CSAPP buffer lab记录——IA32版本
Posted yhjoker
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CSAPP buffer lab记录——IA32版本相关的知识,希望对你有一定的参考价值。
CSAPP buffer lab为深入理解计算机系统(原书第二版)的配套的缓冲区溢出实验,该实验要求利用缓冲区溢出的原理解决5个难度递增的问题,分别为smoke(level 0)、fizz(level 1)、bang(level 2)、boom(level 3)、kaboom(level 4).在实践中加深对函数调用和缓冲区溢出机制的理解(针对IA-32体系结构)。
本记录使用的是取自原书配套网站的self-study handout版本,网址为http://csapp.cs.cmu.edu/2e/labs.html。
原课程实验指导为CSAPP buffer lab writeup:http://csapp.cs.cmu.edu/2e/buflab.pdf
关于实验中gdb、gcc的使用问题可以参考笔者另一篇博客:Linux下编辑、编译、调试命令总结——gcc和gdb描述
Buffer lab的self-study handout版本为一个 .tar 打包文件。解压可参考文章Linux下文件的打包、解压缩指令——tar,gzip,bzip2
实验准备:
解压得到包含三个可执行文件的名为buflab-handout的目录:
bufbomb:用来攻击的缓冲区炸弹程序;
hex2raw:用来进行十六进制向二进制串转换的工具(可能所需输入并不是ASCII的可打印字符,借助此工具进行转换);
makecookie:在实验中是根据ID生成特定的cookie的工具,在self-study中不使用;
使用命令行./bufbomb -u IDname运行bufbomb,程序会根据输入的IDname生成特定的cookie。实验过程中需根据实验要求,构造能够实现特定功能的输入序列,完成对应的五个任务。
hex2raw:由于输入序列所需要的二进制串可能无法完全对应ASCII中的可打印字符,如地址高位为0x80时,ASCII对应的字符是不可通过键盘输入的,可使用hex2raw进行转换。hex2raw读取输入文件中的十六进制数串(每两位用空格隔开),hex2raw将其转换为对应的二进制序列。
可使用 cat filename| ./hex2raw| bufbomb 输入构造的字符串流,其中filename为存放有带转换的十六进制串的文件。
进行调试操作时,可使用 ./hex2raw< filename > output.bin 将转换后的二进制流输出至output.bin,再通过 r < output.bin在gdb中调试
(这里需要注意,实验所提供的hex2rax工具为64位版本,可通过命令 file hex2raw 查看。若在32位环境下运行,会提示cann\'t execute binary file:format error.同时,bufbomb文件为32位版本)
实验分析:(详细可参考buffer lab的writeup介绍)
getbuf()
bufbomb通过一个自定义的getbuf()函数读取输入,并将其复制到目标内存中。该函数主要通过Gets()函数实现。
/* Buffer size for getbuf */ #define NORMAL_BUFFER_SIZE 32 int getbuf() { char buf[NORMAL_BUFFER_SIZE]; Gets(buf); return 1; }
Gets()函数从标准输入中读取输入(以"\\n"或者EOF作为输入结尾,并不检查读取长度),并将其以"\\n"结尾存放在指定的内存区域中。这里可知目标字符数组buf长度为32字节。
注意:buf数组的长度为32个字节,但是数组实际在内存(栈)中被分配的长度和位置随编译器的不同而有所区别,这里由于直接给出了可执行程序,可以使用objdump -d bufbomb 查看getbuf的实现。
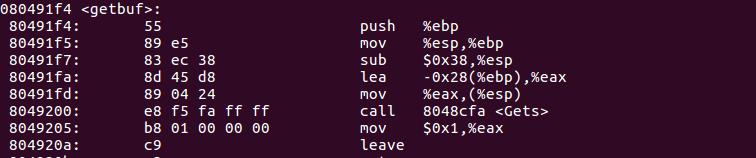
根据函数调用时参数入栈的规则,可知调用Gets函数之前buf数组的首地址会入栈,易知%eax存储的 %ebp - 40 为buf数组的首地址,这里可以看出已分配的空间和数组长度并不严格相同!(为满足数据对齐,IA32保证每个栈帧的长度为16的整数倍)。getbuf的栈结构如下:
当输入不足32个字节时,输出如下:

输入超过32个字节时,输出如下:

使用命令行./bufbomb -u IDname运行bufbomb,程序会根据输入的IDname生成特定的cookie。实验过程中需根据实验要求,构造能够实现特定功能的输入序列,完成对应的五个任务。
hex2raw:由于输入序列所需要的二进制串可能无法完全对应ASCII中的可打印字符,如地址高位为0x80时,ASCII对应的字符无法通过键盘输入(可参考xxxxx),可使用hex2raw进行转换。hex2raw读取输入文件中的十六进制数串,并将两个十六进制数转换为对应字节的二进制流,如想要输入高位地址0x80时,直接在输入文件中写入其对应的十六进制表示 80,hex2raw自动将其转换为对应的二进制序列。可使用 cat filename| ./hex2raw| bufbomb 输入构造的字符串流,其中filename为存放有带转换的十六进制串的文件。(这里需要注意,实验所提供的hex2rax工具为64位版本,可通过命令 file hex2raw 查看。若在32位环境下运行,会提示cann\'t execute binary file:format error.同时,bufbomb文件位32位版本,)
实验过程:
level 0 Candle(10 pts)
在bufbomb中存在函数test(),其调用getbuf()函数读取输入,并通过uniqueval()函数进行堆栈是否被破坏的检查,之后根据读取后的情况进行相应的输出。
void test() 2 { 3 int val; 4 /* Put canary on stack to detect possible corruption */ 5 volatile int local = uniqueval(); 6 7 val = getbuf(); 8 9 /* Check for corrupted stack */ 10 if (local != uniqueval()) { 11 printf("Sabotaged!: the stack has been corrupted\\n"); 12 } 13 else if (val == cookie) { 14 printf("Boom!: getbuf returned 0x%x\\n", val); 15 validate(3); 16 } else { 5 17 printf("Dud: getbuf returned 0x%x\\n", val); 18 } 19 }
同时,bufbomb文件中还存在函数smoke(),level 0即改变程序控制流,使得test函数调用getbuf()后,在getbuf()返回时直接调用smoke()函数,而不是返回函数test()
void smoke() { printf("Smoke!: You called smoke()\\n"); validate(0); exit(0); }
这里主要考察函数调用时返回地址相关的知识。我们知道在函数调用过程中,控制权跳转至目标函数之前,会将返回地址(调用点处的下一条指令的地址)入栈,在函数调用结束后,通过该地址来继续执行调用点的下一条指令。这里,想要在函数调用结束时直接调用smoke()函数,主要在于修改函数调用的返回地址为smoke()函数的地址。注意,虽然test中有检查堆栈破环的canary,但任务目的是在getbuf结束后直接调转至另一函数,而没有执行后续的堆栈是否被破坏的检查,所以可直接构造超出数组长度的字符串来覆盖返回地址,使其指向目标函数的地址。
由前文对getbuf的栈空间的分析,可知想要构造覆盖返回地址的函数,则字符串的结构应为 44个字节的填充字符(buf分配的空间+ebp) + 新的返回地址。
通过gdb动态调试可知smoke函数起始地址为0x08048c18.

构造的字符串为:0*44 + 18 8c 04 08 .(小端法存放)。构造的用于hex2raw转换的文件如图所示,其中30为字符0对应的ASCII的十六进制表示,最后4个字节位小端法表示的smoke函数起始地址。
成功调用了smoke函数:

level 1 Sparkler(10 pts)
bufbomb中存在另一个函数fizz(),其源码如下.fizz()函数将实参与cookie比较,当cookie与实参相等时,则表示成功。这里的cookie即为运行./bufbomb -u UesrID 时根据UserID生成的cookie。
void fizz(int val) { if (val == cookie) { printf("Fizz!: You called fizz(0x%x)\\n", val); validate(1); } else printf("Misfire: You called fizz(0x%x)\\n", val); exit(0); }
level 1的任务为(1)修改getbuf函数返回地址为fizz()函数,而不是返回函数test() ; (2)在fizz()中验证成功,即需传入cookie值作为参数;
这里主要考察的是关于函数的参数传递方面的知识。
下左图:
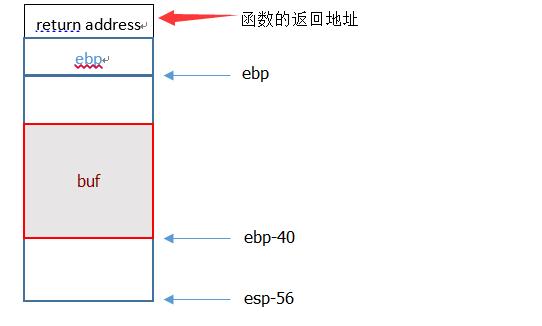
(1)对于有参数的被调函数,函数调用之前会将参数按从右至左的顺序入栈,之后在被调函数中通过%ebp+8、%ebp+12等地址获得函数调用的实参。
(2)函数调用指令call会将函数的返回地址入栈,被调函数会将原函数的栈帧指针即存储在%ebp中的值入栈,并使新的%ebp的值等于%esp,从而使%ebp指向被调函数的栈帧,这样新%ebp指向的地址与函数的参数存放处间隔保存的%ebp和返回地址,故可以通过%ebp+8获得函数的第一参数
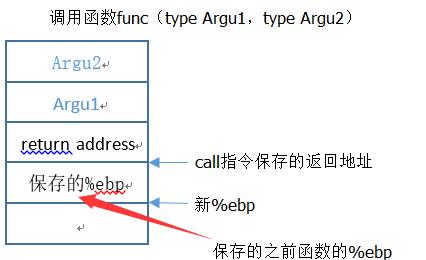
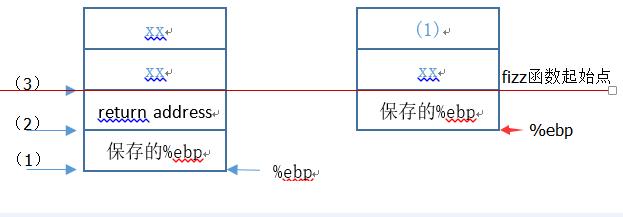
上右图:
(1)左侧箭头标识%esp位置。函数返回时,首先将%ebp值赋值给%esp,则栈顶为位置(1).之后push %ebp,将%ebp还原,%esp在位置(2)。最后ret指令恢复返回地址,%esp指向位置(3);
(2)由于需返回fizz函数,故返回地址已被修改为fizz的地址。注意这里没有call指令,没有返回地址入栈。fizz函数按正常流程执行,其栈自红线处开始。先将%ebp入栈,新的%ebp位置如图所示。fizz函数正常按照%ebp+8的位置取其参数,故图示栈中的位置(1)应被覆盖为cookie值;
故构造的输入字符串应为:44个填充字节 + fizz函数起始地址 + 4个填充字节 + cookie值.fizz函数的起始地址可使用gdb查看,cookie值为bufbomb生成的值,这里注意使用小端法书写即可。


构造的字符串为:0*44 + 42 8c 04 08(fizz起始地址) + 0*4 +da 31 3e 37(cookie) .
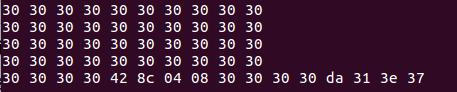
结果如图所示:

level 2 Firecracker(15 pts)
更复杂的构造输入字符串的方法是在字符串中包含有实际功能的机器语言代码,并修改函数的返回地址使其指向构造的代码,从而执行这段代码实现设定的功能。
bufbomb中存在函数bang,函数同样验证cookie与实参的值,并根据结果进行验证,同时输出全局变量global_value的值。
int global_value = 0; void bang(int val) { if (global_value == cookie) { printf("Bang!: You set global_value to 0x%x\\n", global_value); validate(2); } else printf("Misfire: global_value = 0x%x\\n", global_value); exit(0); }
level 2的任务为:(1)通过执行输入构造的机器指令修改global_value的值为cookie的值; (2)如level 0中所执行的,test函数调用getbuf()后,在getbuf()返回时直接调用fizz()函数,而不是返回函数test() ;
任务的关键在于如何构造机器代码,以及使得程序跳转至输入的机器代码处执行,同时注意函数bang的参数传递过程。
构造输入字符串的过程:
(1)全局变量global_value在程序执行的过程中逻辑地址不发生变化,可直接在gdb中得到其地址,使用mov指令对其进行赋值;
(2)将getbuf函数的返回地址修改,指向构造的机器代码的开始处,这里即buf数组的起始地址;
(3)由于getbuf函数的返回地址已经被用于指向输入的机器代码,故跳转至bang函数的实现需要使用额外的指令。这里由于程序是已经编译好的,所以bang函数的逻辑地址不变,故可以直接使用逻辑地址调用。使用push 将bang函数地址入栈,再使用ret指令进行跳转。(push指令将数据放置在栈顶,ret取栈顶的数据并将其作为地址进行跳转);
(4)这里需要注意函数bang的参数传递过程。之前的level 0与level 1,机器代码存放在代码段,由PC指示,数据操作在栈上,由%esp指示。level 2中第一次跳转后,正在执行的机器代码位于栈上的缓冲区中,由PC指示,数据操作也在栈上,由%esp指示,这里需要注意两者的区别,前者是用于执行的,后者用于操作。图示为函数ret指令之后%esp和PC的位置。同样,对函数参数的传递可参考level 1或者直接使用%esp + 4寻址赋值;

构造输入字符串:可执行的机器代码 + 填充字符 + 指向输入机器代码的地址。
通过gdb得到bang函数的起始地址位0x08048c9d。

同样在bang函数的反汇编中,将0x804d100与0x804d108处的值进行了比较,查看地址0x804d108,发现存放的是cookie,则0x804d100处即为全局变量global_value的值。

在getbuf函数内部设置断点,并运行至函数内部,得到buf数组的起始地址为0x55683978.(这里注意要运行至getbuf内部是由于需要使得%ebp指向的是getbuf的栈帧,这样%ebp-40才是buf数组的首地址,否则直接输出%ebp-40可能指向的其他地方)

构造的可执行代码为:
mov $0x373e31da,0x804d100 #将cookie值赋值给global_value mov 0x804d100,%eax mov %eax,4(%esp) #将global_value的值作为实参放置在栈中作为bang的参数 push $0x08048c9d #将bang函数起始地址入栈,注意常数的书写方式,加上$ ret #将栈顶数据作为地址进行跳转
可以将上诉汇编指令进行编译,编译方法可见实验writeup的最后一部分,再使用objdump或gdb反汇编来得到所需的机器代码的十六进制表示。(注意这里和gdb中的代码并没有明确给出指令后缀b、w、l、q,但在实际书写中需加上后缀才能编译)
实际使用的输入字符串如图所示,其中可执行代码(25bytes) + 填充字符(19bytes) + 数组首地址(4bytes)

执行后的结果为:

level 3 Dynamite(20 pts)
目前为止的操作都是使得正常控制流改变并跳转至其它函数,最终使得程序停止,故而以上操作中对于栈的破坏、破坏保留值等操作对于程序运行是可以接受的。更复杂的缓冲区攻击在于执行某些构造的指令改变寄存器或内存中的值,并使程序能正常返回原控制流执行。level 3的任务为通过构造指令,使得getbuf正常返回至test函数,并使得getbuf返回值为cookie值。
需要注意以下几点:
(1)构造的机器指令是存放在getbuf的缓冲区中,想要执行输入的构造代码,只有修改geubuf函数返回时的地址,注意当跳转至构造的代码处执行时,getbuf是已经结束了,返回值1存放在寄存器%eax中;(正是结束时的ret指令才跳转至修改后的地址处)
(2)回想函数调用过程,call指令调用函数时将返回地址放置在栈顶,进入函数后的第一步为保存%ebp,这样在覆盖修改返回地址时必将覆盖保存的%ebp也覆盖掉了。在getbuf函数结束时,会将%esp的值赋值为getbuf栈帧指针%ebp的值(mov指令),之后将保存的%ebp值赋值给寄存器%ebp。前面所述,保存的%ebp在覆盖返回地址时已经被覆盖,故此时%ebp会是一个任意值;
(3)由于题目的要求是正常返回test函数,而该函数存在一定的对缓冲区覆盖的检查(uniqueval函数),故可能需要注意构造的字符串的长度;
如上所述,构造的字符串应完成的功能为:(1)修改存放返回值的寄存%eax; (2)恢复寄存器%ebp的值为正常值,这里即test函数的栈帧; (3)将getbuf正常返回地址放置在栈顶,并通过ret指令返回test函数。
通过gdb调试,在getbuf函数内部设置断点,查看保存的返回地址、保存的%ebp等信息。p $ebp获得getbuf栈帧指针的信息,再使用x /2xw $ebp获得地址%ebp处开始的连续两个4字节空间的值(回忆一下getbuf的栈结构,这两个空间存放的即为保存的%ebp和返回地址)。得到returnaddress为0x08048dbe,保存的%ebp为0x556839d0.

构造的可执行代码为:
movl $0x373e31da,%eax #修改返回值为cookie值 movl $0x556839d0,%ebp #恢复被破坏的保存的%ebp的值 push $0x08048dbe #将返回地址入栈 ret #跳转
构造的字符串序序列如下,其中 构造代码(16字节) + 填充字符(28字节) + 修改的返回地址,即为数组起始地址(4字节)
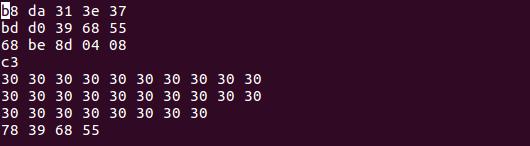
执行结果如下:

level 4 Nitroglycerin(10 pts)
对于一个给定的程序而言,程序每次运行时尤其是被不同用户运行时的使用的栈位置是不同的。造成栈位置变化的原因有很多,其中一个是由于程序在运行时,所有必要的环境变量都以字符串的形式被放置在栈的底部(高地址单元)。对于不同值的环境变量,其所需要的栈空间自然不同,从而使得栈位置的变化,对于不同用户而言这一点更为显著。相应的,程序自然运行与在gdb环境下运行的栈位置也可能不同,因为部分gdb本身运行所需的数据被放置在了栈中。
getbuf函数内置了使栈空间稳定的特性,从而使得进行缓冲区攻击时能够直接获得固定的所需要的地址数据,并采用直接利用的方式写入机器代码中,这也大大降低了实现难度。而这在实际应用情况下是过分理想的。在level 4环节,用户需要在启动bufbomb时使用 -n 选项,从而使得栈空间不再稳定,并在此基础上进行基于缓冲区溢出原理的实验。
程序运行时启用了 -n 选项时,程序在读取输入时会启用 getbufn函数(而不是前面的getbuf)。getbufn函数有与getbuf相似的功能,但前者输入数组的长度为512字节。调用getbufn函数之前,程序会先在栈上分配一个随机长度的空间,从而使得getbufn函数的栈空间在不同调用情况下不再是固定的,实际上%ebp的差值达到±240。在应用 -n 选项的情况下,程序会要求提交输入字符串 5 次,5次输入会面对5个不同的栈空间,并要求每次都成功返回cookie值。level 4的任务与level 3一致,即要求getbufn函数返回调用函数testn时返回cookie值,而不是常规的1.
程序的运行过程加入了栈随机化的操作,即在程序调用之前,先分配一个随机大小的空间,这个空间程序并不使用,但是长度不定,从而使得每次运行时的栈空间地址结构产生变化(主要是在栈相对结构不变的情况下,各个栈中元素的地址发生了变化)。这一操作的显著影响是之前所采用的使用固定的新返回地址覆盖getbufn返回地址的方法受到限制。由于每次栈空间不同,则输入的机器代码的起始位置也不同(回忆上文,每次均是将机器代码放在输入字符串的开始位置,这样每次修改返回地址为输入数组的起始地址即可执行构造的代码,其中输入数组起始地址是固定的),相应的直接指定出构造代码的地址变得不可行。
这里对于栈随机化的破解可以借助“空操作雪橇”(nop sled)的技巧。所谓nop sled是在构造的机器代码之前加入nop指令(no operation的缩写,机器码位 0x90),其作用为仅将PC增加而不执行任何操作。在这种情况下,只要覆盖的地址能够指向nop序列所处的任意一个地址,就可以顺序执行nop指令,直到遇到真正构造的机器代码,这样的情况下,对于用于覆盖的返回地址的要求就降低了。
即构造出的字符串位:nop指令串 + 构造的机器代码 + 返回地址。
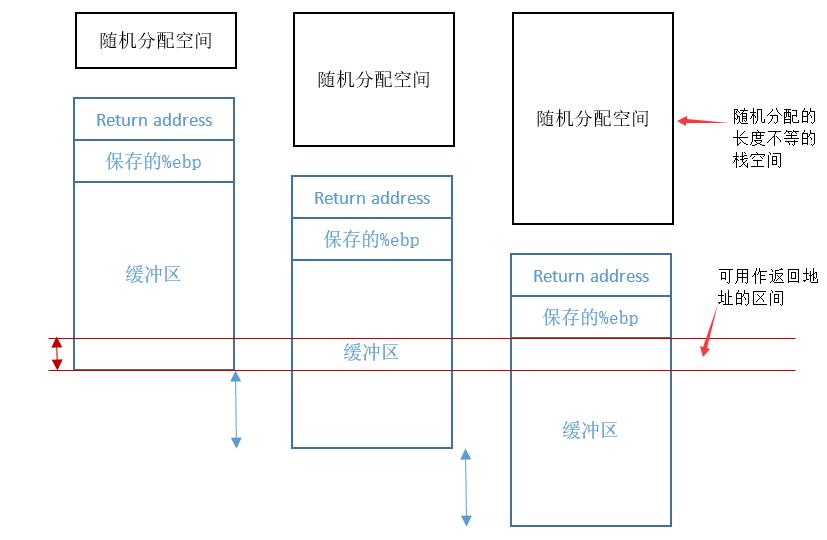
如图所示,由于随机分配的地址空间的存在,栈上各个元素的地址会发生变化,从而使得用于覆盖的返回地址难以确定。使用空操作雪橇时,会在构造的代码之前填入nop指令。题中的缓冲区有512个字节,同时%ebp的差值为±240。正常情况如上图,则存在一个区间,只要返回地址为该区间内的地址,则总可以通过nop指令向上“滑行”至真正执行的构造代码处,从而实现攻击。
查看getbufn函数的实现,可知数组的分配的长度位520个字节(0x208),覆盖返回地址需要填充 520(数组长度)+ 4(保存的%ebp) = 524个字节。

通过 p $eax查看%ebp的值,通过 x /2xw $ebp 查看保存的%ebp和返回地址的值。

解题思路如下:
(1)为达到能返回cookie值至testn函数的目的,同样需要getbufn修改返回地址使其执行构造的代码,完成包括修改返回值、恢复%ebp、返回testn函数这三个步骤;
(2)在步骤(1)中,修改返回值即%eax与返回testn函数的操作与level 3是一样的。总是将返回值修改为cookie,返回testn函数的地址也总是不变的(注意这里程序应用的是栈随机化的操作,影响的是栈空间上的地址,可执行代码是存放在代码段,在题设环境下是不受影响的);
(3)关于如何恢复被覆盖%ebp的问题。栈随机化是在栈上分配一段不定长的内存空间使得栈中元素的地址发生变化。但是,由于程序总是执行相同的操作,使得在不同的执行情况下,程序所使用的栈中元素的相对位置(距离)不发生变化,可尝试在此前提下恢复%ebp。恢复过程是由输入的构造代码执行的,此时%ebp已经被赋予了“废值”(见level 3分析),但%esp是有效的值,可以通过%esp推出被覆盖的保存的%ebp的值。从上面获得的保存的%ebp的值(0x556839d0)和%ebp的值(%0x556839a0),在构造代码执行时,%esp应为%ebp+8 = 0x556839a0 + 8 = 0x556839a8 ,则可以看到在差值为 0x556839d0 - 0x556839a8 = 0x28.上述地址在不同运行情况下是会改变的,但其相对差值不变,故总是可以通过执行%esp + 0x28得到原有的被破坏的%ebp值
以下是借助gdb调试程序的过程中两次运行时的栈空间的变化。可以看到,在两次运行中,%ebp和保存的%ebp改变了,而返回地址没有改变,这是由于返回地址指向的是位于代码段的固定位置处的代码,不受栈随机化的影响,但位于栈上的数据则受到了影响。


构造的可执行代码为:
movl $373e31da,%eax //修改返回值 movl %esp,%ebx addl $0x28,%ebx movl %ebx,%ebp //根据%esp的值得到需要恢复的%ebp的值 pushl $0x08048e3a ret //跳转至原函数
构造的输入字符串为 :nop指令串(506字节) + 构造指令(18字节) + 用于覆盖的新地址(4字节,上述区间中的一个地址即可)
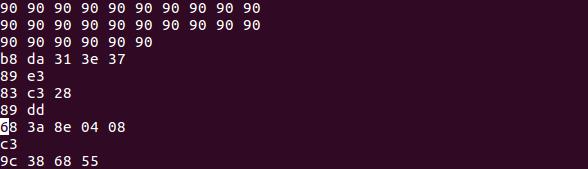
最终结果为:

以上是关于CSAPP buffer lab记录——IA32版本的主要内容,如果未能解决你的问题,请参考以下文章