本地IDEAspark程序远程读取hive数据
Posted 一加六
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了本地IDEAspark程序远程读取hive数据相关的知识,希望对你有一定的参考价值。
描述问题
数据在linux系统服务器上,在自己windows上用IDEA编写spark程序,需要远程访问hive数据。
先说成功步骤,再说配置过程出现的的问题和解决办法
步骤
确保hive --service metastore 服务在Linux服务器已开启,在hive-cli可以正常读取数据。
1 下载winutils
github-winutils各个版本集合
下载里面和自己服务器版本对应的,
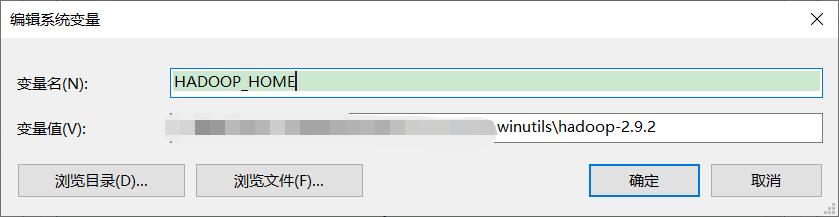
配置HADOOP_HOME
将下载的文件添加到系统环境变量,配置完最好重启系统。
2 添加hive-site.xml文件
下载服务器端的hive-site.xml文件配置
添加到src/main/resources目录下

hive-site.xml
此处好几个注意点
hive.metastore.uris
hive.metastore.warehouse.dir
hive.exec.scratchdir
这几个参数一定注意配置好,后面好几个问题都跟这里有关
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- jdbc连接的URL 01-->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true&useSSL=false&allowPublicKeyRetrieval=true&serverTimezone=GMT%2B8</value>
</property>
<!-- jdbc连接的Driver 02-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<!-- jdbc连接的username 03-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- jdbc连接的password 04-->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>password</value>
</property>
<!--元数据访问地址-->
<property>
<name>hive.metastore.uris</name>
<value>thrift://hbase:9083</value>
</property>
<!-- Hive默认在HDFS的工作目录 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.exec.scratchdir</name>
<value>/tmp</value>
</property>
<!--配置远程访问hive-->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hbase</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<!--配置远程访问hive的用户密码-->
<!--
<property>
<name>hive.server2.thrift.client.user</name>
<value>hive</value>
<description>Username to use against thrift client</description>
</property>
<property>
<name>hive.server2.thrift.client.password</name>
<value>password</value>
<description>Password to use against thrift client</description>
</property>
-->
<!-- yarn作业获取到的hiveserver2用户都为hive用户。设置成true则为实际的用户名 -->
<property>
<name>hive.server2.enable.doAs</name>
<value>false</value>
</property>
<!-- 校验在metastore中存储的信息的版本和hive的jar包中的版本一致性-->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<!--元数据存储授权-->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<property>
<name>mapreduce.jobtracker.address</name>
<value>ignorethis</value>
</property>
<property>
<name>hive.exec.show.job.failure.debug.info</name>
<value>false</value>
</property>
</configuration>
3 spark程序config
def readHive(args:Array[String]*): Unit =
System.setProperty("HADOOP_USER_NAME","root")
val spark2: SparkSession = new SparkSession.Builder()
.master("local[*]")
.appName("sparkReadHive")
//支持读Hive数据
.enableHiveSupport()
.getOrCreate()
spark2.sql("show databases")
spark2.sql("use weblog")
//spark2.sql("show tables").show()
val frame = spark2.sql("select * from mlog limit 100")
frame.show()
读取结果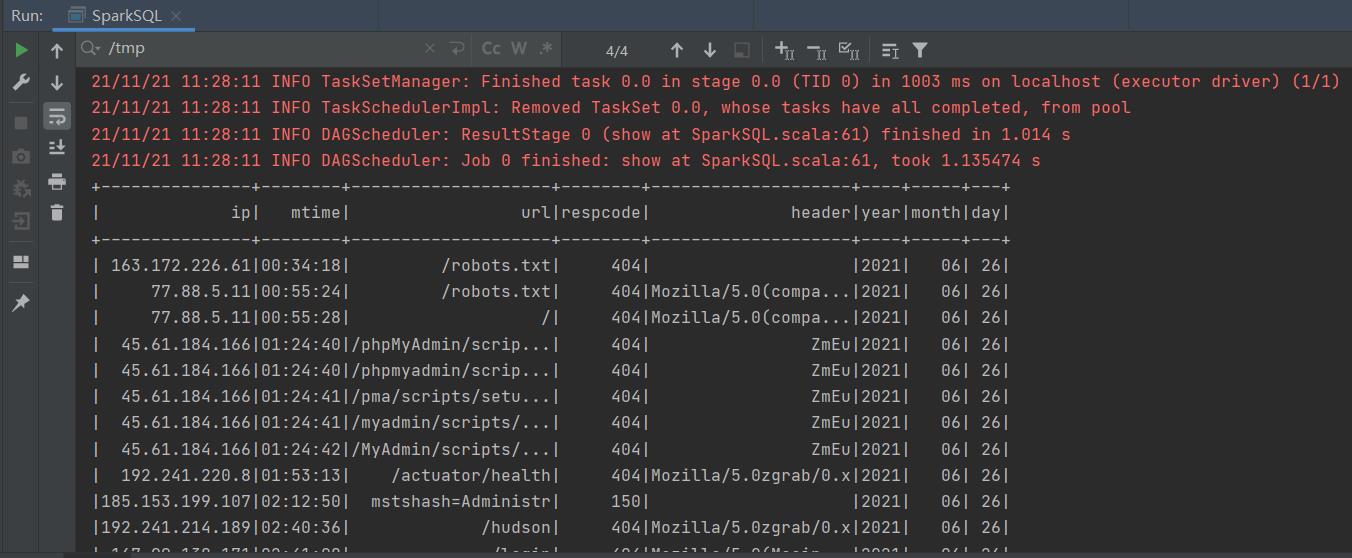
解决过程出现的问题
现存问题
一个WARN
经以上操作程序可读取到hive数据,但会报如下warning,windows无法

具体请看
临时目录tmp有关问题
在hive-site.xml中设置一下,默认使用hdfs上的临时目录
<property>
<name>hive.exec.scratchdir</name>
<value>/tmp</value>
</property>
权限
用有写权限的用户去操作:在spark程序代码中添加:System.setProperty(“HADOOP_USER_NAME”,“root”)
spark.sql.warehouse.dir
INFO SharedState: spark.sql.warehouse.dir is not set, but hive.metastore.warehouse.dir is set. Setting spark.sql.warehouse.dir to the value of hive.metastore.warehouse.dir ('/user/hive/warehouse').
21/11/21 11:28:04 INFO SharedState: Warehouse path is '/user/hive/warehouse'.
只要在hive-site.xml设置了hive.metastore.warehouse.dir,就可以替代,也可在代码添加spark.sql.warehouse.dir使用本地warehouse
JDBC方式
还有一种方式是通过jdbc方式访问hiveserver2,这样查询操作都是在服务端,只能获取查询结果;
参考文章
使用idea, sparksql读取hive中的数据
Hive的metastore和hiveserver2服务
Spark远程连接Hive数据源
以上是关于本地IDEAspark程序远程读取hive数据的主要内容,如果未能解决你的问题,请参考以下文章