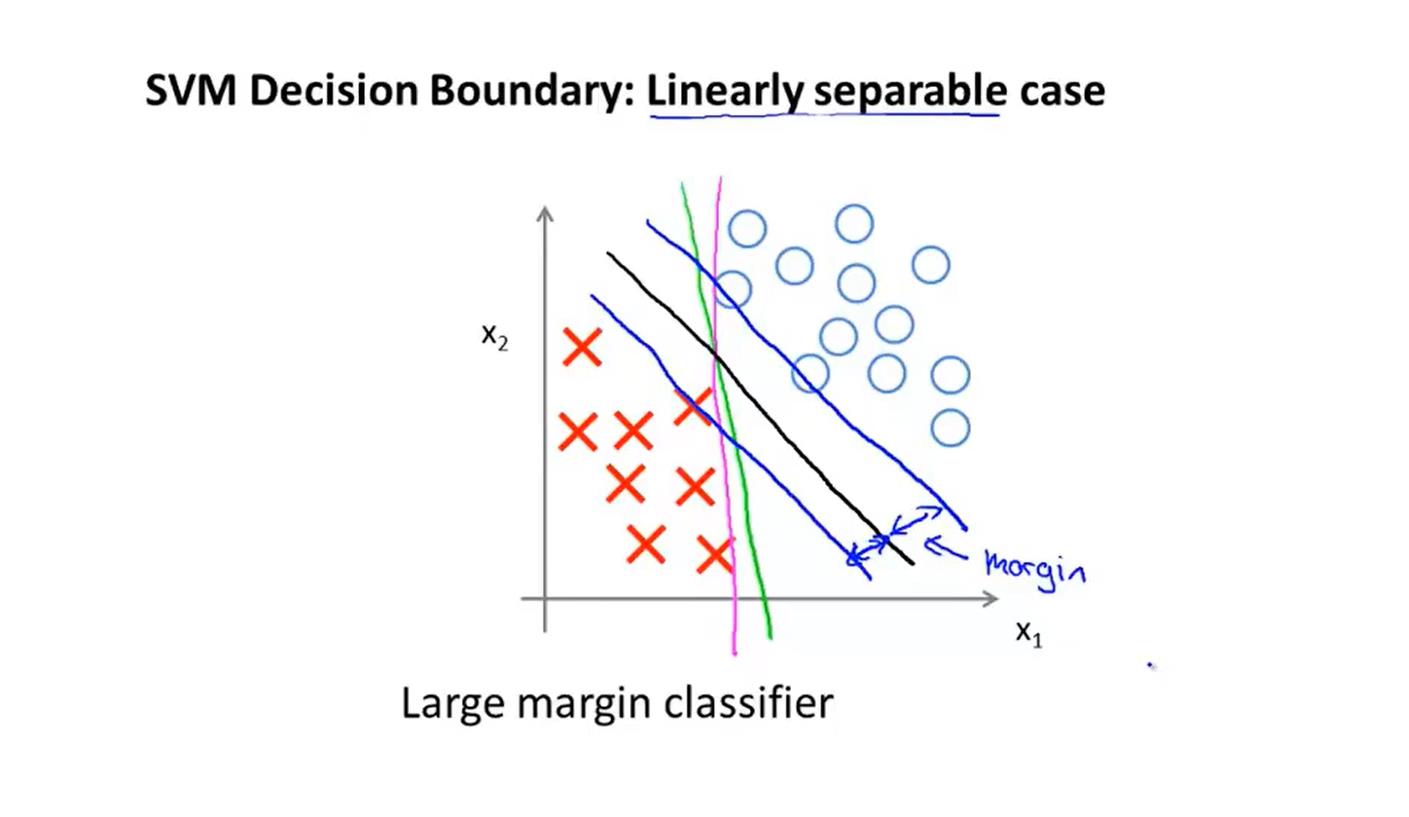
支持向量机(SVM)
图像:

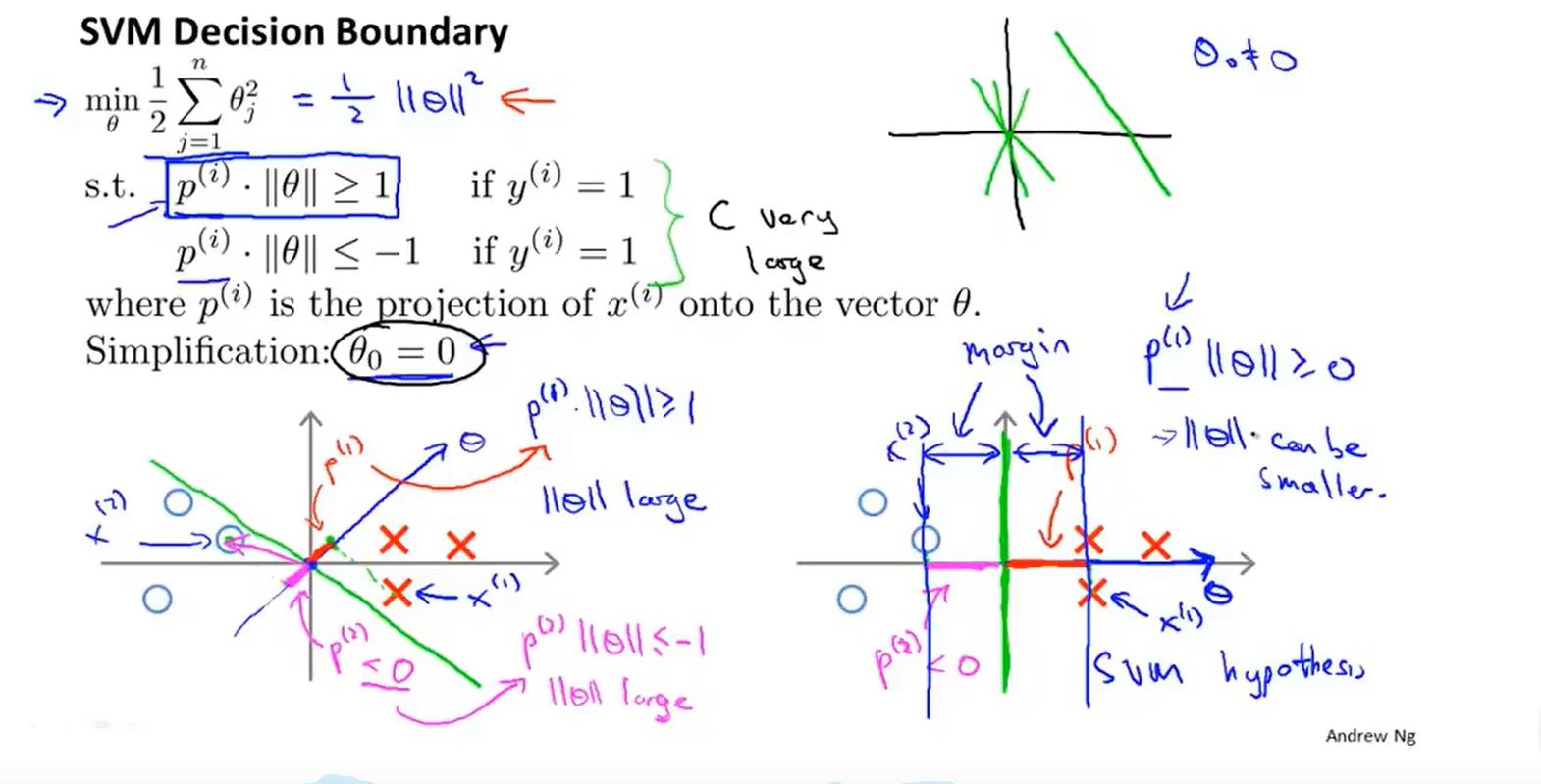
公式:

与logistic回归算法不同的是:支持向量机并不会输出概率,相对的是通过优化的代价函数直接得到一个seita,预测结果(0,1)。
支持向量机的间距,可以提高算法的鲁棒性,这也是被称为大间距分类器的原因
数学原理:(内积)
核函数


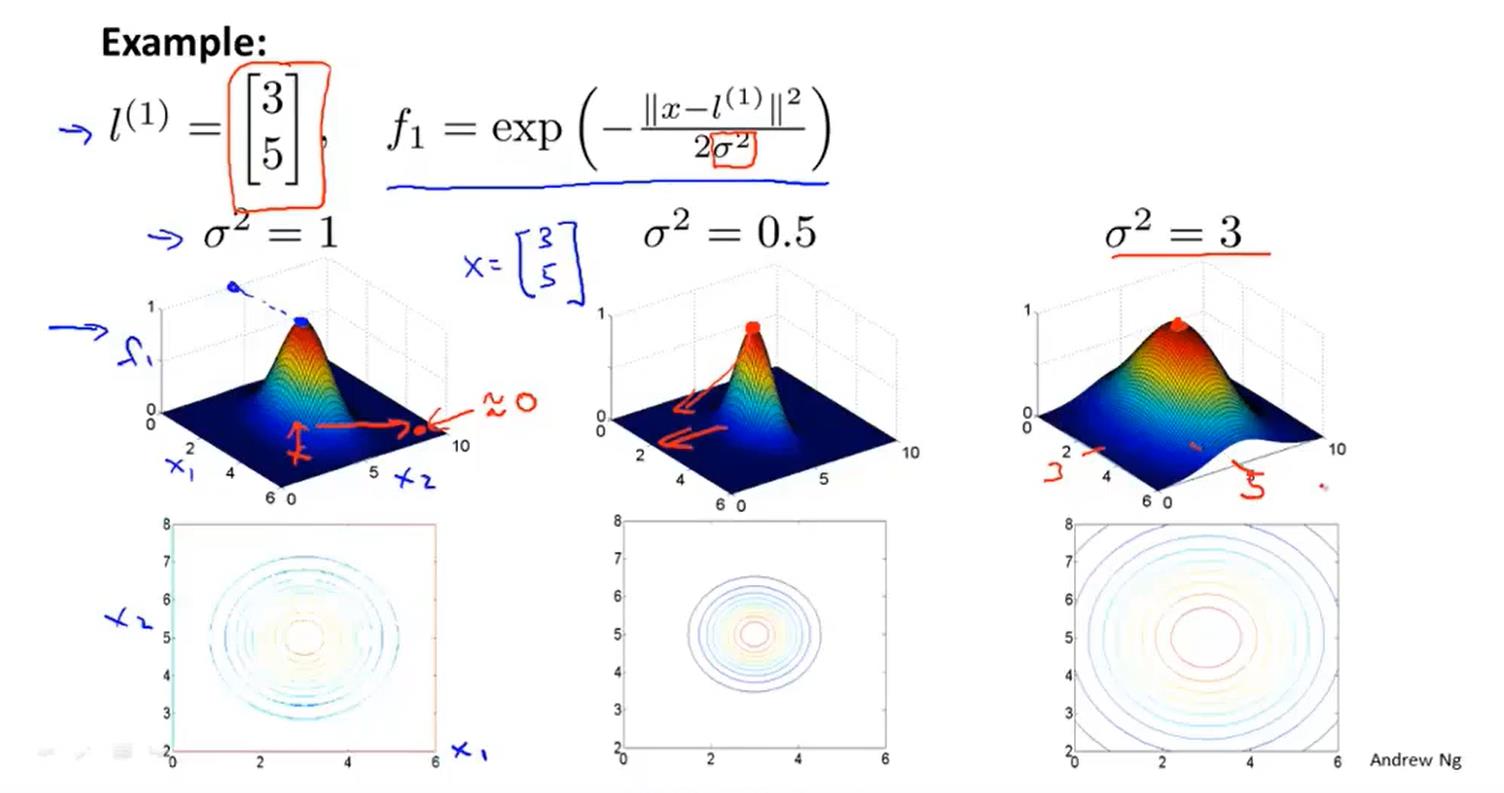
公示举例理解:

如何选取标记点?
将训练样本的x点作为标记点


seigema和C(1/lambda)的选择
- C大适合于高偏差低方差(欠拟合)
- C小适合于高方差低偏差(过拟合)
- seigema大适合于高偏差低方差(欠拟合)
- seigema小适合于高方差低偏差(过拟合)

如何使用SVM
- 选择合适的C
- 选择合适的核函数
- 选择合适的seigema

多类分类中怎么使用SVM

logistic回归vsSVM
n(特征变量)>m(训练集)
logistic更好(或者用无核的SVM(线性)),线性回归拟合好于复杂非线性
n(特征变量)<m(训练集)
SVM高斯核函数更好,可以拟合非线性复杂的函数
神经网络很可能在大多数情况下都能很好地工作,但训练起来可能会比较慢。
无监督学习(暂无总结)
聚类算法:将数据分为不同的簇。

交尾酒会算法:例如分离出不同声音
以上是关于机器学习(监督学习)基础,强推!!!的主要内容,如果未能解决你的问题,请参考以下文章